
- 论文:https://arxiv.org/abs/2511.03601
- Demo:https://stepaudiollm.github.io/step-audio-editx/
- Github:https://github.com/stepfun-ai/Step-Audio-EditX
Step-Audio-EditX —— 全球首个基于大语言模型(LLM)的开源音频编辑模型,能够在语音的情感、说话风格和副语言特征(如语气、语速、语调等)上实现高度富有表现力且可迭代的编辑,同时具备强大的零样本文本转语音(TTS)能力。
核心创新在于:模型仅依赖大间隔(large-margin)合成数据进行训练,无需使用嵌入先验或辅助模块。这种大间隔学习策略使模型能够在多种音色上实现可迭代控制与高表达力,并从根本上区别于传统聚焦于表示层面解耦的思路。实验结果表明,Step-Audio-EditX 在情感编辑和其他细粒度语音控制任务上均超越了 MiniMax-2.6-hd 和 Doubao-Seed-TTS-2.0。
当前 TTS 的问题:由于合成语音中的情感、风格、口音和音色等属性仍然直接来源于参考音频,限制了对这些属性的独立控制,另外,对于克隆语音通常无法有效地遵循提供的风格或情感指令。
许多以往关于语音解耦的研究依赖以下方法来实现属性分离:对抗式训练、特征工程以及创新的网络结构设计。相比之下,文章提出了一种简单但稳定的数据驱动方法。具体来说,我们设计了一条数据生成流程,用于构建高质量的数据对,这些数据对在保持完全相同语言内容的同时,在情绪、说话风格、口音、副语言特征等一个或多个属性上具有明显可区分的差异。通过在这样的数据对上训练模型,能够实现有效的属性解耦,使模型能够对输入语音的属性进行编辑。此外,通过多次迭代的“编辑”步骤,目标属性的强度可以被逐步增强或减弱。除了情绪、风格和副语言特征编辑之外,该方法可以扩展到其他任务,包括语速调整、语音去噪以及静音片段裁剪等。
主要贡献:
- Step-Audio-EditX,这是首个基于大语言模型(LLM)的开源音频模型,擅长富有表现力且可迭代的音频编辑,涵盖情绪、说话风格和副语言特征,并具备强大的 zero-shot TTS 能力。
- 实验结果表明,仅通过大间距(large-margin)数据的后训练,即可实现对情绪和说话风格的可控调节,无需额外的呈现建模或适配器模块。
- 使用大间距数据进行后训练不仅能够实现可迭代的控制与高度的表达能力,而且在跨说话人场景下同样有效,这标志着从传统的基于表征层的解耦方法向新的范式转变。
Architecture
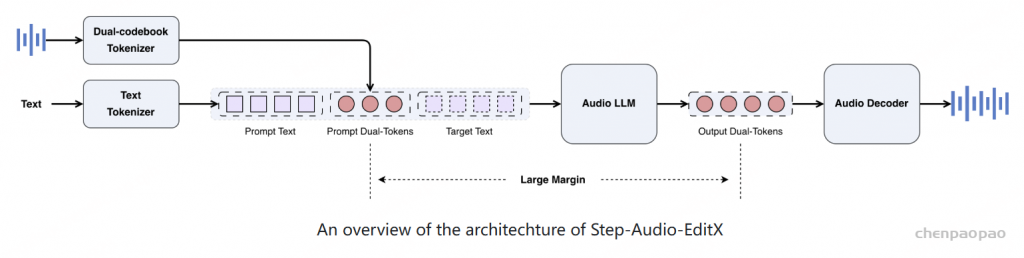
Target Text:带合成的音频文本
基于 Step-Audio 中的音频编辑合成模型,主要改进包括扩展了情感和语音风格的范围,增加了零样本文本转语音 (TTS) 和副语言编辑功能,并将模型参数从 130B 减少到 3B。
系统由三个主要组件组成:
- 双码本音频分词器:将参考音频或输入音频转换为离散的 token;
- 音频大语言模型:生成双码本 token 序列;
- 音频解码器:使用流匹配(flow matching)方法,将音频 LLM 预测的双码本 token 序列转换回音频波形。
Audio Tokenizer:采用并行语言分词器(16.7 Hz,1024 码本)和语义分词器(25 Hz,4096 码本),交错比例为 2:3。观察到双码本分词器能够保留大量情感、韵律及其他非语言信息,这表明该方法在信息解耦方面仍不够理想,这一不足恰好使其非常适合作为验证LLM 后训练策略及所提出的大间隔数据驱动方法有效性的实验对象。
Audio LLM:为了充分利用预训练文本 LLM 的强大语言处理能力,3B 模型首先使用基于文本的 LLM 进行初始化,然后在文本数据与音频双码本token以 1:1 比例混合的数据集上进行训练。音频 LLM 以聊天格式处理文本token及其对应的双码本音频token,最终生成双码本token作为唯一输出。
Audio Decoder:音频解码器由 Flow Matching 模块和 BigVGANv2声码器组成。Flow Matching 模块在输出音频令牌、参考音频以及说话人嵌入(speaker embedding)作为条件下生成 Mel 频谱图,而 BigVGANv2 声码器则进一步将 Mel 频谱图转换为音频波形。对于 Flow Matching 模块,采用扩散变换器(DiT)作为骨干网络,并在 20 万小时高质量语音上训练该模型。
Data
SFT 数据:零样本 TTS、情感编辑、说话风格编辑以及副语言编辑。
- 零样本文本转语音:中文和英文以及少量粤语四川话的内部数据,总计约 60,000 个独立说话人
- 情感与说话风格编辑:高质量数据难以收集,提出简单高效的大边距合成数据方法。
该方法在同一说话人之间进行零样本语音克隆,覆盖不同的情感和说话风格,同时确保对比样本对之间具有足够大的差距。仅需 每种情感或风格的一个提示音频片段,避免了昂贵的数据收集成本。此外,该方法巧妙地将复杂的情感与风格描述 转换为基于比较的样本对构建格式。具体方法如下:
- 声优录音:声优录制表达丰富的情感和说话风格。对于每位声优,每种情感和风格组合录制约 10 秒 的音频片段。
- 零样本克隆:对于每种情感和说话风格,构建三元组 ⟨文本提示, 中性音频, 情感/风格音频⟩。通过选择同一说话人的对应中性与情感/风格音频作为提示音频,并使用 StepTTS 语音克隆接口 处理,文本指令描述目标属性。
- 边距评分(Margin Scoring):为评估生成的三元组,我们使用一个小型人工标注数据集训练评分模型。该模型对音频对进行 1-10 分评分,边距分数越高表示效果越理想。
- 边距选择(Margin Selection):根据边距评分阈值筛选样本。该阈值会根据不同情感和风格进行调整,通用下限设为 6 分。
3. 副语言编辑(Paralinguistic Editing)
副语言 如呼吸、笑声以及填充停顿(例如“嗯”),对于提升合成语音的自然度和表现力至关重要。通过使用 “半合成”策略 实现了副语言编辑能力,该策略利用 NVSpeech 数据集——一个表现力丰富的语音语料库,其对多种副语言类型进行了详细标注,从而使得构建用于模型训练的比较四元组成为可能。
四元组 ⟨text_without_tags, audio_without_tags, text_nv_source, audio_nv_source⟩ 的构建方式不同于三元组:它使用 NVSpeech 的 原始音频和转录文本 作为目标输出,而将通过 StepTTS 语音克隆生成的音频作为输入,该音频是基于去除副语言标注后的原始转录文本合成的。
由于副语言编辑是 在时间域上进行的编辑任务,且存在显著的内在边距差异,因此 数据选择不需要边距评分模型。只需一小部分四元组数据,即可有效激发模型的副语言编辑能力。
强化学习数据:基于人工标注,以及使用 LLM-as-a-Judge(大型语言模型作为评判) 方法
人工标注:收集用户提供的真实世界的 提示音频 及对应文本提示,然后使用 SFT 模型生成 20 个候选响应。接着,通过人工标注员根据 正确性、韵律和自然度 对每个响应进行 5 分制评分,构建 选择/拒绝对。仅保留评分边距大于 3 的样本对。
LLM-as-a-Judge:使用理解能力模型对模型响应的 情感和说话风格编辑 进行 1-10 分评分,再根据评分生成偏好对,并仅在最终数据集中保留 评分边距大于 8 分 的样本对。
经过筛选的大边距样本对将用于训练 奖励模型 和 PPO
训练
两阶段:SFT,然后进行 PPO
SFT 阶段通过在 聊天格式下使用不同系统提示来增强模型的零样本文本转语音合成与编辑能力。
- 在零样本 TTS 任务中,提示音频被编码为 双码本tokens,随后将其解码为字符串形式,并嵌入到系统提示的说话人信息中。待合成文本作为 用户提示,生成的双码本 tokens 则作为系统响应返回。
- 对于编辑任务,所有操作在统一的系统提示下定义。用户提示包含 原始音频 及编辑操作的描述性指令,系统响应则返回 编辑后的音频 tokens。
模型在 SFT 阶段训练 1 个 epoch,学习率范围从 1 × 10⁻⁵ 到 1 × 10⁻⁶。
强化学习用于提升模型在 零样本 TTS 的稳定性,以及在执行编辑指令时的能力和表现力。当 源提示音频与目标编辑输出在情感或风格上存在显著差异 时,这种提升尤为明显,例如将快乐语音生成悲伤语音,或将高音量语音转换为耳语。
该强化学习方法提供了一种新的思路:不再单纯追求理想的语音表示解耦,而是同时优化大边距样本对的构建与奖励模型的评估效果。
奖励模型从 3B SFT 模型 初始化,并使用 人工标注数据与 LLM-as-a-judge 生成的大边距数据 进行训练,优化方法采用 Bradley-Terry 损失。
- 模型为 token 级奖励模型,直接在大边距双码本 token 对上训练,无需在奖励计算过程中通过音频解码器将 token 转回波形。
- 模型训练 1 个 epoch,学习率采用 余弦衰减策略(cosine decay),初始值为 2 × 10⁻⁵,下限为 1 × 10⁻⁵。
PPO 训练:获得奖励模型后,使用 PPO 算法 进行进一步训练。训练使用与奖励模型训练相同的提示种子,但只选择 对 SFT 模型最具挑战性的提示。
- 在 PPO 阶段,critic 先预热 80 步,随后再训练执行者(actor)。
- 优化器初始学习率为 1 × 10⁻⁶,遵循余弦衰减策略,下限为 2 × 10⁻⁷。
- 使用 PPO 剪切阈值 ϵ = 0.2,并施加 KL 散度惩罚系数 β = 0.05。
Evaluation
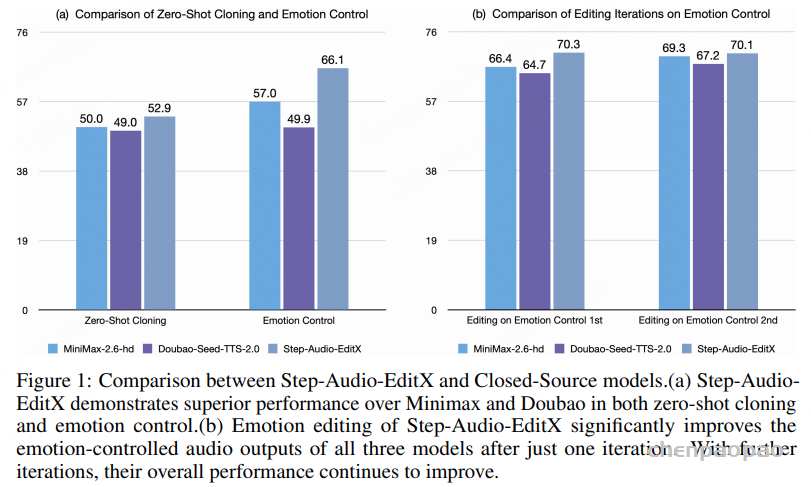
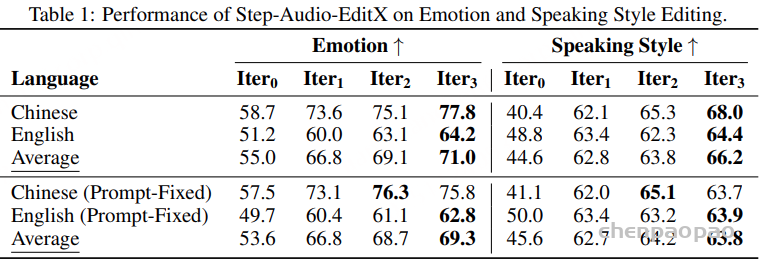
情感与说话风格编辑结果: 如表 1 所示,在 Iter0 音频进行首次编辑后,情感和说话风格的准确率都有显著提升。此外,经过连续迭代编辑后,情感和说话风格的准确率进一步增强。
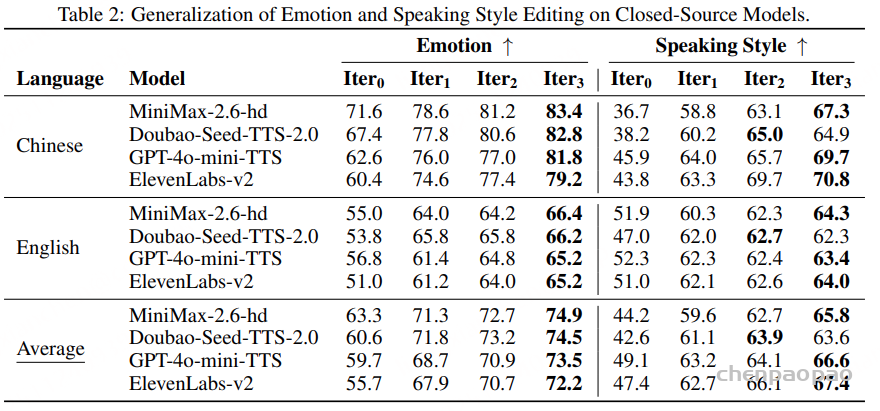
闭源模型上的泛化能力:Step-Audio-EditX 首次编辑 后,所有声音模型的情感和风格准确率均显著提升。经过接下来的两轮迭代,准确率进一步增强,从而有力证明了本模型的 强泛化能力。
闭源模型上的情感控制,Step-Audio-EditX 在零样本克隆能力下展现出 更高的情感准确率,优于其他两款模型。仅经过 一次编辑迭代,所有音频样本的情感准确率均显著提升。将一次情感编辑迭代应用于零样本克隆音频,其效果 超过了闭源模型原生情感控制功能生成的结果。
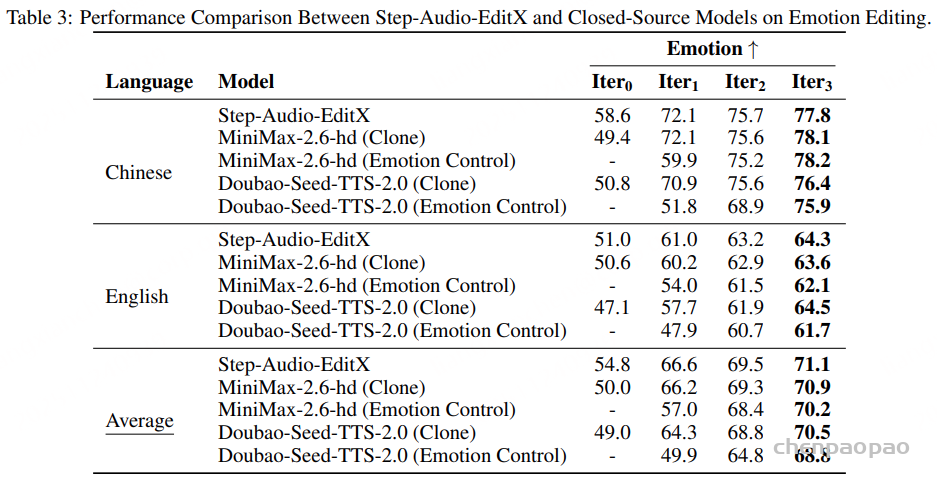
副语言编辑: 如表 4 所示,在仅进行一次编辑迭代后,通过加入副语言标签(paralinguistic tags),模型在副语言元素的重建与插入方面取得了显著性能提升。实验结果表明:经过一次 Step-Audio-EditX 的副语言编辑后,生成的副语言效果已经可与闭源模型使用原生副语言标签直接合成的结果相媲美,展现出强大的泛化能力与编辑一致性。
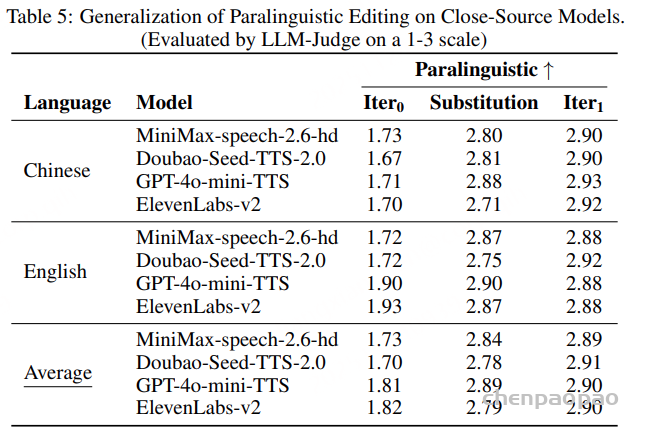
扩展能力:
语速编辑:构造了三元组⟨text, audiosource, audiofaster/slower⟩,其中针对同一说话人,通过 SoX 工具包 的受控速度扰动生成快/慢版本音频。由于语速变化会显著改变 token 序列长度,仅使用 SFT 即可实现有效的语速编辑。
去噪与静音剪裁:基于生成式的方法,实现提示音频和合成音频的定向编辑,包括去噪和静音剪裁。
去噪(Denoising)构造三元组:⟨text, audioaugment, audiosource⟩其中 audiosource 为干净音频(ground truth),audioaugment 通过添加噪声与混响模拟生成。
静音剪裁(Silence Trimming)构造三元组:⟨text, audiosource, audiotrimming⟩audiosource 含有静音片段,audiotrimming 则通过 Silero-VAD 提取语音区间后拼接生成。