
Qwen3.5-Omni 是 Qwen 最新一代全模态大模型,支持文本、图片、音频、音视频理解。结构上,Qwen3.5-Omni 的 Thinker 与 Talker 均采用 Hybrid-Attention MoE 架构。Qwen3.5-Omni 系列包含 Plus、Flash、Light 三种尺寸的 Instruct 版本,支持 256k 长上下文,模型支持超过 10 小时的音频输入及超过 400 秒的 720P(1 FPS)音视频输入。模型在海量文本、视觉以及超过 1 亿小时的音视频数据上进行原生多模态预训练,该模型展现出卓越的全模态感知与生成能力。相比 Qwen3-Omni,Qwen3.5-Omni 多语言能力大大增强,能够支持 113 种语种和方言的语音识别和 36 种语种和方言的语音生成。
- 论文标题: Qwen3.5-Omni Technical Report
- 论文链接: https://arxiv.org/abs/2604.15804v1
- 代码链接: https://modelscope.cn/studios/Qwen/Qwen3.5-Omni-Demo
Qwen3.5-Omni 延续采用 Thinker-Talker 架构,Thinker 通过 Vision Encoder 和 AuT 接受视觉和音频信号输入,音视频信号通过 interleave 交织并搭配 TMRoPE 编码位置信息。Thinker 负责处理全模态信号并输出文本,Talker 负责接收来自 Thinker 的多模态输入以及文本输出,进行 contextual 语音生成,语音表征通过 Qwen3-Omni 提出的 RVQ 编码来替代繁重的 DiT 运算。由于 chunk-wise 的流式输入设计和流式 Talker 设计,整个模型可以进行 realtime interaction。不同于上一代 Qwen3-Omni 的双轨 Talker 输入,Talker 在输入的组织方式上采用了 ARIA(自适应速率交错对齐,Adaptive Rate Interleave Alignment)来动态对齐文本与语音单元,然后进行交错排布,以避免由于文本与语音 Token 编码效率差异导致的语音不稳定性,如漏读、误读或数字发音模糊等问题。
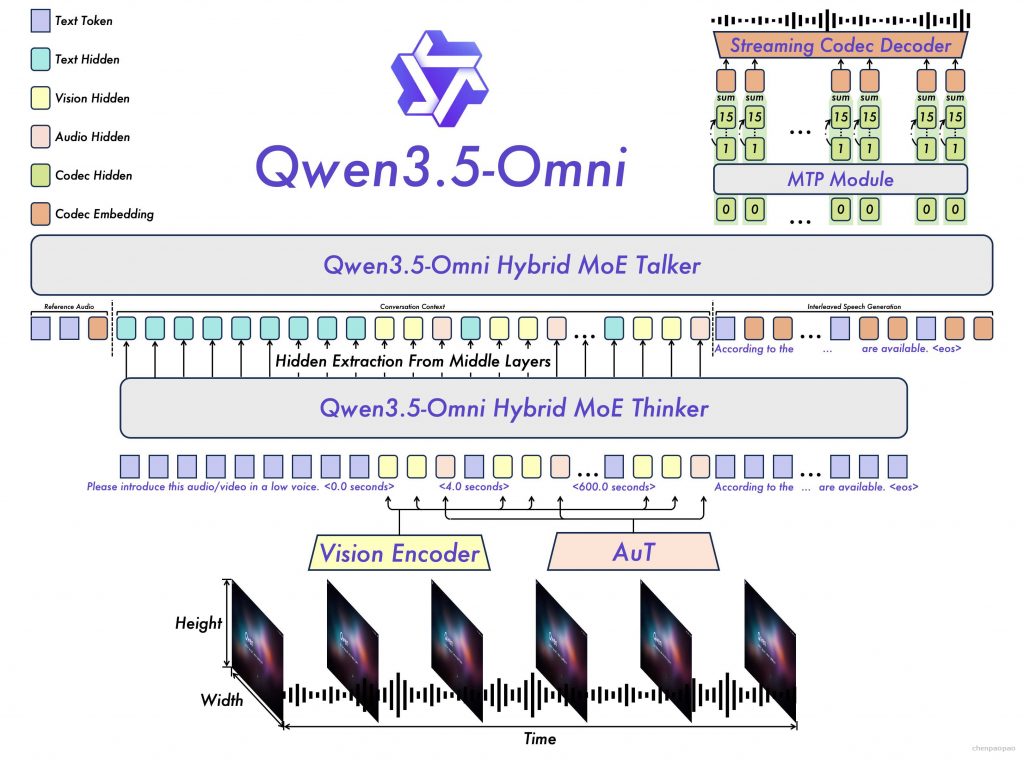
论文最重要的结论可以概括为三点:第一,模型规模扩展到数千亿参数级,并支持 256k 上下文;第二,训练使用了异构图文数据和超过 1 亿小时的音视频数据;第三,Qwen3.5-Omni-Plus 在 215 个音频与音视频理解、推理、交互子任务上达到强竞争力,尤其在音频理解、ASR、语音翻译和语音生成上表现突出。
1. 模型定位:从多模态理解走向全模态交互
Qwen3.5-Omni 处理的输入包括文本、图像、音频、无声视频和带音频的视频,输出则覆盖文本和流式语音。论文强调它是“native omni agent model”:模型不仅能感知和回答,还能进行 WebSearch、FunctionCall、实时语音交互和 Audio-Visual Vibe Coding,也就是从音视频指令中直接生成可执行代码。
从输入建模上看,不同模态会被转换为统一 token 序列。可以把它抽象为:
\( X = [x_{\mathrm{text}};\ f_{\mathrm{audio}}(a);\ f_{\mathrm{vision}}(v)] \)其中 \(f_{\mathrm{audio}}\) 是 AuT 音频编码器,\(f_{\mathrm{vision}}\) 是视觉编码器,Thinker 在统一序列上生成文本级高层表示,Talker 再基于 Thinker 的输出生成流式语音 token。
2. 模型设计:Thinker-Talker + Hybrid MoE
Qwen3.5-Omni 延续 Qwen2.5-Omni 和 Qwen3-Omni 的 Thinker-Talker 架构,但在可扩展性、长上下文和流式语音上做了明显升级。
- Thinker:负责文本生成和跨模态理解。它接收文本、音频、图像、视频的统一表示,并支持 chunk-wise streaming input processing。
- Talker:负责语音生成。它接收 Thinker 的高层表示和当前轮文本输出,生成 RVQ codec token,再由 Code2Wav 渲染为波形。
- Hybrid Attention MoE:Thinker 和 Talker 都采用 Hybrid MoE Transformer。论文特别提到其中的 Gated Delta Net 有助于长音视频序列建模,降低 KV-cache I/O 压力,提高吞吐和并发。
- 长上下文能力:模型输入支持 256k token,约等价于超过 10 小时音频,或 400 秒 720P 视频(1 FPS)。
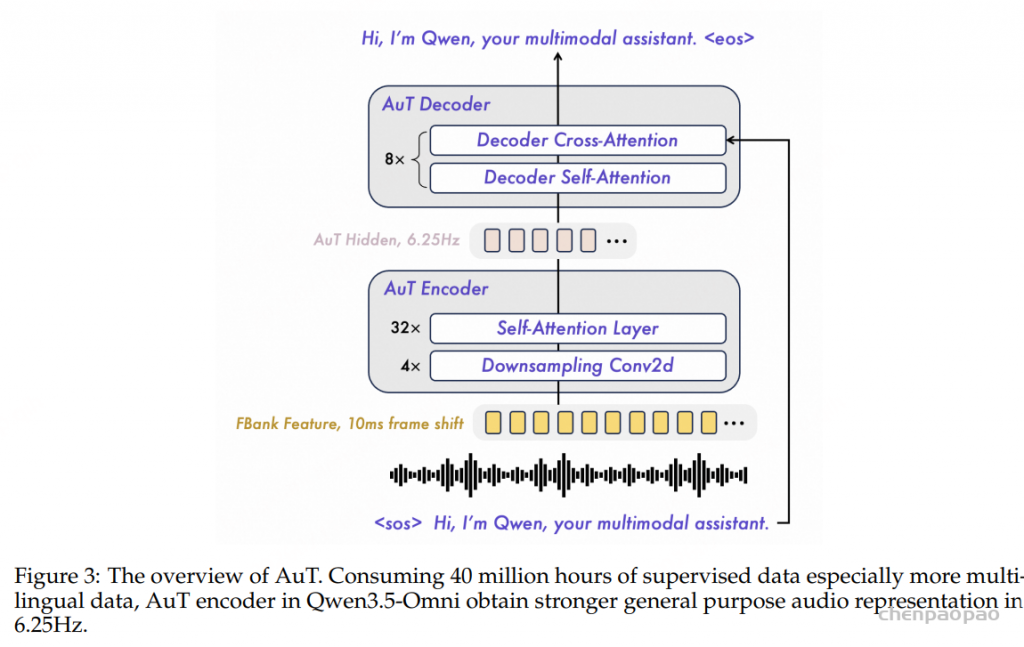
在感知端,文本使用 Qwen3.5 tokenizer,词表从 150k 扩到 250k,论文称多数语言的编解码效率提升 10% 到 60%。音频被重采样到 16kHz,转成 128 通道 Mel 频谱,使用 25ms 窗口和 10ms hop。AuT 音频编码器从头训练,使用 40M 小时音频文本对,经过 4 个 Conv2D block 下采样 16 倍,输出约 6.25Hz 的音频 token,也就是每个输出帧约对应 160ms 原始音频。
在视频和音视频同步上,论文不再只依赖稀疏的绝对时间位置 ID,而是在每个视频或音视频 temporal patch 前插入秒级 timestamp 文本,并在音频序列中随机插入 timestamp。这会略微增加上下文长度,但能让模型更自然地学习时间码,尤其适合长视频和长音频场景。
3. ARIA:解决流式语音中的文本-语音速率错配
论文中最值得关注的创新之一是 ARIA(Adaptive Rate Interleave Alignment)。在流式语音生成中,文本 token 和语音 codec token 的编码效率不同。如果二者对齐不好,就容易出现跳词、发音错误、数字读法混乱、语音不自然等问题。
Qwen3.5-Omni 不再采用固定 interleaving 速率,也不依赖 MFA 这类外部对齐,而是把文本和语音 token 统一到一个单通道交错序列中,并施加自适应速率约束。可简化表示为:
\( \frac{N_{\mathrm{speech}}(y_{\le t})}{N_{\mathrm{text}}(y_{\le t})} \le \frac{N_{\mathrm{speech}}(y)}{N_{\mathrm{text}}(y)} \)这里 \(y_{\le t}\) 表示当前生成前缀,\(N_{\mathrm{speech}}\) 和 \(N_{\mathrm{text}}\) 分别表示前缀中的语音 token 数和文本 token 数。直观理解是:任何前缀中的语音生成进度都不能跑得比该样本整体文本-语音比例更快。这样既保留流式输出,又减少双轨同步开销。
Talker 的语音 codec 采用 RVQ 多码本表示,并通过 MTP 模块预测当前帧的残差码本。可以抽象为:
\( P(c_t^1,\ldots,c_t^K \mid c_{<t}, h) = \prod_{k=1}^{K} P(c_t^k \mid c_t^{<k}, c_{<t}, h) \)其中 \(h\) 是 Thinker 提供的上下文表示,\(c_t^k\) 是第 \(t\) 帧第 \(k\) 个 codec codebook token。随后 causal ConvNet 逐帧把 codec token 转为波形,从而支持低延迟流式合成。
4. 数据与训练流程
Qwen3.5-Omni 的训练覆盖纯文本、图文、视频文本、音频文本、视频音频和视频音频文本等数据。论文披露了几个关键规模:
- 总体使用超过 1 亿小时音视频内容。
- AuT 音频编码器使用 40M 小时音频文本对训练,由 Qwen3-ASR 生成监督信号。
- Talker 初始阶段使用超过 20M 小时多语言语音数据,并配合多模态上下文。
- 第二阶段预训练使用约 4T token,其中 text 0.92T、audio 1.99T、image 0.95T、video 0.14T、video-audio 0.29T。
- 支持范围:文本 201 种语言/变体,语音输入 113 种语言/方言,语音输出 36 种语言/方言。
预训练分为三阶段。S1 是 Encoder Alignment,冻结 LLM,分别训练视觉和音频编码器及 adapter;S2 是 General Stage,解冻所有参数,用多模态混合数据训练,序列长度为 32,768;S3 是 Long Context Stage,把最大长度提升到 262,144,并提高长音频、长视频占比。
后训练也分 Thinker 和 Talker。Thinker 使用三阶段策略:专门教师模型蒸馏、on-policy distillation,以及面向多轮交互的强化学习。Talker 使用四阶段策略:通用训练、长上下文 CPT、DPO/GSPO 偏好优化,以及轻量 speaker fine-tuning,用于增强自然度、表现力、语音可控性和零样本/定制音色能力。
5. 流式延迟与并发
论文给出了端到端首包延迟。单并发下,Qwen3.5-Omni-Flash 的音频输入首包延迟为 235ms,视频输入为 426ms;Qwen3.5-Omni-Plus 分别为 435ms 和 651ms。8 并发下,Flash 的音频/视频整体延迟为 352ms/1625ms,Plus 为 955ms/1980ms。
需要注意,论文明确说明 Flash 和 Plus 因模型规模、部署资源和并行策略不同,不适合做严格横向延迟比较。更关键的结论是:ARIA、chunked prefilling、MTP 和 streaming ConvNet 共同把首包语音延迟控制在可交互范围内。
6. 实验结果:理解能力基本不牺牲,音频能力明显增强
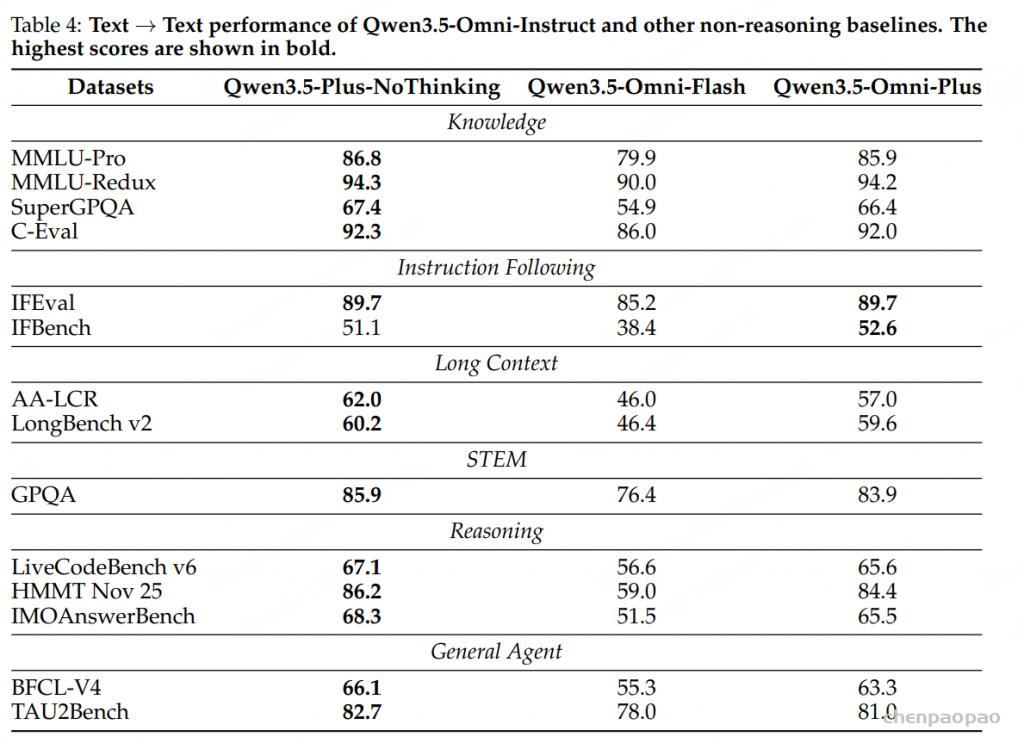
文本能力:Qwen3.5-Omni-Plus 基本保持了 Qwen3.5-Plus-NoThinking 的文本能力。比如 MMLU-Pro 为 85.9 vs 86.8,MMLU-Redux 为 94.2 vs 94.3,C-Eval 为 92.0 vs 92.3,LiveCodeBench v6 为 65.6 vs 67.1。值得注意的是 IFBench 上 Omni-Plus 为 52.6,略高于文本基线的 51.1。
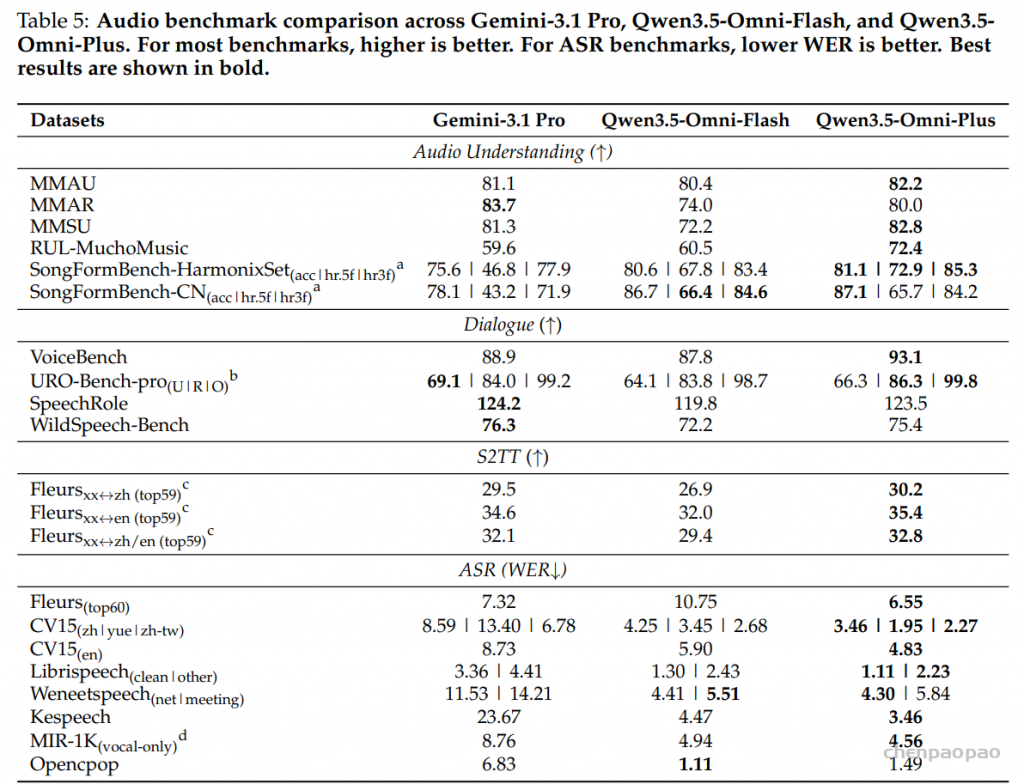
音频理解与 ASR:与 Gemini-3.1 Pro 相比,Qwen3.5-Omni-Plus 在多个音频任务上更强。MMAU 为 82.2 vs 81.1,MMSU 为 82.8 vs 81.3,RUL-MuchoMusic 为 72.4 vs 59.6,VoiceBench 为 93.1 vs 88.9。ASR 方面,Fleurs top60 WER 为 6.55,低于 Gemini-3.1 Pro 的 7.32;LibriSpeech clean/other 为 1.11/2.23,也明显低于 3.36/4.41。
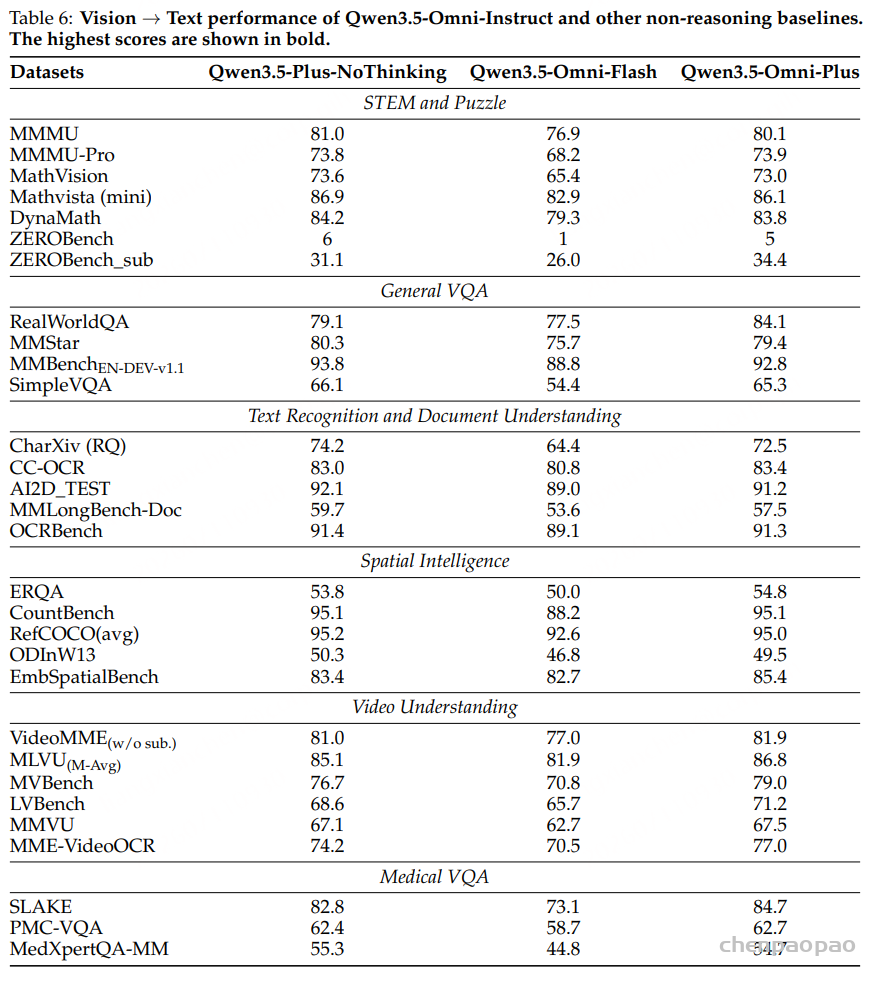
视觉与视频:Qwen3.5-Omni-Plus 在视觉任务上接近 Qwen3.5 文本/视觉基线,并在部分视频任务上更好。例如 RealWorldQA 为 84.1,高于基线 79.1;VideoMME w/o subtitles 为 81.9,高于 81.0;MLVU 为 86.8,高于 85.1;LVBench 为 71.2,高于 68.6。这说明音视频联合训练没有明显损伤视觉能力,反而增强了动态视觉场景的表现。
音视频理解:在 AudioVisual → Text 任务中,Qwen3.5-Omni-Plus 在 DailyOmni 上达到 84.6,高于 Gemini-3.1 Pro 的 82.7;Qualcomm IVD 为 68.5,高于 66.2;Omni-Cloze 为 64.8,高于 57.2。但它在 WorldSense、AV-SpeakerBench、VideoMME with audio 和 OmniGAIA 上仍低于 Gemini-3.1 Pro,说明音视频综合推理和工具使用仍有改进空间。
语音生成:在 SEED-TTS 零样本语音生成中,Qwen3.5-Omni-Plus 的 WER 为 test-zh 0.99、test-en 1.26,优于 Qwen3-Omni-30B-A3B 的 1.07/1.39,也在英文子集上超过 CosyVoice 3 的 1.45。多语言语音生成中,论文称 Qwen3.5-Omni 在 29 个评测语言中有 22 个取得最低 WER,并在多数语言上有更高 speaker similarity。
跨语言与定制音色:跨语言语音生成中,Qwen3.5-Omni 在 12 个方向中 10 个最好。比如 Chinese-to-Korean 错误率为 4.03,而 CosyVoice3 是 14.4,相对降低约 72%。定制音色方面,论文在 2026 年 3 月通过官方 API 对比 ElevenLabs、Gemini-2.5 Pro-Preview-TTS、GPT-Audio-2025-08-28 和 MiniMax-Speech-2.8-HD,Qwen3.5-Omni 在 29 种语言中有 10 种取得最佳 WER,并在日语、韩语等场景表现突出。
7. 关键创新点
- 全模态 Agent 化:模型不只回答问题,还能执行 WebSearch、FunctionCall,并展现 Audio-Visual Vibe Coding 能力。
- Thinker-Talker 的 MoE 升级:Thinker 和 Talker 都采用 Hybrid MoE,兼顾长上下文、多模态建模和服务并发。
- ARIA 对齐机制:用自适应文本-语音速率约束替代固定对齐,改善流式语音的稳定性、韵律和发音自然度。
- 多码本流式语音生成:RVQ token、MTP 和 causal ConvNet 组合,让语音可以从首个 codec frame 开始增量合成。
- 时间戳显式建模:在音视频 patch 中插入文本 timestamp,提升长视频、长音频的时间感知和跨模态同步。
- 大规模多语言训练:覆盖 113 种语音输入语言/方言和 36 种语音输出语言/方言,扩展了 ASR、TTS、跨语言 voice cloning 的边界。
8. 局限
这篇技术报告给出了大量指标,但仍有几个需要谨慎理解的地方。第一,Qwen3.5-Omni-Plus 和 Flash 的延迟数字不适合严格横比,因为部署资源和并行策略不同。第二,音视频综合任务并非全面领先 Gemini-3.1 Pro,尤其 WorldSense、AV-SpeakerBench、VideoMME with audio 和 OmniGAIA 仍有差距。第三,模型训练数据规模很大,但数据构成和过滤细节仍是技术报告级披露,不等于完全可复现。
总体来看,Qwen3.5-Omni 的意义在于把全模态模型从“看图、听音、回答”推进到“实时听看、连续说话、保持长上下文、能调用工具”的阶段。它的架构亮点不只是参数更大,而是通过 Hybrid MoE、ARIA、多码本 codec 和显式时间戳,把模型服务、流式交互和多语言语音生成这些工程难点一起纳入设计。