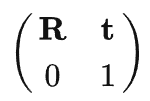教程文档:
【1】https://docs.nvidia.com/deeplearning/tensorrt/index.html
【2】https://developer.nvidia.com/zh-cn/tensorrt
【4】github: https://github.com/NVIDIA/TensorRT
[5] pytorch-onnx-tensorrt全链路简单教程(支持动态输入)
[6] Pytorch转onnx, TensorRT踩坑实录
流程:
(1)Torch模型转onnx
(2)Onnx转TensorRT engine文件
(3)TensorRT加载engine文件并实现推理
Torch模型转onnx:
def torch_2_onnx(model, MODEL_ONNX_PATH ):
OPERATOR_EXPORT_TYPE = torch._C._onnx.OperatorExportTypes.ONNX
"""
这里构建网络的输入,有几个就构建几个
和网络正常的inference时输入一致就可以
"""
org_dummy_input = (inputs_1, inputs_2, inputs_3, inputs_4)
#这是支持动态输入和输出的第一步
#每一个输入和输出中动态的维度都要在此注明,下标从0开始
dynamic_axes = {
'inputs_1': {0:'batch_size', 1:'text_length'},
'inputs_2': {0:'batch_size', 1:'text_length'},
'inputs_3': {0:'batch_size', 1:'text_length'},
'inputs_4': {0:'batch_size', 1:'text_length'},
'outputs': {0:'batch_size', 1:'text_length'},
}
output = torch.onnx.export( model,
org_dummy_input,
MODEL_ONNX_PATH,
verbose=True,
opset_version=11,
operator_export_type=OPERATOR_EXPORT_TYPE,
input_names=['inputs_1', 'inputs_2', 'inputs_3', 'inputs_4'],
output_names=['outputs'],
dynamic_axes=dynamic_axes
)
print("Export of model to {}".format(MODEL_ONNX_PATH))
使用onnxruntime进行验证
1. 安装onnxruntime
pip install onnxruntime
2. 使用onnxruntime验证
import onnxruntime as ort
ort_session = ort.InferenceSession('xxx.onnx')
img = cv2.imread('test.jpg')
net_input = preprocess(img) # 你的预处理函数
outputs = ort_session.run(None, {ort_session.get_inputs()[0].name: net_input})
print(outputs)
3. 上面的这段代码有一点需要注意,可以发现通过ort_session.get_inputs()[0].name可以得到输入的tensor名称,同理,也可以通过ort_session.get_outputs()[0].name来获得输出tensor的名称,如果你的网络有两个输出,则使用ort_session.get_outputs()[0].name和ort_session.get_outputs()[1].name来获得,这里得到的名称在后续tensorrt调用中会使用onnx转TensorRT的engine文件:
import tensorrt as trt
import sys
import os
def ONNX_build_engine(onnx_file_path, write_engine = False):
'''
通过加载onnx文件,构建engine
:param onnx_file_path: onnx文件路径
:return: engine
'''
G_LOGGER = trt.Logger(trt.Logger.WARNING)
# 1、动态输入第一点必须要写的
explicit_batch = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
batch_size = 10 # trt推理时最大支持的batchsize
with trt.Builder(G_LOGGER) as builder, builder.create_network(explicit_batch) as network, trt.OnnxParser(network, G_LOGGER) as parser:
builder.max_batch_size = batch_size
config = builder.create_builder_config()
config.max_workspace_size = common.GiB(2) #common文件可以自己去tensorrt官方例程下面找
config.set_flag(trt.BuilderFlag.FP16)
print('Loading ONNX file from path {}...'.format(onnx_file_path))
with open(onnx_file_path, 'rb') as model:
print('Beginning ONNX file parsing')
parser.parse(model.read())
print('Completed parsing of ONNX file')
print('Building an engine from file {}; this may take a while...'.format(onnx_file_path))
# 重点
profile = builder.create_optimization_profile() #动态输入时候需要 分别为最小输入、常规输入、最大输入
# 有几个输入就要写几个profile.set_shape 名字和转onnx的时候要对应
profile.set_shape("inputs_1", (1,3), (1,256), (10,512))
profile.set_shape("inputs_2", (1,3), (1,256), (10,512))
profile.set_shape("inputs_3", (1,3), (1,256), (10,512))
profile.set_shape("inputs_4", (1,3), (1,256), (10,512))
config.add_optimization_profile(profile)
engine = builder.build_engine(network, config)
print("Completed creating Engine")
# 保存engine文件
if write_engine:
engine_file_path = 'correction_fp16.trt'
with open(engine_file_path, "wb") as f:
f.write(engine.serialize())
return engineTensorRT 加载engine文件并进行推理:
def trt_inference(engine_file):
#此处的输入应当转成numpy的array,同时dtype一定要和原网络一致不然结果会不对
inputs_1= np.array(inputs_1, dtype=np.int32, order='C')
inputs_2= np.array(inputs_2, dtype=np.int32, order='C')
inputs_3= np.array(inputs_3, dtype=np.int32, order='C')
inputs_4= np.array(inputs_4, dtype=np.int32, order='C')
with get_engine(engine_file) as engine, engine.create_execution_context() as context:
#增加部分 动态输入需要
context.active_optimization_profile = 0
origin_inputshape=context.get_binding_shape(0)
origin_inputshape[0],origin_inputshape[1]=inputs_1.shape
context.set_binding_shape(0, (origin_inputshape)) #若每个输入的size不一样,可根据inputs_i的size更改对应的context中的size
context.set_binding_shape(1, (origin_inputshape))
context.set_binding_shape(2, (origin_inputshape))
context.set_binding_shape(3, (origin_inputshape))
#增加代码结束
inputs, outputs, bindings, stream = common.allocate_buffers(engine, context)
# Do inference
inputs[0].host = inputs_1
inputs[1].host = inputs_2
inputs[2].host = inputs_3
inputs[3].host = inputs_4
trt_outputs = common.do_inference_v2(context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream)
def get_engine(engine_path ):
logger = trt.Logger(trt.Logger.INFO)
trt.init_libnvinfer_plugins(logger, namespace="")
with open(engine_path, 'rb') as f, trt.Runtime(logger) as runtime:
return runtime.deserialize_cuda_engine(f.read())
common文件中的allcate_buffers()函数:
def allocate_buffers(engine, context):
inputs = []
outputs = []
bindings = []
stream = cuda.Stream()
for i, binding in enumerate(engine):
size = trt.volume(context.get_binding_shape(i))
dtype = trt.nptype(engine.get_binding_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(device_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
inputs.append(HostDeviceMem(host_mem, device_mem))
else:
outputs.append(HostDeviceMem(host_mem, device_mem))
return inputs, outputs, bindings, stream