Zero-shot TTS中有不少工作用了MEL谱作为中间特征,然后在梅尔谱的基础上,或是用VQ提供离散token,或是用CNN来提取连续latent。对于MEL+VQ的工作,有tortoise-tts、xtts 1&2、megatts1&2、base TTS。
Tortoise-tts
论文:https://arxiv.org/abs/2305.07243
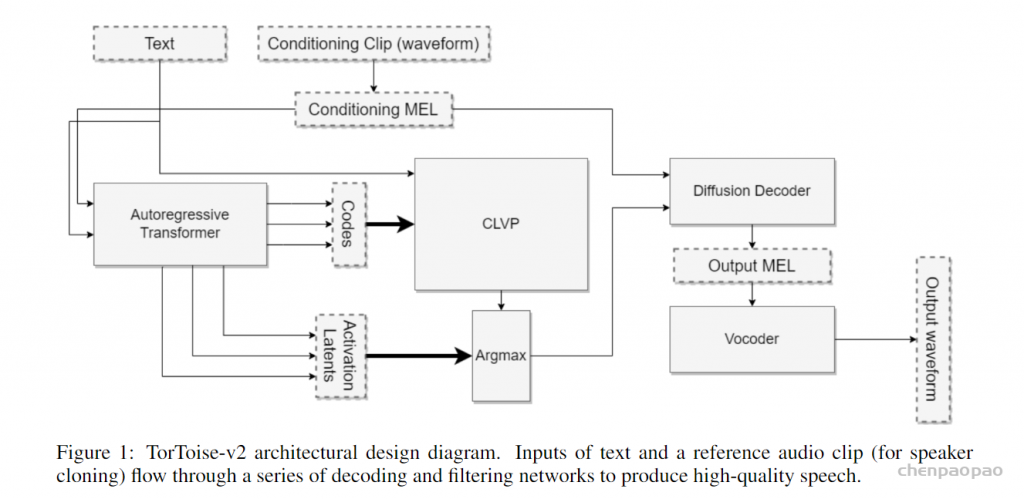
该工作是著名的开源英文TTS模型。其作者目前在OpenAI就职,同时也是GPT-4o的重要Contributor(他自个儿在博客中说的)。Tortoise-tts使用MEL+VQVAE的方法得到语音的MEL token,然后对MEL token以及text token做GPT自回归建模。对于语音的解码,自然也是分为两步:先是用扩散模型将MEL token转换为MEL谱,这一步和文生图很像,用扩散模型是很自然的选择;然后用声码器将MEL谱转换为音频波形。tortoise-tts和VALL-E的主体都是自回归建模,二者的不同主要在于token的不同。
MegaTTS 1&2
Mega-TTS: Zero-Shot Text-to-Speech at Scale with Intrinsic Inductive Bias
Mega-TTS 2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis
字节跳动的MegaTTS系列对语音token编码信息做了显式的信息压缩处理,让语音token仅编码上下文依赖强的韵律信息,然后用GPT自回归来建模语音的韵律。对于其他方面的信息,模型的处理显得较为常规:音色一般具有全局性,使用单一的音色编码器从参考音频中提取就性;对于文本语义内容的处理,模型在很大程度上参考了非自回归的FastSpeech 2。
对于语音的解码,也是分为两步:先通过MEL decoder还原为MEL谱,然后通过声码器解码为音频波形。MegaTTS 2和1总体上类似,在音色编码(音素级编码、多条参考音频)、语音提示长度(扩展同speaker语音上下文长度硬train,音频prompt长度更长)和时长建模(也用GPT自回归)上做了改进,同时堆了更大规模的数据。剪映的后端TTS模型用的就是megatts2。该工作在各论文的评测中表现也都不错。
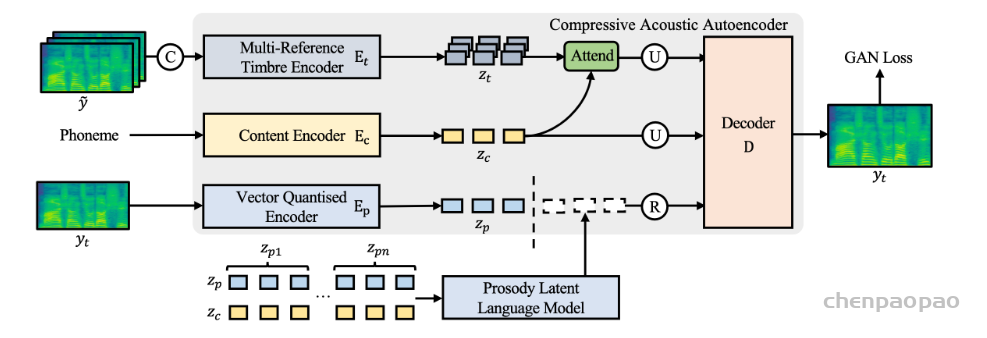
认为语音可以分解为几个属性(例如,内容、音色、韵律和相位),每个属性都应该使用具有适当归纳偏差的模块进行建模。从这个角度出发,我们精心设计了一个新颖的大型零样本 TTS 系统,称为 Mega-TTS,该系统使用大规模的野生数据进行训练,并以不同的方式对不同的属性进行建模:1) 我们没有使用音频编解码器编码的潜在作为中间特征,而是仍然选择频谱图,因为它很好地分离了相位和其他属性。Phase 可以由基于 GAN 的声码器适当构建,不需要由语言模型建模。2) 我们使用全局向量对音色进行建模,因为音色是一个随时间缓慢变化的全局属性。3) 我们进一步使用基于 VQGAN 的声学模型来生成频谱图,并使用潜在代码语言模型来拟合韵律的分布,因为句子中的韵律会随着时间的推移而快速变化,并且语言模型可以捕获局部和长期依赖关系。
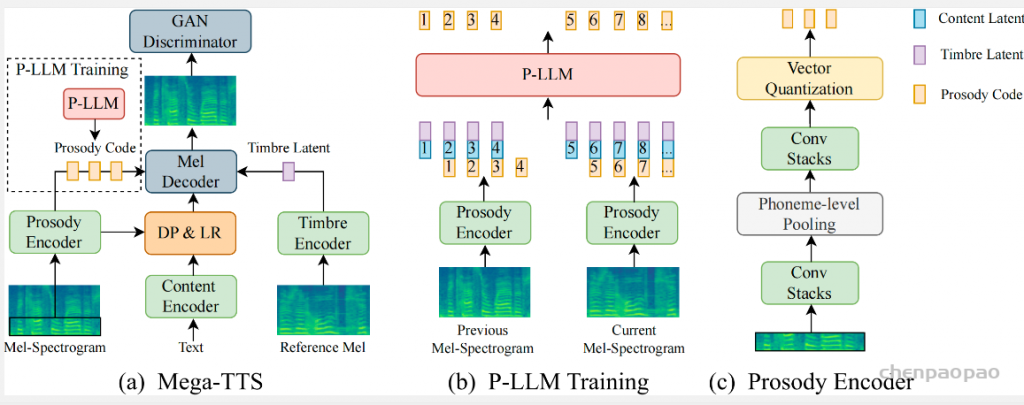
本文介绍了一种通用的零样本 TTS 提示机制 Mega-TTS 2,以应对上述挑战。具体而言,我们设计了一个强大的声学自动编码器,将韵律和音色信息分别编码到压缩的潜在空间中,同时提供高质量的重建。然后,我们提出了一个多参考音色编码器和一个韵律潜在语言模型 (P-LLM),用于从多句提示中提取有用信息。我们进一步利用从多个 P-LLM 输出得出的概率来产生可转移和可控制的韵律。实验结果表明,Mega-TTS 2 不仅可以使用来自任意来源的看不见的说话者的简短提示来合成身份保留语音,而且当数据量从 10 秒到 5 分钟不等时,其表现始终优于微调方法。