
📑 Paper | 🐙 GitHub | 🤗 HuggingFace
🎤 Demo Page | 💬 Contact Us
WenetSpeech-Chuan 包含10000小时大规模川渝方言语音语料,标注丰富,是目前川渝方言语音研究最大的开源资源。涵盖十大领域:短视频、娱乐、直播、纪录片、有声读物、戏剧、访谈、新闻等。开发并开源了Chuan-Pipeilne(方言语音数据处理框架), 收集了大规模的、自然界中的语音录音,涵盖故事讲述、戏剧、评论、视频博客、美食、娱乐、新闻和教育等多个领域。这些长录音通过语音音频检测 (VAD) 被分割成短片段,从而生成用于转录和质量评估的话语级数据。
Chuan-Pipeline

Chuan-Pipeline流程能系统地将原始、未标注的音频转化为一个内容丰富、标注完善的语料库,用于语音识别(ASR)和语音合成(TTS)。
Pre-Processing and Labeling
管道的初始阶段主要关注数据获取、分割,以及为语音片段添加多维副语言标签。原始数据的获取始于从在线视频平台挖掘元数据,以识别可能包含四川方言的内容。经过初步人工审核以确认目标方言的存在后,获取的音频流将进入多阶段处理流程:
- VAD 与分割:使用语音活动检测(VAD)将长音频流切分为 5–25 秒的片段,同时去除沉默和噪声等非语音部分。
- 单说话人选择与聚类:首先使用 pyannote 工具包隔离单说话人片段。随后,使用 CAM++ 模型提取说话人嵌入,并进行聚类,为同一说话人的所有语句分配一致的说话人 ID。
- 副语言注释:
- 性别识别:使用预训练分类器(准确率 98.7%)确定说话人性别。
- 年龄估计:基于 Vox-Profile 基准评测,将年龄划分为儿童、青少年、青年、中年和老年阶段。
- 情绪标注:通过 Emotion2vec 和 SenseVoice 的预测结果进行多数表决,覆盖七类情绪:高兴、愤怒、悲伤、中性、恐惧、惊讶和厌恶。
质量评估
自动化质量评估:用时间戳对齐的语音作为输入,提取音频时长和信噪比(SNR)等指标。随后,这些特征用于计算词级虚拟主观评价分数(WVMOS),作为感知音频质量的替代指标。低质量的音频样本将被丢弃。
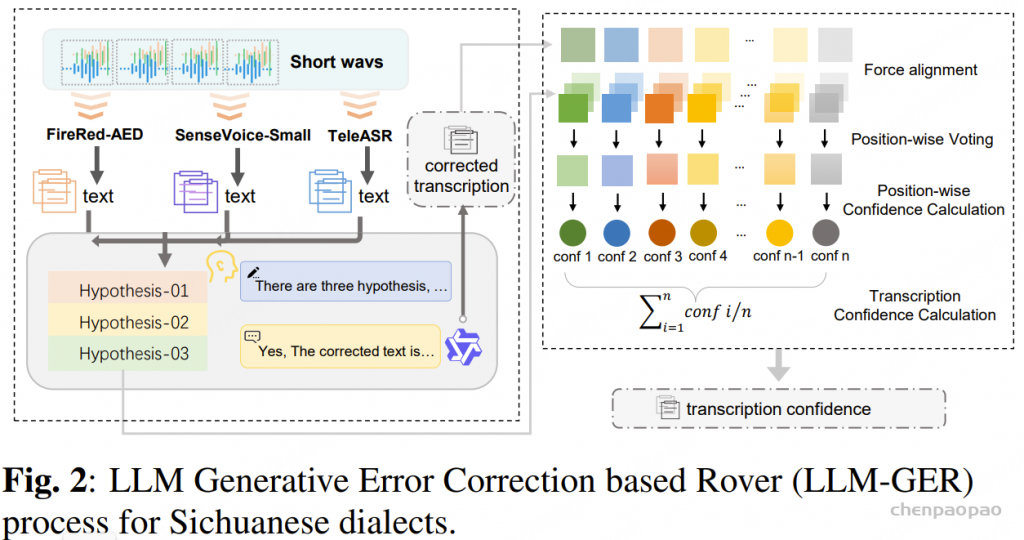
LLM-GER纠错处理
为了提高自动语音识别(ASR)转写的准确性,并在已有研究的基础上,我们提出了一套针对四川方言的鲁棒 ASR 转写框架。我们的方法被称为 基于大语言模型生成的错误纠正 ROVER(LLM Generative Error Correction based ROVER, LLM-GER),旨在将多个 ASR 系统的输出融合为单一、准确且可靠的转写结果。
首先,三套不同的 ASR 系统(FireRed-ASR、SenseVoice-Small 和 TeleASR)生成初步候选转写。随后,这些转写由 Qwen3 进行融合,利用其强大的方言理解能力,并结合我们精心设计的提示(prompt)进行错误纠正,同时保持原始语义和 token 长度不变。

通过这种方法,充分发挥了大语言模型(LLM)在规范化四川方言表达方面的能力,同时整合了多套 ASR 系统的互补优势。这样的组合为 WenetSpeech-Chuan 数据集生成了高质量的转写结果。对测试集的计算结果显示,与单一 ASR 系统的转写相比,LLM-GER 平均可将转写准确率提高约 15%。
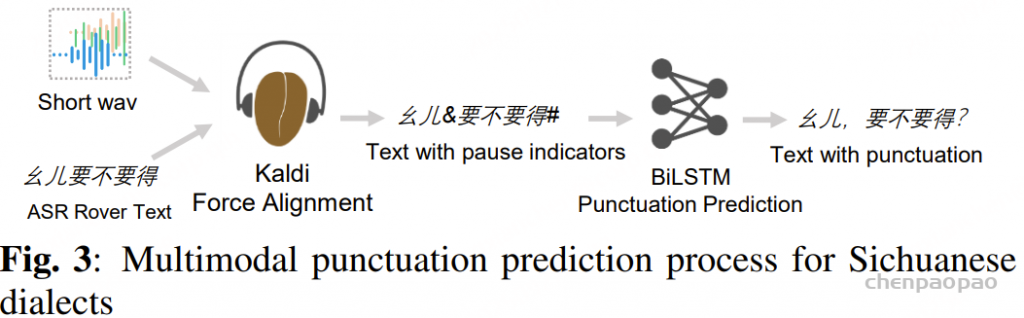
标点符号预测
带标点的准确转写对于 TTS 训练至关重要,但仅依靠文本的标点预测往往与实际语音停顿不匹配。为此,我们提出了一种结合音频与文本模态的多模态标点预测方法。
在音频模态方面,我们使用 Kaldi 模型对音频与文本进行强制对齐,从而获得每个词的时间戳和停顿时长,并根据阈值将停顿划分为短停顿或长停顿(例如,短停顿 0.25 秒,长停顿 0.5 秒)。
在文本模态方面,我们使用 BiLSTM 标点模型在停顿候选位置预测标点:短停顿对应逗号,长停顿对应句号、问号或感叹号。阈值通过人工反馈进行迭代优化,以确保标点与实际语音停顿保持一致。
ps:该方法存在的的问题:由于不涉及语音信息,单模态模型时常无法获知说话人的情感态度,这会导致模型在一些句子末尾难以抉择以句号还是问号作为结束符。
WenetSpeech-Chuan Corpus
通过将 Chuan-Pipeline 应用于收集到的多源原始数据,我们构建了 WenetSpeech-Chuan 语料库,这是一个面向四川方言的大规模、多标签、多领域的资源。本节将详细介绍该语料库,包括其元数据、音频格式、数据多样性以及训练集和评估集的设计原则。
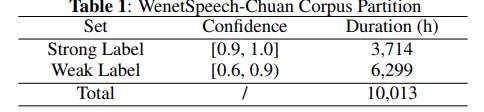
为每个音频片段分配一个置信度,用于衡量自动语音识别(ASR)转录的质量。 如表 1 所示,我们选取了 3,714 小时的强标签数据(Strong Label),其置信度大于 0.90。 6,299 小时的弱标签数据(Weak Label),置信度介于 0.60 与 0.90 之间,被保存在我们的元数据中,用于半监督训练或其他用途。 总的来说,WenetSpeech-Chuan 共包含 10,013 小时的原始音频。
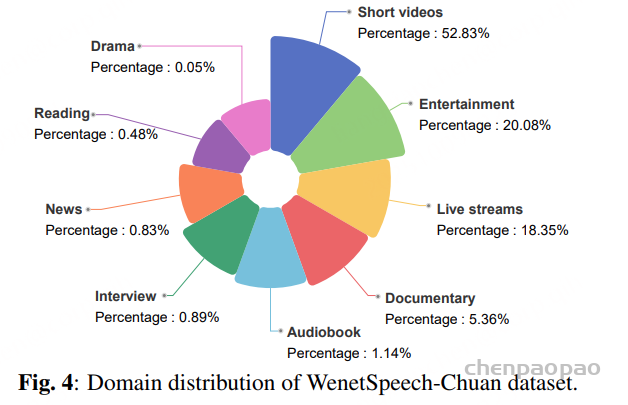
WenetSpeech-Chuan 的来源领域,共包含 9 个类别。 其中,短视频占比最大(52.83%),其次是 娱乐(20.08%) 和 直播(18.35%)。 其他领域包括纪录片、有声书、访谈、新闻、朗读和电视剧,占比较小,但提升了数据集的多样性。
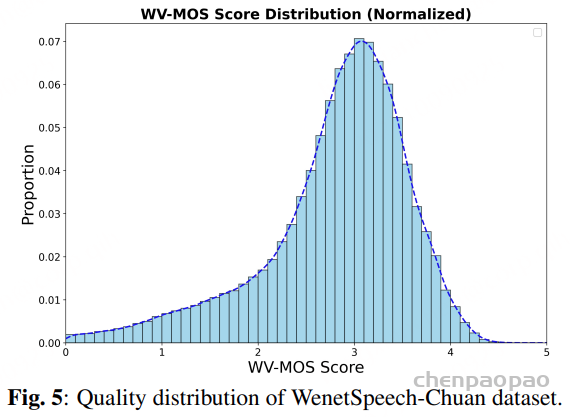
基于 WVMOS 指标 计算得到的音频质量评分主要集中在 2.5 到 4.0 区间,其中 3.0 到 3.5 之间存在一个显著峰值。 这一分布表明,语料库的大部分音频属于 中高质量语音,在干净录音与真实环境声学条件之间取得了平衡,从而使其在训练通用语音模型时具备较强的鲁棒性。
WenetSpeech-Chuan Eval Benchmark:
ASR 评测集:人工标注9.7 小时的评测集划分为 Easy 和 Hard 两个子集
TTS 评测集:
- WSC-Eval-TTS-easy:包含来自多个领域的方言词句子;
- WSC-Eval-TTS-hard:由长句子和大语言模型(LLM)生成的多样化风格句子组成,例如绕口令、俗语和情感化语音。

Experiments
ASR
如表 3 所示,不同类型的模型在四川方言测试集上的表现存在差异。 首先,在所有开源模型中,FireRedASR 在多个评测集上表现出相对稳定的识别性能。 值得注意的是,FireRedASR-AED 在所有测试集上的平均词错误率(WER)为 15.14%,成为表现最优的开源模型。 相比之下,Qwen2.5-omni 和 kimi-audio 等模型在 MagicData-Dialogue 测试集 上的错误率显著偏高,表明其对方言语音的适应性不足。
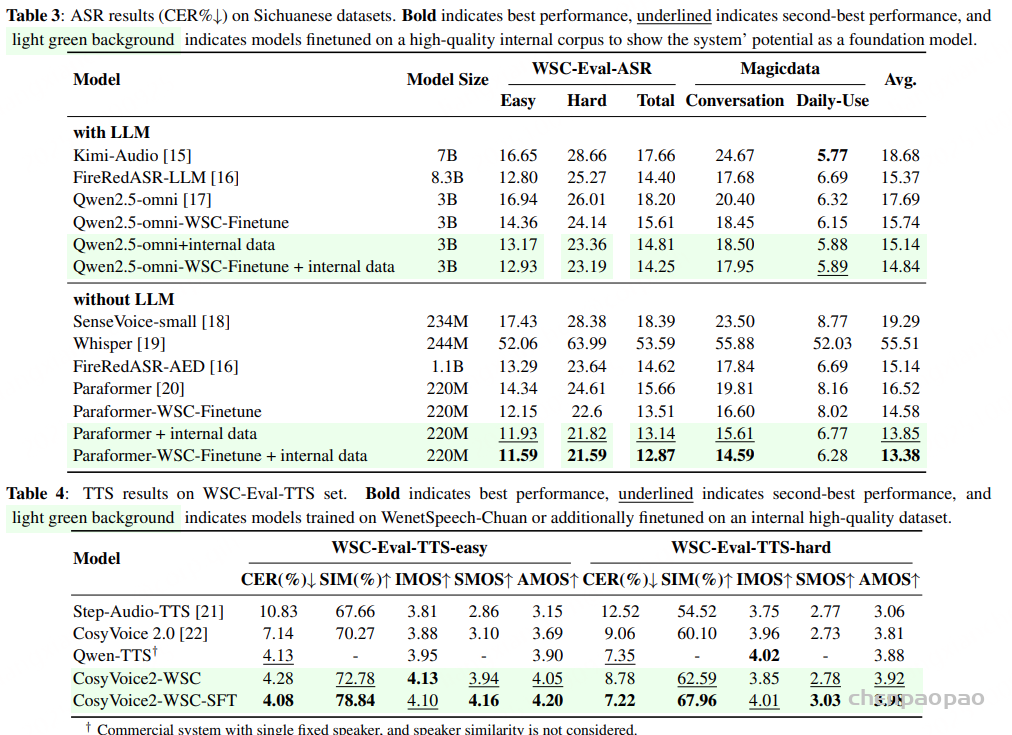
我们经过微调的模型展现出明显的性能提升。在 WenetSpeech-Chuan 上对 Paraformer 和 Qwen2.5-omni 进行微调后,整体性能分别提升了 11.7% 和 11.02% ,彰显了 WenetSpeech-Chuan 在提升方言识别能力方面的显著效果。此外,在额外使用 1000 小时内部数据进行持续微调后,Paraformer 在所有测试集上均达到了 13.38% 的平均 CER,达到了当前最佳水平 ,这证明了 ASR 模型在使用高质量方言数据训练时具有强大的迁移能力和适应性。
综上所述,我们的评估结果清楚地表明,在保持普通话识别能力没有明显下降的同时,WenetSpeech-Chuan 大大增强了模型识别四川方言的能力。
Speech Synthesis
CosyVoice2-WSC 在客观和主观指标上均展现出极具竞争力的表现。在简单分类下,其 CER 达到 4.28%,接近 Qwen-TTS 的 4.13%,同时实现了更高的感知质量和最佳的说话人相似度。在困难分类下,其 CER 上升至 8.78%,而 Qwen-TTS 仅为 7.35%,但仍保持了更高的感知质量,SIM 高于 62%,在挑战性场景中展现出更佳的鲁棒性。
与错误率较高的 Step-Audio-TTS 和 CosyVoice2 基线相比,CosyVoice2-WSC 在准确率和感知质量之间取得了更佳的平衡。经过微调后,CosyVoice2-WSC-SFT 取得了进一步的提升。在简单划分中,其 CER 最低,为 4.08%,SIM 最高,为 78.84%,同时 MOS 家族得分也处于领先地位。在困难划分中,其 CER 降至 7.22%,并保持了最佳 AMOS 得分,这表明微调能够同时提升准确率和感知质量。
总而言之,这些结果证实了 WenetSpeech-Chuan 数据集为构建稳健、高质量的四川方言 TTS 系统奠定了坚实的基础。
结论
WenetSpeech-Chuan,这是目前中国最大的四川方言开源语料库,包含超过 10,000 小时的多维语音标注。为了构建该数据集,我们开发了 Chuan-Pipeline,这是一个功能全面的数据处理工具包,能够支持这一大规模资源的创建。