
字节音乐大模型Seed-Music发布,支持一键生成高质量歌曲、片段编辑等
- 论文:《Seed-Music: Generating High-Quality Music in a Controlled Way》
- 技术报告地址:https://arxiv.org/pdf/2409.09214
- Seed-Music 官网:https://team.doubao.com/seed-music
关键内容
关键技术贡献如下:
- 提出了一种基于新型 token 和语言模型(LM)的方法,并引入了一种能够根据不同类型用户输入生成专业生成内容(PGC)质量音乐的训练方法。
- 提出了一种全新的基于扩散模型的方法,特别适合音乐编辑。
- 引入了一种在歌唱声音背景下的零样本声音转换的新颖方法。系统可以根据用户短至 10 秒的参考歌唱或甚至普通语音的音色生成完整的声乐混音。
据豆包大模型团队官网介绍,Seed-Music 是一个具有灵活控制能力的音乐生成系统,包含 Lyrics2Song(歌词转歌曲)、Lyrics2Leadsheet2Song(歌词转简谱再转歌曲)、Music Editing(音乐编辑)、Singing Voice Conversion (歌声转换)四大核心功能,具体涵盖十种创作任务。
目前,业界在 AI 音乐领域的研究主要集中在以下几个核心问题:
- 音乐信号的复杂性:音乐信号包含多个重叠音轨、丰富的音调和音色以及广泛的频率带宽,不仅要保持短期旋律的连贯性,还要在长期结构上展现出一致性。
- 评估标准的缺乏:音乐作为一种开放、主观的艺术形式,缺乏一套通用的问题表述和用于比较的黄金指标,评估局限性大。
- 用户需求的多样性:不同的用户群体,如音乐小白、音乐初学者、资深音乐人等,对音乐创作的需求差异很大。
无论是传统的音乐辅助创作工具,还是当下热门的 AI 音乐生成的研究和产品,面向上述问题,均还处于摸索阶段。
比如针对音乐信号复杂性,Google、Meta、Stability AI 等各家在音频、演奏、曲谱层面上做了建模尝试,效果各有优缺,而且各家的评估方法均有局限,人工评测仍必不可少。
面对这些挑战,字节 Seed-Music 采用了创新的统一框架,将语言模型和扩散模型的优势相结合,并融入符号音乐的处理。
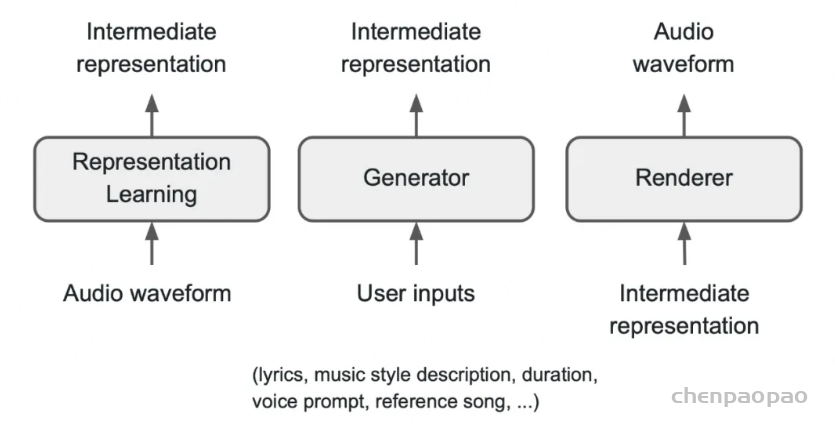
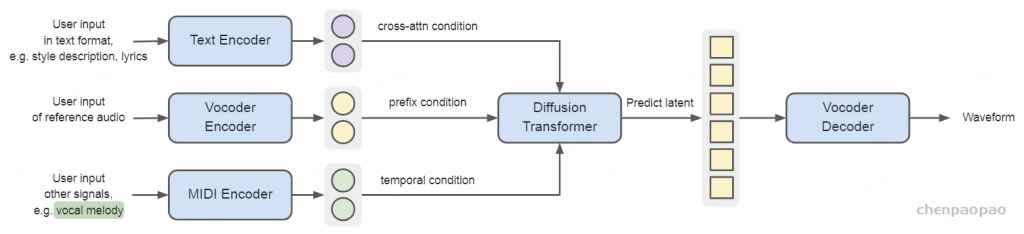
如上图所示,从高层次来看 Seed-Music 有着统一的音乐生成框架,主要包含以下三个核心组件:一个表征模型,用于将原始音频波形压缩成某种压缩表征形式;一个生成器,经过训练可以接受各种用户控制输入,并相应地生成中间表征;一个渲染器,能够从生成器输出的中间表征中,合成高质量的音频波形。
基于统一框架,Seed-Music 建立了三种适用于不同场景的中间表征:音频 token、符号音乐 token 和声码器 latent。
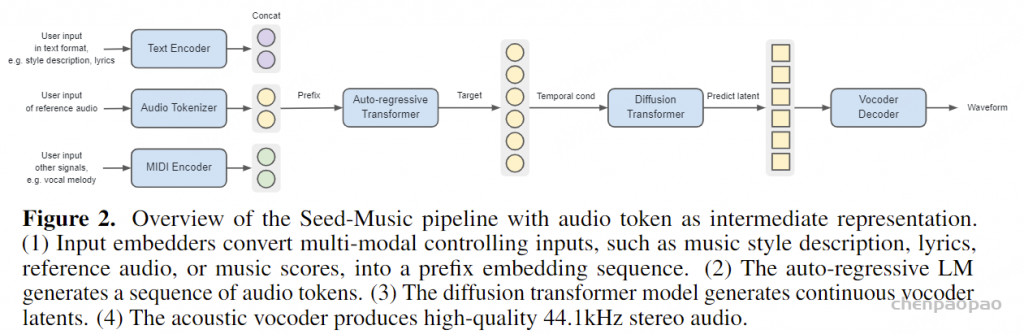
- 音频 token:通常以低于音频采样率的标记率学习,旨在有效编码语义和声学信息,能轻松桥接不同模态,但不同音乐信息高度纠缠,给生成器带来挑战。对应图二Audio Tokenizer的输出。
- 符号音乐 token:如 MIDI、ABC 记号或钢琴卷帘记号等,本质上离散,可被大型语言模型操作,具有可解释性,便于用户在辅助音乐创作中交互,但缺乏声学信息,依赖渲染器生成声学细节。对应图二的MIDI编码器输出。
- 声码器 latent:在探索基于扩散模型的音乐音频生成中,可作为中间表征,与量化音频标记相比,信息损失少、渲染器权重更轻,但生成器输出不可解释,且由于仅用波形重建目标训练,可能不够有效作为训练生成器的预测目标。对应图二扩散模型的输出部分。
满足多元需求专门提供高灵活编辑:
Seed-Music 创新点之一,在于能通过 lead sheet(领谱)来编辑音乐,这增加了音乐创作可解释性。
在官方视频的 Lead2Song 部分,可以看到同一版歌词,通过领谱增减音轨、改变输入风格后,就能得到不同结果的歌曲,显著提高模型的实用性。
除领谱外,Seed-Music 也能直接调整歌词或旋律。比如,“情人节的玫瑰花,你送给了谁 / 你送给别人”,歌词修改前后,旋律保持不变,音乐的连贯性得以保持,过渡效果非常平滑。
输入内容除了文本,也可以是音频,它能基于原曲输出续作或仿作。下面这首英文歌曲“摇身一变”,仿写成了中文古风歌。
哪怕输入临时录制的 10 秒人声, Seed-Music 的零样本音频转换技术都能够将其转化为流畅的声乐。惊喜的是,Seed-Music 能将中文人声输入转换为英文声乐输出,实现了跨语种人声克隆,扩大了音乐小白们的创作空间。
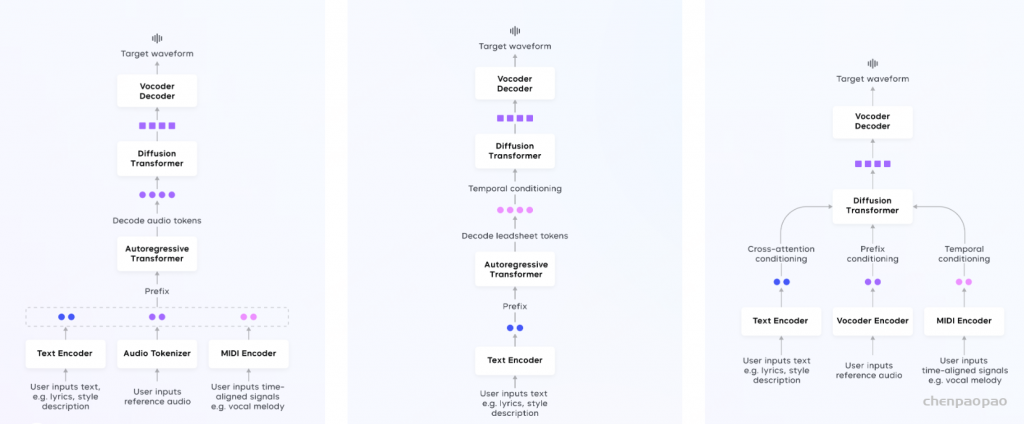
如图所示,中间表征对整个系统来说很重要,每种表征都有其特点和适用场景,具体选择取决于用户的音乐创作任务。
- 基于音频 token 的链路:包括 tokenizer、自回归语言模型、token 扩散模型和声码器,音频 token 有效地存储了原始信号的显著音乐信息,语言模型根据用户控制输入生成音频 token,token 扩散模型处理音频 token 以生成具有增强声学细节的音频波形。
- 基于符号音乐 token 的链路:采用符号音乐 token 作为中间表征,与音频 token 基于的管道类似,但有一些区别,如 lead sheet tokenizer 将信息编码为 token,语言模型学习预测 lead sheet token 序列,lead sheet token 是可解释的,并且允许在训练和推理中注入人类知识,但扩散模型从 lead sheet token 预测声码器 latent 更具挑战性,需要更大的模型规模。
- 基于声码器 latent 的链路:遵循通过 latent 扩散建模从文本直接生成音乐到声学声码器 latent 表征的工作,通过变分自编码器和扩散模型将条件信号映射到归一化和连续的声码器 latent 空间。
在上述链路中,Seed-Music 经历三个训练阶段:预训练、微调和后训练。预训练旨在为音乐音频建模建立强大的基础模型;微调包括基于高质量音乐数据集的数据微调,以增强音乐性,或者针对特定创作任务提高可控性、可解释性和交互性的指令微调;后训练是通过强化学习进行的,从整体上提高了模型的稳定性。
此外,在推理时,样本解码方案对于从训练模型中诱导出最佳结果至关重要。研究者们同时会应用模型蒸馏和流式解码方案来提高系统的延迟。
论文:《Seed-Music: Generating High-Quality Music in a Controlled Way》
摘要:
我们推出 Seed-Music,这是一套音乐生成和编辑系统,旨在通过细粒度的风格控制来制作高质量的音乐。我们的统一框架利用自回归语言建模和扩散方法来支持两个关键的音乐创作工作流程:受控音乐生成和后期制作编辑。为了控制音乐生成,我们的系统可以通过多模式输入的性能控制来生成声乐,包括歌词、风格描述、音频参考、乐谱和语音提示。对于后期制作编辑,它提供了交互式工具,可直接在现有音乐音轨中编辑歌词、旋律和音色。我们鼓励读者探索 https://team.doubao.com/seed-music 上的演示音频示例。
贡献。鉴于这些挑战,我们强调Seed-Music的多功能性。它支持声乐和器乐音乐生成、歌唱声合成、歌唱声转换、音乐编辑等。我们的方法、实验和解决方案旨在满足多样化的使用案例。我们提出一个统一框架,适应音乐家的不断发展工作流程,而不是依赖于单一的建模方法,如自回归(AR)或扩散。我们的关键贡献包括:
- 我们介绍了一个统一框架,该框架结合了自回归语言建模和扩散方法,以实现基于多种多模态输入的高质量声乐生成。
- 我们提出了一种基于扩散的方法,能够对音乐音频进行细粒度编辑。
- 我们提出了一种新颖的零样本歌唱声转换方法,仅需用户提供10秒的歌唱或语音录音。
第三部分介绍框架,该框架建立在三种基本表示上:音频标记、符号标记和声码器潜变量。将详细说明相应的流程和设计选择。在第四部分,我们深入探讨了我们的统一框架如何配置和训练以支持各种音乐生成和编辑任务。在第五部分和第六部分,我们讨论了Seed-Music的潜在应用和局限性,包括构建安全和道德生成AI系统的相关问题。
Method
我们的音乐生成系统由三个核心组件组成,如 Figure 1 所示:一个 表示学习模块,它将原始音频波形压缩为中间表示,作为训练后续组件的基础;一个 生成器,它处理各种用户控制输入并生成相应的中间表示;以及一个 渲染器,它根据生成器中的中间表示合成高质量的音频波形。
主要设计选择是中间表示。如第2节所述,我们确定了三种实用的选项:音频标记、符号音乐标记和声码器潜变量。每种选项的优缺点总结在表1中。

音频token旨在以远低于音频采样率的速率高效编码语义和声学信息。当与基于自回归语言模型的生成器一起使用时,音频标记可以有效连接不同的模态。然而,它们的主要限制在于缺乏可解释性,诸如声乐发音、音色和音高等音乐属性以高度纠缠的格式嵌入。先前的研究探讨了某些音频标记与语义特征的对应关系,而其他标记则捕捉声学方面。这种纠缠使生成器在生成音频标记时难以控制音乐的特定元素,如旋律和音色。
符号token(如MIDI、ABC符号和MusicXML)是离散的,可以轻松地被标记化为与语言模型兼容的格式。与音频标记不同,符号表示是可解释的,允许创作者直接读取和修改。然而,它们缺乏声学细节,这意味着系统必须高度依赖渲染器生成音乐表演的细腻声学特征。训练这样的渲染器需要大量的配对音频和符号转录数据集,而这种数据集在声乐音乐中尤其稀缺。
来自变分自编码器的声码器潜变量作为连续的中间表示,尤其是在与扩散模型结合使用时。这些潜变量捕获比量化音频标记更细致的信息,使得在此流程中渲染器可以更轻量化。然而,与音频标记类似,声码器潜变量也是不可解释的。此外,由于声码器潜变量是为了音频重构而优化的,它们可能编码过多的声学细节,这对生成器的预测任务帮助不大。
选择中间表示取决于具体的下游音乐生成和编辑任务。在本节的其余部分,我们将介绍系统设计的技术细节,以及这三种中间表示的应用案例,详见第4节。
Audio Token-based Pipeline
基于音频令牌的管道,如图2所示,包含四个构建块:(1) 音频令牌化器,将原始音乐波形转换为低速率离散令牌;(2) 自回归语言模型(即生成器),接收用户控制输入,将其转换为前缀令牌,并预测目标音频令牌序列;(3) 令牌扩散模型,根据音频令牌预测声码器潜变量;(4) 声学声码器,渲染最终的44.1kHz立体声音频波形。目标音频令牌到潜变量扩散模块和潜变量到波形声码器模块共同形成令牌到波形的过程,称为渲染器。

音频tokenizer。音频tokenizer的有效性对该管道的成功至关重要。音频令牌嵌入了原始信号中的关键信息,如旋律、节奏、和声、音素和乐器音色。我们的实现受到Betker [2023]、Wang等 [2023b] 和Łajszczak等 [2024]的启发,并在架构和训练上进行了进一步优化,以实现以下目标:
• 在低压缩率下高保留关键信息,提高自回归语言模型的训练效率。
• 在语义和声学特征之间保持平衡,确保有足够的语义细节来优化生成器的训练,同时保持足够的声学细节以便渲染器准确重建波形。这个令牌生成与信号重建之间的权衡 [Blau和Michaeli,2019] 被仔细管理。
生成器。自回归语言模型通过对控制信号进行条件处理生成音频令牌,这些控制信号引导生成期望的音频输出。每个训练示例由配对的注释和音频组成,注释被转换为一系列嵌入,作为语言模型的前缀。不同控制信号模态的处理总结如下:
• 分类信号:闭合词汇标签(如音乐风格)通过查找表转换为分类嵌入,而自由形式的文本描述则使用MuLan [Huang et al., 2022]的通用文本编码器进行处理。
• 浮点信号:旋律音符持续时间或歌曲长度等变量使用xVal编码 [Golkar et al., 2023] 嵌入,以表示连续数值输入。
• 歌词信号:歌词被转换为音素序列,以捕捉发音,改善模型对未见单词的泛化能力。
• 参考音频信号:tokenizer从参考音频中提取离散令牌序列,然后将其映射到与tokenizer的码本大小相同的连续嵌入查找表中,或者进一步聚合为轨道级嵌入。
在训练过程中,模型通过使用教师强制在下一个令牌预测任务上最小化交叉熵损失。在推理阶段,用户输入根据指定模态转换为前缀嵌入,然后自回归地生成音频令牌。
渲染器。一旦自回归语言模型生成音频令牌,这些令牌就由渲染器处理,以生成丰富的高质量音频波形。渲染器是一个级联系统,由两个组件组成:扩散变换器(DiT)和声学声码器,两者均独立训练。DiT采用标准架构,具有堆叠的注意力层和多层感知机(MLP)。其目标是逆转扩散过程,从噪声中预测干净的声码器潜变量,通过在每一步估计噪声水平。声学声码器是低帧速率变分自编码器声码器的解码器,设计类似于[Kumar et al., 2024, Lee et al., 2022, Cong et al., 2021, Liu and Qian, 2021]。我们发现,将声码器潜变量结构化为级联系统中的信息瓶颈,并结合可控的模型大小和训练时间进行优化,能够产生优于直接将音频令牌转换为波形的单一模型的音频质量和更丰富的声学细节。
Symbolic Token-based Pipeline
与音频令牌基础管道不同,符号令牌生成器(如图3所示)旨在预测符号令牌,以提高可解释性,这对解决Seed-Music中音乐家的工作流程至关重要。

先前的研究提出了旋律生成算法 [Ju et al., 2021; Zhang et al., 2022]。然而,它们缺乏对声乐音乐生成至关重要的明确音素和音符对齐信息。此外,它们仍然仅限于符号音乐生成,无法进行音频渲染。在另一条研究线上,有一些特定任务的先前工作研究了通过和声 [Copet et al., 2024]、力度和节奏 [Wu et al., 2023] 等音乐可解释条件来引导音乐音频生成的方法。受到爵士音乐家如何使用乐谱来勾勒作品旋律、和声和结构的启发,我们引入了“乐谱令牌”作为符号音乐表示。我们强调乐谱令牌与音频令牌相比的关键组成部分、优点和局限性如下。
• 为了从音频中提取符号特征以训练上述系统,我们利用内部开发的音乐信息检索(MIR)模型,包括节拍跟踪 [Hung et al., 2022]、调性和和弦检测 [Lu et al., 2021]、结构部分分段 [Wang et al., 2022]、五种乐器的MIDI转录(即人声、钢琴、吉他、贝斯和鼓) [Lu et al., 2023; Wang et al., 2024a],以及歌词转录。乐谱令牌表示音符级细节,如音高、持续时间、在小节中的位置、与音符对齐的声乐音素,以及轨道级属性,如段落、乐器和节奏。
• 乐谱令牌与可读乐谱之间的一对一映射使创作者能够直接理解、编辑和与乐谱互动。我们尝试了不同的方法来生成乐谱令牌序列:REMI风格 [Huang和Yang, 2020] 和 xVal [Golkar et al., 2023]。REMI风格的方法将乐器轨道交错到量化的基于节拍的格式中,而xVal将起始和持续时间编码为连续值。虽然xVal风格编码在更贴合我们生成模型的最终产品——音乐表现,但我们发现REMI风格更适合与音乐家的用户互动。
• 乐谱令牌允许在训练和推理过程中融入人类知识。例如,可以在预测序列中下一个令牌时应用音乐理论规则作为约束,以提高预测准确性。
• 由于乐谱令牌缺乏声学特征表征,我们需要在级联渲染器中扩大令牌到潜变量的扩散模型,以实现与音频令牌基础系统相同的端到端性能。
Vocoder Latent-based Pipeline
先前的研究 [Evans et al., 2024c,d; Levy et al., 2023; Rombach et al., 2022] 表明,“文本到音乐”的任务可以通过直接预测声码器潜变量来实现高效的方法。类似地,我们训练了一个在低潜变量帧率下运行的变分自编码器(VAE),并配合一个扩散变换器(DiT),将条件输入映射到标准化的连续声码器潜变量,如图4所示。
与基于音频令牌的管道相比(见第3.1节),自回归变换器模块被省略,尽管DiT和声码器的架构仍然大体相似。为了实现可比的性能,其他剩余模块的模型大小被扩大。在自回归方法中,所有条件输入被编码为前缀序列中的令牌,这可能导致过长的前缀,从而在处理更大和更复杂的输入时性能下降。相反,基于声码器潜在设计提供了更大的灵活性,能够更好地融入更广泛的条件信号,并支持多通道输入和输出。我们总结了不同类型提示的使用方式如下:
- 声码器潜在空间中的上下文条件:这使得音频修补场景成为可能,例如音频延续和编辑。
- 输入噪声空间中的上下文条件:对于歌词和风格描述等可变长度输入,交叉注意层在每个变换器块中应用,以融入这些输入。
- 跨多个轨道的时间输入:时间变化信号(如旋律轮廓、强度曲线和时间对齐的乐器音轨)可以在去噪过程中每一步添加作为条件输入。
- 多通道输出:在训练期间提供多通道输出示例时得到支持。例如,模型可以生成多个音乐上不同的音轨(如人声、贝斯、鼓和吉他),从而实现混音和重混等下游制作场景。这些音轨级别的训练示例可以通过音乐源分离(MSS)获得。
Model Training and Inference
对于上述所有管道,Seed-Music经历三个训练阶段:预训练、微调和后训练,类似于Seed-TTS和其他基于文本的语言模型。预训练阶段旨在为通用音乐音频建模奠定更好的基础。微调阶段包括数据微调以增强音乐性,或指令微调以提高特定创作工作流程的可控性、可解释性和互动性。
Seed-Music的后训练通过强化学习(RL)进行,这已被证明在文本和图像处理方面是一种有效的学习范式。近期研究表明,近端偏好优化(PPO)可以扩展到音乐和语音生成。受这些发现的启发,我们探索了RL方法,以改善生成输出与各种输入控制信号的对齐,并增强音乐性。我们考虑的奖励模型包括:原歌词提示与从生成音频提取的歌词转录之间的编辑距离,输入流派与音频输出检测流派的比较精度,以及歌曲结构提示与生成音频检测结构之间的匹配。此外,基于节奏、乐器、音频参考和用户语音提示的额外奖励模型可以用于指示生成输出中强调哪些音乐属性。此外,结合人类反馈可以产生捕捉用户细微偏好的奖励模型。我们将对RL的深入研究留待未来工作。
在推理过程中,样本解码方案的选择对自回归和扩散模型的输出质量和稳定性至关重要。我们观察到,仔细调整无分类器引导至关重要,以确保音乐性和对提示的遵循。为了减少延迟,我们应用模型蒸馏以最小化DiT模型所需的迭代步骤。此外,我们开发了一种流式解码方案,允许在自回归模型继续生成令牌序列的同时进行音频流生成。
Experiments
在本节中,我们展示了四个基于模型能力的应用:Lyrics2Song(第4.1节)、Lyrics2Leadsheet2Song(第4.2节)、MusicEDiT(第4.3节)和zero-shot唱歌声音转换(第4.4节)。
在Lyrics2Song中,我们介绍了一个基于用户提供的歌词和音乐风格输入生成高质量人声音乐的系统。Lyrics2Leadsheet2Song在Lyrics2Song的基础上,结合了符号音乐表示,以增强可解释性,并生成乐谱,用户可以访问并调整旋律和节奏,从而更精细地控制最终音频输出。MusicEDiT探索了一种基于扩散的修补系统,使用户能够编辑现有音乐音频的歌词和旋律,作为后期制作工具来修改歌曲的人声。在zero-shot唱歌声音转换中,我们提供了一种解决方案,允许用户基于自己的声音在现有音频中修改人声音色,且仅需最少的参考数据。这一应用以低准备成本促进了人声个性化。对于上述每个应用,我们讨论了与中间表示、模型架构和其他配置相关的设计选择,以优化系统以适应各自的用例。
Lyrics2Song
Lyrics2Song生成基于用户提供的音乐风格描述和带有章节标签(如“段落”、“副歌”和“桥段”)的歌词的声乐音乐表演。这项任务利用音频基于令牌的管道,借助令牌化和自回归技术对多模态数据(即歌词、风格、标签和音频)进行对齐,并支持流式解码以实现快速、响应式的交互。
该系统支持短音频片段的生成和完整曲目的制作。生成的音频展示了富有表现力和动态的人声表演,旋律动人,并且乐器种类繁多,涵盖多种风格,展现出成熟的音乐性。
带音频参考的人声音乐生成
除了风格描述外,我们的系统还支持音频输入作为提示来指导音乐生成。通过收听示例,可以看到输出是如何参考音频提示的音乐风格生成的。由于用文本或标签描述所需音乐对新手用户来说可能不够直观,因此音频提示提供了一种更有效的交流音乐意图的方式。
我们的系统支持两种音频提示模式:继续模式和混音模式。在继续模式中,从音频参考提取的音频令牌被连接到前缀中,以继续自回归生成,从而确保与参考音频在结构、旋律和声响上的高度相似。在混音模式中,音频参考被转换为预训练的联合文本-音频嵌入空间中的嵌入向量。这一嵌入总结了音频参考的全局特征,然后被纳入前缀中以指导生成,使生成的音频能够采纳不同的风格。
在这两种模式下,我们的模型展示了强大的能力,能够保持输入歌词与音频参考中固有歌词之间的连贯性,即使在没有自动歌词转录的帮助下。当输入歌词在结构和语义上与音频参考中的歌词相似时,模型倾向于模仿参考的旋律和结构。然而,当输入歌词在风格上显著不同(例如语言、结构、押韵)时,连贯性会减弱。尽管如此,模型仍能有效保持自然的节奏模式、乐器、声乐质量和整体音乐主题。
器乐音乐生成
虽然音频基于令牌的管道主要设计用于声乐音乐生成,但如果歌词输入仅包含章节标签而没有文本,它也支持器乐音乐生成。我们提供了多种风格的器乐生成示例,每个部分按指定时间展开,并展示了部分之间清晰的结构转换(例如,从段落到副歌)。
评估指标
我们使用以下定量指标在开发过程中评估生成质量。这些指标也被重新用于自回归语言模型的强化学习过程中的奖励模型。
- 词错误率(WER):我们使用内部开发的唱歌歌词转录模型,该模型支持英语和中文,以转录生成的音频并计算与歌词提示的词(或拼音)错误率。虽然有用,但由于延长元音、辅音、音高变化和类似非语言节奏等因素,WER并不是评估音乐声乐质量的完美指标。这些特征可能会引入噪声。
- 音乐标签性能:为了评估生成音频与输入风格描述之间的对齐,我们使用内部开发的音乐标签和结构分段模型,从生成的音频中预测高层次的音乐属性,包括流派、情绪、声乐音色、声乐性别和结构部分。这些预测属性与输入的风格描述和章节标签进行比较,以平均精确度分数作为相关性的定量指标。
对于定性评估,我们使用比较平均意见得分(CMOS),基于一组音乐训练评审员的反馈。我们定义了以下三个评估维度:
- 音乐性:评估音乐属性,包括声乐旋律的新颖性、和声的适当使用、惯用音乐形式(例如主题、变奏)、连贯结构、合适的和弦进行、特征节奏模式和完善的乐器配器。
- 音频质量:评估声学特性,如声乐清晰度、乐器真实感、频谱细节以及鼓的瞬态和起音的清晰度。评审员还考虑任何不希望的音频伪影,如失真、闷音或某些频段能量缺失。
- 提示遵循:衡量生成音频与输入歌词和风格提示的吻合程度。
在语音领域,基准数据集已建立用于评估TTS系统,采用WER和自动说话人验证(ASV)等指标。然而,目前没有相应的音乐生成基准提供定量评分。此外,音乐性—评估音乐生成质量的关键因素—具有高度的主观性,并且难以用客观指标量化。我们鼓励读者收听提供的音频示例,以更好地评估我们系统的质量。
音频令牌与声码器潜在
我们还使用声码器潜在基础管道进行Lyrics2Song实验,取得了与音频令牌基础管道相当的性能。然而,我们发现自回归语言模型在交互应用中固有地更适合于扩散模型。其因果架构使流式解决方案能够提供近乎实时的体验,同时还允许与多模态模型的未来集成。
Lyrics2Leadsheet2Song
Lyrics2Leadsheet2Song管道是一个两步过程,用于实现Lyrics2Song任务:Lyrics2Leadsheet和Leadsheet2Song。在第一步中,从输入的歌词和风格描述生成乐谱令牌。在第二步中,从乐谱令牌生成音乐音频。整体管道如第3.2节所示。乐谱令牌使用户能够参与生成过程,在最终渲染之前编辑旋律、和弦、乐器和节奏。
Lyrics2Leadsheet
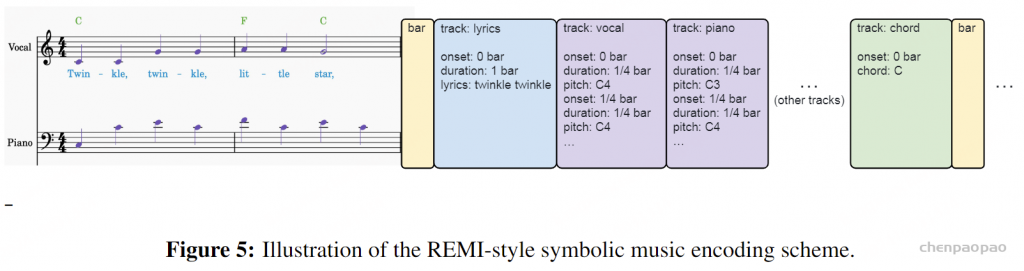
我们基于[Chen et al., 2024c]开发了一种基于规则的符号音乐编码方案,以将音乐音频片段的符号特征编码为乐谱令牌序列。如图5所示,该方案编码了歌词和各种音乐事件。它识别八种事件类型:歌词音素、小节、和弦、声乐音符、低音音符、钢琴音符、吉他音符和鼓音符。除“小节”外,每种事件类型在乐谱令牌中都表示为一个独特的“轨道”。小节事件定义了基本的时间结构,各轨道按小节交错排列。
对于轨道内的每个事件(例如,音素、音符、和弦),我们在适用时编码开始时间、持续时间和音高值。
如第3.2节所述,生成器使用我们内部的MIR模型提取的乐谱令牌进行训练。以下是一些示例,展示了自回归语言模型如何根据输入的歌词和风格提示预测与音素对齐的音符,以及适合流派的旋律和节奏。
Leadsheet2Song
Leadsheet2Song管道涉及从一系列乐谱令牌渲染完整的音频混音。在演示示例中,我们展示了生成的声乐音乐如何遵循给定乐谱令牌中的声乐旋律、音素、节奏、和弦进行和乐器音符。渲染器有效地生成自然且富有表现力的多乐器音乐表演的细微差别,为专业人士提供了一种强大的工具,以快速回顾音频结果,而无需在合成器中进行细致的参数调整。
Leadsheet2Vocals
除了生成完整的音频混音外,Lyrics2Leadsheet2Song系统可以配置为生成单独的音轨,包括人声、鼓、低音、钢琴和吉他,既可以使用符号表示也可以生成音频。唱歌声音合成(SVS)是该系统的一个应用,其中模型设置为仅输出人声音轨,如这些示例所示。
Music Editing
在本节中,我们探讨音乐音频编辑作为后期制作过程。第3.3节中描述的基于扩散的方法的非因果特性使其特别适合此类任务。例如,在文本条件下的修补中,扩散模型能够在遮蔽音频段前后访问上下文,从而确保更平滑的过渡[Wang et al., 2023c]。我们将此框架视为乐谱条件下的修补任务,以训练DiT模型。在推理过程中,修改后的乐谱作为条件输入,遮蔽与乐谱中修改部分对应的音频段并重新生成。
在这些听力示例中,我们展示了系统在保持旋律和伴奏的同时,精确修改演唱歌词的能力,支持英语和普通话的演唱。在某些情况下,歌词在同一语言内进行修改,而在其他情况下,系统允许在语言之间交替。此外,在这些示例中,我们展示了用户如何在指定的时间段内精确调整旋律,同时保持歌词、其余旋律和伴奏轨道不变。这种新的“生成音频编辑”范式让我们感到兴奋,因为它保留了原始曲目的音乐表现和基本特质,而这一点在没有重新录制人声及原始乐器音轨的情况下以往是复杂或几乎不可能实现的。
Zero-shot Singing Voice Conversion
为创作者编辑声乐音乐的最直观方式之一是将声乐音色转换为与其自身声音相匹配的音色。本节探讨了作为Seed-Music套件最终组成部分的唱歌声音转换(VC)系统。尽管我们的唱歌VC方法与Seed-TTS中介绍的语音VC有相似之处,但在声乐生成背景下的声音克隆和转换面临更大的挑战[Arik et al., 2018]:
- 声乐混合:声乐音乐通常由声乐和背景乐器伴奏组成,两者在和声和节奏方面具有强一致性。相比之下,语音信号往往包含与语音内容无关的背景环境声音。尽管现代MSS模型可以隔离声乐,但通常会引入降低质量的伪影。我们的目标是开发一个可扩展的系统,能够直接处理声乐与背景轨道的混合,而不依赖MSS,从而避免这些伪影。
- 声乐范围:唱歌声音的音高范围远大于语音。在零-shot唱歌VC中,系统必须将参考声音的音高范围推广到合成的唱歌声音,这对模型的鲁棒性提出了很高要求。
- 声乐技巧:唱歌声音具有高度表现力,并涉及比语音更多的技巧。同一位歌手在歌剧中、音乐剧或爵士即兴中演唱时,听起来可能截然不同。唱歌VC系统必须准确捕捉和重现这些表现性技巧,同时处理清晰发音和韵律等常规语音特征。
- 唱歌与语音参考:在VC应用中,用户通常提供语音作为参考声音,无论是用于语音还是唱歌合成。我们的系统专门设计为能够接受无论是语音还是唱歌的参考声音,并能够有效地使用短语音片段作为参考进行唱歌VC。
- 业余与专业唱歌:与语音VC数据相比,业余唱歌与专业唱歌的配对数据显著较少。这使得唱歌VC特别具有挑战性,因为模型必须适应非专业唱歌输入,并将其转换为专业质量的表现。例如,如果用户提供的唱歌参考音调不准,唱歌VC系统不仅要捕捉其声音的音色,还必须纠正音高。
听力示例展示了我们的唱歌VC系统在不同场景下的表现。结果的质量在很大程度上取决于参考声音与目标唱歌信号之间的相似性。例如,当两者都是用英语演唱的男性声音时,效果最佳。然而,处理跨性别和跨语言的情况更具挑战性,往往会导致伪影、失真和发音不一致等问题。
结论
在本报告中,我们介绍了Seed-Music,这是一个全面的音乐生成和编辑系统套件,旨在支持多样化的音乐创作工作流程。我们展示了该系统如何基于多模态输入(包括歌词、风格描述、音频参考、乐谱和声音提示)生成高质量的声乐音乐。我们的统一框架通过三种中间表示(即音频标记、乐谱标记和声码器潜在表示)及其相关管道,满足各种用例,为用户提供灵活的工具,从创意到生成和编辑。
从应用的角度来看,Seed-Music 降低了艺术创作和音乐表达的门槛。我们相信本报告中的演示可以赋能从初学者到专业人士的广泛创作者。例如,文本到音乐系统与零-shot唱歌声音转换的结合,使初学者能够更深入地参与创作过程。初学者不仅是从远处与音乐互动,而是能将自己独特的声音和身份融入到过程中,增强创意的构思。
音乐也是短视频、电影、游戏和增强现实/虚拟现实体验等补充媒体的重要组成部分。实时条件控制和生成音乐的渲染引入了全新的互动形式,超越了传统的音频播放。我们展望新的艺术媒介,在这些媒介中,生成音乐能够响应来自文本、游戏叙事和视觉艺术风格的条件信号。
对于专业人士而言,提议的乐谱标记旨在无缝集成到音乐家、作曲家、歌手和艺术家的工作流程中。我们相信,这些标记有潜力发展成为音乐语言模型的符号标准,类似于传统音乐制作中的MIDI。音乐家和制作人可以在保持对旋律、和声和节奏元素的熟悉控制的同时,利用生成模型的强大功能。此外,能够编辑和操控录制的音乐,同时保持其音乐语义,将为行业节省大量时间和成本。我们对未来在音轨生成和编辑方面的发展特别感兴趣,这将超越声乐轨道。这些能力将使专业人士能够更高效地探索音乐创意,从而增加发现“意外惊喜”的可能性,这通常对创作过程至关重要。