
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 | ||||||
来源:磐创AI分享
神经网络可视化工具
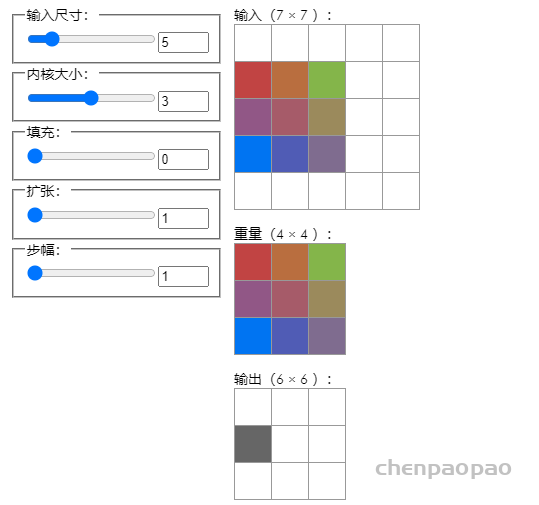
Convolution Visualizer
https://ezyang.github.io/convolution-visualizer/index.html
这种交互式可视化演示了各种卷积参数如何影响输入、权重和输出矩阵之间的形状和数据依赖性。将鼠标悬停在输入/输出上将突出显示相应的输出/输入,而将鼠标悬停在权重上将突出显示哪些输入与该权重相乘以计算输出。(严格来说,这里可视化的操作是相关性,而不是卷积,因为真正的卷积在执行相关性之前会翻转其权重。但是,大多数深度学习框架仍然称这些卷积,最终与梯度下降相同.)
Weights & Biases
https://docs.wandb.ai/v/zh-hans/
Weights & Biases 可以帮助跟踪你的机器学习项目。使用我们的工具记录运行中的超参数和输出指标(Metric),然后对结果进行可视化和比较,并快速与同事分享你的发现。
通过wandb,能够给你的机器学习项目带来强大的交互式可视化调试体验,能够自动化记录Python脚本中的图标,并且实时在网页仪表盘展示它的结果,例如,损失函数、准确率、召回率,它能够让你在最短的时间内完成机器学习项目可视化图片的制作。
总结而言,wandb有4项核心功能:
看板:跟踪训练过程,给出可视化结果
报告:保存和共享训练过程中一些细节、有价值的信息
调优:使用超参数调优来优化你训练的模型
工具:数据集和模型版本化
也就是说,wandb并不单纯的是一款数据可视化工具。它具有更为强大的模型和数据版本管理。此外,还可以对你训练的模型进行调优。
draw_convnet
一个用于画卷积神经网络的Python脚本
https://github.com/gwding/draw_convnet
NNSVG
http://alexlenail.me/NN-SVG/LeNet.html
PlotNeuralNet:用于为报告和演示绘制神经网络的 Latex 代码。
https://github.com/HarisIqbal88/PlotNeuralNet
Tensorboard
https://www.tensorflow.org/tensorboard/graphs
Caffe
https://github.com/BVLC/caffe/blob/master/python/caffe/draw.py
Matlab
http://www.mathworks.com/help/nnet/ref/view.html
Keras.js
https://transcranial.github.io/keras-js/#/inception-v3
DotNet
https://github.com/martisak/dotnets
Graphviz
http://www.graphviz.org/
ConX
https://conx.readthedocs.io/en/latest/index.html
ENNUI
Neataptic
https://wagenaartje.github.io/neataptic/
pyTorch模型可视化
visdom:
在PyTorch深度学习中,最常用的模型可视化工具是Facebook(中文为脸书,目前已改名为Meta)公司开源的Visdom
Visdom可以直接接受来自PyTorch的张量,而不用转化成NumPy中的数组,从而运行效率很高。此外,Visdom可以直接在内存中获取数据,毫秒级刷新,速度很快。
Visdom的安装很简单,直接执行以下命令即可:
pip install visdom
开启服务,因为visdom本质上是一个类似于Jupyter Notebook 的Web服务器,在使用之前需要在终端打开服务,代码如下:
python -m visdom.server
正常执行后,根据提示在浏览器中输入相应地址即可,默认地址为:
http://localhost:8097/
实例
本例通过使用PyTorch的可视化工具Visdom对手写数字数据集进行建模。
步骤1:先导入模型需要的包,代码如下。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from visdom import Visdom
步骤2:定义训练参数,代码如下。
batch_size=200
learning_rate=0.01
epochs=10
… …
执行成功后,在visdom网页可以看到实时更新的训练过程的数据变化,每一个epoch测试数据更新一次,如图9-15所示。
Visdom是由Plotly 提供的可视化支持,所以提供一下可视化的接口:
- vis.scatter : 2D 或 3D 散点图
- vis.line : 线图
- vis.stem : 茎叶图
- vis.heatmap : 热力图
- vis.bar : 条形图
- vis.histogram: 直方图
- vis.boxplot : 箱型图
- vis.surf : 表面图
- vis.contour : 轮廓图
- vis.quiver : 绘出二维矢量场
- vis.image : 图片
- vis.text : 文本
- vis.mesh : 网格图
- vis.save : 序列化状态
更新损失函数
在训练的时候我们每一批次都会打印一下训练的损失和测试的准确率,这样展示的图表是需要动态增加数据的,下面我们来模拟一下这种情况:
x,y=0,0
env2 = Visdom()
pane1= env2.line(
X=np.array([x]),
Y=np.array([y]),
opts=dict(title='dynamic data'))Setting up a new session…
for i in range(10):
time.sleep(1) #每隔一秒钟打印一次数据
x+=i
y=(y+i)*1.5
print(x,y)
env2.line(
X=np.array([x]),
Y=np.array([y]),
win=pane1,#win参数确认使用哪一个pane
update='append') #我们做的动作是追加TensorBoard
pytorch也支持tensorboard的使用:
Tensorboard的使用逻辑
Tensorboard的工作流程简单来说是
- 将代码运行过程中的,某些你关心的数据保存在一个文件夹中:
这一步由代码中的writer完成- 再读取这个文件夹中的数据,用浏览器显示出来:
这一步通过在命令行运行tensorboard完成。官方:
https://pytorch.org/docs/stable/tensorboard.html?highlight=tensorboard
其中可视化的主要功能如下:
(1)Scalars:展示训练过程中的准确率、损失值、权重/偏置的变化情况。
(2)Images:展示训练过程中记录的图像。
(3)Audio:展示训练过程中记录的音频。
(4)Graphs:展示模型的数据流图,以及训练在各个设备上消耗的内存和时间。
(5)Distributions:展示训练过程中记录的数据的分部图。
(6)Histograms:展示训练过程中记录的数据的柱状图。
(7)Embeddings:展示词向量后的投影分部。
动手练习:可视化模型参数
步骤1:首先导入相关的第三方包,代码如下。
import numpy as np
from torch.utils.tensorboard import SummaryWriter
步骤2:将loss写到Loss_Accuracy路径下面,代码如下。
np.random.seed(10)
writer = SummaryWriter(‘runs/Loss_Accuracy’)
步骤3:然后将loss写到writer中,其中add_scalars()函数可以将不同的变量添加到同一个图,代码如下。
for n_iter in range(100):
writer.add_scalar(‘Loss/train’, np.random.random(), n_iter)
writer.add_scalar(‘Loss/test’, np.random.random(), n_iter)
writer.add_scalar(‘Accuracy/train’, np.random.random(), n_iter)
writer.add_scalar(‘Accuracy/test’, np.random.random(), n_iter)
代码体中要做的事
首先导入tensorboard
from torch.utils.tensorboard import SummaryWriter 这里的SummaryWriter的作用就是,将数据以特定的格式存储到刚刚提到的那个文件夹中。
首先我们将其实例化
writer = SummaryWriter('./path/to/log')这里传入的参数就是指向文件夹的路径,之后我们使用这个writer对象“拿出来”的任何数据都保存在这个路径之下。
这个对象包含多个方法,比如针对数值,我们可以调用
writer.add_scalar(tag, scalar_value, global_step=None, walltime=None)这里的tag指定可视化时这个变量的名字,scalar_value是你要存的值,global_step可以理解为x轴坐标。
举一个简单的例子:
for epoch in range(100)
mAP = eval(model)
writer.add_scalar('mAP', mAP, epoch)这样就会生成一个x轴跨度为100的折线图,y轴坐标代表着每一个epoch的mAP。这个折线图会保存在指定的路径下(但是现在还看不到)
同理,除了数值,我们可能还会想看到模型训练过程中的图像。
writer.add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
writer.add_images(tag, img_tensor, global_step=None, walltime=None, dataformats='NCHW')可视化
我们已经将关心的数据拿出来了,接下来我们只需要在命令行运行:
tensorboard --logdir=./path/to/the/folder --port 8123然后打开浏览器,访问地址http://localhost:8123/即可。这里的8123只是随便一个例子,用其他的未被占用端口也没有任何问题,注意命令行的端口与浏览器访问的地址同步。
如果发现不显示数据,注意检查一下路径是否正确,命令行这里注意是
--logdir=./path/to/the/folder 而不是
--logdir= './path/to/the/folder '另一点要注意的是tensorboard并不是实时显示(visdom是完全实时的),而是默认30秒刷新一次。
细节
1.变量归类
命名变量的时候可以使用形如
writer.add_scalar('loss/loss1', loss1, epoch)
writer.add_scalar('loss/loss2', loss2, epoch)
writer.add_scalar('loss/loss3', loss3, epoch)的格式,这样3个loss就会被显示在同一个section。
2.同时显示多个折线图
假如使用了两种学习率去训练同一个网络,想要比较它们训练过程中的loss曲线,只需要将两个日志文件夹放到同一目录下,并在命令行运行
tensorboard --logdir=./path/to/the/root --port 8123