

论文: https://arxiv.org/abs/2404.19756
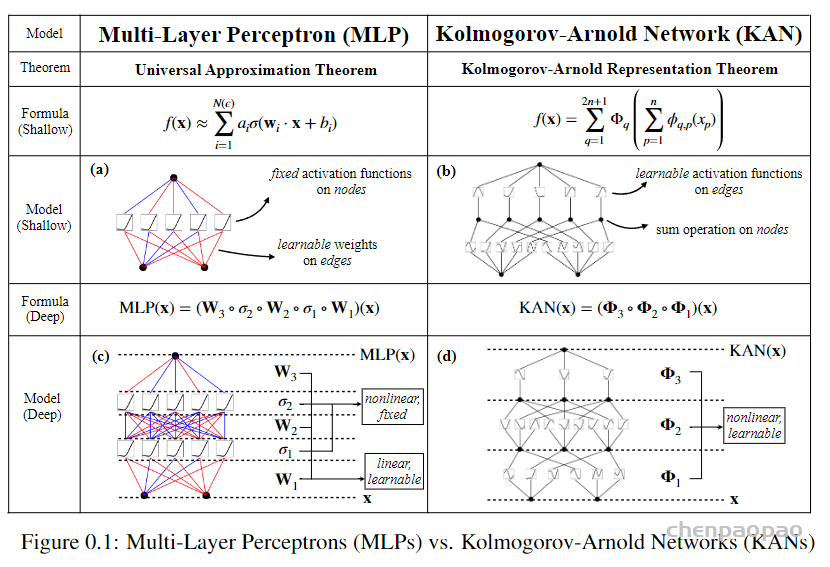
一、MLP 本质回顾
MLP 本质上是用一个线性模型外面包了一层非线性激活函数来实现非线性空间变换。线性模型的好处在于简单,每条边就是两个参数w和b,合到一起用向量矩阵表示 W。
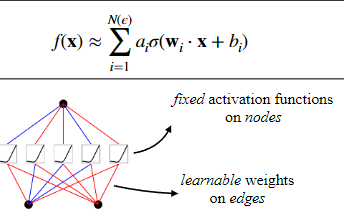
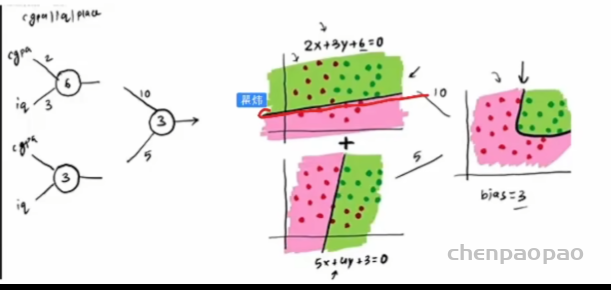
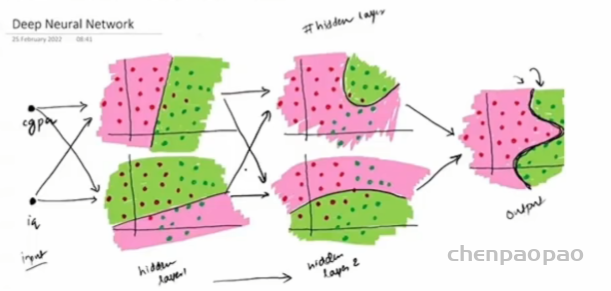
比如下面的图,通过结合两个线性决策边界并在第二层应用激活函数,形成了一个非线性决策边界。两个线性决策边界,每一个由一条直线表示,分别是2x+3y+6=0 和5x+3y=0。这些直线分别在二维空间中划分出了不同的区域。第一层的输出通常会作为第二层的输入。然后再次通过激活函数进行处理。形成了一个复杂的、非线性的曲线形状的决策边界。这是因为每个线性模型的输出都受到了非线性激活函数的影响,允许模型捕捉更复杂的数据模式。多层结构和非线性激活函数使得网络能够将简单的线性决策边界通过复合和变换,转化为能够解决更复杂分类问题的非线性决策边界。
从理论上讲,一个包含足够多神经元的单隐藏层网络可以逼近任何连续函数(这是由通用近似定理保证的)。比如下图所示分类界面变成了曲面。
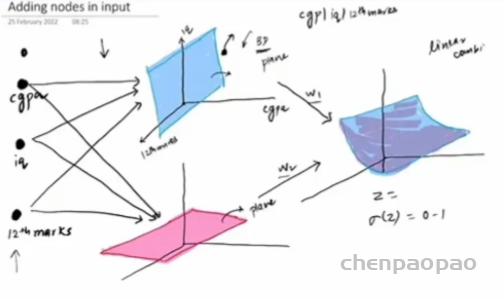
在 MLP 中,每层都进行线性变换后跟非线性操作。这种层级结构允许模型学习数据的多层次特征表示。随着层数的增加,模型的表示能力也随之增强。比如下图,这就是深度学习管用的根本原因,越深越牛逼。
表达成线性代数的矩阵形式,就是下面的公式:
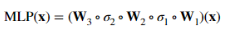
在这个表达式中,圆圈(·)表示的是函数组合运算,也就是函数复合的意思。用图表示就是我们常见的形式:
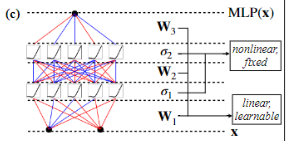
注意:这里所有的激活函数都尽量使用相同的进行简化。当然有的时候用两个
你可能会问,为什么神经网络一定要用 MLP的形式?没有什么为什么,因为它管用,它简单,奥卡姆剃刀原理。适合用来理解基本的前向传播和反向传播算法,也易于用各种编程语言和框架实现。因此,历史上就选它了,整个深度学习的基础。
二、MLP 的硬伤注定了深度学习大厦的脆弱?
MLP 也就是全连接网络可以说是整个深度学习的基础,后面所有的网络无论CNN/RNN/transformer 都是在它基础上的修改,即便是现在吹牛逼不上税的大模型们。但谁能想到它居然是个有天然硬伤的豆腐渣模块呢?
1.梯度消失和梯度爆炸:当使用传统的激活函数(如Sigmoid或Tanh)时,MLP 在进行反向传播计算梯度时确实容易遇到梯度消失或梯度爆炸的问题,会出现激活函数的导数连乘积(画图)。当它非常小或非常大,网络又很深,连续乘积会使得梯度趋向于0(梯度消失)或变得异常大(梯度爆炸),从而阻碍学习过程。
2.参数效率低:MLP 通常使用全连接层,这意味着每层的每个神经元都与前一层的所有神经元相连接,导致参数数量迅速增加,尤其是对于输入维度很高的数据(比如图像数据)。这不仅增加了计算负担,也增加了模型过拟合的风险。这就是大模型的困境,拼参数量没出路,大部分学习都是浪费掉的,效率巨低下无比,好比人海战术。
3.处理高维数据的能力有限:MLP没有利用数据的内在结构(如图像中的局部空间相关性或文本数据的序列信息)。例如,在图像处理中,MLP 无法有效地利用像素之间的局部空间关联,这使得其在图像识别等任务上的性能不如卷积神经网络(CNN)。
4、长期依赖问题:虽然 MLP 理论上可以逼近任何函数,但在实际应用中,它们很难捕捉到输入序列中的长期依赖关系(长时间跨度的相关信息)。这一点在处理时间序列或自然语言处理任务时尤为明显,而循环神经网络(RNN)和transformer在这些任务中通常表现得更好。
但无论 CNN/RNN/transformer 怎么改进,都躲不掉 MLP 这个基础模型根上的硬伤就是这个线性组合+激活函数的模式。进而决定了整个深度学习大厦的脆弱。就好比板砖出现了问题。那能不能替换掉这种板砖呢?谈何容易,既要解决函数拟合准确度的问题,又要保证神经网络的效率,这不亚于重新发明深度学习这个学科。因此虽然理论上任何结构都可以,但并没有出现一种更好的基础模型组件。这恰恰是 KAN 网络带给大家的惊喜,也给发展了十几年沉闷的深度学习世界带来了一丝变革的曙光。我们来看它具体干了什么?
三、KAN 网络为什么牛逼?
Kolmogorov-Arnold Networks 顾名思义基于柯尔莫果洛夫-阿诺尔德表示定理。是由这两个俄罗斯数学家 1957 年提出的如何用一组较简单的函数来表示任何一个多变量的连续函数。
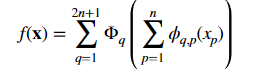
想象一下,你有一个非常复杂的配方,需要各种各样的原料和步骤来制作一道菜。柯尔莫果洛夫·阿诺尔德表示定理告诉我们,无论这个配方多么复杂,我们总能找到一种方法,通过一些简单的基本步骤(这里是一些基本的函数)来重现这道菜的味道。在上面的式子中,输入是x,φq.p(xp)是基本的一元函数,就像是青椒西红柿基本原料的处理。内层求和就是放到一起。中q是外层的函数,各自接受内层求和的结果作为输入。外层的求和 ∑表示整个函数 fx) 是子函数中q 的和。用图来表示就相当于一个两层的神经网络,区别在于一没了线性组合,而是直接对输入进行激活;二来这些激活函数不是固定的,而是可以学习的。
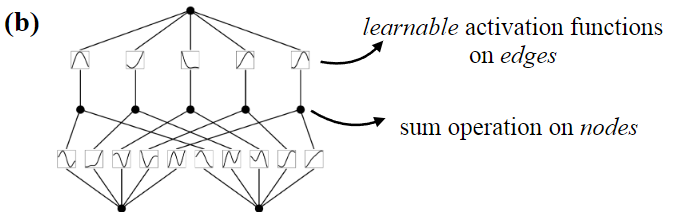
和 MLP 每层统一进行非线性空间变换相比,这相当于对每个坐标轴单独进行非线性变换,然后再组合形成多维度空间。(画个简图,先组合再变形和先单个变形再简单组合的区别)
公式写成向量的形式就是:
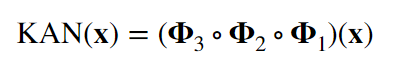
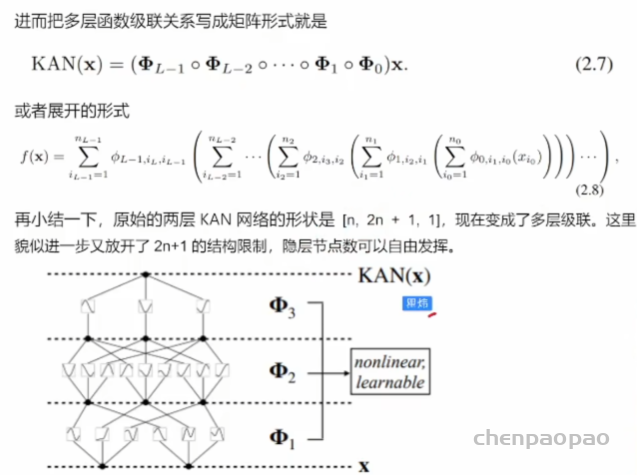
对比 MLP,没有了激活函数和参数矩阵的嵌套关系,而直接是非线性函数中的嵌套。对于多层网络,这相当于下面的结构:
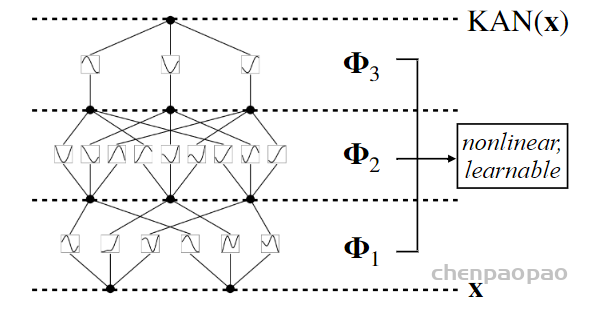
注意这里所有的非线性函数中都采用同样的函数结构,只是用不同的参数来控制其形状。具体来说,文章选择了数值分析中的样条函数 spline。这个英语单词 spline 来源于可变形的样条工具,那是一种在造船和工程制图时用来画出光滑形状的工具。
对比 MLP 和 KAN,最大的区别就是变固定的非线性激活+线性参数学习为直接对参数化的非线性激活函数的学习。因为参数本身的复杂度,显然单个spline 函数的学习难度要比线性函数难,但 KANS通常允许比 MLPs 更小的计算图,也就是实现同样效果,需要的网络规模更小。例如,文章展示了在解偏微分方程(PDE)的过程中,一个2层宽度为10的 KAN 比一个4层宽度为 100 的 MLP 具有更高的准确度(均方误差 10^-7 对比10^-5)并且具有更高的参数效率(参数数量100 对比 10000)。
到这里为止,你一定好奇,这IDEA不复杂啊,难道以前没人想到,有,但是卡壳在都坚持使用原始的二层宽度为(2n+1)的表示方法,并没有机会利用更现代的技术(例如,反向传播)来训练网络。KAN 模型的贡献就在于通过进一步简化推广到任意宽度和深度,同时通过广泛的实证实验论证了在 AI + 科学方面的效果,而且具备很好的准确性和可解释性。这就牛通了啊,深度学习最大的问题就是个黑盒子,训练网络像是炼丹。大模型越弄越大,很可能一条道走到黑就进死胡同了。好比芯片的摩尔定律。现在出现了量子芯片,原理上就不同,从而有可能实现根本性的变革。当然,原来的各种网络结构还能平替重做一遍,有没有感觉一片 AI 新大陆向你招手了。我一直劝大家别太短视,成天只盯着transformer,大模型兜兜转转,撑死了也是井中之蛙。
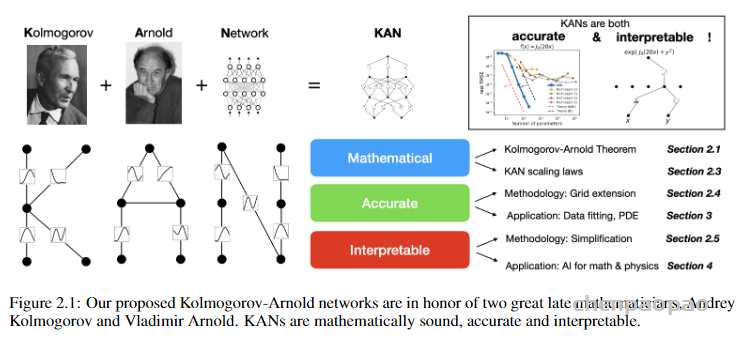
四、KAN 的架构细节
4.1 详细解释
整个网络架构原理看图一目了然。很多个这种类似四分之三个周期的正弦函数组合起来就能拟合任意形状的函数。换句话说,用 B-spline 这一种激活函数两次求和就够了。
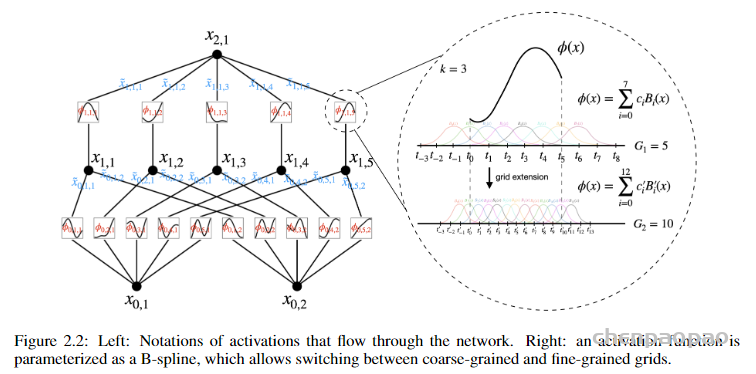
图中展示的结构中,使用了两种尺度或分辨率的组合:粗粒度和细粒度网格,在保持计算效率的同时,更加精确地捕捉和适应函数的变化。这种基础结构其实并不是很难想到,以前就有了,但难点是怎么把它变深,否则单靠这么点玩意儿是不能逼近复杂函数的。这就是本文的主要贡献了。

这里I是层编号,右边为输入,左边为输出。看上面左图就大致明白对应关系,输入为2 个,因此第二层是 2*2+1=5个。中j 就是每条边上的激活函数,也就是非线性变换。相当于每个x都有5个分身,然后再分别组合。其中i用来标记当前层的节点而j用来标记下一层的节点。每个节点 x_i 的输出通过激活函数 φ_l,ij处理后,贡献到所有下一层的 x_l+1,的计算中。对应上面左图,输入层2个节点,第二层5个节点,因此矩阵为 5*2。矩阵的第一列表示x_0,1对应的5个激活函数,第二列对应x_0,2的,然后两两组合。
因此,这里需要强调的是 KAN 网络层节点数不是随便搞的,由输入节点个数确定2n+1个,然后所需要的参数或者连接数为(2n+1)*n,明显比全连接少了不少,看图就知道。

SiLU(Sigmoid Linear Unit)是一种神经网络激活函数,也被称为 Swish 函数。这个函数由一篇 Google Brain 的论文首次提出,并因其在某些任务上表现出的优异性能而受到关注。你可以认为它就是 sigmoid 函数的一种变体。
2.假设层宽相等,L层,每层 N 个节点。
2.每个样条函数的阶数通常为k=3,在G个区间上G +1个网格点。”G 个区间”指的是样条函数的分段定义的区间数。
那么总共大约有 O(N’L(G +k))或O(N2LG)个参数。相比之下,具有深度工 和宽度 N 的多层感知机(MLP)只需要O(N2L)个参数,这看起来比KAN更有效率也就是说单看计算复杂度好像 KAN 还不如 MLP 简单,但是幸运的是,KANS 通常需要比 MLPS 小得多的 NN,这不仅节省了参数,而且还提高了泛化能力,并且有助于解释性。
换句话理解,就是借助 spline 样条函数的表达能力,无需很多节点就能实现比较强的表达能力,因此总的来说,可以比 MLP 节省不少参数量。
4.2 逼近能力和缩放定律的讨论
文章花了一页的篇幅推导证明了定理
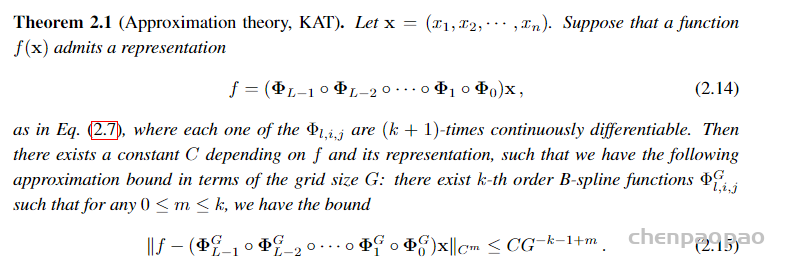
这部分讲的不是人能听懂的话,看不懂很正常。简单说,就是从数学上证明可以通过构建多层的 B样条函数网络来有效逼近复杂函数。尽管增加网络的深度和复杂度,KANS能够通过细致的网格划分来逼近高维函数,而不会受到维数灾难的影响,也就是在高维空间中,数据的稀疏性和处理复杂度急剧增加的问题。而残差率不依赖于维度,因此战胜了维数灾难!
再来看看所谓的缩放定律。注意这里的缩放定律与大模型领域的不同。后者是说模型大小(如参数数量)的增加,模型的性能(例如在语言任务中的准确性)通常会提高,并且有时这种提升的速度可以用某些数学关系(如幂律关系)来描述C=6ND。这里更偏重于理论和数学上的分析,当然背景相似,都是讨论随着参数数量的增加,模型表现的提升。这部分内容基本上也可以暂时略过,主要就是简要对比了几种理论关注于如何通过理论来指导实际的神经网络设计,以实现更有效的学习和泛化能力。后面还有讨论,这里暂时可以忽略。
好,我们接下来重点看看 KAN 准确性和可解释性的改进
4.3 如何提升准确性?
MLPs通过增加模型的宽度和深度可以提高性能,但这种方法效率低下,因为需要独立地训练不同大小的模型。KANS:开始可以用较少的参数训练,然后通过简单地细化其样条网格来增加参数,无需重新训练整个模型。
基本原理就是通过将样条函数(splines)旧的粗网格转换为更细的网格,并对应地调整参数,无需从头开始训练就能扩展现有的 KAN 模型。这种技术称为“网格扩展”(grid extension)
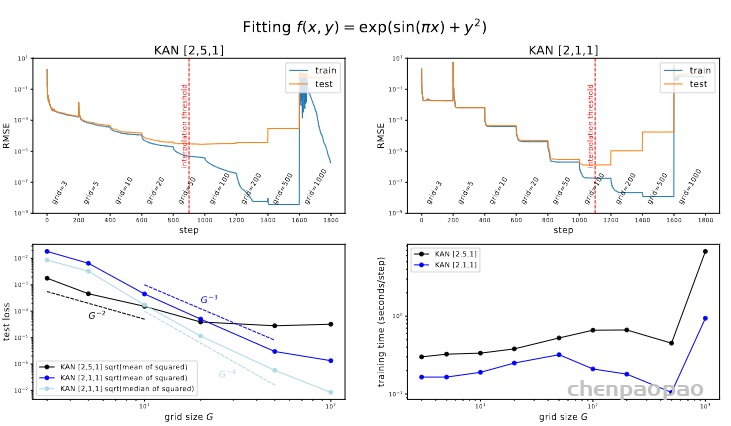
文章用了一个小例子来证明这一点。用 KAN 网络逼近一个函数。上图中横轴的每个grid-x“标签代表了在特定训练步骤时进行网格细化的时点。每次这样的标记出现,都意味着网格点数量在这个步骤有所增加,从而使模型能够更细致地逼近目标函数,这通常会导致误差的下降。表明网格点的增加直接影响了模型的学习效果,提高了逼近目标函数的精度。左右图表示了两种不同结构的网络。
下面两个图分别展示了测试误差随网格大小变化(左下图)和训练时间随网格大小的变化(右下图)。结论就是误差loss 随网格大小 grid size G在不同的规模上显示出不同的缩放关系;训练时间随网格大小增加而增长,特别是在网格非常大时(接近1000),训练时间急剧上升。
这些观测结果支持了文章中关于 KANS 利用网格扩展可以有效提高精度而无需重新训练整个模型的说法,同时也提示了在选择网格大小时可能需要在模型精度和训练效率之间做出权衡。简单说,网格太密了也不好,太费时。
4.4 如何提升可解释性?
尽管上面介绍了 KAN 的不少好处,但遇到实际问题时该怎么设计网络结构依然是个玄学。因此需要有种方法能自动发现这种结构。本文提出的方法是使用稀疏正则化和剪枝技术从较大的 KAN 开始训练,剪枝后的 KAN 比未剪枝的 KAN 更易解释。为了使 KAN 达到最大的可解释性,本文提出了几种简化技术,并提供了一个示例,说明用户如何与KAN 进行交互以增强可解释性。
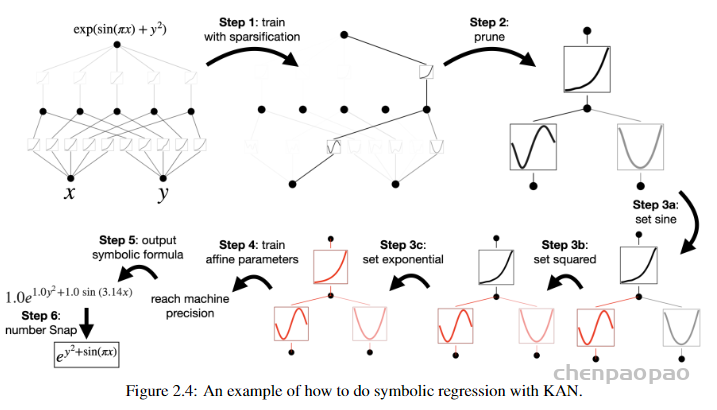
1.稀疏化:使用数据集训练一个 KAN 模型,使其能够尽可能地拟合目标函数。MLP通常使用 L1 正则化来促进权重的稀疏性,L1正则化倾向于推动权重值向零收缩特别是那些对模型输出影响不大的权重。权重短阵的“稀疏化“可以降低模型的复杂性,减少模型的存储需求和计算负担,因为只需要处理非零权重;还能提高模型的泛化能力,减少过拟合的风险。
2.剪枝:在稀疏化后,进一步通过剪枝技术移除那些不重要的连接和神经元。设定特定激活函数:根据剪枝后各神经元的特性,手动设置或调整特定神经元的激活函数
3.训练仿射参数:在调整了激活函数后,对模型中的剩余参数进行再次训练,优化这
些参数以最好地拟合数据。
4.符号化:最终,模型将输出一个符号公式,这个公式是对原始目标函数的一个近似表示,但通常会更简洁、更易于理解和分析。
五、实验验证
5.1 KAN准确性
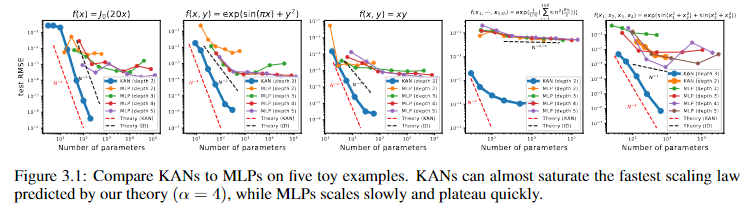
比较了 KAN 与 MLP 在逼近5个典型函数上的性能,横轴是参数量,纵轴为均方根误差(RMSE)。总的来说,KAN和MLP随着参数数量的增加,RMSE都在下降。
在大多数情况下,KAN(蓝色线)比相同深度的MLP具有更低的 RMSE,尤其是在参数数量较少时。这表明 KANS 在参数利用效率上可能更高。MLP 在参数数量增加后性能提升逐渐放缓并迅速达到平台期,这可能是因为 MLP 对于这些类型的函数拟合存在固有的限制。KAN 在多个测试案例中都接近或跟随理论曲线。
这表明 KANS 在处理复杂函数和高维数据时可能是更优的选择,具有更好的扩展性和效率。这种性能优势特别重要,当我们需要从有限的数据中学习复杂的模式时,如在物理建模、声音处理或图像处理等任务中。当然目前还都是比较理论化的实验数据。
接着对比了 KAN 和 MLP 在高难度的特殊函数拟合任务上的性能,结论类似。随参数量增多KAN(蓝色)表现稳定,越来越好,而MLP(黄色)出现平台期。KANS在维持低误差的同时,表现出更好的参数效率和泛化能力。这一点对于设计高效目精确的机器学习模型来说是极其重要的,特别是在资源受限或对精度要求极高的应用中。
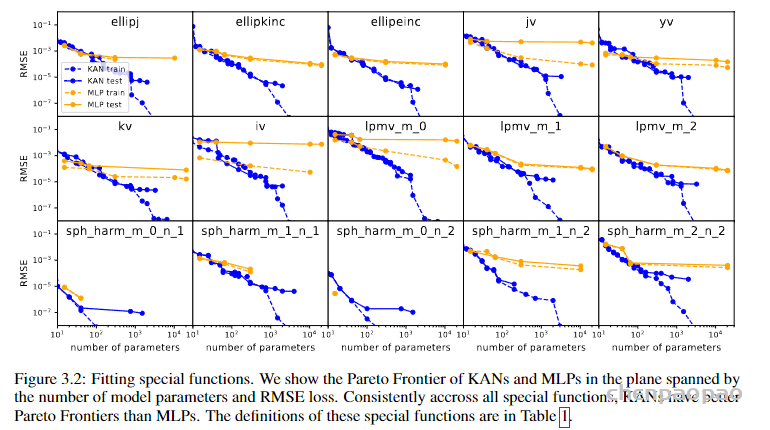
5.2 KAN 的可解释性
借助前面提升模型可解释性的小技巧,包括稀疏化、剪枝等,KAN 网络最终形成的网络结构不仅能够实现数学函数的拟合,而且其形式本身能反映出被拟合函数的内在结构。
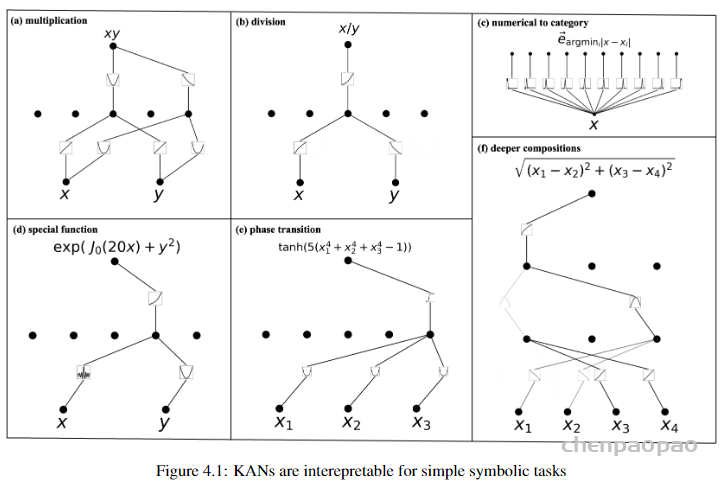
以第一个图为例
函数:f(T,y)= xy
解释:图中的结构利用了恒等式 2xy =( X+ y)?-x2- y2 来计算乘法。这说明KAN通过结合基本运算(加法、平方)来实现复杂的乘法操作,展示了KAN如何通过基本的数学操作构造更复杂的函数。
x和y各自经过线性函数求和,然后平方,同时再减去x和y的平方。
因此可以看出,KAN 模型的牛逼之处在于两点:首先,不仅仅在于自身的型结构,MLP是先组合再非线性激活,KAN 是先非线性激活再组合;其次,KAN的训练能实现自身结构上的优化,有点自组织的味道了。
八、小结
1.MLP 的硬伤:我们回归了 MLP的核心原理,线性组合+非线性激活。深层次化网络后,反向传播求导数时单一激活函数的连乘积会产生很多问题,而且全连接网络导致参数效率低下。
2.KAN 的原理:用单一架构的参数化可学习非线性激活函数直接组合,实现非线性空间变换。模型表征能力大大提升。
3.KAN 训练算法:通过 grid extension,也就是激活函数分辨率提升,以及稀疏化、剪枝等结构自优化技巧,实现了准确性和可解释性的提升。能够在参数量大大减少的情况下实现相同甚至更有的拟合效果。
4.实验验证:仿真实验提供了有效的量化的效果证明,展示了非常有前景的方向,但目前显然还比较初级。不过,提供了一条新的道路。