
GAN只是拟合原数据集的像素概率分布,生成的样本并没有提供新的信息以优化模型的分类边界。我理解,样本插值还能优化一下分类边界,原始GAN充其量只能添加一点噪声,或许能增强一点模型泛化能力吧(真做数据增强还得InforGAN、styleGAN这样的才好,能通过潜空间插值对图像做高级语义的增强,这是后话。)。
原始GAN用起来也不方便,为了分别生成0~9的数字,得将原数据集按标签分为10组,每组用一个模型训练,一共需要10个模型。训练时由于每组的数据量少到原来的十分之一,也会发生因样本太少导致模型无法拟合的现象。所以,意欲降伏GAN的大神给原始GAN装了个钮,让GAN乖乖要啥给啥。这个带按钮的改进版就是CGAN。
CGAN(Conditional GAN)介绍
1、CGAN的原理
CGAN的全称是Conditional Generative Adversarial Nets,即条件生成对抗网络。故名思议,就是通过添加限制条件,来控制GAN生成数据的特征(类别)。
当我第一次了解了CGAN原理,我惊诧于它给GAN“加按钮”的方法竟然如此简单粗暴,要做仅仅就是“把按钮加上去”——训练时将控制生成类别的标签连同噪声一起送进生成器的输入端,这样在预测时,生成器就会同样根据输入的标签生成指定类别的图片了。判别器的处理也是一样,仅仅在输入加上类别标签就可以了。
那么,为什么加了标签,CGAN就乖乖听话、要啥给啥了呢?原理也是十分简单,我们知道GAN要干的就是拟合数据的概率分布,而CGAN拟合的就是条件下的概率分布。
GAN:
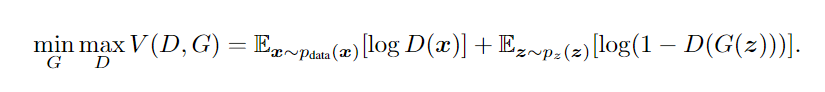
原生GAN中的概率全改成条件概率:
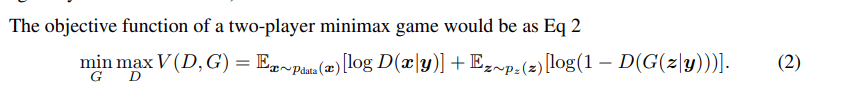
而上面CGAN公式中的条件y就是咱给GAN装的“钮”。加上了这个条件按钮,GAN优化的概率期望分布公式就变成了CGAN优化的条件概率期望分布公式。即CGAN优化的目标是:在条件Y下,在判别器最大化真实数据与生成数据差异的情况下,最小化这个差距。训练CGAN的生成器时要同时送入随机噪声z和和条件y(在本项目中y就是MNIST手写数字数据集的数字标签)。就是这么简单!
2、CGAN的结构
CGAN设计巧妙,而结构也十分简单、清晰,与经典GAN只有输入部分稍许不同。
我们看看原始GAN与CGAN的结构对比(包括生成器和判别器),上半部份的是经典GAN,下半部分是CGAN:
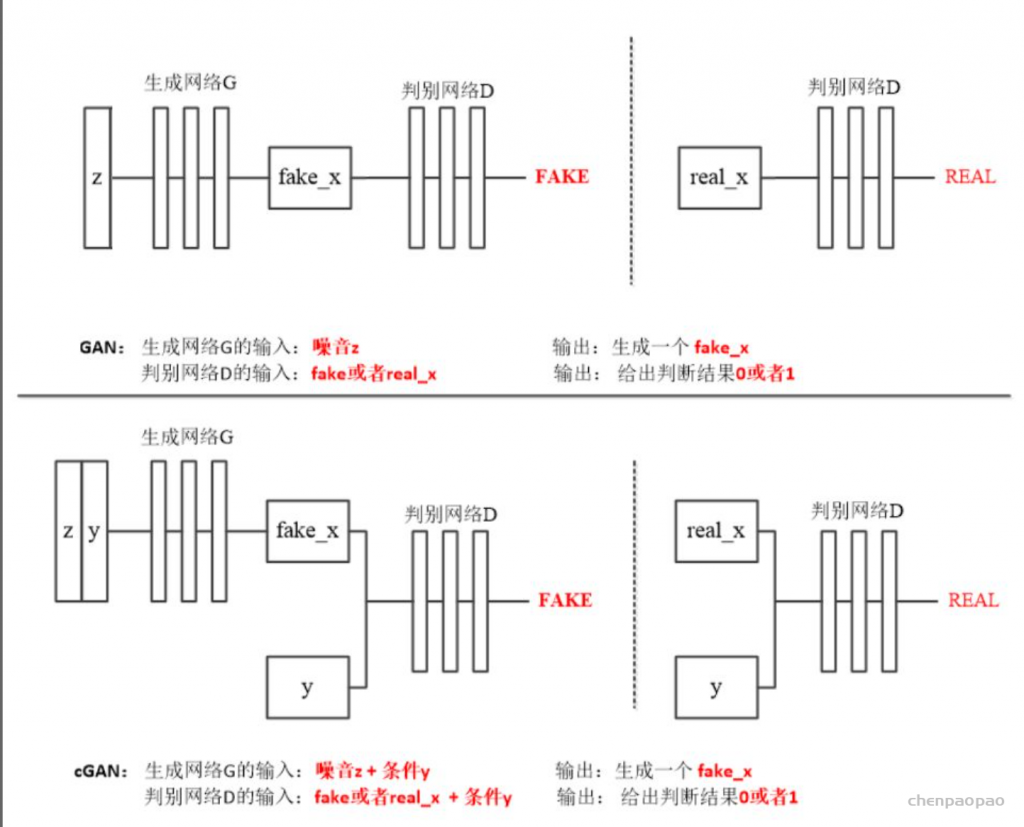
我们先回顾下经典GAN的结构流程(如上图上半部份所示):
- 训练判别器。将噪声z送入生成器,输出fake_x;将fake_x送入判别器,在更新判别器参数时尝试拉近判别器的输出与真标签1的距离,即最小化判别器输出与真标签1的交叉熵损失。再将真图片送入判别器,更新判别器参数时尝试拉近判别器的输出与假标签0的距离,即最小化判别器输出与假标签0的交叉熵损失。这个过程中,用真、“假”图片训练判别器的顺序不必需固定,真、假标签取值0、1也无需固定(可相反,效果没有区别)。要注意的是,训练判别器的过程中,只更新判别器参数,不更新生成器参数。
- 训练生成器。生成器训练的过程和判别器基本一样,只是将生成器输出的“假图片”送入判别器后,将判别器的输出与真标签(1)拉近。目的就是,使生成器参数更新的方向朝着“骗过判别器的目标”进行,也就是所谓“对抗过程”。当然判别器出掌(判别器更新参数)时,生成器不还手(生成器不更新参数),轮到生成器还手(生成器更新参数)时,判别器也得双手背后(判别器不更新参数)。不然就打成一团,谁也看不到招式(无法正确更新参数,提高生成能力)了
我们再看下CGAN给GAN加的“料”(如上图下半部份所示):
- 先看判别器。如图,无论是给判别器送入真图片还是生成器生成的假图片时,都要加上个“条件y”,也就是分类标签。判别器输出没有变化仍然只是判断输入图片的真假。老实说,当时我曾想:既然咱都conditional GAN了,这个判别器是不是要输出分类标签y来训练Condition那部分?但转念一想,不行,判别器还是得判别真假,不然没法和生成器对抗了。BUT,后来我发现还真有走这个路线的GAN,叫InfoGAN。这个InfoGAN给生成器配了两个判别器,一个判真假,一个分类别。
- 再看生成器。生成器的输入除了随机噪声z外,也加入了“条件y”。到这儿,我又想:既然有了条件标签,就不用输入噪声z了吧~。答案当然是,不行!因为,噪声z的维度是和生成器输出图片的尺寸、复杂度相关的。本项目中输出图片尺寸是28×28=784。按理说模型进行映射的输入、输出尺寸应该是相等的。但是输出图片只是手写数字,规律比较简单,输入的尺寸可以进行一定程度的压缩。一般噪声z的维度为几十到一百就能生成比较理想的图片细节,如果太低会导致生成器拟合能力不足,生成图片质量低下。条件z只是一个取值0~9的维度为一的向量,模型拟合像素概率分布的效果可想而知。后面我们介绍的Pix2Pix模型的输入是一张和输出尺寸相同的图片,就不再输入噪声z了。
CGAN需要注意的一点是:输入的条件标签y不但要在输入时与噪声z融合在一起,在生成器和判别器的每一层输入里都要与特征图相融合,才能让模型“学好条件y”。不然,标签可能不灵~