
Stereo magnification:Learning view synthesis using multiplane images
本文主要研究新视角合成任务中 Narrow-baseline Stereo Images Pairs(处于同一水平基线的左右视角图像)输入的情况。本文首次提出了 Multiplane Images (MPI) 的场景表达方式,其优点在于:
- 只需用网络预测一次 MPI 的场景表达,后续就能重复利用该 MPI 来生成多个不同视角下的图片;
- 能够有效获取未出现在 Stereo 输入图像中(被遮挡)的场景结构。
另外,为了训练网络,本文还提出了一种使用在线视频来生成训练数据的方法
方法:
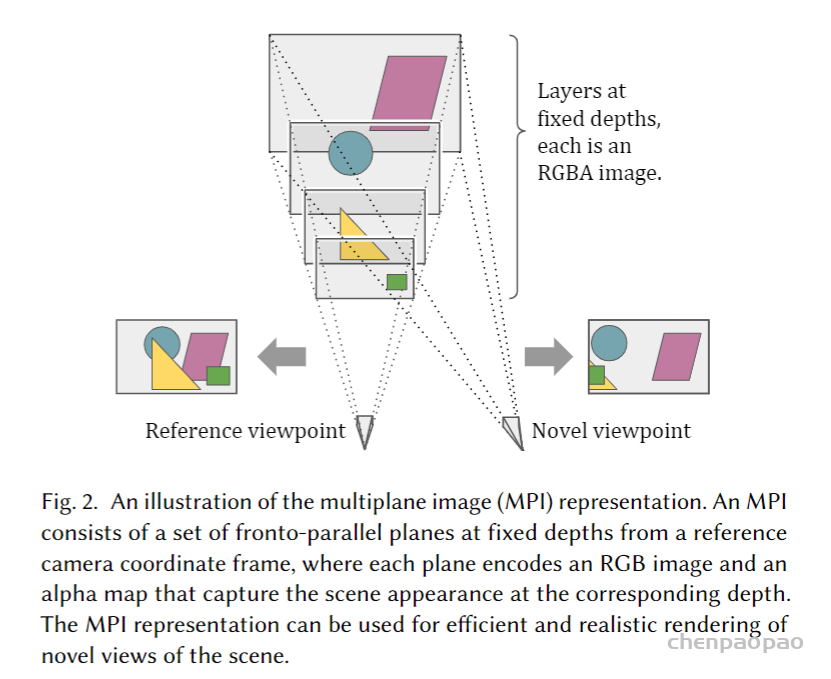
1. MPI 场景表达
MPI 包含多个平面,每个平面 d 编码两种信息:RGB 颜色图像 C d,透明度 Alpha 图 α d ,因此整个 MPI 可表示为 RGBA 图像的集合,即 { ( C 1 , α 1 ) , . . . , ( C D , α D ) },其中 D 表示平面的数量(作者最终采用了 32 个平面)。
2. MPI 网络学习
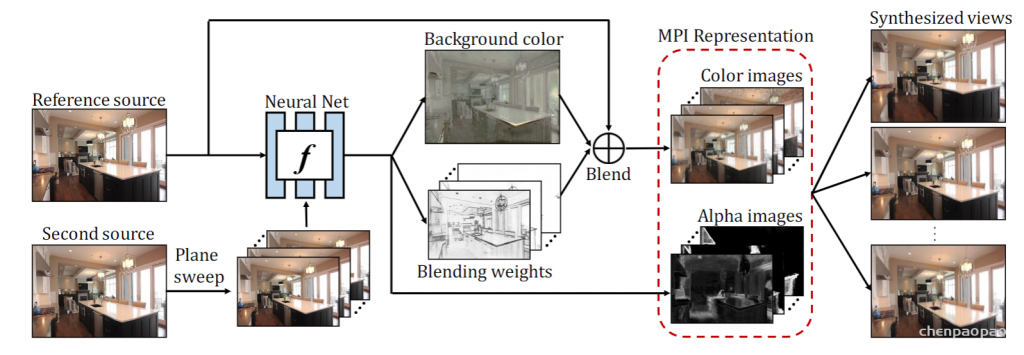
模型训练过程中,输入为(I1,I2,c1,c2),ground truth 为(It,ct),其中 I 表示图像,ci=(pi,ki),pi 表示相机外参,ki 表示相机内参。目标是学习一个 MPI 表达网络 f θ ( ⋅ ) ,以(I1,I2,c1,c2) 作为输入,推断出 MPI 的场景表达,并重建出 ct 相机参数下的目标图像 It 。
网络输入:下面假设 I1 为 Reference Source,I2 为 Second Source,为了将 I2 的位姿信息嵌入到I1 中,作者先计算了一个 Plane Sweep Volume (PSV),即将 I2 投影到I1 的不同深度平面上(由于这里采用 Stereo 图像输入,I1 和 I2 位于同一水平基线上,故只需将I2 做不同程度的水平偏移即可得到 PSV。和 Stereo Depth Estimation 任务中的 Cost Volume 类似)。之后将I2 的 PSV 和I1 concat 到一起作为网络的输入,输入的尺度为 H × W × 3 ( D + 1 )。
网络输出:作者认为如果让网络回归出每个平面对应的 RGBA 四个通道,网络输出的通道数太多,对于网络的学习太过困难,因此,作者采用了一种简单有效的做法,即将每个平面的 RGB 看作是参考图 I1 和一张统一背景图 I^b 的加权平均:
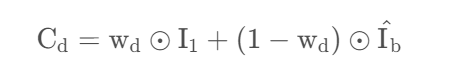
直观地来说,对于前景内容占主导的附近的平面,I1 将占有更高的权重,而 I ^ b 用于捕捉在参考视图中被遮挡的表面
那么网络仅需要回归出一张背景图I^b,每个平面的融合概率 wd,以及透明度αd,就能够获得完整的 MPI 表达了。总体而言,原本输出的尺寸为 WH⋅4D,在经过调整之后,变为WH⋅(2D+3) 。
3、使用MPIs进行可微视图合成
给定关于一个参考帧的IMPI 表示,我们能够通过对每个平面的RGBA图像应用平面变换(逆单应性),并将已转换的图像按前后顺序组合成单个图像的阿尔法组合,最终合成得到一个新奇视图I^t。
平面变换和阿尔法组合都是可微的,因此可以很容易地融入到学习流程的其余部分中。

4. 损失函数

结果展示:

