
- 论文:VOICECRAFT: Zero-Shot Speech Editing and Text-to-Speech in the Wild
- code:https://github.com/jasonppy/VoiceCraft
- demo:https://jasonppy.github.io/VoiceCraft_web/
- 特点: 一套架构支持语音克隆和音频编辑
作为Zero shot-TTS VALL-E的后续改进,VoiceCraft不得不提。可以称之为“优雅的VALL-E”。它的优雅主要体现在两个方面:casual masking和delayed stacking。所谓的causal masking,是为了用自回归GPT架构来做语音编辑任务,就是把被mask的部分移动到序列末尾去预测,一套架构同时做合成和编辑任务;所谓的delay stacking,是为了适配自回归和RVQ,通过delay错位让当前码本的token预测正好可以利用前面那些token的预测结果,比起VALL-E那样自回归和非自回归缝合在一起的结构要优雅不少。
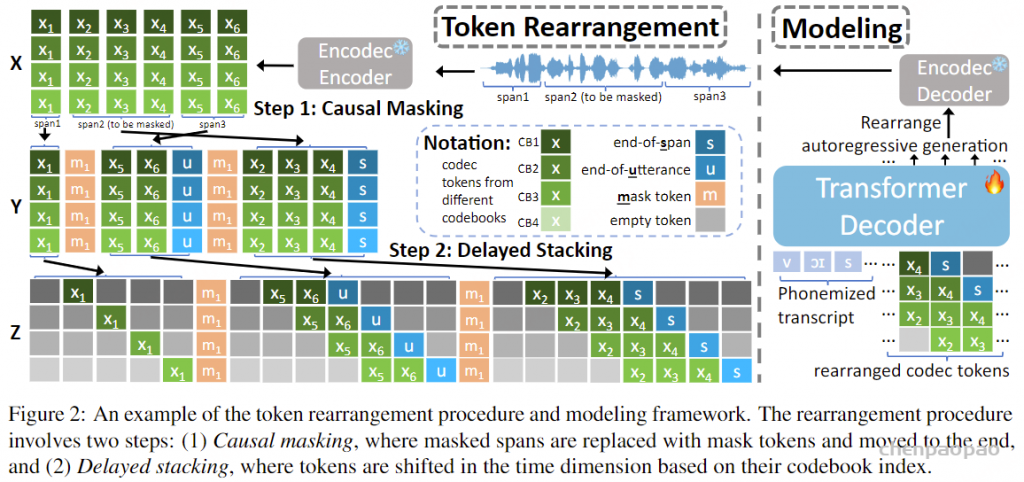
VoiceCraft 通过重新排列神经编解码器的输出标记,将序列填充(用于语音编辑)和延续(用于零样本 TTS)转换为简单的从左到右的语言建模。重排包括两个步骤:(1) 因果掩码以实现双向上下文的自回归延续/填充,以及 (2) 延迟堆叠以确保高效的多码簿建模。VoiceCraft 采用仅限解码器的 Transformer,并使用自回归序列预测 进行训练。
重排步骤 1:因果掩码:
给定一个连续的语音波形作为输入,我们首先使用 Encodec将其量化成一个 T by K codec 矩阵 X ,其中 T 是时间帧的数量,是 K RVQ 码本的数量。 X 可以写成 (X1,⋯,XT) ,其中 Xt 是一个长度 K 向量,表示在时间步 t 中来自不同码本的代码,我们假设 Codebook k 中的代码对 Codebook k−1 中的残差进行建模。在训练过程中,我们的目标是随机屏蔽一些 span 的标记 (Xt0,…,Xt1) ,然后以所有未屏蔽的标记为条件自动回归预测这些被屏蔽的标记。这在 时 t1<T 是个问题,因为在执行自回归生成时,我们无法以未来的输出为条件。我们需要修改掩码, X 使其具有因果关系,方法是将要掩码的跨度移动到序列的末尾,以便在填充这些标记时,模型可以针对过去和未来未掩码的标记。
只需将所有被屏蔽的 span 移动到序列的末尾,即可轻松地将上述过程扩展到多个被屏蔽的 span。要屏蔽 n 的 span 数从 Poison(λ) 中采样,然后对于每个 span,我们采样一个 span length l∼Uniform(1,L) 。最后,我们在约束 X 下随机选择 span 的位置,确保它们彼此不重叠。然后,选定的 n 范围将替换为掩码标记 ⟨M1⟩,⋯,⟨Mn⟩ 。这些掩码 span 中的原始标记将移动到 sequence X 的末尾,每个 span 前面都有其相应的掩码标记。
重排步骤 2:延迟堆叠
在因果掩码标记重新排列之后,重新排列矩阵 Y 的每个时间步都是标记向量 K 。Copet et al. ( 2023) 观察到,当对堆叠的 RVQ 令牌进行自回归生成时,应用延迟模式是有利的,这样时间对码簿 k 的预测 t 就可以以同一时间步长对码簿 k−1 的预测为条件。我们采用与本文类似的方法。假设 span Ys 的形状为 Ls×K .应用延迟模式会将其重新排列到 Zs=(Zs,0,Zs,1,⋯,Zs,Ls+K−1) 中,其中 Zs,t,t∈[Ls+K−1] 定义为

其中 Ys,t−k+1,k 表示位于 matrix Ys 中 coordinate (t−k+1,k) 处的标记,即 (t−k+1) 第 个时间步的 k 第 个 Codebook 条目。为了确保 ∀t∈[Ls+K−1] , Zs,t 包含 K 有效的标记,我们引入了一个特殊的可学习 [空] 标记并定义 Ys,t−k+1,k≜[empty],∀t∈{s:s<k∪s−k+1>Ls} 。请注意,掩码标记不是任何 span 的一部分,并且在延迟堆叠期间不会更改。我们定义延迟堆叠的结果矩阵 Z=(Z1,⟨M1⟩,Z2,⟨M1⟩,⋯,⟨MS−12⟩,ZS)
推理:
语音编辑。语音编辑的设置如下:我们有语音记录 R 及其转录 W ,我们希望模型仅修改 的 R 相关跨度,以便它与目标转录 W′ 匹配。我们假设 是 W′ 的编辑版本 W ,其中插入、替换或删除了一些单词。这个任务和训练任务几乎一模一样,有两个区别: 1) 在训练过程中,输入的成绩单只是原始录音 W 的成绩单,而在推理过程中,它是一个修改后的成绩单 W′ 2) 在训练过程中,要屏蔽的跨度(即 编辑)是随机选择的。在推理过程中,我们通过比较原始转录本和目标转录本来识别应该屏蔽掉的单词来选择它们,然后使用原始转录本的单词级强制对齐来识别与这些要屏蔽的单词相对应的编解码器标记跨度。为了确保已编辑的语音和未编辑的语音之间的平滑过渡,还需要对要编辑的 span 周围的相邻单词进行轻微修改,以便对协同发音效果进行建模。因此,我们指定了一个小的 margin 超参数 ϵ ,并在左侧和右侧将掩码跨度长度 ϵ 延长.
在自回归生成过程中,我们将所有未屏蔽的跨度的目标转录本提供给模型,并在应进行编辑的位置插入掩码标记。然后,我们让模型自回归地继续这个序列,从而填充被掩盖的 span。然后,生成的编解码器令牌被拼接回它们在话语中的正确位置,我们使用 Encodec 解码器网络将完整的编解码器令牌序列映射回波形。
Zero-shot TTS。正如我们之前提到的,我们模型的零样本 TTS 很简单,因为它只对应于在原始话语的末尾执行插入编辑。在这种情况下,会为模型提供语音提示及其转录,以及要生成的语音的目标转录。这三个输入连接在一起并馈送到模型,然后它自动回归地生成目标转录本的编解码器序列。