
CycleGAN、pix2pix、iGAN的主要贡献者最近在NIPS 2017上又推出了一篇文章Toward Multimodal Image-to-Image Translation(见https://junyanz.github.io/BicycleGAN/,https://arxiv.org/pdf/1711.11586.pdf),讨论如何从一张图像同时转换为多张风格不一成对的图像。
Pix2pix 和 CycleGAN 是非常的流行GAN,不仅在学术界有许多变体,同时也有许多基于此的应用。但是,它们都有一个缺点——图像的输出看起来几乎总是相同的。例如,如果我们要执行斑马到马的转换,被转换的同一马的照片将始终具有相同的外观和色调。这是由于GAN固有的特性,它学会过滤了噪声的随机性。
像pix2pix这样的图像转换(一对一)的方式是存在歧义的,因为不可能只对应一个输出。因此作者提出了一种一对多的输出,即将可能输出的图像是存在一定的分布特性的。

论文的主要方法如下图所示:

下图是 BicycleGAN 相关的模型和配置。图(a)是推理的配置,图像A与噪声相结合以生成图像B ^ ,可以将此看作是 cGAN 。在BicyleGAN中,形状为(256, 256, 3)的图像A是条件,而从潜在编码 z采样的噪声为大小为8的一维向量。图(b)是 pix2pix + 噪声 的训练配置。而图(c) 和 图(d) 的两个配置由 BicycleGAN 训练时使用:

简而言之,BicycleGAN 可以找到潜在编码z与目标图像B之间的关系,因此生成器可以在给定不同的z时学会生成不同的图像B ^ 。如上图所示,BicycleGAN 通过组合 cVAE-GAN 和 cLR-GAN 这两种模型来做到这一点。
cVAE-GAN
VAE-GAN 的作者认为,L1 损失并不是衡量图像视觉质量的良好指标。例如,如果图像向右移动几个像素,则人眼看起来可能没有什么不同,但会导致较大的L1损失。因此使用 GAN 的鉴别器来学习目标函数,以判断伪造的图像是否真实,并使用 VAE 作为生成器,生成的图像更清晰。如果忽略上图(c)中的图像 A ,那就是 VAE-GAN ,由于以 A 为条件,其成为条件 cVAE-GAN 。训练步骤如下:
- VAE 将真实图片 B编码为多元高斯分布的潜在编码,然后从它们中采样以创建噪声输入,此流程是标准的VAE工作流程;
- 使用图像 A 作为条件及从潜矢量 z 采样的噪声用于生成伪图像B ^
训练中的数据流为 B − > z − > B ^ ( 图(c) 中的实线箭头),总的损失函数由三个损失组成:
对抗损失 \(L_{GAN}^{VAE}\)
L1重建损失 \(L_{1}^{VAE}(G)\)
KL散度损失 \(L_{KL}(E)\)
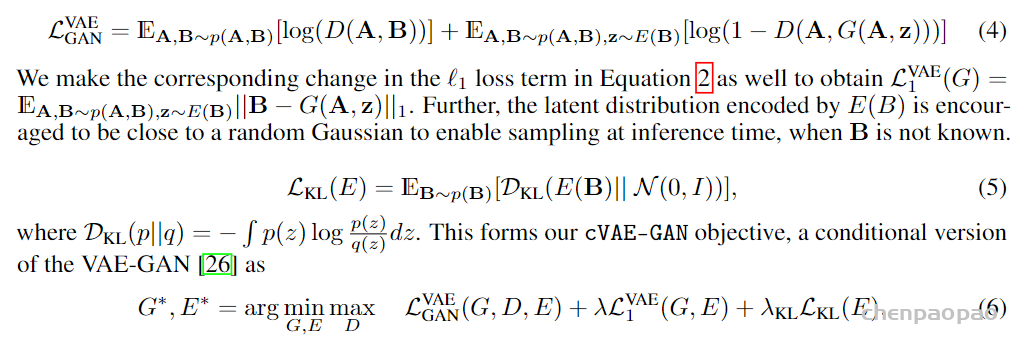
cLR-GAN(Conditional Latent Regressor GAN)
在 cVAE-GAN 中,对真实图像B进行编码,以提供潜在矢量的真实样本并从中进行采样。但是,cLR-GAN 的处理方式有所不同,其首先使用生成器从随机噪声中生成伪图像 B^,然后对伪图像 B^ 进行编码,最后计算其与输入随机噪声差异。
前向计算步骤如下:
首先,类似于 cGAN ,随机产生一些噪声,然后串联图像A以生成伪图像 B ^ ,之后,使用来自 VAE-GAN 的同一编码器将伪图像 B ^ 编码为潜矢量。
最后,从编码的潜矢量中采样 z ^ ,并用输入噪声 z 计算损失。数据流为 z −> B ^ −> z ^ ( 图(d) 中的实线箭头),有两个损失:
对抗损失 \(L_{GAN}\)
噪声 N(z) 与潜在编码之间的 L1损失 \(L_{1}^{latent}\)
通过组合这两个数据流,在输出和潜在空间之间得到了一个双映射循环。 BicycleGAN 中的 bi 来自双映射(双向单射),这是一个数学术语,简单来说其表示一对一映射,并且是可逆的。在这种情况下,BicycleGAN 将输出映射到潜在空间,并且类似地从潜在空间映射到输出。总损失如下:
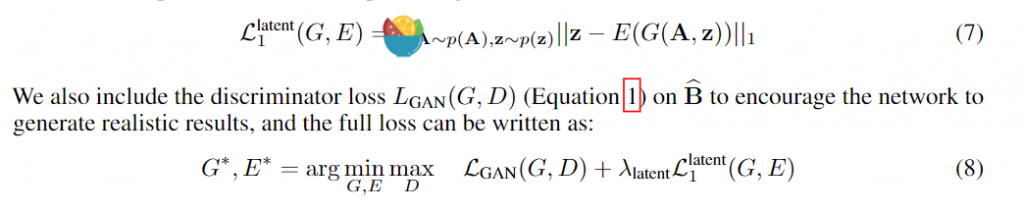
最总的损失:

可以分为两块来理解,第一块就是cVAE-GAN的训练,我们分析的基础就是鞋子纹理风格生成为例。
鞋子纹理图片经过编码器得到编码后的latent z通过KL距离将其拉向我们事先定义好的分布N(z)上,将服从分布的z与鞋子草图A结合后送入生成器G中得到重构的鞋子纹理图 。 此时为了衡量重构和真实的误差,这里用了L1损失和GAN的对抗思想实现,我们在后面损失函数分析部分再说。这样cVAE-GAN部分就可以训练了,cVAE GAN的重点还是在得到的embedding z。
。 此时为了衡量重构和真实的误差,这里用了L1损失和GAN的对抗思想实现,我们在后面损失函数分析部分再说。这样cVAE-GAN部分就可以训练了,cVAE GAN的重点还是在得到的embedding z。
另一块就是cLR-GAN的训练,将鞋子草图A和分布N(z)结合经过生成器G得到鞋子纹理图, 再通过对生成的纹理图编码后得到的z去趋近分布N(z)来反向矫正生成图,达到一个变相的循环。
当这两部分训练的很好时,这个就是我们需要的BicycleGAN了,在检验训练效果时我们只需要,输入A加上N(z)就可以生成鞋子的纹理图了, 这个N(z)具体为什么怎么取将决定生成为纹理的风格了。
一些细节
- 这里有一个小trike就是z和图片A的结合送入生成器G的结合方法,文中给出了两种方法:一种直接concat在input的channel上,一种Unet在压缩的时候,每次结果都加。 我们通过图解可以更好理解。

pytorch代码:https://github.com/junyanz/BicycleGAN