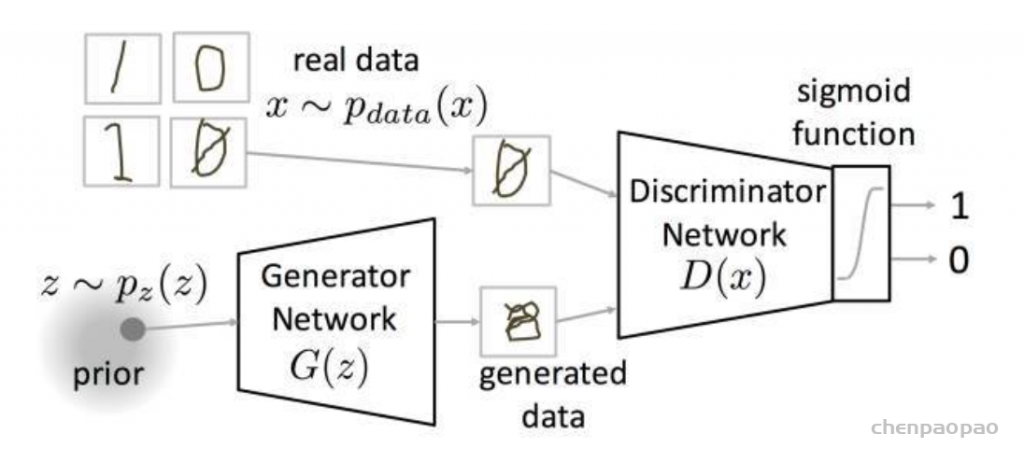
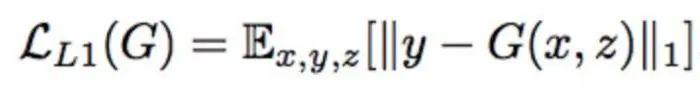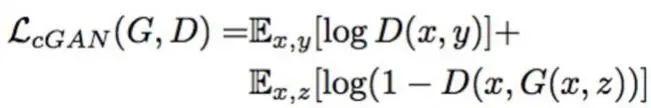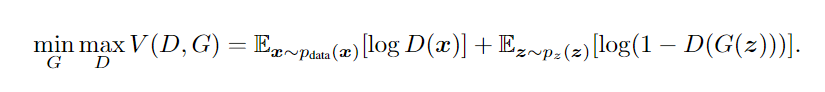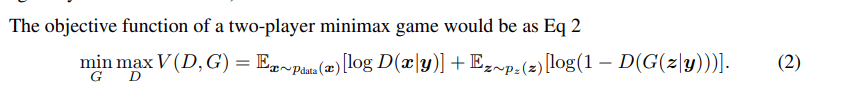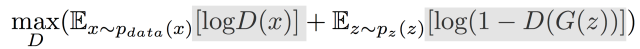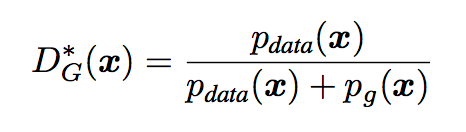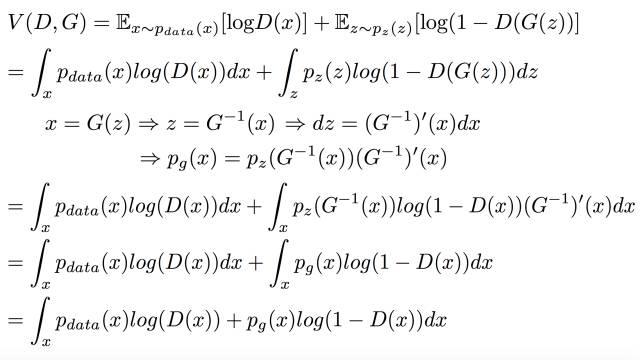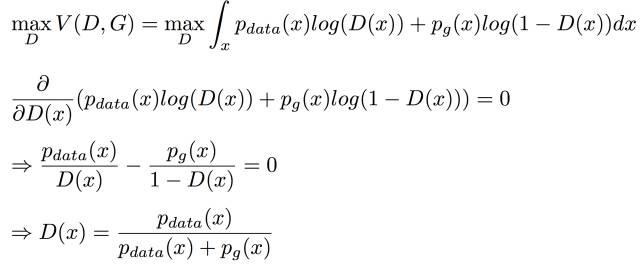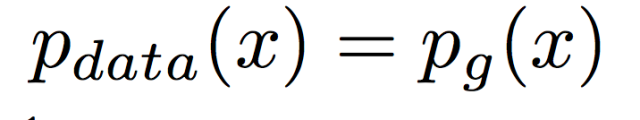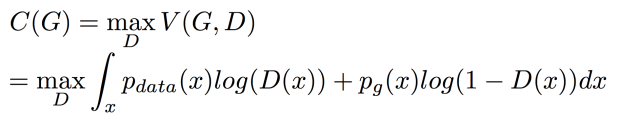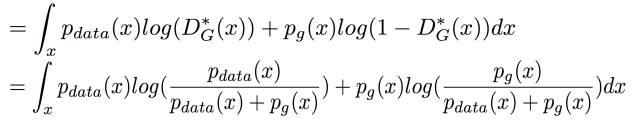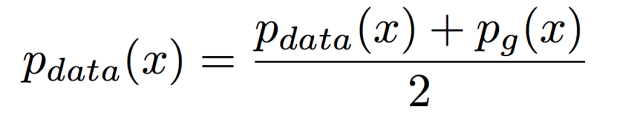摘自 https://zhuanlan.zhihu.com/p/306442363
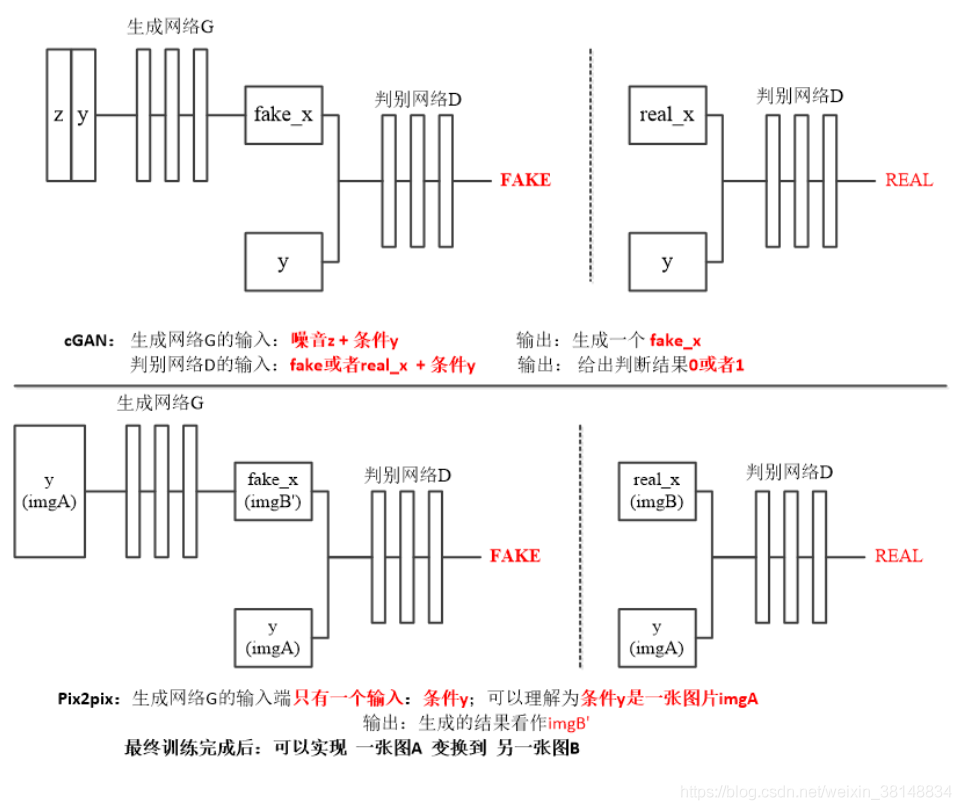
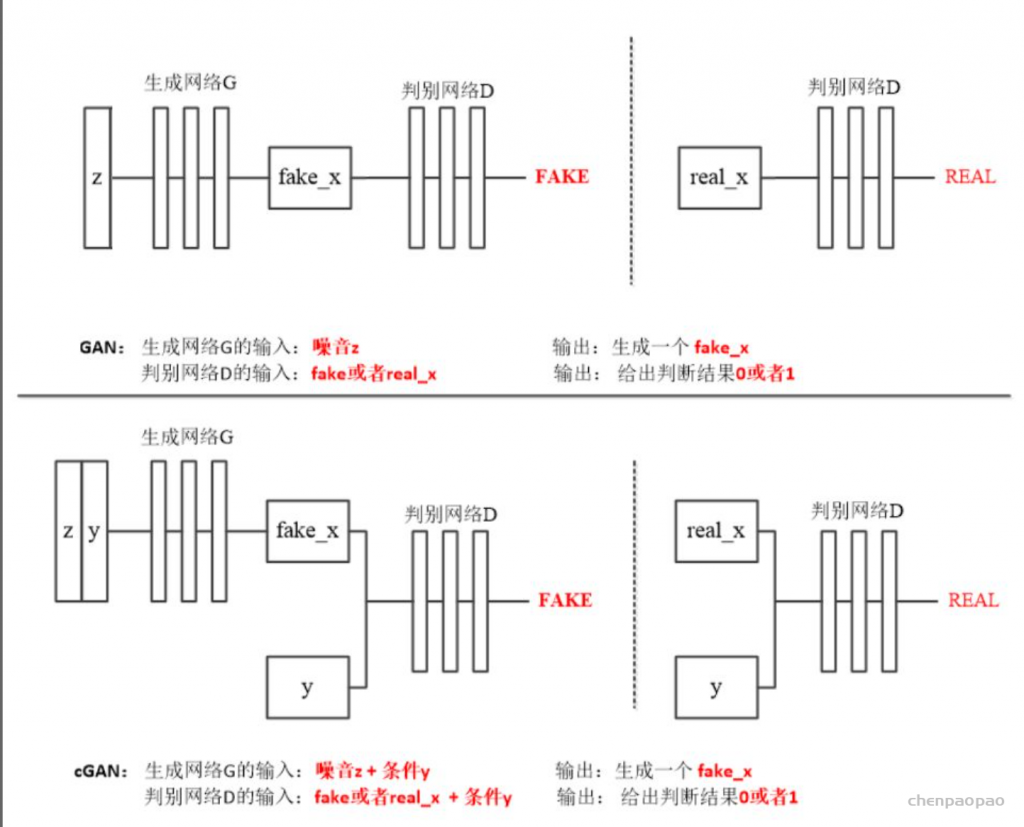
pixtopix需要一对一,一个image对应一个image,训练集的两组图片一一对应才能训练
CycleGAN的介绍
1.CycleGAN的原理
CycleGAN,即循环生成对抗网络,出自发表于 ICCV17 的论文《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》,和它的兄长Pix2Pix(均为朱大神作品)一样,用于图像风格迁移任务。以前的GAN都是单向生成,CycleGAN为了突破Pix2Pix对数据集图片一一对应的限制,采用了双向循环生成的结构,因此得名CycleGAN。
首先,CycleGAN也是一个GAN模型,通过判别器和生成器的对抗训练,学习数据集图片的像素概率分布来生成图片。
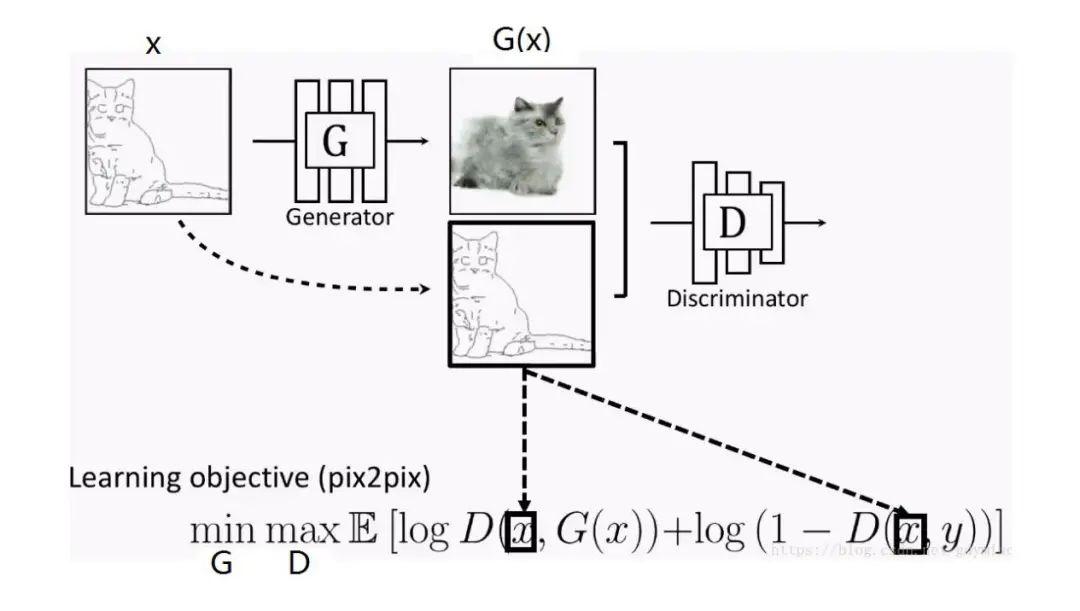
要完成X域到Y域的图片风格迁移,就要求GAN网络既要拟合Y域图片的风格分布分布,又要保持X域图片对应的内容特征。打个比方,用草图风格的猫图片生成照片风格的猫图片时,要求生成的猫咪“即要活灵活现,又要姿势不变”。“拟合数据分布”本来就是GAN干的活儿,而“保持原图片特征”在Pix2Pix上是这么实现的:
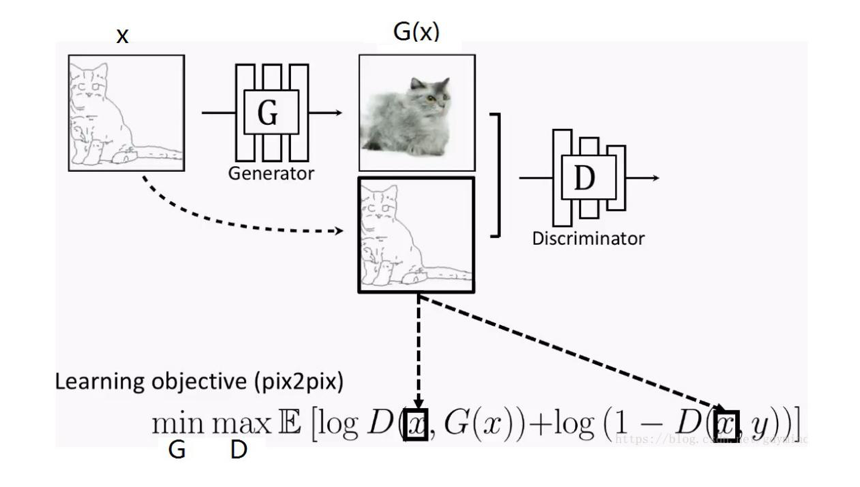
因为Pix2Pix是一个CGAN,所以,我们通过用X域图片当约束条件来限制Pix2Pix的输出Y域风格图片时保有X域图片的特征。
而送入CycleGAN的两组(X域Y域)图片没有一一对应关系,即使我们将X域图片当成限制条件输入到一个CGAN中,也起不到限制模型输出保有X域图片特征的作用。因为,送入的两组图片完全是随机配在一起,CGAN学不到任何联系。因此,CycleGAN采取了一个绝妙的设计:通过添加“循环生成”并优化一致性损失(Consistency Loss)来代替CGAN中使用的约束条件来限制生成器保有原域图片特征。这样就不需要训练集图片一一对应了。
2.CycleGAN的流程
下面,我们就来看看循环生成网络(CycleGAN)到底是怎么“循环起来”的:
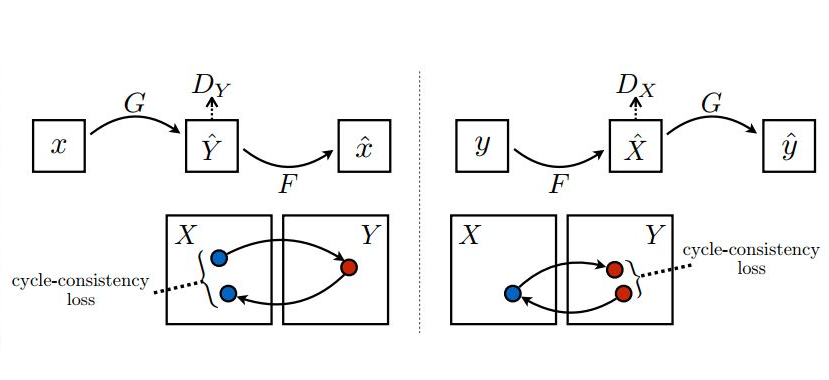
上图左半部分,将原域图片x送入(x2y方向)生成器G生成目标域图片y^,然后再将生成的目标域图片y^送入(y2x方向)生成器F反过来生成原域图片x^。生成x^的目的就是用它与输入的真图片x来算L1 Loss。我们知道Pix2Pix优化时除了使用GAN Loss(对抗损失)外,还加入了生成器输入图片和输出图片的L1 Loss来对齐生成图片与输入图片的宏观轮廓(所谓低频信息)。同样的逻辑,我们也能在CycleGAN中用L1 Loss来对齐“循环生成”的x^与输入的原图片x的内容自然,x生成的y^的轮廓也是和x对齐的了。这就达到了(原论文中的例子)“马变斑马,花纹变,姿势不变”的目的了。(我在网上看到的CycleGAN资料都没有点明这一点的,所以只好自行脑补,欢迎指正。)
在这个x->y^->x^的生成过程中,可以通过判别器Dy与生成器(x2y)G进行对抗训练。那么这个链条上的反向生成器(y2x)F怎么办?当然是加个判别器Dx与它进行对抗训练了。这样CycleGAN就有了两个方向相反的生成器,两个分别判别x域、y域图片的判别器。但要注意一个问题:就像GAN的生成器和判别器不能同时训练一样,Cyc1eGAN的两个生成器、两个判别器也只能一个一个训练,这就形成了CycleGAN训练的两条“环路”。
3.CycleGAN的结构
接下来,我们再看看这两对判别器、生成器怎么摆:
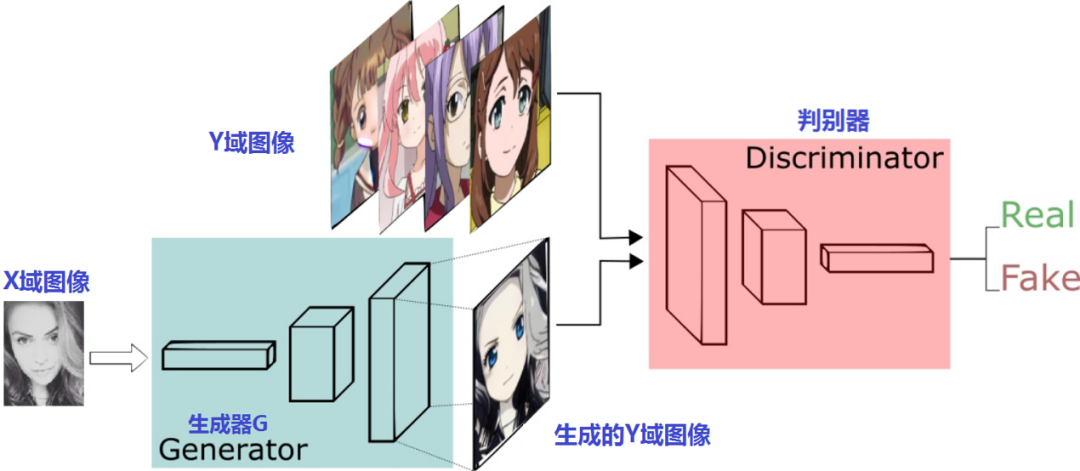
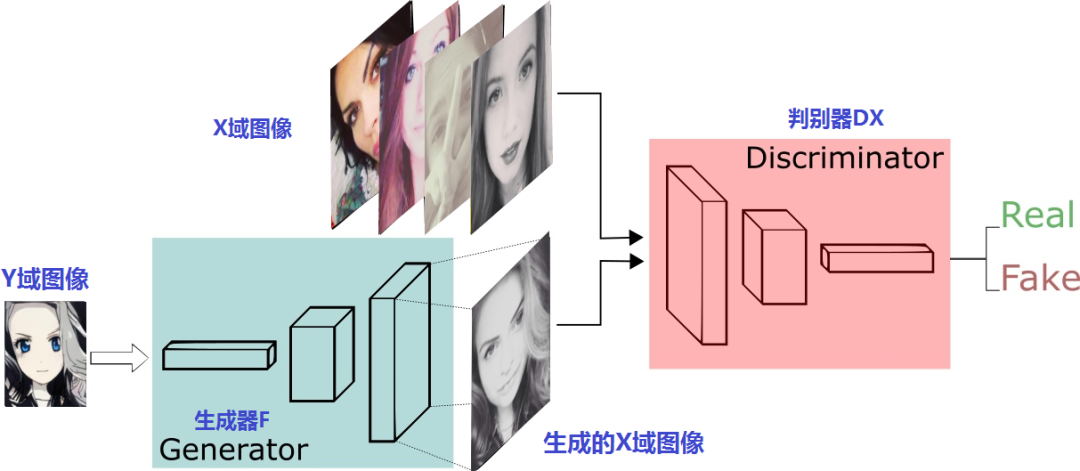
上半部份是生成器G和判别器Dy进行x2y的训练过程,下半部份是生成器F和判别器Dx进行y2x的训练过程。很像是两个风格迁移方向相反Pix2Pix模型,只是这两个GAN是普通GAN,不是Pix2Pix那样的CGAN。这一点,从生成器和判别器的输入就可以看出来,输入的只有原域图片并没有像Pix2Pix一样融合条件图片。
4.CycleGAN的loss函数
前面分析了CycleGAN的原理,我们已经知道了CycleGAN的loss由对抗损失(称为gan loss或adversarial loss)和循环一致性损失(consitency loss)组成,下面看看公式:
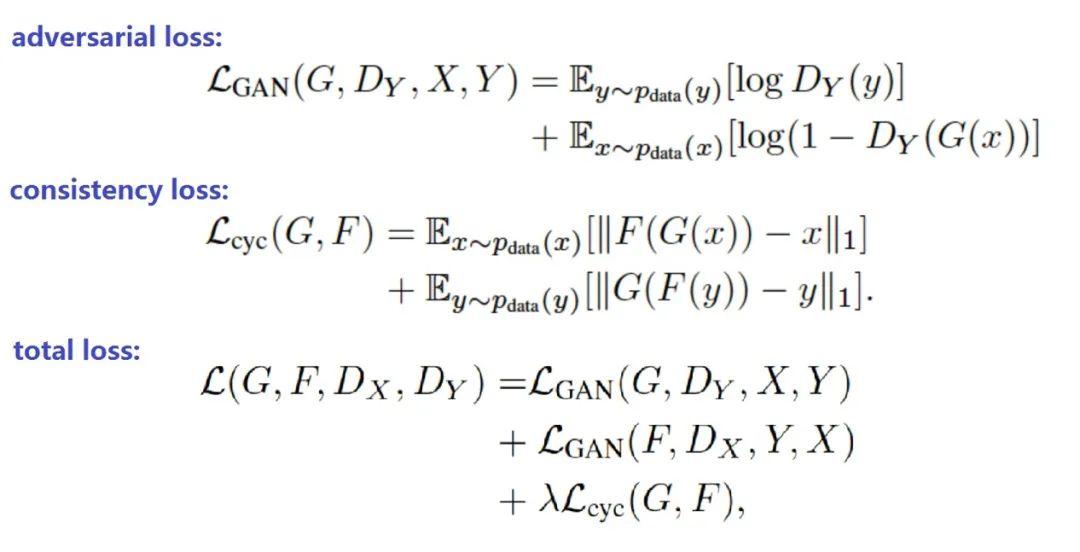
上面公式中:
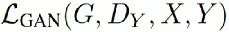
指的是x2y过程的对抗损失(adversarial loss)
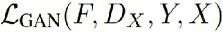
指的是y2x过程的对抗损失(adversarial loss)
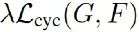
指的是生成器G和生成器F的循环一致性损失。
其中为循环一致性损失(consitency loss)的缩放系数,是一个超参数。
实际上,原论文的代码还加入了本体映射损失(identity loss),只是默认设置为关闭。CycleGAN正常训练时,生成器G输入x,生成y^。计算生成器G的本体映射损失(identity loss)时,生成器G输入y,生成y^,然后用y与y^的L1 loss作为G的identity loss。相应地,生成器F的identity loss则是输入的x与生成的x^的L1 loss。优化CycleGAN时,如果启用identity loss则将这两部分加到模型总loss中。与循环一致性损失(consistency loss)一样,也使用缩放系数超参控制其在总loss中所占比重。
论文中提到,CycleGAN使用identity loss的目的是在迁移的过程中保持原色调,下面是使用identity loss的对比效果:

上面图片最右边一列使用identity loss后果然纠正了生成器的色偏。
code: