
项目地址:https://ommer-lab.com/research/latent-diffusion-models/
试玩: https://huggingface.co/spaces/stabilityai/stable-diffusion
High-Resolution Image Synthesis with Latent Diffusion Models
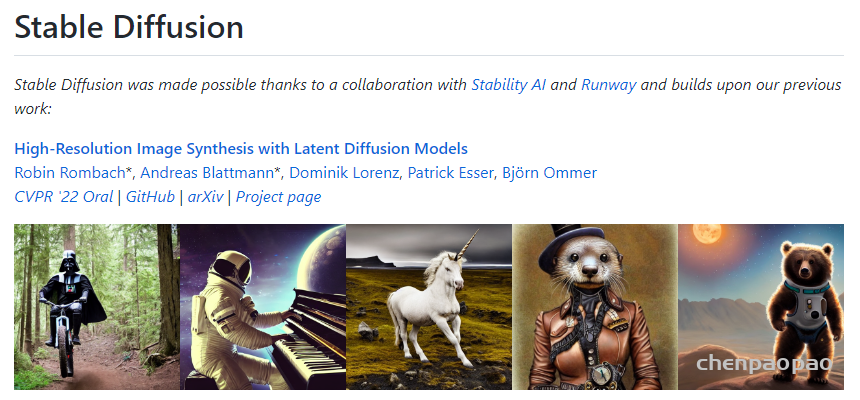
Stable Diffusion 是一个“文本到图像”的人工智能模型。近日,Stable AI 公司向公众开放了它的预训练模型权重。当输入一个文字描述时,Stable Diffusion 可以生成 512×512 像素的图像,这些图像如相片般真实,反映了文字描述的场景。
这个项目先是经历了早期的代码发布,而后又向研究界有限制地发布了模型权重,现在模型权重已经向公众开放。对于最新版本,任何人都可以在为普通消费者设计的硬件上下载和使用 Stable Diffusion。该模型不仅支持文本到图像的生成,而且还支持图像到图像的风格转换和放大。与之一同发布的还有 DreamStudio 测试版,这是一个用于该模型的 API 和 Web 用户界面。
Stable AI 公司表示:
“Stable Diffusion 是一个文本到图像的模型,它将使数十亿人在几秒钟内创造出令人惊叹的艺术。它在速度和质量上的突破意味着它可以在消费者级的 GPU 上运行。这将允许研究人员和公众在一系列条件下运行它,并使图像生成普及化。我们期待着有围绕这个模型和其他模型的开放生态系统出现,以真正探索潜伏空间的边界。”
Latent Diffusion 模型(LDM)是 Stable Diffusion 模型建立的一种图像生成方法。LDM 通过在潜伏表示空间(latent representation space)中迭代“去噪”输入来创建图像,然后将表示解码为完整的图像,这与其他著名的图像合成技术,如生成对抗网络(GAN)和 DALL-E 采用的自动回归方法不同。最近的 IEEE/CVF 计算机视觉和模式识别会议(CVPR)上有一篇关于 LDM 的论文,它是由慕尼黑路德维希-马克西米利安大学的机器视觉和学习研究小组创建的。今年早些时候,InfoQ 也报道的另一个基于扩散的图片生成 AI 是谷歌的 Imagen 模型。
Stable Diffusion 可以支持众多的操作。与 DALL-E 类似,它可以生成一个高质量的图像,并使其完全符合所需图像的文字描述。我们也可以使用一个直观的草图和所需图像的文字描述,从而创建一个看起来很真实的图像。类似的“图像到图像”的能力可以在 Meta AI 的 Make-A-Scene 模型中找到,该模型刚发布不久。
一些人公开分享了 Stable Diffusion 创建的照片的例子,Stable AI 的首席开发人员 Katherine Crowson 也在 Twitter 上分享了许多照片。毫无疑问,基于人工智能的图片合成技术将对艺术家和艺术界产生影响,这令一些观察家感到担忧。值得注意的是,在 Stable Diffusion 发布的同一周,一幅由人工智能生成的作品在科罗拉多州博览会的艺术竞赛中获得了最高荣誉。
Stable Diffusion 的源代码可以在 GitHub 上查阅。
试玩地址: https://huggingface.co/spaces/stabilityai/stable-diffusion

Contribution
- Diffusion model是一种likelihood-based的模型,相比GAN可以取得更好的生成效果。然而该模型是一种自回归模型,需要反复迭代计算,因而训练和推理都十分昂贵。本文提出一种diffusion的过程改为在latent space上做的方法,从而大大减少计算复杂度,同时也能达到十分不错的生成效果。( “democratizing” research on DMs),在unconditional image synthesis, inpainting, super-resolution都能表现不错~
- 相比于其它进行压缩的方法,本文的方法可以生成更细致的图像,并且在高分辨率(风景图之类的,最高达10242px都无压力)的生成也表现得很好。
- 提出了cross-attention的方法来实现多模态训练,使得class-condition, text-to-image, layout-to-image也可以实现。
more general cross-attention mechanism.
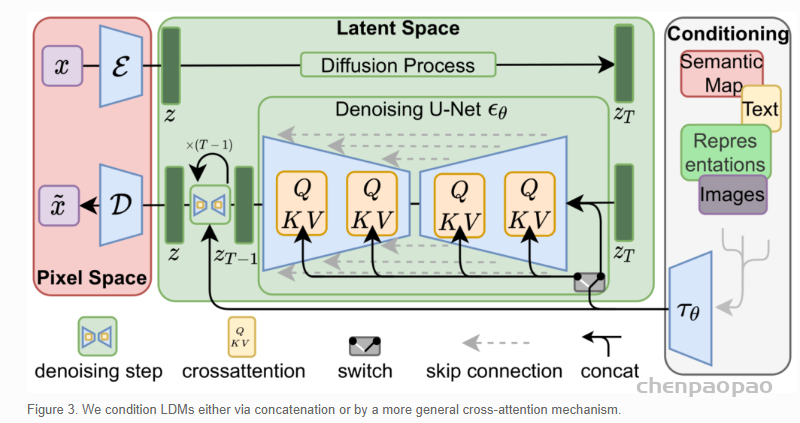
整体框架如图,先训练好一个AutoEncoder(包括一个encoder和decoder)。因此,我们可以利用encoder压缩后的数据做diffusion操作,再用decoder恢复即可。
- Autoencoder训练: L1/L2loss来作为重建损失,用GAN来做对抗攻击?,用KL loss来把latent space拉到正态分布,防止搜索空间过大。
- 用了encoder降维后,就可以使用latent space diffusion了~ 具体扩散过程其实没有变,只不过现在扩散和重建的目标为latent space的向量了。Diffusion model具体实现为 time-conditional UNet。
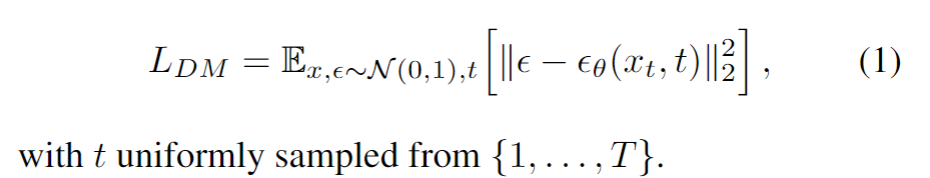

为了引入conditioning的信息,提出了domain specific encoder τθ(y)不同模态的(比如text, class, image…)转成中间表达(intermediate representation),再利用cross-attention来嵌入到UNet中去。
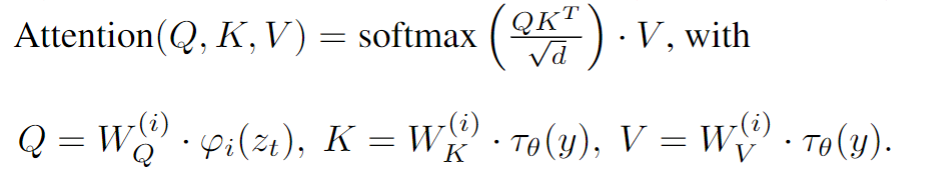

Experiments
展示一些可用的任务:
- layout-to-image 输入bounding box输出图像。
- text-to-image输入文本,输出图像。


- 输入landscape输出高分辨率的风景图。

- 超分辨率

- inpainting (图像修复/编辑)

效率对比。大概时间上缩短为1/3~ 并且,FID的值更小。
