
ArXiv: https://arxiv.org/abs/2407.05361
GitHub: https://github.com/open-mmlab/Amphion/tree/main/preprocessors/Emilia
Homepage: https://emilia-dataset.github.io/Emilia-Demo-Page/
HuggingFace: https://huggingface.co/datasets/amphion/Emilia
Emilia-Large数据集是一个全面的多语言数据集,具有以下特点:
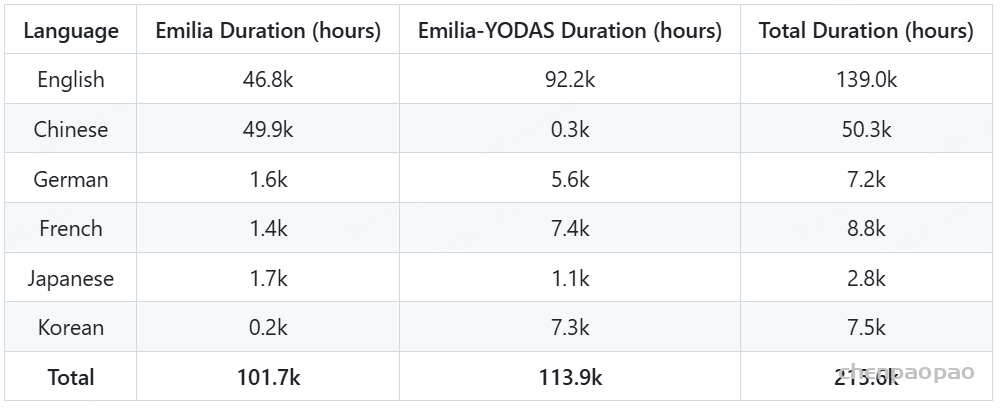
- 其中Emilia包含超过101,000小时的语音数据, Emilia-YODAS包含超过114,000小时的语音数据;
- 涵盖六种不同的语言:英语 (En)、中文 (Zh)、德语 (De)、法语 (Fr)、日语 (Ja) 和韩语 (Ko) ;
- 包含来自互联网上不同视频平台和播客的各种说话风格的多样化语音数据,涵盖脱口秀、访谈、辩论、体育评论和有声读物等各种内容类型。
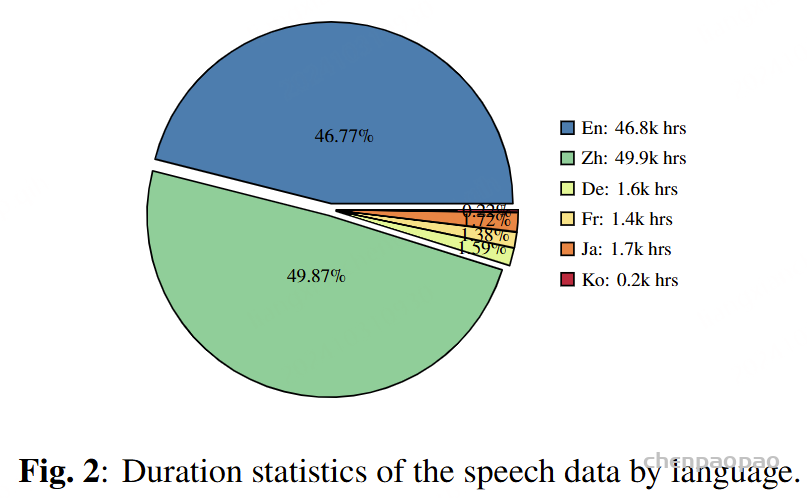
下表提供了数据集中每种语言的持续时间统计数据。
Emilia 数据集结构:
|-- openemilia_all.tar.gz (all .JSONL files are gzipped with directory structure in this file)
|-- EN (114 batches)
| |-- EN_B00000.jsonl
| |-- EN_B00000 (= EN_B00000.tar.gz)
| | |-- EN_B00000_S00000
| | | `-- mp3
| | | |-- EN_B00000_S00000_W000000.mp3
| | | `-- EN_B00000_S00000_W000001.mp3
| | |-- ...
| |-- ...
| |-- EN_B00113.jsonl
| `-- EN_B00113
|-- ZH (92 batches)
|-- DE (9 batches)
|-- FR (10 batches)
|-- JA (7 batches)
|-- KO (4 batches)JSONL 文件示例:
{"id": "EN_B00000_S00000_W000000", "wav": "EN_B00000/EN_B00000_S00000/mp3/EN_B00000_S00000_W000000.mp3", "text": " You can help my mother and you- No. You didn't leave a bad situation back home to get caught up in another one here. What happened to you, Los Angeles?", "duration": 6.264, "speaker": "EN_B00000_S00000", "language": "en", "dnsmos": 3.2927}
{"id": "EN_B00000_S00000_W000001", "wav": "EN_B00000/EN_B00000_S00000/mp3/EN_B00000_S00000_W000001.mp3", "text": " Honda's gone, 20 squads done. X is gonna split us up and put us on different squads. The team's come and go, but 20 squad, can't believe it's ending.", "duration": 8.031, "speaker": "EN_B00000_S00000", "language": "en", "dnsmos": 3.0442}Emilia-Pipe 概述 👀
Emilia-Pipe 是第一个开源预处理管道,旨在将原始的野生语音数据转换为高质量的训练数据,并带有用于语音生成的注释。此管道可以在几分钟内将一小时的原始音频处理为模型就绪数据,只需要原始语音数据。
Emilia 和 Emilia-Pipe 的详细说明可以在我们的论文中找到。
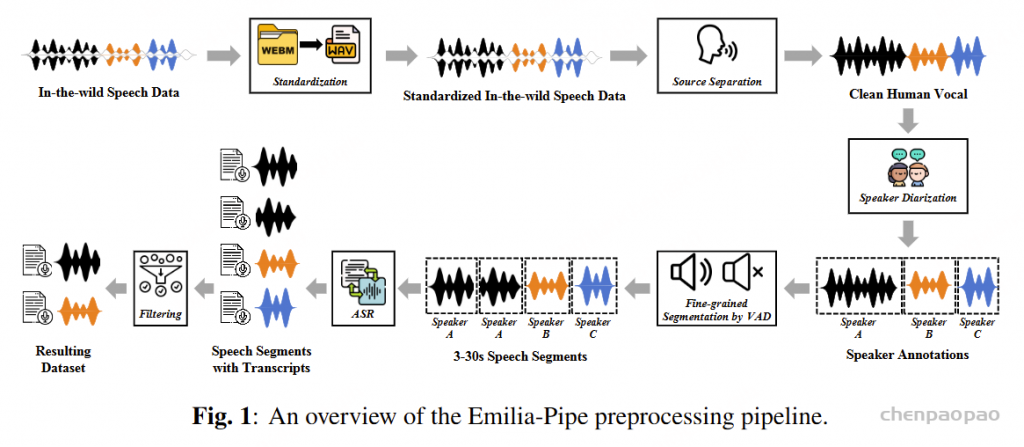
The Emilia-Pipe includes the following major steps:
Emilia-Pipe 包括以下主要步骤:
- Standardization:Audio normalization
标准化:音频标准化 - Source Separation: Long audio -> Long audio without BGM
源分离: 长音频 -> 无 BGM 的长音频 - Speaker Diarization: Get medium-length single-speaker speech data
说话人分类:获取中等长度的单个说话人语音数据 - Fine-grained Segmentation by VAD: Get 3-30s single-speaker speech segments
按 VAD 进行精细分割:获取 3-30 秒的单说话人语音片段 - ASR: Get transcriptions of the speech segments
ASR:获取语音段的听录 - Filtering: Obtain the final processed dataset
筛选:获取最终处理后的数据集
具体使用的模型:
- Source Separation: UVR-MDX-NET-Inst_HQ_3
- VAD: snakers4/silero-vad
- 说话人分类: pyannote/speaker-diarization-3.1
- ASR: m-bain/whisperX, using faster-whisper and CTranslate2 backend.
- DNSMOS 预测:DNSMOS P.835
关于ASR:
缺乏文本转录限制了 Emilia 数据集在 TTS 任务中的直接使用。为了解决这个问题,我们应用 ASR 技术对分段的语音数据进行转录。为了平衡速度和准确性,我们使用了最先进的多语言 ASR 模型 Whisper-Medium。为了进一步提高效率,我们使用了 WhisperX ,它基于更快的 Whisper 后端和 CTranslate2 8 推理引擎。该设置的速度是官方 Whisper 实现的四倍,同时几乎保持相同的准确性。为了避免重复处理,我们绕过了 WhisperX 的 VAD 组件,直接使用VAD的结果。此外,我们还实现了基于更快 Whisper 后端的批处理推理,以并行转录语音数据。这些优化显著提高了整个流程的效率。
关于筛选:
在实际场景中,一些噪声可能无法通过源分离完全处理,Whisper 模型可能会出现幻觉,某些原始语音数据可能质量较低。为了确保生成数据集的质量,我们应用以下过滤标准。首先,我们使用 Whisper 模型的语言识别结果,丢弃任何未被预测为我们目标语言(英语、法语、德语、中文、日语、韩语)或模型语言置信度低于 80% 的语音数据。其次,我们使用 DNSMOS P.835 OVRL 评分来评估整体语音质量,仅保留评分高于 3.0 的语音数据。最后,对于每个原始语音样本,我们计算其对应片段的平均字符持续时间。平均音素持续时间超出第三四分位数上方 1.5 倍四分位距(IQR)或低于第一四分位数的片段被视为异常值,相关的语音片段将被丢弃。经过过滤后,生成的数据集将用于训练语音生成模型。
DNSMOS:评估噪声抑制效果的非侵入性客观语音质量指标。人类主观评估语音质量时音频质量的“黄金标准”。传统音频评估指标需要参考干净的语音信号,这无法对真实的应用环境中的音频作出准确评估。因为真实应用中干净的语音信号难以获得。然而,传统的无参考方法与人类主观评估质量相关性很差,没有被广泛采用。本文介绍了来自微软的深度学习多阶段噪声抑制评估方法
Emilia-Large 数据集
推出全新升级的 Emilia-Large 数据集,带来以下三大核心提升:
1️⃣ 数据总量大幅提升:在原有 Emilia 101k 小时数据的基础上,新增 Emilia-YODAS 114k 小时的全新数据,开源总量突破 200k 小时,再次刷新开源 TTS 数据集的规模上限!
2️⃣ 小语种数据显著扩充:增加更多德语、法语、韩语等低资源语言数据,TTS 技术不再局限于中英文,助力全球多语言应用!
3️⃣ 商业化限制放宽:原 Emilia 数据集基于 CC-BY-NC 协议,而新增的 Emilia-YODAS 数据基于 CC-BY 协议,全面支持各类商业化应用,赋能更多创新场景!

除了数据本身的升级,我们在相关论文中深入探讨了以下研究问题:
👉 In-the-wild 数据与传统有声书数据的优势对比
👉 数据规模与TTS性能之间的关系
👉 多语言(multilingual)与跨语言(crosslingual)TTS的效果比较
Emilia-Large 数据集的发布,标志着我们在 TTS 领域的技术开放与共享迈出了重要一步。我们期待与全球开发者携手,共同推动语音技术的进步与普及,赋能更多创新应用场景!
- 📌 Emilia-Dataset: https://huggingface.co/datasets/amphion/Emilia-Dataset
- 📌 Emilia-Pipe GitHub:https://github.com/open-mmlab/Amphion/tree/main/preprocessors/Emilia
- 📌 论文:https://arxiv.org/abs/2501.15907