
近几年有关单目图像深度识别的算法以CNN为主流,更细的说是以无监督的同时对深度、计算机角度、光流等同时计算的端到端深度网络为主流。所谓无监督其实是指在训练过程中不需要输入真实的深度值,这样做有一个好处就是目前能够测量到深度信息的传感器还不够精确,因此由不够精确的label训练出的model得到的预测结果必然不会特别令人满意;
所谓同时计算呢,在我理解是指在训练过程中,用一个能够表征时间序列上有前后关系的帧之间的差别的loss同时训练多个网络,而在得到model后每个网络可以单独使用。
很聪明,不同作用的网络相当于人为的特征提取过程,最后的预测基于这个人为的特征提取结果,但这种方法也有其缺点,我能想到的就是参数的增加,网络结构的复杂化和人为特征对最终预测结果有没有起引导作用只能用实验去证明。
详细说呢,首先,所谓的“自监督”虽然不需要输入真实深度信息,但需要输入双目摄像头获取到的同一时刻不同角度的图像或者前后帧图像。
自监督的单目深度估计包括: 基于双目训练的无监督模型 和 基于视频序列的无监督模型
基于双目训练的无监督模型:
UnSupervised Monocular Depth Estimation with Left-Right Consistency, CVPR, 2017
学习方法在单目深度估计上面有比较好的结果了,但还把深度估计问题作为一个有监督的回归问题。所以需要大量相对应的ground truth用来训练。记录有质量的各种场景的深度信息是一个比较难的事情。作者做了一个新方法,替代了现在直接用深度图数据训练。这个方法是用容易获得的双目立体视觉的角度。
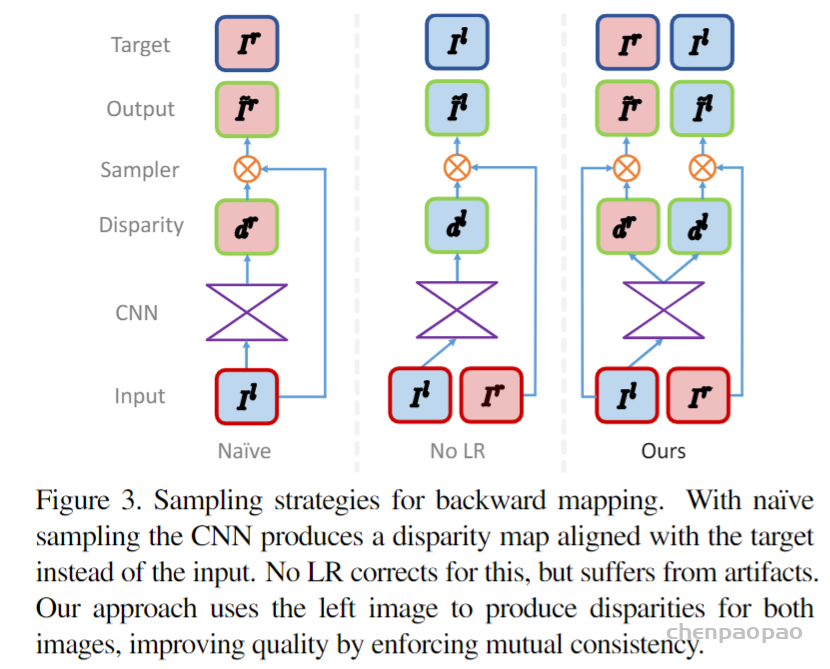
作者提出了全新的训练函数目标函数,可以让卷积神经网络学习到深度估计,虽然没有深度信息的ground truth。利用一些对极几何约束,作者产生了视差损失。还发现只用图像重建结果会产生低质量的深度图。为了克服这个困难,作者构建了一个新颖的训练损失,可以加强左右视差图的一致性,这样能够提升性能和鲁棒性。作者的方法在KITTI数据集的单目深度估计上达到了state-of-the-art,超过用ground-truth深度训练的有监督方法。

基于视频序列的无监督模型:
UnSupervised Learning of Depth and Ego-Motion from Video,CVPR,2017
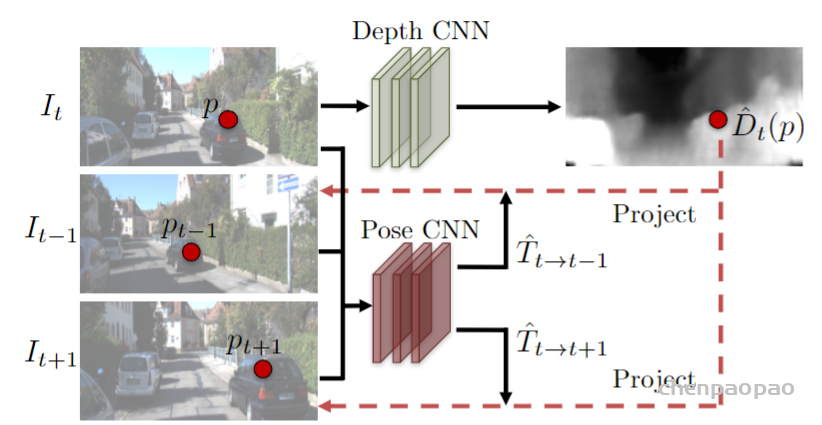
这篇文章提出了一种非监督的多功能网络,主要思想就像之前提到过的用一个loss同时训练两个网络。网络的结果如图,其中第一个网络可接受一幅图片作为输入,输出其对应的深度图片;第二个网络为姿态网络,接受t,t+1和t-1三个时刻三幅图片作为输入,输出从t到t+1和从t到t-1的相机姿态变化矩阵。


输入为前中后三帧连续的图片,同时训练两个网络,一个得到深度预测结果,一个得到视差矩阵结果
[ICCV 2019] Digging into Self-Supervised Monocular Depth Prediction
目前自监督深度学习取得最好进展的地方,一般说来自监督不需要标注,使用内在几何(通常是多视图几何)关系监督学习,从另一个侧面说明3d视觉才是视觉的本质。
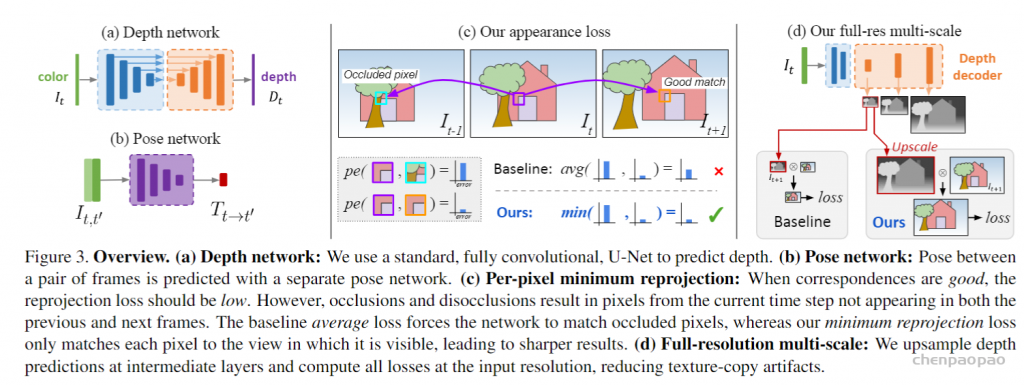
这篇文章中的作者开发了一种方法,该方法使用深度估计和姿态估计网络的组合来预测单帧图像中的深度。 它通过在一系列运动的图像(包括单目和双目)序列上训练一个建立在自监督损失函数上的架构来实现,这一架构包括两个网络,一个用来在单目图像上预测深度,另一个在运动图像之间预测姿态。 此方法不需要标注训练数据集。 相反,它使用图像序列中的连续时间帧和姿态的重投影关系来进行训练。 稍后将更详细地描述重建过程。 论文的主要贡献是:
1.一种自动mask技术,可消除loss对不重要像素的注意力,减少它们的影响
2.用深度图修正光度重建误差
3.多尺度深度估计
模型架构:本文的方法使用深度网络和姿态网络。 深度网络是经典的U-Net [2]编码器-解码器模型结构。 编码器是经过预训练的ResNet模型,当然也可以考虑其他模型。 深度解码器将输出转换为深度值。作者使用基于ResNet18的姿势网络,该姿态网络经过修改后,可以使用两个彩色图像作为输入来预测单个6自由度相对姿势或旋转和平移参数。 姿势网络使用前后两帧而不是典型的立体图像对作为图像对输入。 它可以从序列中的前一帧和后一帧通过角度预测目标图像的外观。
训练:下图说明了模型的训练过程。
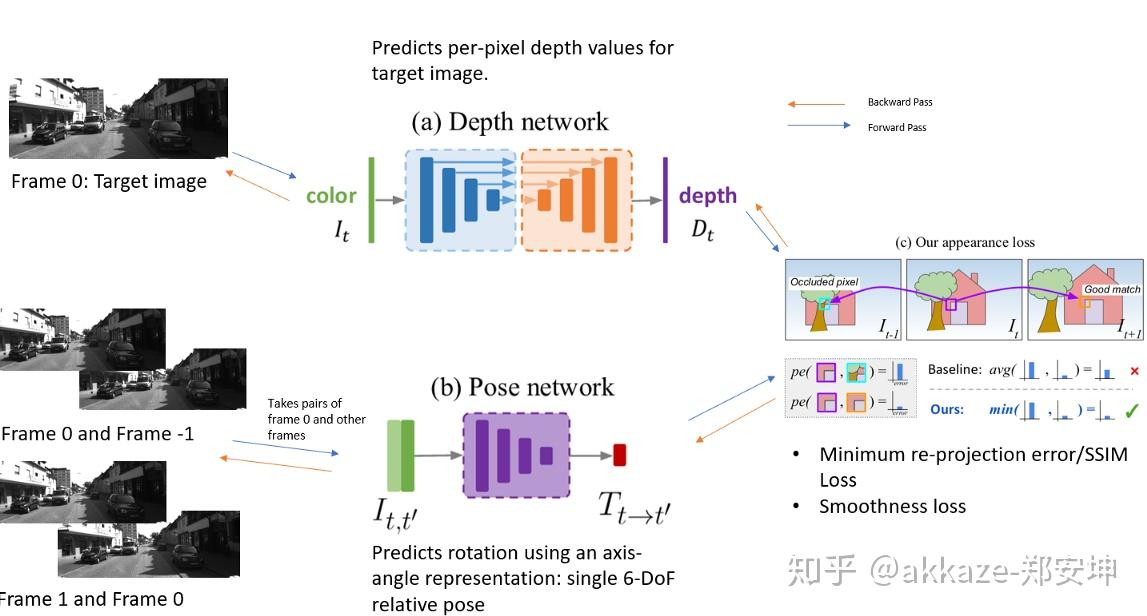
光度重建误差:目标图像位于第0帧,并且用于姿态估计过程的图像可以是前一帧或后一帧,也就是帧+1或帧-1。该损失是基于目标图像和重建的目标图像之间的相似性。重建过程通过使用姿态网络从源帧(帧+1或帧-1)计算转换矩阵开始。然后使用旋转和平移的信息来计算从源帧到目标帧的映射。最后使用从深度网络预测的目标图像的深度图和从姿势网络转换的矩阵,将其投影到具有固有内参矩阵K的摄像机中,以获取重建的目标图像。此过程需要先将深度图转换为3D点云,通过姿态将点云转换到另一个坐标系后再使用相机内参将3D点转换为2D点。所得的点用作从目标图像进行双线性插值的采样网格。
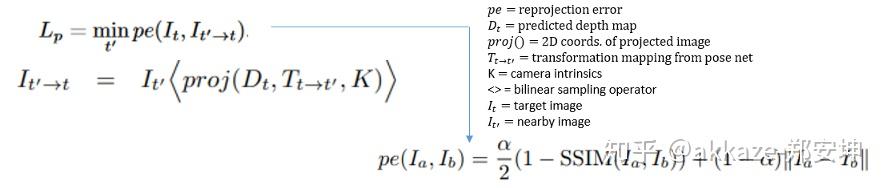
这种loss的目的是减少目标图像和重建的目标图像之间的差异,在目标图像和重建的目标图像中,姿态和深度估计的过程中都需要使用它。
自动mask:最终的光度重建误差要乘以一个mask,该mask解决与假设相机在静态场景(例如静态场景)中移动的变化有关的问题。尤其是 一个物体正在以与相机相似的速度移动,或者在其他物体正在移动时照相机已停止,也就是那些在相机坐标系里静止的物体。 这些相对静止的物体理论上应该有无穷大的深度。 作者使用一种自动mask方法解决了这一问题,该方法可以过滤不会将外观从一帧更改为下一帧的像素,也就是那些和相机同步运动的像素。 mask是二进制的,如果目标图像和重建的目标图像之间的最小光度误差小于目标图像和源图像的最小光度误差,则为1,否则为0。
当相机是静止的时,这种方法会图像中的所有像素都被掩盖(实际场景中概率很低)。 当物体以与照相机相同的速度移动时,会导致图像中静止物体的像素被掩盖。
多尺度估计:作者将各个尺度的损失合并在一起。 将较低分辨率的深度图上采样到较高的输入图像分辨率,然后在较高的输入分辨率下重新投影,重新采样并计算光度误差。 作者声称,这使得各个比例尺上的深度图以实现相同的目标,即对目标图像进行精确的高分辨率重建。
其他形式的loss:作者加入了平均归一化的逆深度图值和输入/目标图像之间的边缘敏感的平滑度损失。 这鼓励模型学习尖锐的边缘并消除噪声。
项目地址:https://sites.google.com/view/struct2depth
目标运动建模:来自Google大脑的作者发表了该文章,该文章进一步扩展了Monodepth2。 它们通过预测单个目标而不是整个图像的运动来改善姿态网络估计。 因此,现在重建的图像序列不再是单个投影,而是组合在一起的一系列目标的投影。 这通过两个模型一个目标运动模型和一个相机运动估计网络(类似于前面几节中描述的姿态网络)来做到。 步骤如下:
1.预训练的MASK-RCNN [2]模型用于捕获潜在移动目标的语义分割。
2.使用二进制掩码从静态图像(帧-1,帧0和帧+1)中删除这些可能移动的对象
3.被掩盖的图像被发送到ego-motion(相机自身运动)网络,并输出帧-1和0与帧0和+1之间的转换矩阵。
4.mask过程可提取静态背景,然后提取ego-motion转换矩阵,而无需移动对象。 使用来自[3]的方程。
具体操作时需要注意以下几点
1.使用之前步骤3中产生的相机运动转换矩阵,并将其应用于帧-1和帧+1,用这个矩阵来变换帧0。
2.使用从步骤3得到的相机运动变换矩阵,并将其应用于可能移动的对象的分割mask到帧-1和帧+1,以获取每个目标相当于帧0的形变后的分割mask。
3.二进制掩码用于保持与变形分割掩码关联的像素。
4.mask图像与变形图像组合在一起,并传递到目标运动模型,该模型输出预测的对象运动。
结果显示必须知道相机必如何运动才能“解释”对象外观的变化。 然后,要根据目标运动建模过程的步骤4中生成的运动模型来移动对象。 最后,将形变后的对目标运动与形变后的静态背景结合起来,以获得最终的形变图像:

学习目标尺度:虽然Monodepth2通过其自动mask技术解决了静态物体或以与照相机相同速度移动的物体的问题,但struct2 depth作者还是建议对模型进行约束,以识别物体的比例,从而改善物体运动的建模。
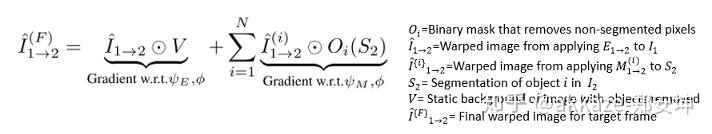
基于对象的类别(例如楼房)定义每个对象的比例loss,旨在基于对象比例的知识来限制深度。 loss是图像中对象的输出深度图与通过使用相机的焦距,基于对象类别的先验高度和图像中分割后的对象的实际高度计算出的近似深度图之间的差 ,两者均按目标图片的平均深度进行缩放