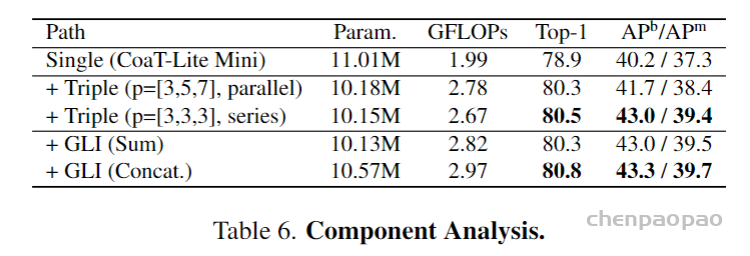
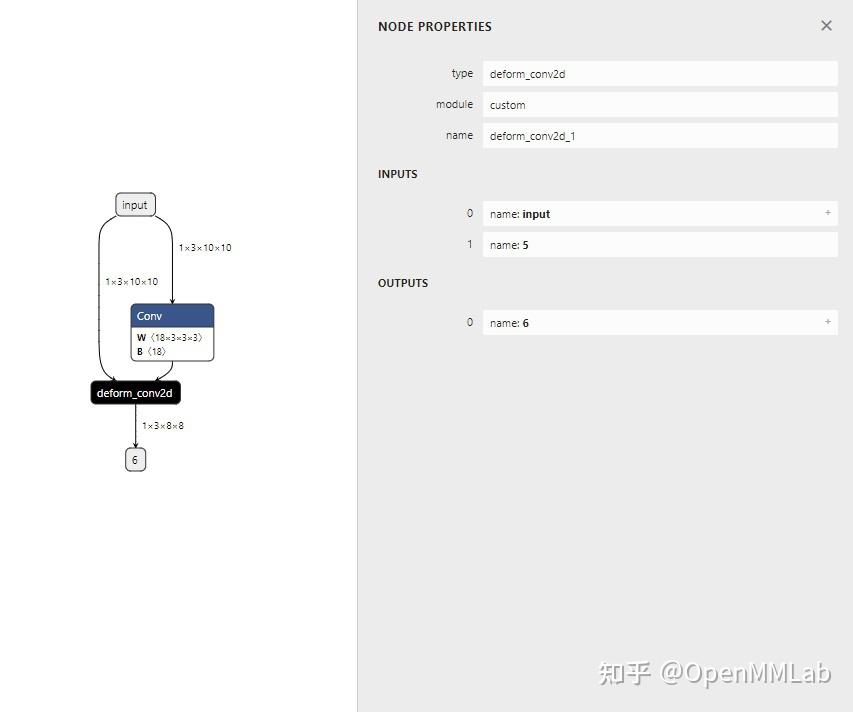
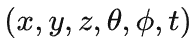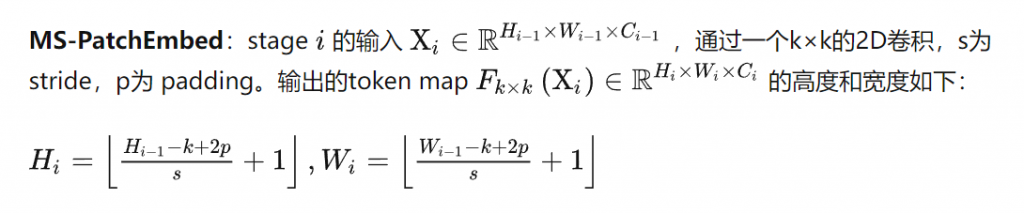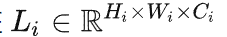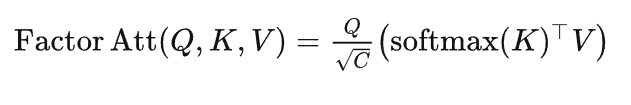摘自:https://zhuanlan.zhihu.com/p/486914187
官网:https://pytorch.org/docs/stable/jit.html
PyTorch 无疑是现在最成功的深度学习训练框架之一,是各种顶会顶刊论文实验的大热门。比起其他的框架,PyTorch 最大的卖点是它对动态网络的支持,比其他需要构建静态网络的框架拥有更低的学习成本。PyTorch 源码 Readme 中还专门为此做了一张动态图:

对研究员而言, PyTorch 能极大地提高想 idea、做实验、发论文的效率,是训练框架中的豪杰,但是它不适合部署。动态建图带来的优势对于性能要求更高的应用场景而言更像是缺点,非固定的网络结构给网络结构分析并进行优化带来了困难,多数参数都能以 Tensor 形式传输也让资源分配变成一件闹心的事。另外由于图是由 python 代码构建的,一方面部署要依赖 python 环境,另一方面模型也毫无保密性可言。
而 TorchScript 就是为了解决这个问题而诞生的工具。包括代码的追踪及解析、中间表示的生成、模型优化、序列化等各种功能,可以说是覆盖了模型部署的方方面面。
TorchScript
动态图模型通过牺牲一些高级特性来换取易用性,那到底 JIT 有哪些特性,在什么情况下不得不用到 JIT 呢?下面主要通过介绍 TorchScript(PyTorch 的 JIT 实现)来分析 JIT 到底带来了哪些好处。
- 模型部署
PyTorch 的 1.0 版本发布的最核心的两个新特性就是 JIT 和 C++ API,这两个特性一起发布不是没有道理的,JIT 是 Python 和 C++ 的桥梁,我们可以使用 Python 训练模型,然后通过 JIT 将模型转为语言无关的模块,从而让 C++ 可以非常方便得调用,从此「使用 Python 训练模型,使用 C++ 将模型部署到生产环境」对 PyTorch 来说成为了一件很容易的事。而因为使用了 C++,我们现在几乎可以把 PyTorch 模型部署到任意平台和设备上:树莓派、iOS、Android 等等…
2. 性能提升
既然是为部署生产所提供的特性,那免不了在性能上面做了极大的优化,如果推断的场景对性能要求高,则可以考虑将模型(torch.nn.Module)转换为 TorchScript Module,再进行推断。
3. 模型可视化
TensorFlow 或 Keras 对模型可视化工具(TensorBoard等)非常友好,因为本身就是静态图的编程模型,在模型定义好后整个模型的结构和正向逻辑就已经清楚了;但 PyTorch 本身是不支持的,所以 PyTorch 模型在可视化上一直表现得不好,但 JIT 改善了这一情况。现在可以使用 JIT 的 trace 功能来得到 PyTorch 模型针对某一输入的正向逻辑,通过正向逻辑可以得到模型大致的结构,但如果在 `forward` 方法中有很多条件控制语句,这依然不是一个好的方法,所以 PyTorch JIT 还提供了 Scripting 的方式。
TorchScript Module 的两种生成方式
1. 编码(Scripting)
可以直接使用 TorchScript Language 来定义一个 PyTorch JIT Module,然后用 torch.jit.script 来将他转换成 TorchScript Module 并保存成文件。而 TorchScript Language 本身也是 Python 代码,所以可以直接写在 Python 文件中。
使用 TorchScript Language 就如同使用 TensorFlow 一样,需要前定义好完整的图。对于 TensorFlow 我们知道不能直接使用 Python 中的 if 等语句来做条件控制,而是需要用 tf.cond,但对于 TorchScript 我们依然能够直接使用 if 和 for 等条件控制语句,所以即使是在静态图上,PyTorch 依然秉承了「易用」的特性。TorchScript Language 是静态类型的 Python 子集,静态类型也是用了 Python 3 的 typing 模块来实现,所以写 TorchScript Language 的体验也跟 Python 一模一样,只是某些 Python 特性无法使用(因为是子集),可以通过 TorchScript Language Reference 来查看和原生 Python 的异同。
理论上,使用 Scripting 的方式定义的 TorchScript Module 对模型可视化工具非常友好,因为已经提前定义了整个图结构。
2. 追踪(Tracing)
使用 TorchScript Module 的更简单的办法是使用 Tracing,Tracing 可以直接将 PyTorch 模型(torch.nn.Module)转换成 TorchScript Module。「追踪」顾名思义,就是需要提供一个「输入」来让模型 forward 一遍,以通过该输入的流转路径,获得图的结构。这种方式对于 forward 逻辑简单的模型来说非常实用,但如果 forward 里面本身夹杂了很多流程控制语句,则可能会有问题,因为同一个输入不可能遍历到所有的逻辑分枝。
此外,还可以混合使用上面两种方式。
模型转换
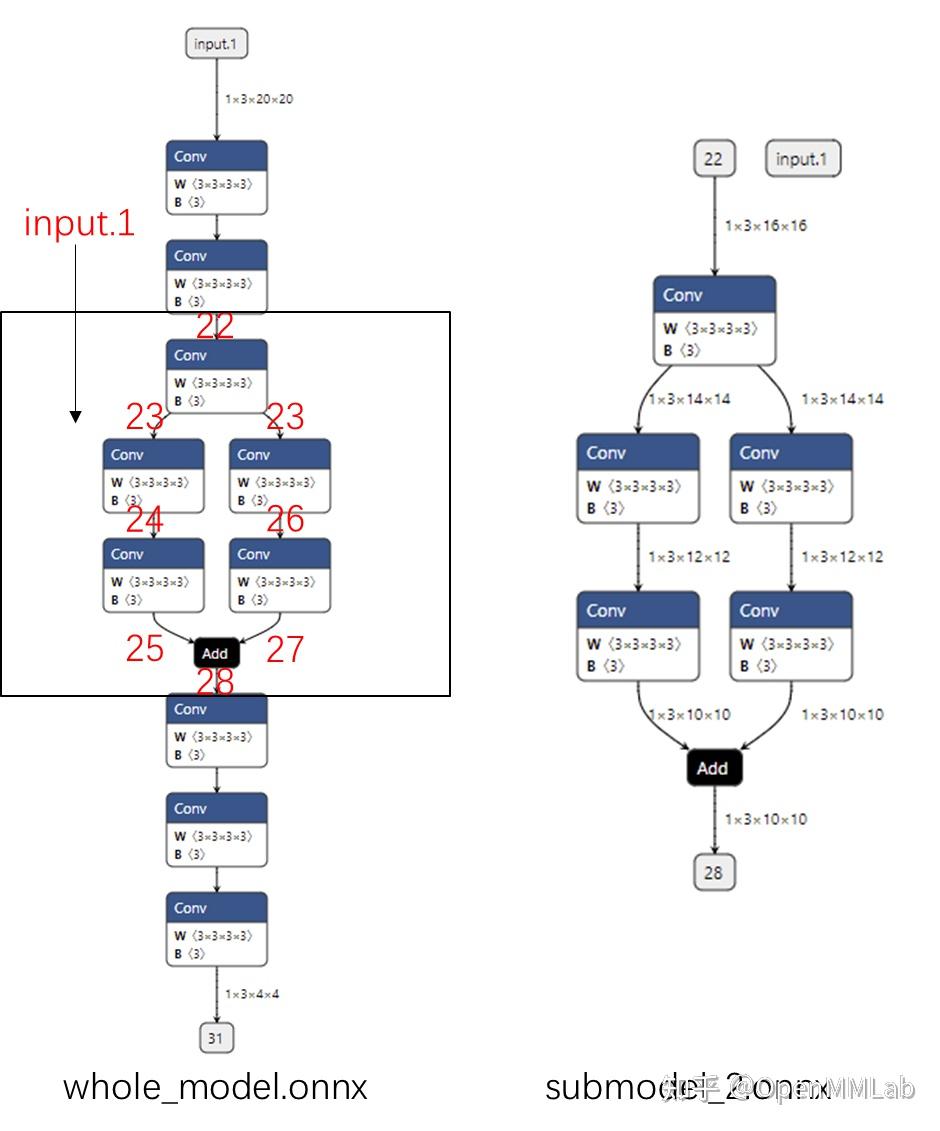
作为模型部署的一个范式,通常我们都需要生成一个模型的中间表示(IR),这个 IR 拥有相对固定的图结构,所以更容易优化,让我们看一个例子:
import torch
from torchvision.models import resnet18
# 使用PyTorch model zoo中的resnet18作为例子
model = resnet18()
model.eval()
# 通过trace的方法生成IR需要一个输入样例
dummy_input = torch.rand(1, 3, 224, 224)
# IR生成
with torch.no_grad():
jit_model = torch.jit.trace(model, dummy_input) JIT 是一种概念,全称是 Just In Time Compilation,中文译为「即时编译」,是一种程序优化的方法
到这里就将 PyTorch 的模型转换成了 TorchScript 的 IR。这里我们使用了 trace 模式来生成 IR,所谓 trace 指的是进行一次模型推理,在推理的过程中记录所有经过的计算,将这些记录整合成计算图。
那么这个 IR 中到底都有些什么呢?我们可以可视化一下其中的 layer1 看看:
jit_layer1 = jit_model.layer1
print(jit_layer1.graph)
# graph(%self.6 : __torch__.torch.nn.modules.container.Sequential,
# %4 : Float(1, 64, 56, 56, strides=[200704, 3136, 56, 1], requires_grad=0, device=cpu)):
# %1 : __torch__.torchvision.models.resnet.___torch_mangle_10.BasicBlock = prim::GetAttr[name="1"](%self.6)
# %2 : __torch__.torchvision.models.resnet.BasicBlock = prim::GetAttr[name="0"](%self.6)
# %6 : Tensor = prim::CallMethod[name="forward"](%2, %4)
# %7 : Tensor = prim::CallMethod[name="forward"](%1, %6)
# return (%7) 是不是有点摸不着头脑?TorchScript 有它自己对于 Graph 以及其中元素的定义,对于第一次接触的人来说可能比较陌生,但是没关系,我们还有另一种可视化方式:
print(jit_layer1.code)
# def forward(self,
# argument_1: Tensor) -> Tensor:
# _0 = getattr(self, "1")
# _1 = (getattr(self, "0")).forward(argument_1, )
# return (_0).forward(_1, ) 没错,就是代码!TorchScript 的 IR 是可以还原成 python 代码的,如果你生成了一个 TorchScript 模型并且想知道它的内容对不对,那么可以通过这样的方式来做一些简单的检查。
刚才的例子中我们使用 trace 的方法生成IR。除了 trace 之外,PyTorch 还提供了另一种生成 TorchScript 模型的方法:script。这种方式会直接解析网络定义的 python 代码,生成抽象语法树 AST,因此这种方法可以解决一些 trace 无法解决的问题,比如对 branch/loop 等数据流控制语句的建图。script方式的建图有很多有趣的特性,会在未来的分享中做专题分析,敬请期待。
模型优化
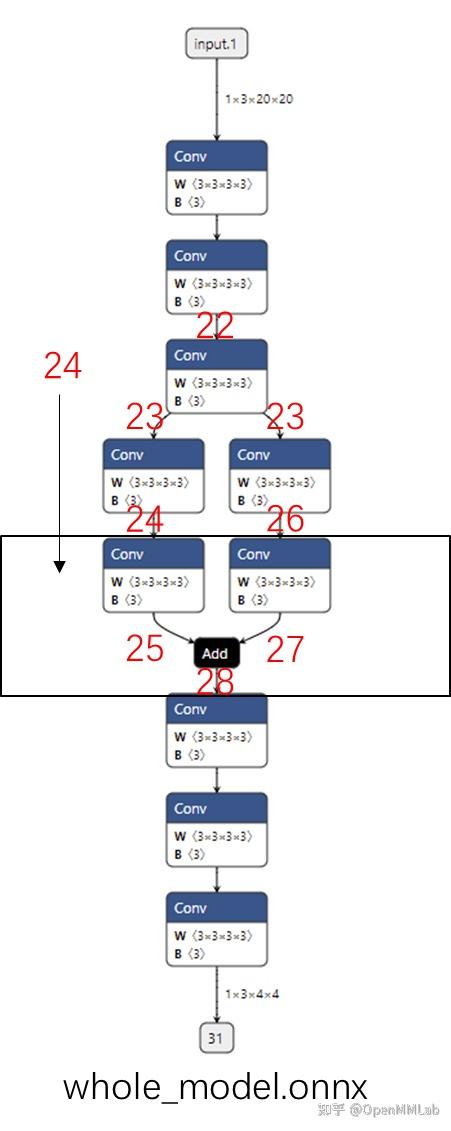
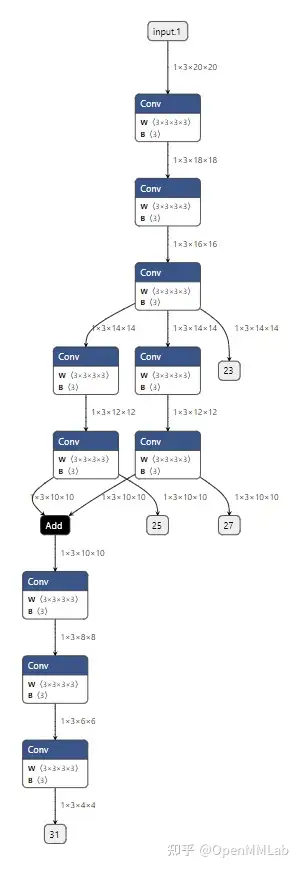
聪明的同学可能发现了,上面的可视化中只有resnet18里forward的部分,其中的子模块信息是不是丢失了呢?如果没有丢失,那么怎么样才能确定子模块的内容是否正确呢?别担心,还记得我们说过 TorchScript 支持对网络的优化吗,这里我们就可以用一个pass解决这个问题:
# 调用inline pass,对graph做变换
torch._C._jit_pass_inline(jit_layer1.graph)
print(jit_layer1.code)
# def forward(self,
# argument_1: Tensor) -> Tensor:
# _0 = getattr(self, "1")
# _1 = getattr(self, "0")
# _2 = _1.bn2
# _3 = _1.conv2
# _4 = _1.bn1
# input = torch._convolution(argument_1, _1.conv1.weight, None, [1, 1], [1, 1], [1, 1], False, [0, 0], 1, False, False, True, True)
# _5 = _4.running_var
# _6 = _4.running_mean
# _7 = _4.bias
# input0 = torch.batch_norm(input, _4.weight, _7, _6, _5, False, 0.10000000000000001, 1.0000000000000001e-05, True)
# input1 = torch.relu_(input0)
# input2 = torch._convolution(input1, _3.weight, None, [1, 1], [1, 1], [1, 1], False, [0, 0], 1, False, False, True, True)
# _8 = _2.running_var
# _9 = _2.running_mean
# _10 = _2.bias
# out = torch.batch_norm(input2, _2.weight, _10, _9, _8, False, 0.10000000000000001, 1.0000000000000001e-05, True)
# input3 = torch.add_(out, argument_1, alpha=1)
# input4 = torch.relu_(input3)
# _11 = _0.bn2
# _12 = _0.conv2
# _13 = _0.bn1
# input5 = torch._convolution(input4, _0.conv1.weight, None, [1, 1], [1, 1], [1, 1], False, [0, 0], 1, False, False, True, True)
# _14 = _13.running_var
# _15 = _13.running_mean
# _16 = _13.bias
# input6 = torch.batch_norm(input5, _13.weight, _16, _15, _14, False, 0.10000000000000001, 1.0000000000000001e-05, True)
# input7 = torch.relu_(input6)
# input8 = torch._convolution(input7, _12.weight, None, [1, 1], [1, 1], [1, 1], False, [0, 0], 1, False, False, True, True)
# _17 = _11.running_var
# _18 = _11.running_mean
# _19 = _11.bias
# out0 = torch.batch_norm(input8, _11.weight, _19, _18, _17, False, 0.10000000000000001, 1.0000000000000001e-05, True)
# input9 = torch.add_(out0, input4, alpha=1)
# return torch.relu_(input9) 这里我们就能看到卷积、batch_norm、relu等熟悉的算子了。
上面代码中我们使用了一个名为inline的pass,将所有子模块进行内联,这样我们就能看见更完整的推理代码。pass是一个来源于编译原理的概念,一个 TorchScript 的 pass 会接收一个图,遍历图中所有元素进行某种变换,生成一个新的图。我们这里用到的inline起到的作用就是将模块调用展开,尽管这样做并不能直接影响执行效率,但是它其实是很多其他pass的基础。PyTorch 中定义了非常多的 pass 来解决各种优化任务,未来我们会做一些更详细的介绍。
序列化
不管是哪种方法创建的 TorchScript 都可以进行序列化,比如:
# 将模型序列化
jit_model.save('jit_model.pth')
# 加载序列化后的模型
jit_model = torch.jit.load('jit_model.pth') 序列化后的模型不再与 python 相关,可以被部署到各种平台上。
PyTorch 提供了可以用于 TorchScript 模型推理的 c++ API,序列化后的模型终于可以不依赖 python 进行推理了:
// 加载生成的torchscript模型
auto module = torch::jit::load('jit_model.pth');
// 根据任务需求读取数据
std::vector<torch::jit::IValue> inputs = ...;
// 计算推理结果
auto output = module.forward(inputs).toTensor(); 与 torch.onnx 的关系:ONNX 是业界广泛使用的一种神经网络中间表示,PyTorch 自然也对 ONNX 提供了支持。torch.onnx.export函数可以帮助我们把 PyTorch 模型转换成 ONNX 模型,这个函数会使用 trace 的方式记录 PyTorch 的推理过程。聪明的同学可能已经想到了,没错,ONNX 的导出,使用的正是 TorchScript 的 trace 工具。具体步骤如下:
- 使用 trace 的方式先生成一个 TorchScipt 模型,如果你转换的本身就是 TorchScript 模型,则可以跳过这一步。
- 使用许多 pass 对 1 中生成的模型进行变换,其中对 ONNX 导出最重要的一个 pass 就是
ToONNX,这个 pass 会进行一个映射,将 TorchScript 中prim、aten空间下的算子映射到onnx空间下的算子。 - 使用 ONNX 的 proto 格式对模型进行序列化,完成 ONNX 的导出。