
https://github.com/openai/whisper
Blog:https://openai.com/blog/whisper/
OpenAI Whisper
拥有 GTP-3 语言模型,并为 GitHub Copilot 提供技术支持的人工智能公司 OpenAI 近日开源了 Whisper 自动语音识别系统,Open AI 强调 Whisper 的语音识别能力已达到人类水准。
Whisper 是一个自动语音识别(ASR,Automatic Speech Recognition)系统(transformer模型),OpenAI 通过从网络上收集了 68 万小时的多语言(98 种语言)和多任务(multitask)监督数据对 Whisper 进行了训练。OpenAI 认为使用这样一个庞大而多样的数据集,可以提高对口音、背景噪音和技术术语的识别能力。除了可以用于语音识别,Whisper 还能实现多种语言的转录,以及将这些语言翻译成英语。OpenAI 开放模型和推理代码,希望开发者可以将 Whisper 作为建立有用的应用程序和进一步研究语音处理技术的基础。
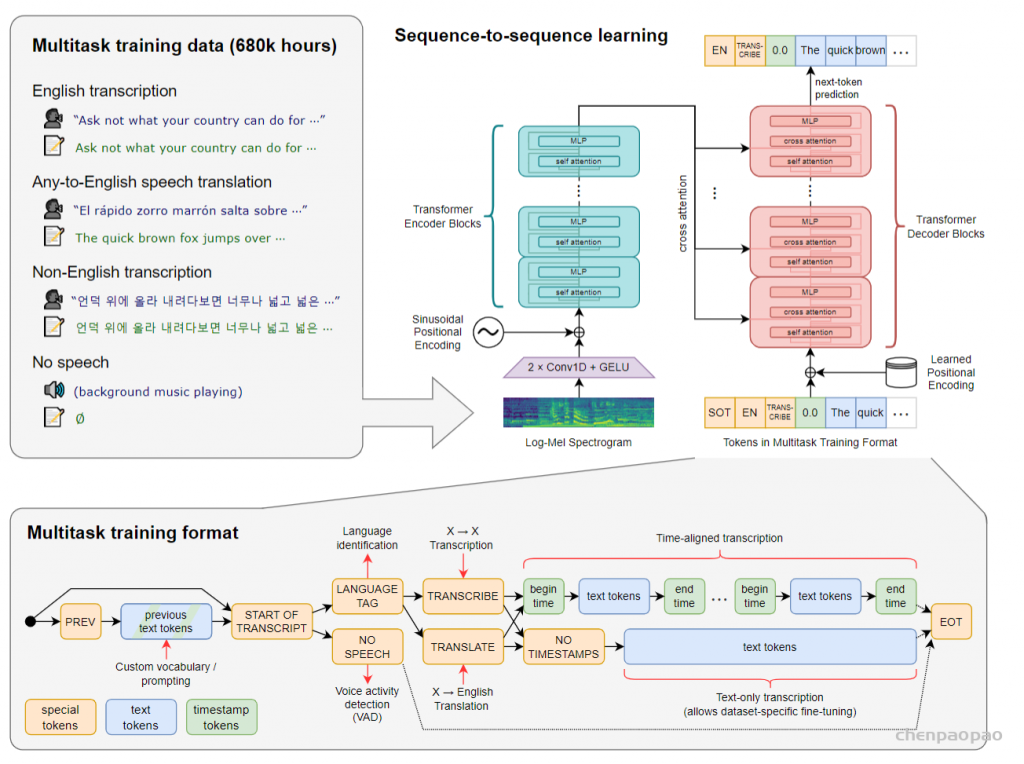
including multilingual speech recognition, speech translation, spoken language identification, and voice activity detection
Whisper 执行操作的大致过程:
输入的音频被分割成 30 秒的小段、转换为 log-Mel 频谱图,然后传递到编码器。解码器经过训练以预测相应的文字说明,并与特殊的标记进行混合,这些标记指导单一模型执行诸如语言识别、短语级别的时间戳、多语言语音转录和语音翻译等任务。
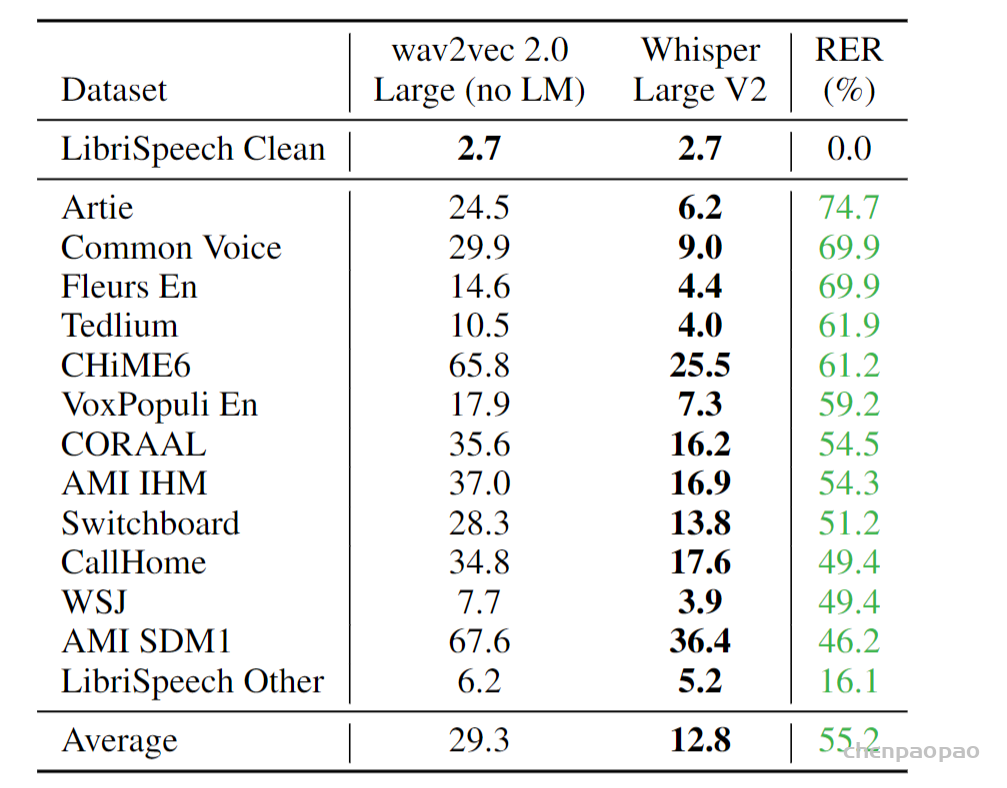
相比目前市面上的其他现有方法,它们通常使用较小的、更紧密配对的「音频 – 文本」训练数据集,或使用广泛但无监督的音频预训练集。因为 Whisper 是在一个大型和多样化的数据集上训练的,而没有针对任何特定的数据集进行微调,虽然它没有击败专攻 LibriSpeech 性能的模型(著名的语音识别基准测试),然而在许多不同的数据集上测量 Whisper 的 Zero-shot(不需要对新数据集重新训练,就能得到很好的结果)性能时,研究人员发现它比那些模型要稳健得多,犯的错误要少 50%。
目前 Whisper 有 9 种模型(分为纯英文和多语言),其中四种只有英文版本,开发者可以根据需求在速度和准确性之间进行权衡,以下是现有模型的大小,及其内存要求和相对速度:

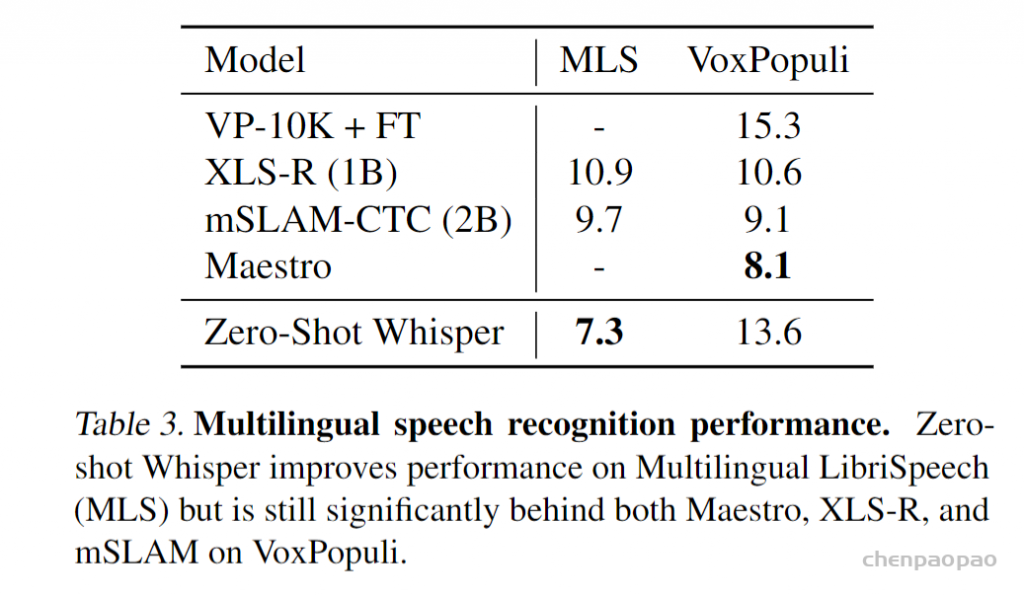
Whisper的表现因语言而异。下图显示了使用largeV2模型使用Fleurs数据集的语言进行细分。
论文:稳健的语音识别通过大规模的弱监督
弱监督的意思是指我们的语音数据是有标号的,但是标号的可行度不是那么高,质量一般这也是,这也是作者能够采集到近70万h的数据的原因。(在样本数量和质量之间做权衡)
摘要
我们研究了互联网上的大量的训练好的的语音处理系统的功能。当把我们的数据集扩大到680,000小时,且是一个多语言和多任务监督训练时,最终的模型可以与在标准数据集训练好的其他模型相比具有相同的效果,但whisper无需进行任何微调,在面对新数据集时候无需微调。与人类相比,模型具有准确性和鲁棒性。我们正在发布模型和推理代码,以作为在强大语音处理上进一步工作的基础。
引言
目前主流的语音识别方法是先进行大规模的无监督预训练(Wav2Vec 2.0),比如, Wav2Vec 采集了1000000h的无标签训练数据,先用这些数据进行预训练一个编码器(使用对比学习 or 字训练),encoder能够对语音数据做一个很好的编码,然后在面向下游任务时,可以在标准训练集中做微调(只需要几十小时的数据就可),这样比只在标准数据集上训练的结果好很多。
这些预训练好的语音编码器能够学习到语音的一个高质量表示,但是用无监督方法训练的编码器仍然需要训练一个解码器,需要用带标签的数据来微调,微调是一个很复杂的过程,如果不需要微调就好了,这也是本文要做的工作。此外,过去的工作缺乏一个很好的解码器,这是一个巨大的缺陷,而语音识别系统就是应该是“out of box”,也就是拿来即用。
有监督学习很多方法是把多个有监督的数据集合并成一个大的数据集,这样确实保证比在单个数据集上的准确性和泛化性都要好,但是之前的工作最多也就是5000h的数据集,跟之前的100万h的无监督数据集相比差的太多。
顺着这个思路,如果我们把数据集的标号放松一下,就会获得个更多的数据集。在数量和质量之间做权衡是一个不错的选择,比如在yutube上采集视频和字幕作为数据集,为了追求样本的多样性和数量,稍微降低一点质量也是可以的。因此本文就是把弱监督数据集扩展到了68万h,并将模型取名whisper.
方法
数据处理:不需要对标号做任何后处理。从互联网中采集到的数据多种多样,比如声音的环境、录制的设备、说话的人、语言。这样让模型更加稳健,但是对应的我们希望标号质量应该要一致,因此需要做一个过滤系统,把一些质量差的文本删除(一般是一些机器自动生成的文本,如果使用其作为标号,那训练出来的模型效果也不会很好)、去重等等。训练数据30s以及对应的标号作为一个样本。
数据部分是本文最核心的贡献。由于数据够多,模型够强,本文模型直接预测原始文本,而不经过任何标准化(standardization)。从而模型的输出就是最终识别结果,而无需经过反向的文本归一化(inverse text normalization)后处理。所谓文本归一化包括如将所有单词变小写,所有简写展开,所有标点去掉等操作,而反向文本归一化就是上述操作的反过程。在 Whisper 中,这些操作统统不用,因为数据足够多,可以覆盖所有的情况。
在本文收集的语音数据中,包含了不同环境、不同语言、不同说话人等多样的数据,这有助于训练出文件的语音识别系统。然而,文本标签的多样性对模型的学习是一种阻碍。为了解决这个问题,本文使用了几种自动过滤方法,来提高文本标签的质量。
- 首先,收集自互联网的语音识别数据,很有可能文本标签就是来自现有的语音识别系统的识别结果。之前有研究工作表明,在训练数据中混有机器生成的标签数据会损害模型的性能。为此,本文根据机器识别结果的一些特点,过滤掉了这些数据。
- 另外,本文对数据中语音所属语言和文本所属语言进行检测。如果文本是非英语的其他语言,则要求语音也必须是同种语言;如果文本是英语,则语音可以是任何语言(因为本文方法中有一个其他语言到英语的翻译任务)。
- 本文用一个语音识别模型在收集的数据上进行测试,发现在一些错误率极高的数据中,存在音频信息不完整、字幕声音不匹配等低质量数据,这些数据同样会被过滤掉。
另外,可能在收集的数据中含有标准语音识别数据集中的内容,为了避免对测试结果产生影响,这部分数据同样需要去掉。
最后,将音频切分为 30s 的片段,配上对应文本,得到训练数据。
2、模型
由于我们的工作重点是研究大规模监督预训练的语音识别能力,因此我们使用现成的架构来避免将我们的发现与模型改进混淆。具体来说就是使用最原始的encoder-decoder Transformer (Vaswani et al., 2017)模型作为网络。将所有音频重新采样至16,000 Hz,80通道的Mel频谱图表示,其步幅为10毫秒。对于特征归一化,我们将输入归一化到-1和1之间,整个训练数据集的平均值约为零。
输入(80*3000)在送入transformer之前先经过卷积层(kernel=3),主要是考虑卷积具有局部相关性,输出80*1500,降低维度。剩下的部分就是一个经典 transformer 架构。
Whisper 使用的模型改动不大,就是 Transformer 第一次提出时的 encoder-decoder 架构。Whisper 的入出侧是声音信号,声音信号的预处理是将音频文件重采样到 16000 Hz,并计算出 80 通道的梅尔频谱,计算时窗口大小为 25ms,步长为 10ms。然后将数值归一化到 -1 到 1 之间,作为输入数据。可以认为是对于每一个时间点,提取了一个 80 维的特征。之前数据处理部分提到每个音频悲切氛围 30s 的片段,这里步长为 10,所以每 30 秒有 3000 个时间点。综上,对于一个 30 秒的音频数据,我们提取到形状为 3000×80 的特征。对应到 NLP 中,可以理解为句子长度为 3000,每个词的词嵌入维度为 80。
3000×80 的输入数据首先通过两个 1D 卷积层,得到 1500×80 的特征。后面的处理就是标准的 Transformer encoder-decoder结构了。将这个特征送入到 Transformer encoder 中,提取处的特征作为交叉注意力输入送给 decoder。decoder 每次预测下一个 token,其输入是对应多任务学习的一些预设 token 和 prompt。
3、核心:多任务训练
虽然语音系统主要的任务是给一段话,把里面说的词识别出来,但是实际上大部分语言识别系统来说,还需要进行其他的后处理:检测是否有人说话(VAD)、谁在说话、识别的语音文本添加标点等等。作者希望一个模型可以同时做转录、VAD、时间戳、检测等等任务。
all in one的方法会带来两个问题:比如要做VAD,可能我只需要一个小模型就可以完成,但现在必须要用这个超大模型。另外,假如我这个模型在某个任务表现不好,那么我需要多添加该任务数据继续训练,但继续训练,其他任务的效果是否会受影响。
具体任务如下:
一是给定英文语音,转录成英文文本;二是给定其他语言语音,转录并翻译成英文文本;三是给定其他语言语音,转录成该语言文本;四是给定只有背景音乐的音频,识别出无人说话。

所有这些任务都由解码器预测的 token 序列表示,从而使得一个模型能够处理多个任务。这几个任务及模型输出 token 的关系可以从图中下方的图示中的 token 序列看出:在 START OF TRANSCRIPT token 之后,如果当前无人说话,则识别为 NO SPEECH 。如果有人说话,则识别出当前语音所属的语言 LANGUAGE TAG 。然后有两种可能的任务 TRANSCRIBE 还是翻译任务 TRANSLATE ,这两种任务又分为两种形式:带时间戳的和不带时间戳的,分别穿插或不穿插时间戳 token ,预测出文本 token。最后到达 EOT token,整个流程结束。
那么如何训练这些任务呢?使用的是一个prompt格式,不同的任务通过不同的tokens组合来区别的,三种:特殊控制token、文本token、时间戳token。
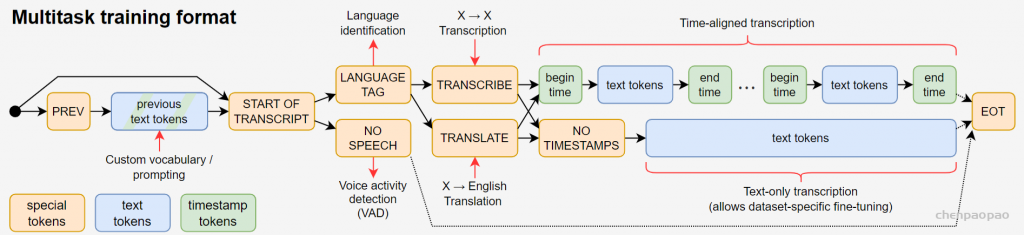
从起点开始,有一定概率走prev这个,表示前面一段我已经转录的内容(包括文本和时间戳),也有一定概率直接走到start token,然后学习语言类别token(包括99种语言+空白),接下来分两个token(转录还是翻译),然后有分两中(是否预测时间戳),有时间戳token则需要预测这句话的开始结束时间+内容,没有时间戳的话,直接预测这三十秒的文字,最后EOT结束。这样相比bert使用不同的输出头,对应不同的损失来说。whisper多任务只需要一个输出头,一个损失函数就可以,通过控制输入的流来控制不同的任务。但这样设计也有缺陷:某个任务表现不好,需要模型完全训练,这样对其他任务来说也会有影响,牵一发动全身。
实验
作者实验的数据集是模型训练集没有使用过的,认为是zero-shot。验证标准:WER

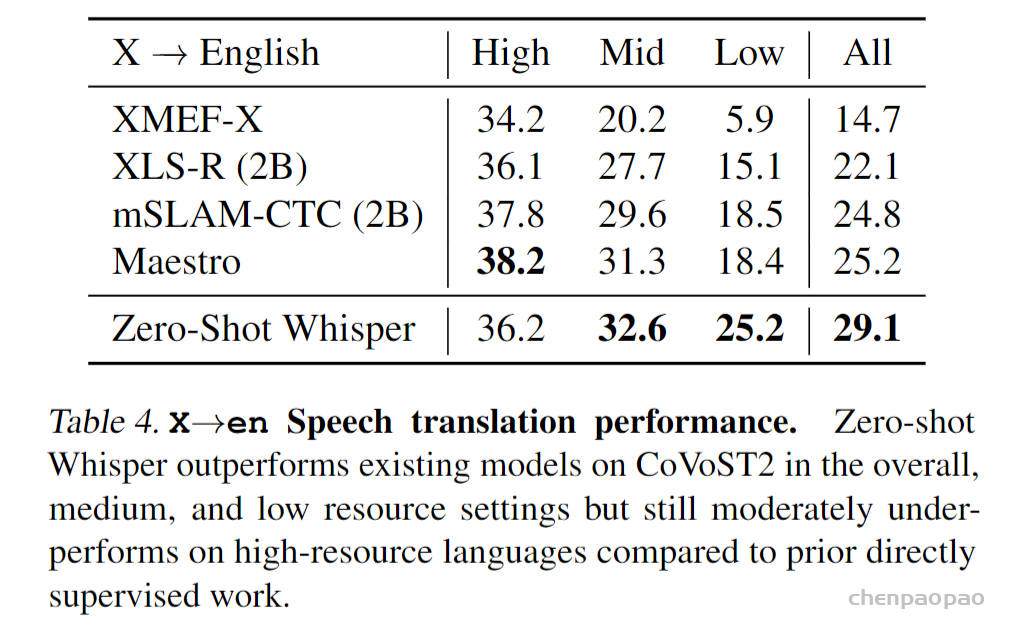

结论
Whisper 说明在语音识别领域,对于把大规模的弱监督训练的认识还是不够,我们的模型结果说明不需要做自监督 或者自训练,只要在大规模数据集上训练好模型,推理时无需任何微调,只需要zero-shot就可以。
基于Whisper开发应用工具:
AutoCut: 通过字幕来剪切视频
github: https://github.com/mli/autocut
AutoCut 使用 Whisper 来对你的视频自动生成字幕。然后在字幕文件中你选择需要保留的句子,AutoCut 将对你视频中对应的片段裁切并保存。你无需使用视频编辑软件,只需要编辑文本文件即可完成视频剪切。
假如你录制的视频放在 2022-11-04/ 这个文件夹里。那么运行
autocut -d 2022-11-04
提示:如果你使用 OBS 录屏,可以在
设置->高级->录像->文件名格式中将空格改成/,即%CCYY-%MM-%DD/%hh-%mm-%ss。那么视频文件将放在日期命名的文件夹里。
AutoCut 将持续对这个文件夹里视频进行字幕抽取和剪切。例如,你刚完成一个视频录制,保存在 11-28-18.mp4。AutoCut 将生成 11-28-18.md。你在里面选择需要保留的句子后,AutoCut 将剪切出 11-28-18_cut.mp4,并生成 11-28-18_cut.md 来预览结果。
你可以使用任何的 Markdown 编辑器。例如我常用 VS Code 和 Typora。下图是通过 Typora 来对 11-28-18.md 编辑。

全部完成后在 autocut.md 里选择需要拼接的视频后,AutoCut 将输出 autocut_merged.mp4 和对应的字幕文件。
转录某个视频生成 .srt 和 .md 结果。
autocut -t 22-52-00.mp4
- 如果对转录质量不满意,可以使用更大的模型,例如autocut -t 22-52-00.mp4 –whisper-model large默认是
small。更好的模型是medium和large,但推荐使用 GPU 获得更好的速度。也可以使用更快的tiny和base,但转录质量会下降。
剪切某个视频
autocut -c 22-52-00.mp4 22-52-00.srt 22-52-00.md
- 默认视频比特率是
--bitrate 10m,你可以根据需要调大调小。 - 如果不习惯 Markdown 格式文件,你也可以直接在
srt文件里删除不要的句子,在剪切时不传入md文件名即可。就是autocut -c 22-52-00.mp4 22-52-00.srt - 如果仅有
srt文件,编辑不方便可以使用如下命令生成md文件,然后编辑md文件即可,但此时会完全对照srt生成,不会出现no speech等提示文本。autocut -m test.srt test.mp4 autocut -m test.mp4 test.srt # 支持视频和字幕乱序传入 autocut -m test.srt # 也可以只传入字幕文件
一些小提示
- 讲得流利的视频的转录质量会高一些,这因为是 Whisper 训练数据分布的缘故。对一个视频,你可以先粗选一下句子,然后在剪出来的视频上再剪一次。
最终视频生成的字幕通常还需要做一些小编辑。你可以直接编辑md文件(比srt文件更紧凑,且嵌入了视频)。然后使用autocut -s 22-52-00.md 22-52-00.srt来生成更新的字幕22-52-00_edited.srt。注意这里会无视句子是不是被选中,而是全部转换成srt。- 最终视频生成的字幕通常还需要做一些小编辑。但
srt里面空行太多。你可以使用autocut -s 22-52-00.srt来生成一个紧凑些的版本22-52-00_compact.srt方便编辑(这个格式不合法,但编辑器,例如 VS Code,还是会进行语法高亮)。编辑完成后,autocut -s 22-52-00_compact.srt转回正常格式。 - 用 Typora 和 VS Code 编辑 Markdown 都很方便。他们都有对应的快捷键 mark 一行或者多行。但 VS Code 视频预览似乎有点问题。
- 视频是通过 ffmpeg 导出。在 Apple M1 芯片上它用不了 GPU,导致导出速度不如专业视频软件。