
OpenVoice: Versatile Instant Voice Cloning
https://github.com/myshell-ai/OpenVoice
它能够仅使用一小段参考发言者的音频片段来复制其声音,然后能生成多种语言的语音。 OpenVoice被设计为尽可能地解耦语音中的组件。语言、音色和其他重要的语音特征的生成是相互独立的,从而能够灵活地操纵各个语音风格和语言类型。 解耦的结构降低了对模型大小和计算复杂性的要求 ,同时不使用自回归或者扩散模型,加快推理速度。支持训练数据集之外的说话人和语言,适合为语音大模型提供大规模的合成语音数据。【核心:将语音克隆任务解耦为独立的子任务,其中每个子任务都比耦合的任务更容易实现。 】
主要功能:【可以用于合成音频数据】
1.准确的音色克隆。OpenVoice可以准确地克隆参考音色,并生成多种语言和口音的语音。
2.灵活的语音风格控制。OpenVoice支持对语音风格的精细控制,例如情感和口音,以及其他风格参数,包括节奏、停顿和语调。
3.零样本跨语言语音克隆。即使这些语言未在训练集中出现也能进行声音复制。
4、支持的语言包括英语(英国、美国、印度、澳大利亚)、西班牙语、法语、中文、日语、韩语
OpenVoice V2的新增特性:
- 更好的音频质量: 采用新的训练策略以提升音频质量。
- 原生多语言支持: V2 版本原生支持英语、西班牙语、法语、中文、日语和韩语。
-
集成 MeloTTS: V2 版本引入了 MeloTTS 技术,通过
pip install git+https://github.com/myshell-ai/MeloTTS.git进行安装,这是一个新的文本到语音转换系统,增强了声音的自然度和表现力。 - 免费商业使用: 自2024年4月起,V1和V2版本均以 MIT 许可证发布,支持商业和研究用途的免费使用。
-
声音样式和语言的解耦设计:
- OpenVoice 的设计哲学是将声音的不同特性(如音色、风格、语言)进行解耦,使得可以独立控制各个参数,从而达到灵活调整的目的。这一设计减少了模型的大小和复杂性,提高了操作的灵活性和推断速度。
-
基础发音者TTS模型与音色转换器:
- 基础发音者TTS模型:这一模型允许对风格参数进行控制,如情绪和口音等。它是一个单发音者或多发音者模型,可以通过改变输入的风格和语言嵌入来输出不同风格的语音。
- 音色转换器:这一组件采用编码器-解码器结构,负责将基础发音者的音色转换为参考发音者的音色。通过这种方式,即使基础声音与目标声音风格不同,也能保持原有风格的同时改变音色。
-
训练策略和数据处理:
- 在训练过程中,采用了大量的多语种、多风格的音频样本。通过这些样本,模型学习如何准确复制音色并控制声音的不同风格。使用特定的损失函数来确保在保留风格的同时去除或转换音色,从而实现高质量的声音生成。
背景
目前语音克隆有以下问题:
1、除了克隆音色,如何灵活控制其他重要的风格参数,如情感,重音,节奏,停顿和语调?这些特征对于生成上下文中的自然语音和对话至关重要,而不是单调地叙述输入文本。以前的方法只能克隆参考说话人的单调音色和风格,但不允许灵活操纵风格。
2、zreo-shot能力:如果要生成的说话人没有训练集里 或者 要说话者的语言没有出现在训练集里,模型可以克隆参考语音并生成该语言的语音吗?
3.如何在不降低质量的情况下实现超高速实时推理,这对于大规模商业生产环境至关重要。
为了解决前两个问题,OpenVoice被设计为尽可能地解耦语音中的组件。语言、音色和其他重要的语音特征的生成是相互独立的,从而能够灵活地操纵各个语音风格和语言类型。这是在不标记MSML训练集中的任何语音风格的情况下实现的。我们想澄清的是,本研究中的零激发跨语言任务与VALLE-X中的任务不同。在VALLE-X中,所有语言的数据都需要包含在MSML训练集中,并且模型不能泛化到MSML训练集之外的未知语言。相比之下,OpenVoice被设计为推广到MSML训练集之外的完全看不见的语言。第三个问题是默认解决的,因为解耦的结构降低了对模型大小和计算复杂性的要求。 我们不需要一个大模型来学习一切。此外,我们避免了自回归或扩散成分,以加快推理。
方法
很明显,同时为任何说话者克隆音色、实现对所有其他风格的灵活控制以及轻松添加新语言可能是非常具有挑战性的。它需要大量的组合数据集,其中受控参数相交,数据对只在一个属性上不同,并被很好地标记,以及一个相对大容量的模型来拟合数据集。
我们还注意到,在常规的单一说话人TTS中,不需要语音克隆,就可以相对容易地添加对其他风格参数的控制以及添加新语言。例如,在10K短音频样本的单说话人数据集,该10K短音频样本具有标记的情绪和语调,足以训练提供对情绪和语调的控制的单说话者TTS模型。添加新的语言或口音也很简单,只需要通过在数据集中添加另一个说话者。
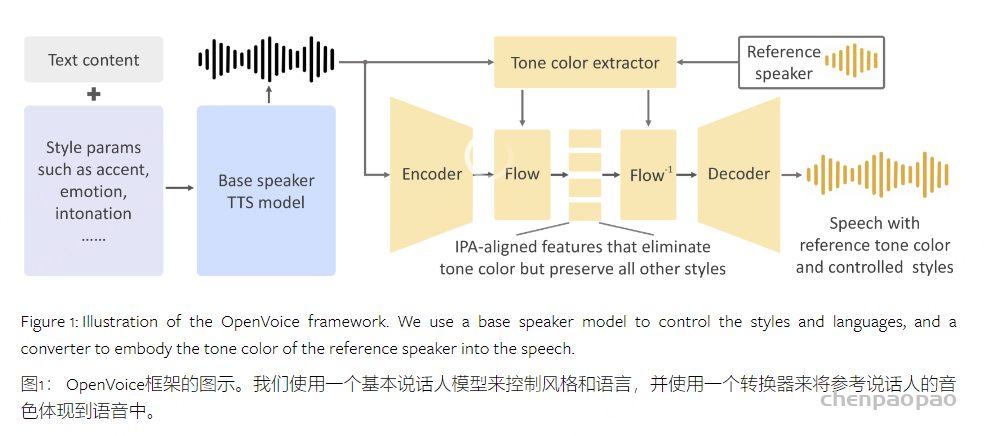
OpenVoice背后的直觉是将IVC任务解耦为独立的子任务,其中每个子任务都比耦合的任务更容易实现。音色的克隆与对所有其余风格参数和语言的控制完全分离。我们提出使用基本说话人TTS模型来控制风格参数和语言,并使用音色转换器来将参考音色体现到生成的语音中。
Model Structure
OpenVoice的两个主要组件是base说话人TTS模型和音色转换器。base说话人TTS模型是单说话人或多说话人模型,其允许控制风格参数(例如,情感、重音、节奏、停顿和语调)、重音和语言。由该模型生成的语音被传递到音色转换器,该音色转换器将base说话人的音色改变为参考说话人的音色。
Base说话人TTS模型。Base Speaker TTS模型的选择非常灵活。例如,可以修改VITS模型,以在其文本编码器和持续时间预测器中接受样式和语言嵌入。其他选项如InstructTTS也可以接受样式提示。也可以使用商业上可用的(和便宜的)模型,例如Microsoft TTS,它接受指定情感,停顿和发音的语音合成标记语言(SSML)。人们甚至可以跳过基本说话人TTS模型,以他们想要的任何风格和语言自己阅读文本。在我们的OpenVoice实现中,我们默认使用VITS模型,但其他选择也是完全可行的。我们将基本模型的输出表示为 𝐗(LI,SI,CI) ,其中三个参数分别表示语言、风格和音色。 类似地,来自参考说话者的语音音频表示为 𝐗(LO,SO,CO) 。
音色转换器. 音色转换器是一个编码器-解码器结构,中间有一个可逆的归一化流程。编码器是一个1D卷积神经网络,它将 𝐗(LI,SI,CI) 的短时傅立叶变换频谱作为输入。所有的卷积都是单步的。由编码器输出的特征图被表示为 𝐘(LI,SI,CI) 。音色提取器是一个简单的2D卷积神经网络,它对输入语音的梅尔频谱图进行操作,并输出一个编码音色信息的单个特征向量。我们将其应用于 𝐗(LI,SI,CI) 以获得矢量 𝐯(CI) ,然后将其应用于 𝐗(LO,SO,CO) 以获得矢量 𝐯(CO) 。
标准化flow层将 𝐘(LI,SI,CI) 和 𝐯(CI) 作为输入,并输出消除色调音色信息但保留所有剩余样式属性的特征表示 𝐙(LI,SI) 。 特征字母表(LI,SI)沿时间维度与国际音标(IPA)沿着对齐。然后,我们在反方向上应用归一化流层,其将 𝐙(LI,SI) 和 𝐯(CO) 作为输入并输出 𝐘(LI,SI,CO) 。这是将来自参考说话者的音色 CO 体现到特征图中的关键步骤。然后 𝐘(LI,SI,CO) 被HiFi-Gan解码为原始波形 𝐗(LI,SI,CO) 。我们的OpenVoice实现中的整个模型是前馈的,没有任何自回归组件。音色转换器在概念上类似于语音转换,但是在其功能性、其模型结构上的归纳偏差和训练目标上具有不同的重点。 音色转换器中的flow层在结构上类似于基于流的TTS方法,但是具有不同的功能和训练目标。
替代方法和缺点。虽然有其他方法来提取 𝐙(LI,SI) ,但我们根据经验发现,所提出的方法实现了最佳的音频质量。可以使用HuBERT来提取离散或连续的声学单元以消除音色信息,但我们发现这种方法也从输入语音中消除了情感和口音。当输入是看不见的语言时,这种类型的方法也存在保留音素的自然发音的问题。我们还研究了另一种方法,该方法仔细构建信息瓶颈以仅保留语音内容,但我们观察到这种方法无法完全消除音调音色。
OpenVoice的贡献在于提供了一个解耦的框架,将语音风格和语言控制从音色克隆中分离出来。这非常简单,但非常有效,特别是当你想控制风格,口音或推广到新的语言。如果想要在XTTS这样的耦合框架上拥有相同的控制权,可能需要大量的数据和计算,并且很难流利地说每种语言。在OpenVoice中,只要单扬声器TTS说话流利,克隆的语音就会流利。 将语音风格和语言的生成与音色的生成脱钩是OpenVoice的核心理念。
Training
为了训练base speaker TTS模型,我们从两个英语说话人(美国口音和英国口音)、一个汉语说话人和一个日语说话人收集了音频样本。共30K句,平均句长7s。中英文数据都有情感分类标签。我们对VITS模型【无需任何情感标注,通过对参考语音使用情感提取模型 提取语句情感embedding输入网络,实现情感可控的VITS合成】进行了改进,并将情感范畴嵌入、语言范畴嵌入和说话人id输入到文本编码器、时长预测器和flow层。培训遵循VITS作者提供的标准程序。训练后的模型能够通过在不同的基本说话人之间切换来改变口音和语言,并以不同的情绪来阅读输入文本。我们还用额外的训练数据进行了实验,证实了节奏、停顿和语调可以用和情绪完全一样的方式学习。
为了训练音色转换器,我们从20 K个人中收集了300 K音频样本。大约180K个样本是英语,60k个样本是中文,60k个样本是日语。这就是我们所说的MSML数据集。音色转换器的训练目标是双重的。首先,我们要求编码器-解码器产生自然的声音。在训练过程中,我们将编码器输出直接馈送到解码器,并使用具有mel频谱图损失和HiFi-GAN损失的原始波形来监督生成的波形。
其次,我们要求流层从音频特征中消除尽可能多的音色信息。在训练过程中,对于每个音频样本,其文本被转换为IPA中的音素序列,每个音素由可学习的向量嵌入表示。向量嵌入的序列被传递到Transformer编码器以产生文本内容的特征表示。将该特征表示为 𝐋∈ℝc×l ,其中 c 是特征通道的数量, l 是输入文本中的音素的数量。音频波形由编码器和流层处理以产生特征表示 𝐙∈ℝc×t ,其中 t 是特征沿时间维度沿着的长度。 然后,我们使用动态时间扭曲(替代方案是单调对齐)沿着时间维度对齐 𝐋 和 𝐙 以产生 𝐋¯∈ℝc×t ,并最小化 𝐋¯ 和 𝐙 之间的KL发散。由于 𝐋¯ 不包含任何音色信息,因此最小化目标将鼓励流层从其输出 𝐙 中移除音色信息。流层以来自音色编码器的音色信息为条件,这进一步帮助流层识别需要消除的信息。此外,我们不提供任何风格或语言信息供流层进行调节,这会阻止流层消除除音色以外的信息。 由于流层是可逆的,因此将它们调节在新的音色信息上并运行其逆过程可以将新的音色添加回特征表示,然后将特征表示解码为包含新的音色的原始波形。
总结
OpenVoice展示了卓越的实例语音克隆能力,并且在语音风格和语言方面比以前的方法更灵活。这种方法背后的直觉是,只要我们不要求模型能够克隆参考说话者的音调颜色,就可以相对容易地训练基本说话者TTS模型来控制语音风格和语言。因此,我们建议将音色克隆与其他语音风格和语言分离,我们认为这是OpenVoice的基本设计原则。