
Self-Supervised Monocular Depth Estimation witha Vision Transformer
paper: https://arxiv.org/pdf/2208.03543.pdf
基于深度学习单目深度估计任务简介
深度估计是计算机视觉领域的一个基础性问题,其可以应用在机器人导航、增强现实、三维重建、自动驾驶等领域。而目前大部分深度估计都是基于二维RGB图像到RBG-D图像的转化估计,主要包括从图像明暗、不同视角、光度、纹理信息等获取场景深度形状的Shape from X方法,还有结合SFM(Structure from motion)和SLAM(Simultaneous Localization And Mapping)等方式预测相机位姿的算法。其中虽然有很多设备可以直接获取深度,但是设备造价昂贵。也可以利用双目进行深度估计,但是由于双目图像需要利用立体匹配进行像素点对应和视差计算,所以计算复杂度也较高,尤其是对于低纹理场景的匹配效果不好。而单目深度估计则相对成本更低,更容易普及。
那么对于单目深度估计,顾名思义,就是利用一张或者唯一视角下的RGB图像,估计图像中每个像素相对拍摄源的距离。对于人眼来说,由于存在大量的先验知识,所以可以从一只眼睛所获取的图像信息中提取出大量深度信息。那么单目深度估计不仅需要从二维图像中学会客观的深度信息,而且需要提取一些经验信息,后者则对于数据集中相机和场景会比较敏感。
摘要:
自监督单眼深度估计是一种有吸引力的解决方案,它不需要难以获取的深度标签来进行训练。 卷积神经网络 (CNN) 最近在这项任务中取得了巨大成功。 然而,它们有限的接受域限制了现有的网络架构只能在局部进行推理,从而削弱了自我监督范式的有效性。 鉴于 Vision Transformers (ViTs) 最近取得的成功,我们提出了 MonoViT,这是一个全新的框架,结合了 ViT 模型支持的全局推理和自监督单目深度估计的灵活性。 通过将普通卷积与 Transformer 块相结合,我们的模型可以在局部和全局进行推理,以更高的细节和准确性产生深度预测,从而使 MonoViT 在已建立的 KITTI 数据集上实现sota的性能。 此外,MonoViT 在 Make3D 和 Driving Stereo 等其他数据集上证明了其卓越的泛化能力。
介绍:
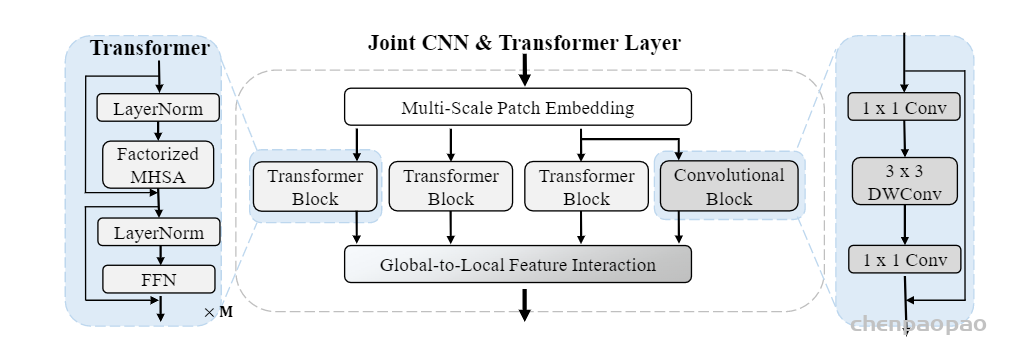
Transformers (ViTs)最近表现出杰出的目标检测和 语义分割等任务的结果,这要归功于它们能够建立像素之间的长距离关系,因此是全局感受野。另外,有相关工作将VIT应用于深度估计,但不是采用自监督单目深度估计。 本文弥补了这个缺失的步骤,提出了MonoViT architecture。它在其骨干网中结合了卷积层和最先进的 (SoTA) MPViT块【1】进而对图片中的局部信息(objects)和全局信息(前景和背景之间的关系,以及物体之间)进行建模。 该策略使我们能够消除由 CNN 编码器的有限感知域引起的瓶颈,产生自然更细粒度的预测。
作者在KITTI dataset进行实验,表现优于其他sota模型,还分析了模型泛化能力跨不同的数据集,将 MonoViT 与它在 Make3D 和 Driving-Stereo datasets进行比较,也突出显示了 MonoViT 的卓越泛化能力
模型架构:
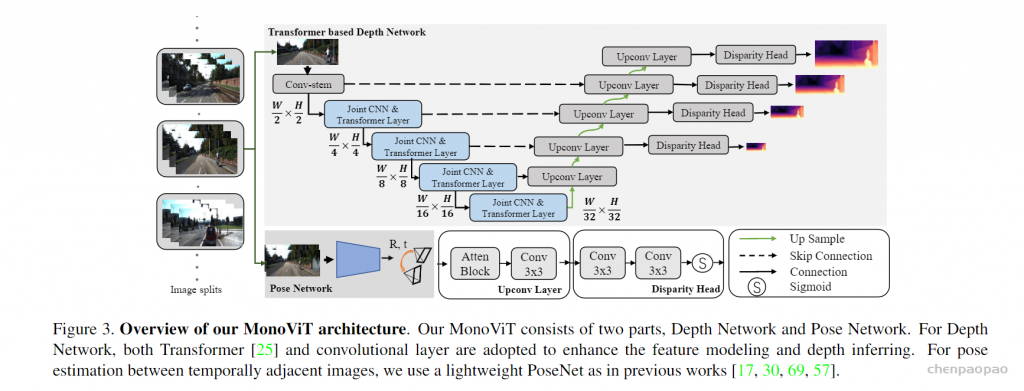
Deep Network:
Joint CNN & Transformer Layer used in depthencoder:
PoseNet:
PoseNet 倾向于简单而有效的实现。 具体来说, PoseNet 使用 ResNet18【2】的轻量级结构。 接收相邻图像 [I, I†] 作为输入,输出视频序列相邻帧之间的 6 DoF 相对位姿 T。这个网络用于最终辅助计算loss,提供监督信息。
Loss损失函数
View reconstruction loss:
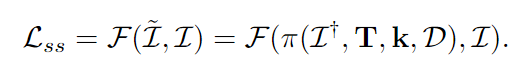
Smoothness loss. As in previous works, the edge-aware smoothness loss is used to improve the inverse depth map d:


【1】MPViT: Multi-Path Vision Transformer for Dense Prediction
【2】Deep residual learning for image recognition