
- 论文链接:https://arxiv.org/abs/2409.00750
- 样例展示:https://maskgct.github.io
- 模型下载:https://huggingface.co/amphion/maskgct
- Demo 展示:https://huggingface.co/spaces/amphion/maskgct
- 项目地址:https://github.com/open-mmlab/Amphion/tree/main/models/tts/maskgct
- 公测应用:voice.funnycp.com

近期,港中大(深圳)联手趣丸科技联合推出了新一代大规模声音克隆 TTS 模型 ——MaskGCT。该模型在包含 10 万小时多语言数据的 Emilia 数据集上进行训练,展现出超自然的语音克隆、风格迁移以及跨语言生成能力,同时保持了较强的稳定性。MaskGCT 已在香港中文大学(深圳)与上海人工智能实验室联合开发的开源系统 Amphion 发布。
本文介绍了一种名为 Masked Generative Codec Transformer(MaskGCT)的全非自回归 TTS 模型。
现有大规模文本到语音(TTS)系统通常分为自回归和非自回归系统。自回归系统隐式地建模持续时间,但在鲁棒性和持续时间可控性方面存在一定缺陷。非自回归系统在训练过程中需要显式的文本与语音对齐信息,并预测语言单元(如音素)的持续时间,这可能会影响其自然度。
该模型消除了文本与语音监督之间的显式对齐需求,以及音素级持续时间预测。MaskGCT 是一个两阶段模型:在第一阶段,模型使用文本预测从语音自监督学习(SSL)模型中提取的语义标记;在第二阶段,模型基于这些语义标记预测声学标记。MaskGCT 遵循掩码预测学习范式。在训练过程中,MaskGCT 学习根据给定的条件和提示预测掩码的语义或声学标记。在推理过程中,模型以并行方式生成指定长度的标记。通过对 10 万小时的自然语音进行实验,结果表明 MaskGCT 在质量、相似度和可理解性方面优于当前最先进的零样本 TTS 系统。
一、方法
MaskGCT 模型由四个主要组件组成:
1. 语音语义表示编解码器:将语音转换为语义标记。
2. 语音声学编解码器:从声学标记重建波形。
3. 文本到语义模型【 非自回归Tranformer 】:使用文本和提示语义标记预测语义标记。
4. 语义到声学模型【非自回归Tranformer】:基于语义标记预测声学标记。

语音语义表示编解码器用于将语音转换为离散的语义标记,这些标记通常通过离散化来自语音自监督学习(SSL)模型的特征获得。与以往使用 k-means 方法离散化语义特征相比,这种方法可能导致信息损失,从而影响高质量语音的重建或声学标记的精确预测,尤其是在音调丰富的语言中。为了最小化信息损失,本文训练了一个 VQ-VAE 模型来学习一个向量量化码本,该码本能够从语音 SSL 模型中重建语音语义表示。具体来说,使用 W2v-BERT 2.0 模型的第 17 层隐藏状态作为语音编码器的语义特征,编码器和解码器由多个 ConvNext 块组成。通过改进的 VQ-GAN 和 DAC 方法,使用因子分解码将编码器输出投影到低维潜在变量空间。
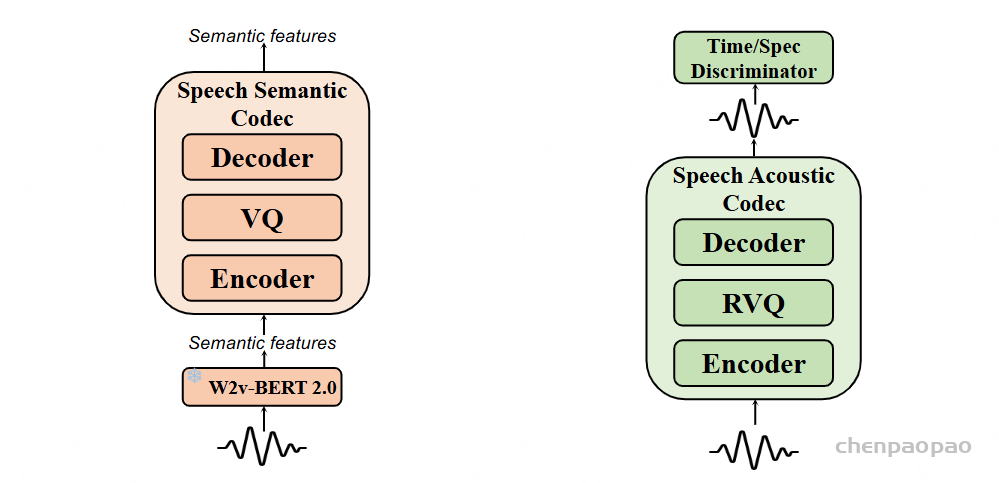
语音声学编解码器旨在将语音波形量化为多层离散标记,同时尽可能保留语音的所有信息。本文采用残差向量量化(Residual Vector Quantization, RVQ)方法,将 24K 采样率的语音波形压缩为 12 层的离散标记。此外,模型使用 Vocos 架构作为解码器,以提高训练和推理效率。
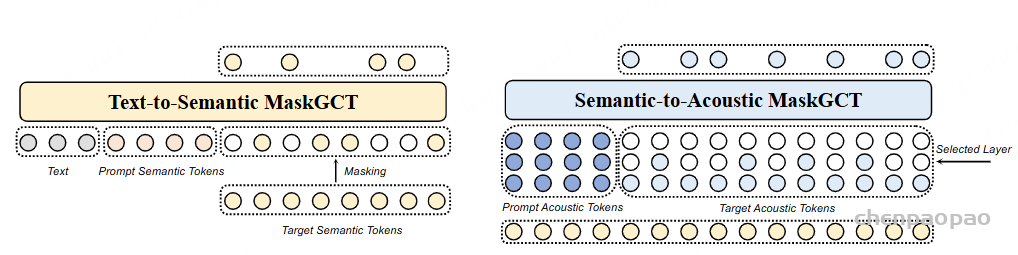
文本到语义模型采用非自回归掩码生成 Transformer,而不使用自回归模型或任何文本到语音的对齐信息。在训练过程中,我们随机提取语义标记序列的前缀部分作为提示,以利用语言模型的上下文学习能力。我们使用 Llama 风格的 Transformer 作为模型的主干,结合门控线性单元(GLU)和 GELU 激活函数、旋转位置编码等,但将因果注意力替换为双向注意力。还使用了接受时间步 t 作为条件的自适应 RMSNorm。在推理过程中,我们生成任意指定长度的目标语义标记序列,条件是文本和提示语义标记序列。本文还训练了一个基于流匹配的持续时间预测模型,以预测基于文本和提示语音持续时间的总持续时间,利用上下文学习。
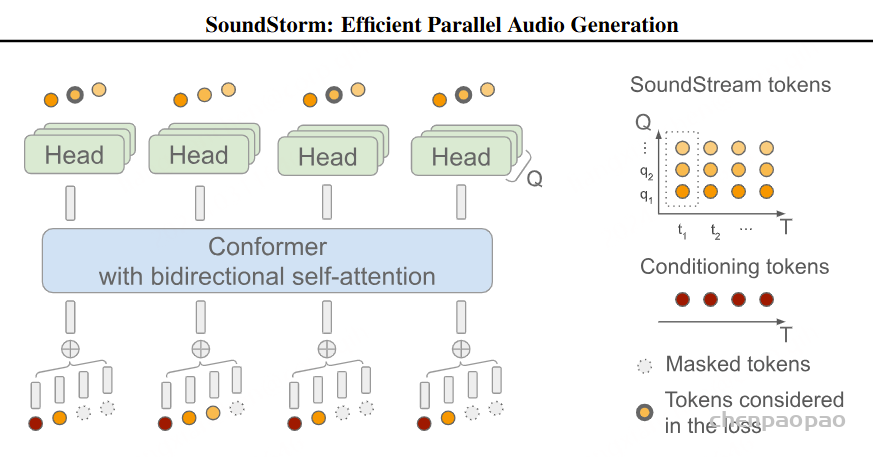
语义到声学模型同样采用非自回归掩码生成 Transformer,【基于 SoundStorm】,该模型以语义标记为条件,生成多层声学标记序列以重建高质量语音波形。对于 S2A 模型的输入,由于语义令牌序列中的帧数等于提示声学序列和目标声学序列中帧数的总和,我们简单地将语义令牌的嵌入和从层 1 到层 j的声学令牌的嵌入相加。在推理过程中,我们从粗到细为每层生成令牌,在每层内使用迭代并行解码。
二、支持的功能
MaskGCT 能超自然地模拟参考音频音色与风格,并跨语言生成音频
Zero-shot In-context Learning 根据提示音频自动生成下文
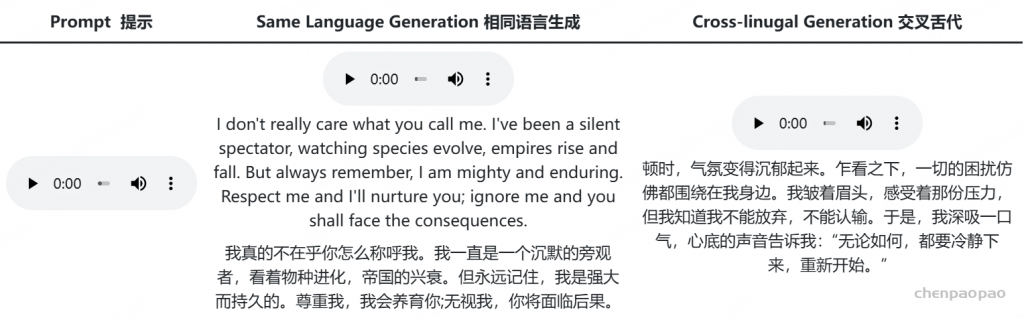
MaskGCT 可以模仿名人或动画节目中角色的声音。

MaskGCT 可以学习提示语音的韵律、风格和情感。
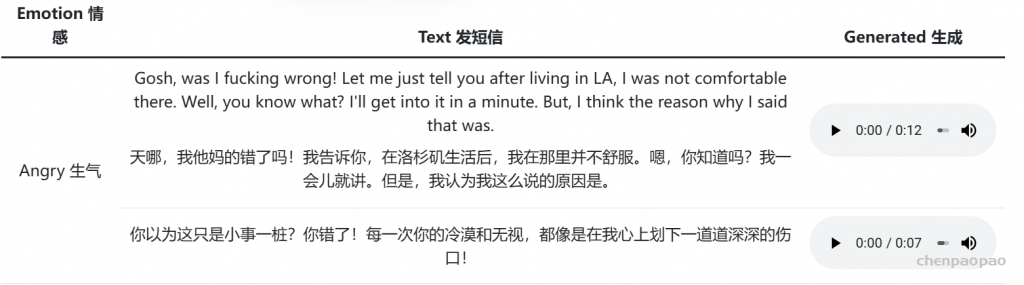

MaskGCT 可以从提示语音中学习如何说话,包括情感和口音等风格。

MaskGCT 具有控制生成音频的总持续时间的能力,从而使我们能够将生成的语音的速度调节在合理的范围内。

与 AR 模型相比,MaskGCT 表现出更高的稳健性(更低的 WER),在一些具有挑战性的情况下(例如绕口令和 AR 模型容易产生幻觉的其他样本)表现出增强的稳定性。

Speech Editing 语音编辑。
基于掩码和预测机制,我们的文本到语义模型支持在文本-语音对齐器的帮助下进行零镜头语音内容编辑。通过使用对齐器,我们可以识别原始语义标记序列的编辑边界,屏蔽需要编辑的部分,然后使用编辑后的文本和未屏蔽的语义标记来预测被屏蔽的语义标记。

语音对话。MaskGCT 通过使用改进的训练策略微调 S2A (语义到声学)模型来支持零镜头语音转换。我们仍在努力提高语音转换的有效性。源和提示示例来自 Seed-TTS 的 demo 页面。

跨语言视频翻译。

三、实验结果
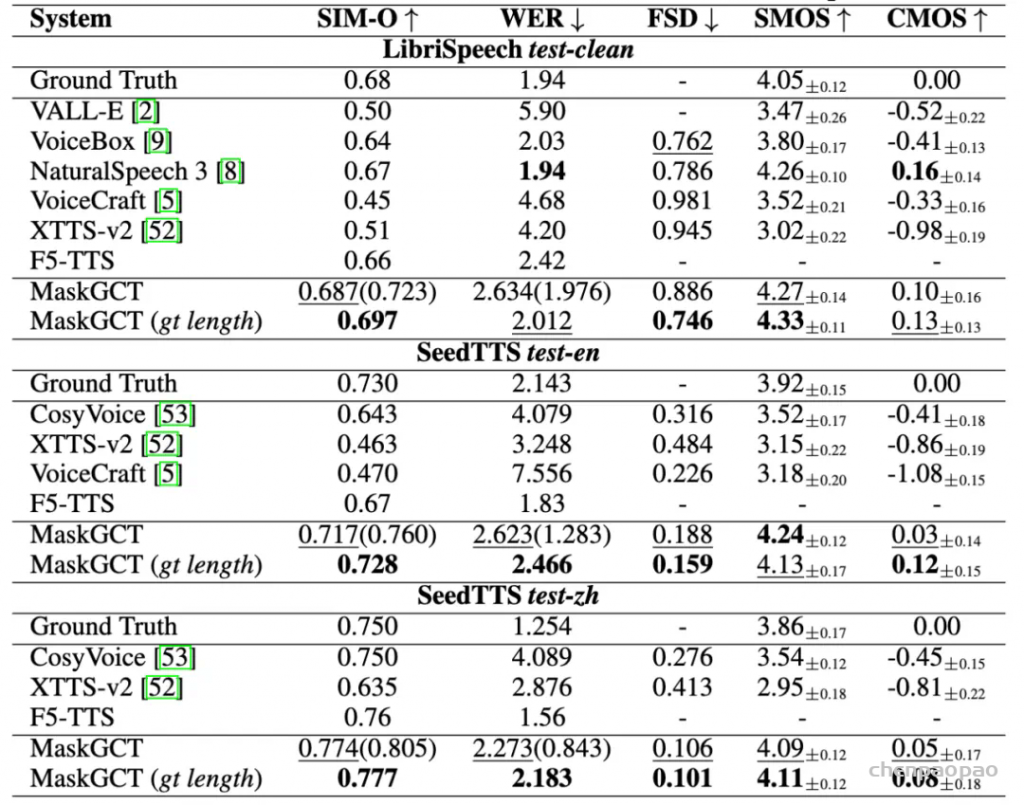
SOTA 的语音合成效果:MaskGCT 在三个 TTS 基准数据集上都达到了 SOTA 效果,在某些指标上甚至超过了人类水平。
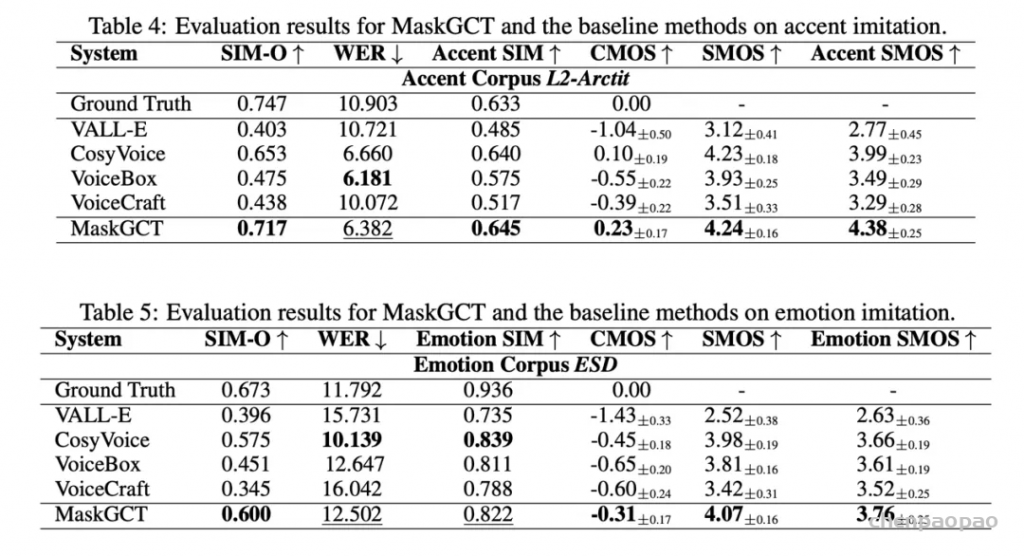
此外,MaskGCT 在风格迁移(口音、情感)也达到了 SOTA 的水准:
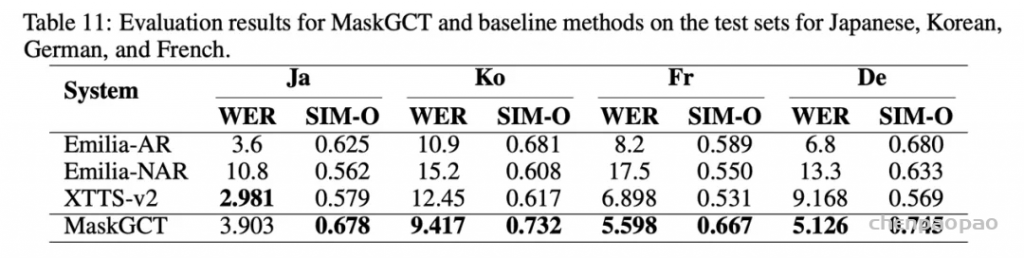
我们还研究了 MaskGCT 在中、英外其它语言的能力:
四、应用场景
目前,MaskGCT 在短剧出海、智能助手、有声读物、辅助教育等领域拥有丰富的应用场景。为了加快落地应用,在安全合规下,趣丸科技打造了多语种速译智能视听平台 “趣丸千音”。一键上传视频即可快速翻译成多语种版本,并实现音话同步、口型同步、去字幕等功能。该产品进一步革新视频翻译制作流程,大幅降低过往昂贵的人工翻译成本和冗长的制作周期,成为影视、游戏、短剧等内容出海的理想选择平台。
《2024 年短剧出海白皮书》显示,短剧出海成为蓝海新赛道,2023 年海外市场规模高达 650 亿美元,约为国内市场的 12 倍,短剧出海成为蓝海新赛道。以 “趣丸千音” 为代表的产品的出现,将加速国产短剧 “走出去”,进一步推动中华文化在全球不同语境下的传播。
五、总结
MaskGCT 是一个大规模的零样本 TTS 系统,利用全非自回归掩码生成编解码器 Transformer,无需文本与语音的对齐监督和音素级持续时间预测。MaskGCT 通过文本预测从语音自监督学习(SSL)模型中提取的语义标记,然后基于这些语义标记预测声学标记,实现了高质量的文本到语音合成。实验表明,MaskGCT 在语音质量、相似度和可理解性方面优于最先进的 TTS 系统,并且在模型规模和训练数据量增加时表现更佳,同时能够控制生成语音的总时长。此外,我们还探索了 MaskGCT 在语音翻译、语音转换、情感控制和语音内容编辑等任务中的可扩展性,展示了 MaskGCT 作为语音生成基础模型的潜力。