
1. 前言
Middlebury是计算机视觉和三维中间领域著名的高校,特别是提供了著名的立体匹配benchmark数据库,并不断提供新数据的更新。在MVS领域,也同样提供了经典的benchmark数据库,包含两个物体-Temple和Dino,其中Temple有312张相片,Dino有363张相片,如下图所示。并且每个物体还提供了由激光Lidar测量得到的地面真值(Groud Truth)数据,因此可以用来准确的衡量不同MVS算法的准确性(重建的三维模型与真值的差异)和完整性(有多少真值包含在重建的三维模型中)。
在建立该数据库的过程中,Middlebury的研究团队分类总结了当时(2006年)的state-of-art的算法,提出了算法有效性评价标准。基于该标准,并使用该数据库验证这些算法的有效性,最终形成该文章1。这篇文章是后来几乎每一篇研究MVS算法的文章的必引参考文献,其中对于算法的分类介绍和有效性验证规则十分经典,下面分别进行总结。

2. MVS算法分类
MVS是指Multiview Stereo,具体来说是通过多幅已知拍摄方位信息(外方位元素)的图像来估计目标三维信息的算法,数据基于图像的三维重建中一大类非常重要和实用的算法。文章中提到类似的方法还有双目或者三目立体匹配方法,这一类方法能够获得单一的视差图,但是受限于照片数量和拍摄角度,无法覆盖物体的全部表面。另一类方法是多基线立体重建方法,可以构建稀疏特征点集。
一般来说,MVS可以按照如下6个方面的标准进行分类:
- 场景表达方式(scene representation);
- 图像一致性计算方法(photo consistency measure);
- 可见性模型(visible model);
- 在重建时优先考虑的形状约束(shape prior);
- 重建算法(reconstruction algorithm);
- 初始化条件(initialization requirements)。
下面分别对每个方面进行简单的描述。
2.1 场景表达(Scene Representation)
场景表达是指重建得到的三维场景使用什么样的数学模型进行表达,一般来说有如下4种方式:
- 体素(Voxel)
- 层次级(level set):记录每个点到某个最近平面的距离
- 多边形实体(polygon mesh):这是应该是我们最熟悉的表达方式,也是人工三维建模最常见的数据表达方式
- 深度图(depth map):一般基于像方立体匹配算法算法生成的结果就是深度图,每个像素的灰度值代表该像素距离当前图像平面的距离。
2.2 图像一致性计算方法(Photo Consistency Measure)
这部分和双目立体匹配中用到的图像一致性计算方法类似,但是考虑到MVS本身的特殊性,一般来说,MVS中图像一致性计算根据搜索内容的不同分为以下两种方法
1. 基于物方的图像一致性计算方法
通常使用体素表达方法,搜索空间中的每个体素在对应两幅图像中的投影位置的图像一致性,如果该一致性计算值小于某个阈值,则该体素可以认为是代表了真实物体。
2. 基于像方的图像一致性计算方法
根据极线约束,对于一幅图像的某个点,搜索其对应极线上最相似的匹配点(一致性最高),这种方法通常在双目立体视觉中使用。
需要注意的是这两种方法都是基于物体表面为Lambartian的假设,但是也有进一步的研究利用BRDF进行计算,或者考虑物体的阴影,消除物体阴影对于一致性计算的影响。
2.3 可见性模型(Visible Model)
可见性模型是在计算图像一致性时,决定究竟哪些图像和参考图像有共视区域,可以进行图像一致性计算的方法。一般来说,有如下三种模型
- 几何模型。
- 准几何模型。
- 基于粗差(outlier)的模型,通常是将遮挡视为粗差,因为对于一个点来说,在两视中被看到的可能性大于被遮挡的可能性。
2.4 在重建时优先考虑的形状约束(Shape Prior)
由于常见的弱纹理(大范围区域颜色相同或者相近)或者无纹理等原因,导致在匹配是在这些区域无法得到良好的匹配结果,因此需要引入形状约束来近似约束这些区域的可能形状,可以使得最终得到的场景具有某种特殊的性质。这种方法在双目立体匹配的研究中是极为常见的方法,但是在MVS中,由于多幅图像提供更强的约束,较少使用这种方法。常见的形状约束方法如下:
- 基于场景重建的技术通常采用“最少平面数”约束,因为过多的多边形面片会使得场景过于破碎。
- 基于体素和Space carve的重建方法通常增加“最多平面数”约束,使得表面具有更加丰富的细节。
- 在基于像方的匹配方法中,通常添加局部平滑约束:例如双目立体匹配中常见的piece-wise smothness,假设场景中的弱纹理区域是与摄影平面平行的小平面。
2.5 重建算法(Reconstruction Algorithm)
- 体素着色算法:从一个volumn中提取一个平面出来
- 通过递推的方法展开一个平面:在过程中最小化代价函数(based on voxels, level-set, mesh)
- 基于像方的匹配,生成深度图,并对不同图像间的深度图进行融合
- 提取特征点,拟合一个面来重建特征
2.6 初始化条件(Initialization Requirements)
- 需要图像集(毕竟是基于图像的三维重建,需要尽可能多的多角度拍摄的同一场景的图像)
- 几乎所有的算法都要求或者假设待重建三维目标的空间范围或者scene geometry
- 基于像方的方法要求最大/最小视差(这一点要求和2类似)
3. MVS算法的评价
文章中提出,对于MVS算法应该从一下两个方面进行评价
1. 准确性
准确性是指重建结果与真值间的差距,一般方法是,对于重建结果中的一个三维空间点,寻找其对应真值中的点,计算其距离,最后统计所有点距离真值的距离。 根据统计结果来评价重建结果的准确性。
2. 完整性
完整性是指有多少真值被包含在重建结果中。一般方法与准确性计算类似,但是是计算真值中的点到重建结果中最近点的距离,统计所有真值点的计算结果来评价重建的完整性。需要注意的是,如果真值中的点距离重建结果中最近点的距离大于某个阈值,则认为是没有找打匹配点,也就是该真值点没有被覆盖。
SFM的重建成果是稀疏三维点云,而MVS可以获得更好的结果
(1)如何理解密集点云的生成原理
MVS是生成密集点云的方法,事实上,为什么我们在SFM中不能得到密集点云?因为,SFM中我们用来做重建的点是由特征匹配提供的!这些匹配点天生不密集!而使用计算机来进行三维点云重建,我们必须认识到,点云的密集程度是由人为进行编程进行获取的。SFM获得点的方式决定了它不可能直接生成密集点云。
而MVS则几乎对照片中的每个像素点都进行匹配,几乎重建每一个像素点的三维坐标,这样得到的点的密集程度可以较接近图像为我们展示出的清晰度。
其实现的理论依据在于,多视图照片间,对于拍摄到的相同的三维几何结构部分,存在极线几何约束。
描述这种几何约束:
想象,对于在两张图片中的同一个点。现在回到拍摄照片的那一刻,在三维世界中,存在一条光线从照片上这一点,同时穿过拍摄这张照片的相机的成像中心点,最后会到达空间中一个三维点,这个三维点同时也会在另一张照片中以同样的方式投影。
这个过程这样看来,很普通,就如同普通的相机投影而已。但是因为两张图片的原因,他们之间存在联系,这种联系的证明超过了能力范围,但是我们只需要知道,此种情况下,两张照片天然存在了一种约束。
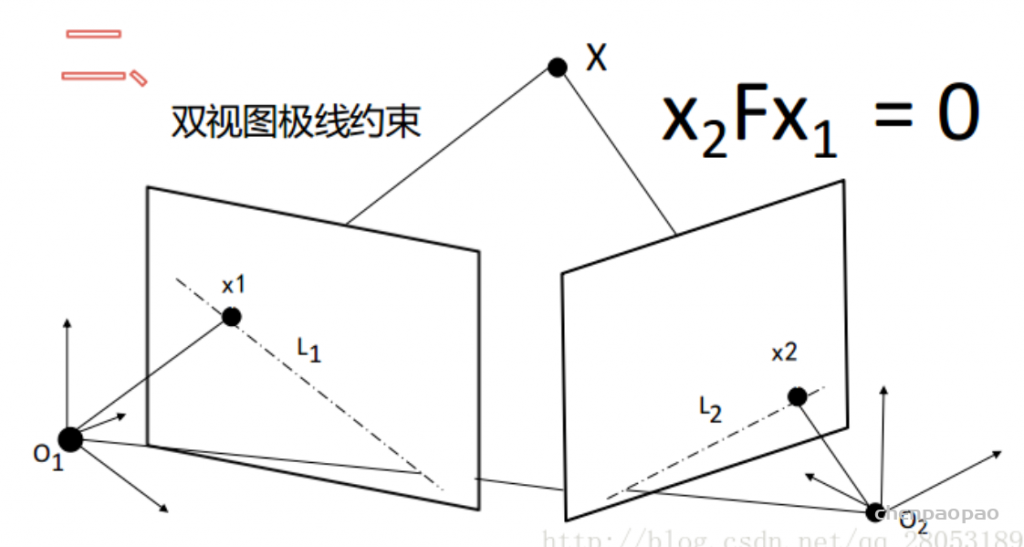
X表示空间中的一点,x1、x2为X在两张图片中的同一点。由于天然的约束,已知x1,想要在另一张图片中找到x2,可以在直线L2上进行一维寻找。 MVS主要做的就是如何最佳搜索匹配不同相片的同一个点。
2)初步探究MVS中的点匹配方法
在有了约束的基础上,接下来就是在图片上的一条线上进行探测,寻找两张图片上的同一点。主要方法为逐像素判断,两个照片上的点是否是同一点——为此提出图像点间的“一致性判定函数”
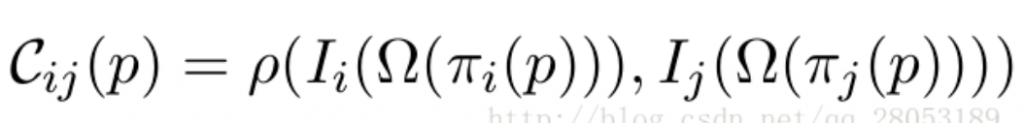
π (p)是使得点p投影到照片上一点的函数, Ω(x) 函数定义了一个点x周围的区域,I(x) 函数代表了照片区域的强度特征,ρ(f, g) 是用来比较两个向量之间的相似程度的
ρ函数和Ω函数的具体选择决定这个”一致性判别“的准确度。这个函数的具体实现,由编程实现。
参考文献
- Seitz, S. M., Curless, B., Diebel, J., Scharstein, D., & Szeliski, R. (n.d.). A Comparison and Evaluation of Multi-View Stereo Reconstruction Algorithms. In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition – Volume 1 (CVPR’06) (Vol. 1, pp. 519–528). IEEE. https://doi.org/10.1109/CVPR.2006.19