SLM(speech language model, SLM)不仅要合成合乎上下文语义的高表现力语音,合成的语音还要符合用户的即时要求。一些text-guided zero-shot TTS的工作值得参考。这些工作一般都是在已有的zero-shot TTS模型或者text-to-audio模型上改造而来,同时吸收transcription和description两路条件。其中的重点还是在于数据集的构建。这方面的工作有:PromptTTS、InstructTTS、ParlerTTS、VoiceLDM和Audiobox。
TTS模型同样可以遵循文本指令或者语音指令,合成符合用户即时要求的语音,摆脱对参考音频的依赖。text-guided zero-shot TTS在模型架构上和zero-shot TTS有非常大的相似性,但训练数据可能较为缺乏。因此,先开发zero-shot TTS,再用类似SALMONN 或者 Qwen2-audio那样的多模态理解模型来打标签(类似DALLE3的做法),这样数据集构造方式,可能会是更好的选择。
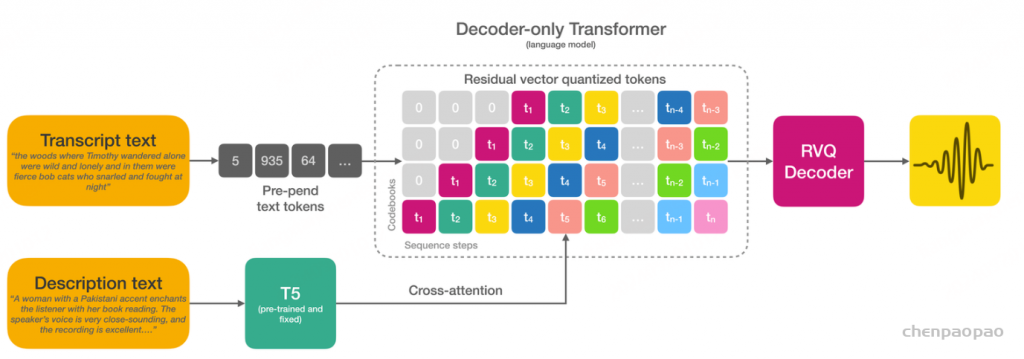
ParlerTTS
Natural language guidance of high-fidelity text-to-speech with synthetic annotations
训练代码开源:https://github.com/huggingface/parler-tts
ParlerTTS。VALL-E/VoiceCraft的增强版,通过T5编码器和cross-attention旁路引入了描述性文本的信息。该工作的目的是想使用自然语言prompt来指定说话风格和环境信息,摆脱对参考音频的依赖。描述性标签文本的收集过程也显得相当朴素:通过定制化的监督式模型获取语音数据的口音特征、录音质量特征、音高语速特征。然后用LLM将这些特征转换为自然语言的描述。在我看来,这个工作有这么几点局限性吧:其一,缺乏情绪标签;其二,语音描述性标签的收集并不具备通用性,较为繁琐,远不如一个强大的多模态语音理解模型来得实在。文章demo虽然达到了预期的效果,但场景似乎局限在朗读的情景中。
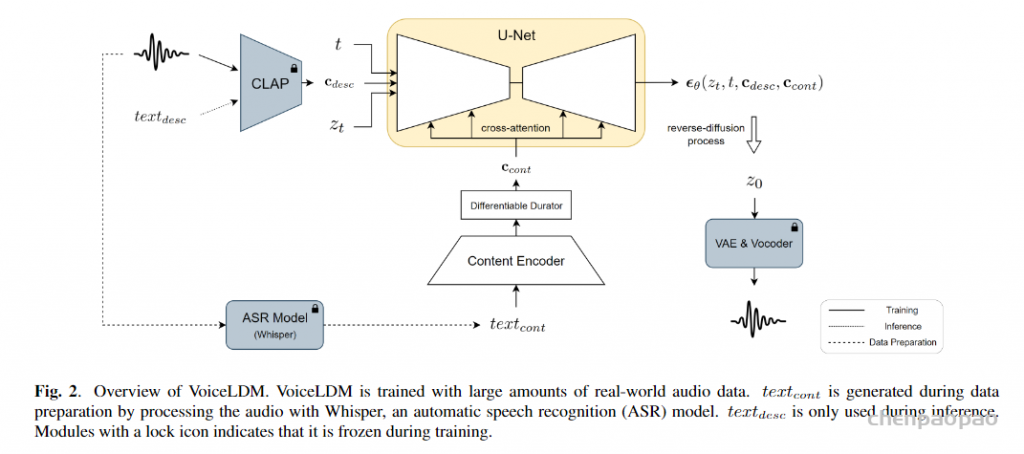
VoiceLDM
VoiceLDM: Text-to-Speech with Environmental Context
VoiceLDM。在VoiceLDM1的基础上增加了转录文本的输入。这个工作和AudioLDM 1很像,同样使用CLAP注入语音的描述性信息。不同地是,为了做TTS任务,该工作通过cross-attention旁路增加了transcription的信息。