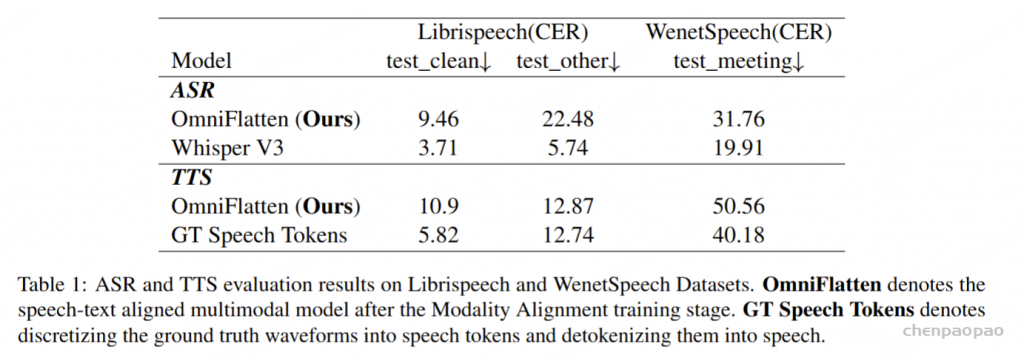
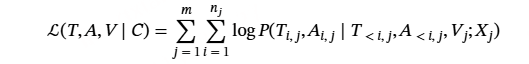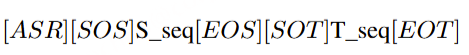Mini-Omni:语言模型可以在流中听、说和思考
Github:https://github.com/gpt-omni/mini-omni
Paper:arxiv.org/abs/2408.16725
对话训练数据集开源:VoiceAssistant-400K is uploaded to Hugging Face.【基于cosyvoice合成的】
- Qwen2 as the LLM backbone.
- litGPT for training and inference.
- whisper for audio encoding.【用于模型音频表征编码】
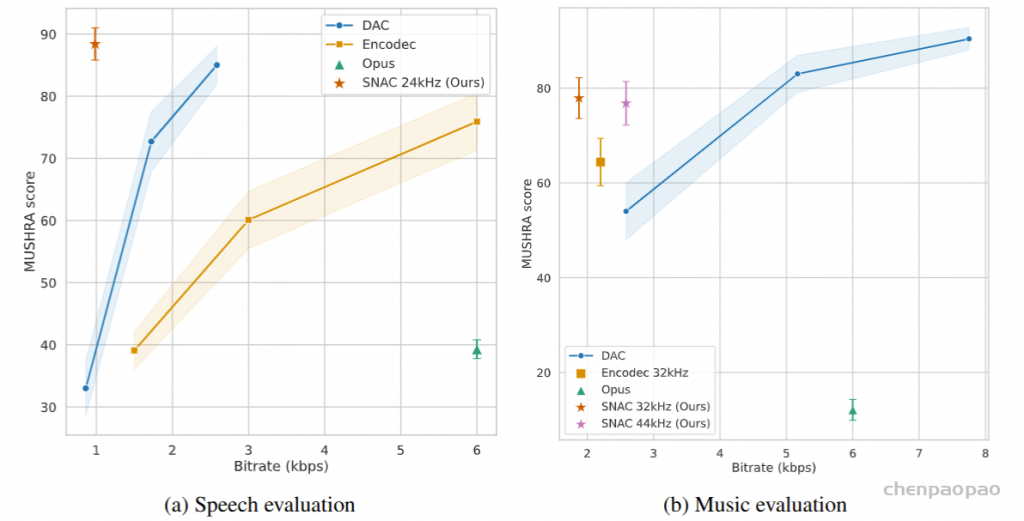
- snac for audio decoding.【RVQ架构用于模型音频解码】
- CosyVoice for generating synthetic speech.【用于合成训练数据】
- OpenOrca and MOSS for alignment.
- Mini-Omni的基本思想是通过文本来指导音频的生成,这种方法基于假设:text token有更高的信息密度,可以使用更少的token表示相同的信息。
- 生成音频token时以对应文本token为条件,类似在线语音合成系统,且生成音频前用 N 个pad token填充,确保先产生文本token。
- 模型可依据说话者和风格的embedding,控制说话者特征和风格元素。
Introduction
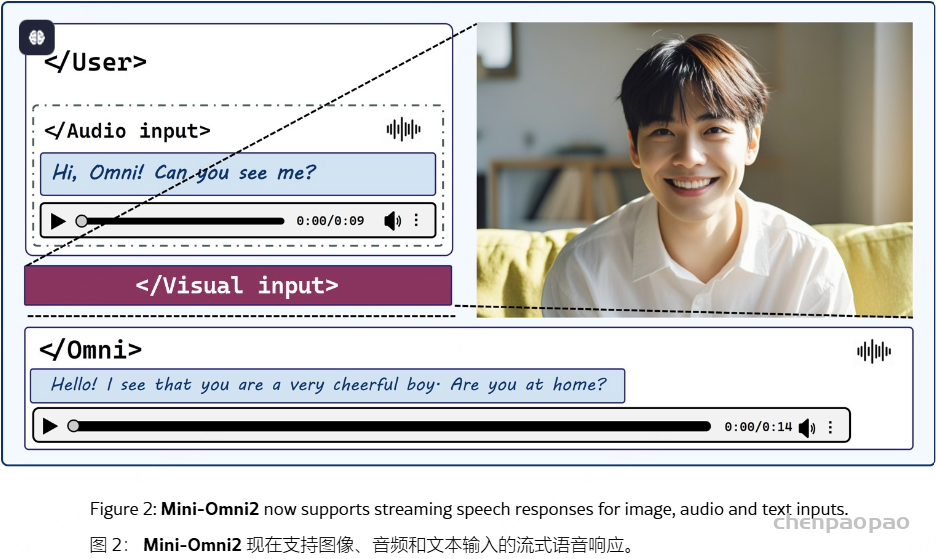
Mini-Omni,这是一种基于音频的端到端对话模型,能够进行实时语音交互。为了实现这种能力,提出了一种文本指导的语音生成方法,以及推理过程中的批处理并行策略,以进一步提高性能。该方法还有助于以最小的退化保留原始模型的语言能力,使其他工作能够建立实时交互能力。我们将这种训练方法称为 “Any Model Can Talk”。我们还引入了 VoiceAssistant-400K 数据集,以微调针对语音输出优化的模型。据我们所知,Mini-Omni 是第一个用于实时语音交互的完全端到端的开源模型,为未来的研究提供了宝贵的潜力。
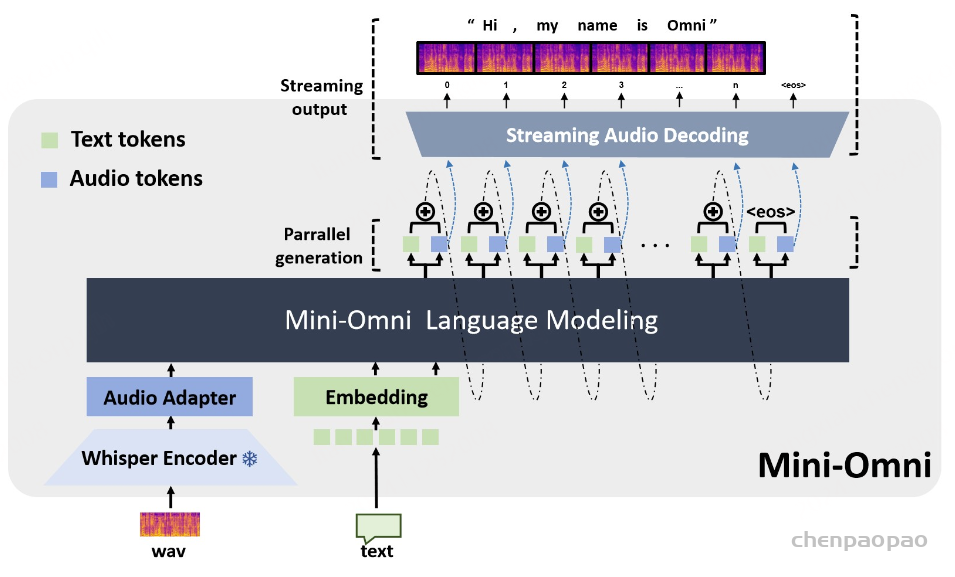
Mini-Omni,这是第一个具有实时对话功能的开源多模型大型语言模型,具有完全端到端的语音输入和输出功能。它还包括各种其他音频转文本功能,例如自动语音识别 (ASR)。我们采用了目前可用的现成方法来离散语音标记,并采用了最简单的模型架构,使我们的模型和方法很容易被其他研究人员采用。直接音频推理带来了重大挑战;然而,我们的方法仅使用 0.5B 模型和有限数量的合成音频数据就成功地解决了这个问题。
重要的是,我们的训练框架可以在不严重依赖广泛的模型功能或大量数据的情况下实现这一目标。
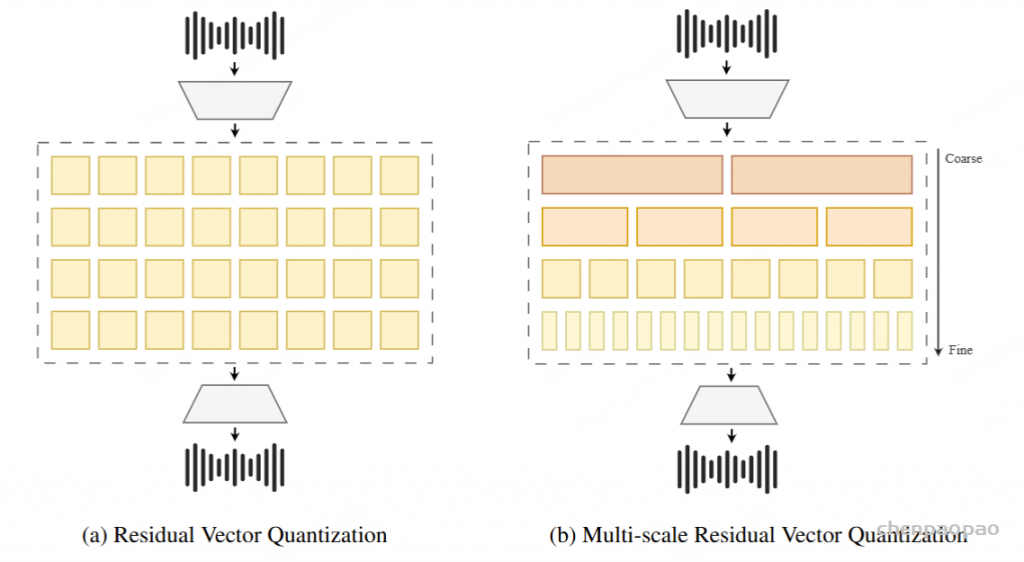
为了利用和保留语言模型的原始功能,我们提出了一种并行生成范式,其中 transformer 同时生成音频和文本标记。随后,我们观察到音频模态对文本能力的影响很小,并进一步引入了基于批处理的并行生成,这显着增强了模型在流式音频输出过程中的推理能力。作为一个 重要决策,我们选择不牺牲音频质量来换取更简单、比特率更低的音频编码器,以降低模型中音频推理的复杂性。但是,为了确保音频质量,我们选择了 SNAC ,这是一款音乐级编码器,具有 8 层码本,每秒处理数百个令牌。创新地,我们应用了文本指导的延迟并行生成来解决长 SNAC 码本序列的问题。实验表明,音频输出质量与常见的 TTS 系统相当。
我们还提出了一种方法,该方法只要对原始模型进行最少的训练和修改,使其他工作能够快速发展自己的语音能力。我们将这种方法称为 “Any Model Can Talk”,旨在使用有限数量的附加数据实现语音输出。该方法通过额外的适配器和预先训练的模型来扩展语音功能,并使用少量合成数据进行微调。这与上述并行建模方法相结合,可以在新模态中启用流式输出,同时保留原始模型的推理能力。
最后,观察到大多数开源 QA 数据集都包含混合代码或过长的文本,这使得它们不适合语音模型。为了克服这一限制,我们引入了 VoiceAssistant-400K 数据集,其中包含超过 400,000 个由 GPT-4o 专门生成的条目,用于语音助理监督微调 (SFT)。
方法
提出了一种同时生成文本和音频的新方法。这种方法假设文本输出具有更高的信息密度,因此可以通过更少的标记实现相同的响应。在生成音频标记的过程中,模型能够高效地基于对应的文本标记进行条件生成,类似于在线 TTS 系统。为确保在生成音频标记之前先生成对应的文本标记,我们在模型中引入了以 N 个标记进行填充的机制,该值可作为超参数进行调整。此外,模型还能够基于说话人嵌入和风格嵌入进行条件生成,从而实现对说话人特征和风格元素的控制。
将audio token和text token合并成新的词表,生成时同时预测audio token和text token,Loss如下:
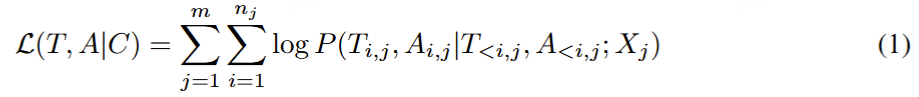
其中 T ,A 是训练语料 C 中的文本-音频输出对,m 是训练样本的数量。 Xj 是第 j 个示例的输入条件,nj 是 的最大个数样本 Tj 和 Aj、Ti,j 和 Ai,j 表示第 j 个样本的第 i 个文本标记和音频标记。
解码策略
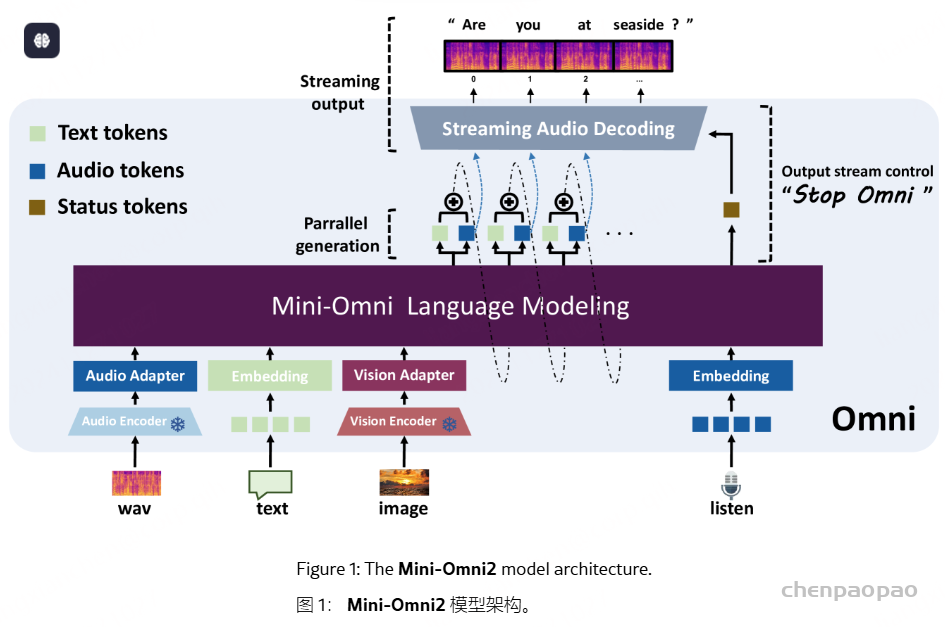
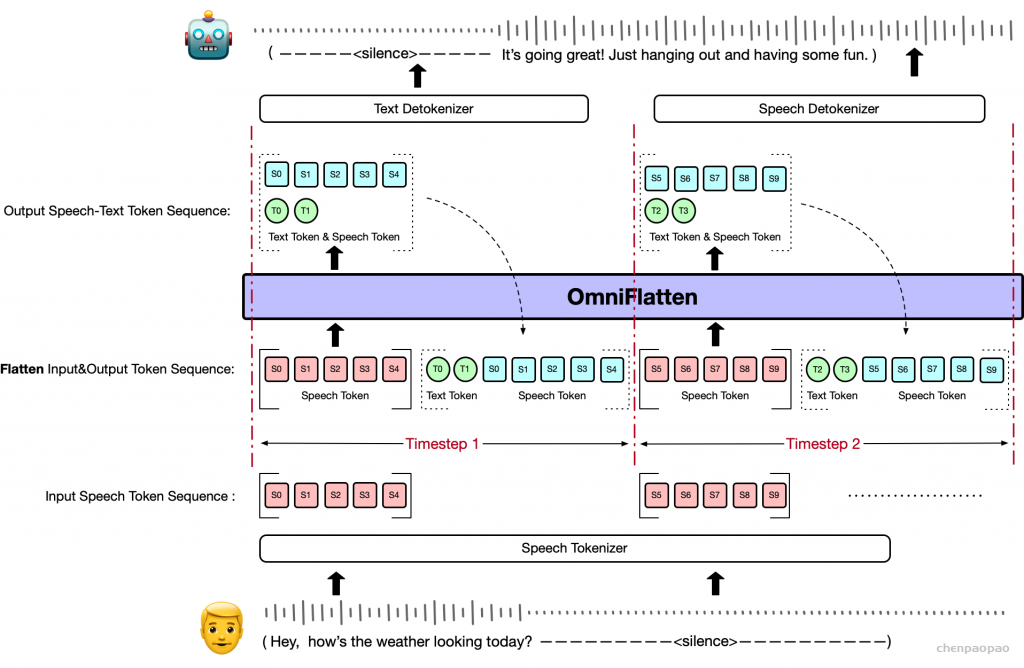
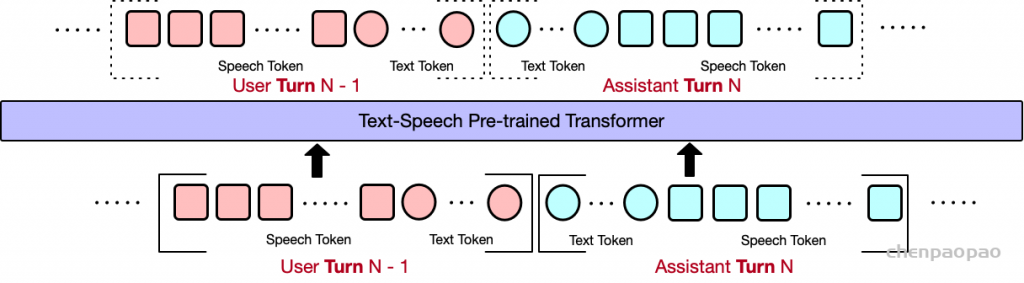
Mini-Omni 对响应进行了重组,通过文本-音频并行解码方法将这些推理能力转移到流式音频输出。这种方法同时输出音频和文本令牌,并通过文本到语音合成生成音频,确保实时交付,同时利用基于文本的推理优势。为了与大型模型的输入保持一致,在生成下一个标记之前,将并行生成的所有序列相加,如图 1 所示。这种方法使模型能够在聊天场景中实现实时语音输出,同时将第一个标记延迟降至最低。
文本延迟并行解码。并行生成最早是由 MusicGen引入的,以加速音乐生成过程,我们已将这种方法集成到文本模态中以增强推理能力。并行解码是可行的,因为语言模型训练中使用的音频标记码本通常由多个层组成;同时生成所有层可以显著提高模型速度。对于实时语音输出模型,并行解码更为重要,它允许在标准设备上每秒生成数百个音频令牌。在本文中,我们采用 SNAC 作为音频编码器,它由 7 个具有互补关系的标记层组成。因此,我们采用 8 个子语言模型头(sub-Language Model heads),一步生成 8 个标记,包括文本,同时在相邻层之间保持一步延迟。由于音频令牌是从文本合成派生的,因此首先输出文本令牌,然后输出从第一层到第七层的 SNAC 令牌。我们提出的文本优先延迟并行解码的过程如图 2(b) 所示。
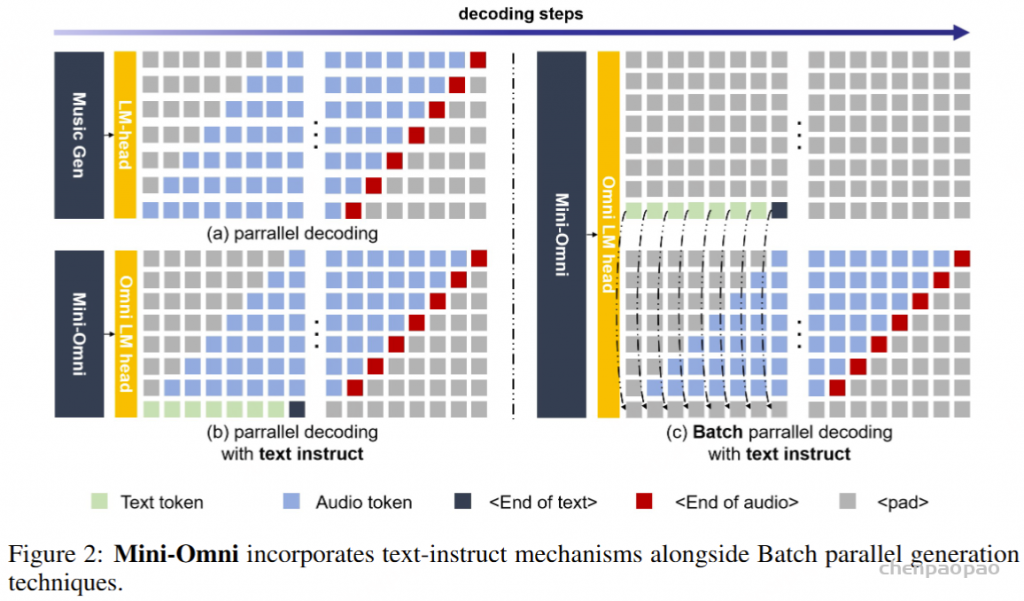
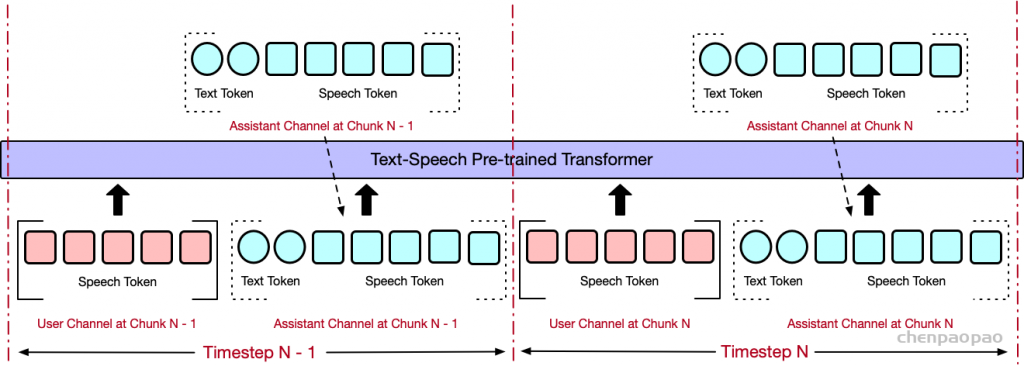
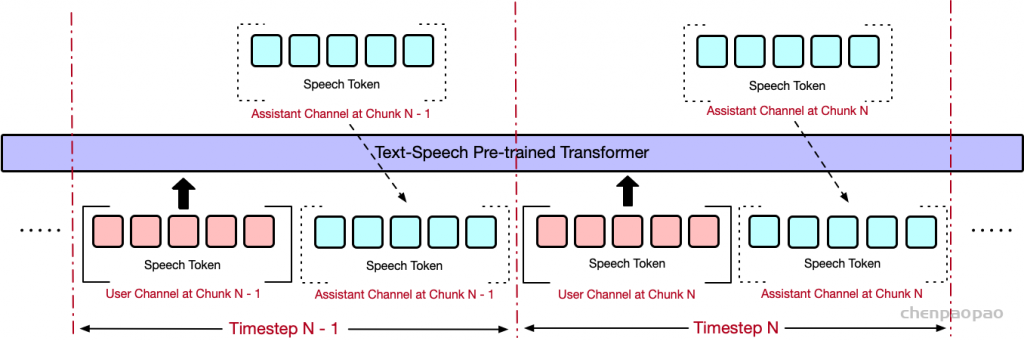
批量并行解码。尽管前面介绍的并行生成方法有效地将推理能力从文本模态转移到音频模态,但我们的实验表明,模型的推理性能在文本和音频任务之间仍然存在差异,音频响应往往更简单。我们假设这是由于模型容量的限制或音频数据不足造成的。为了解决这个问题并进一步增强模型在对话过程中的推理能力,最大限度地转移其基于文本的能力,我们实验性地采用了 Batch 方法。鉴于该模型在文本模态中的性能更强,我们将单个输入的推理任务扩展到批量大小 2:如前所述,一个样本需要文本和音频响应,而另一个样本只需要文本响应,专注于基于文本的音频合成。但是,第一个样本的文本标记输出将被丢弃,第二个样本的文本输出将嵌入到第一个样本的相应文本标记位置。同时,使用第二个样本的纯文本响应中的内容对第一个样本中的音频进行流式处理;我们将此过程称为 Batch 并行解码。通过这种方法,我们以最小的资源开销,有效地、几乎完全地将模型的基于文本的能力转移到音频模态中,从而显着增强了它在新模态中的推理能力。批量并行解码的推理过程如图 2(c) 所示。我们相信批量并行解码代表了一项关键的算法创新,它使如此小的模型能够表现出强大的对话能力。
训练方法:Any Model Can Talk
该方法旨在尽可能保留原始模型的功能。这首先是由于我们的基础模型的强大性能,其次是因为该方法可以应用于其他在文本输出方面表现出色但缺乏强大的语音交互能力的工作。
Audio Encoding:音频输入主要侧重于从输入音频中提取特征,选项包括 Hubert 或单独预训练的音频编码器。鉴于我们专注于语音输入,Whisper 和 Qwen2-audio也展示了在一般音频任务中的有效性能。对于音频输出,使用多码本方法选择音频令牌可以更好地捕获音频细节。尝试了用于音频令牌建模的扁平化,但结果导致令牌过长,这对流式有害,并导致学习不稳定。相反,受 MusicGen 启发的并行解码采用了延迟模式与文本条件相结合。
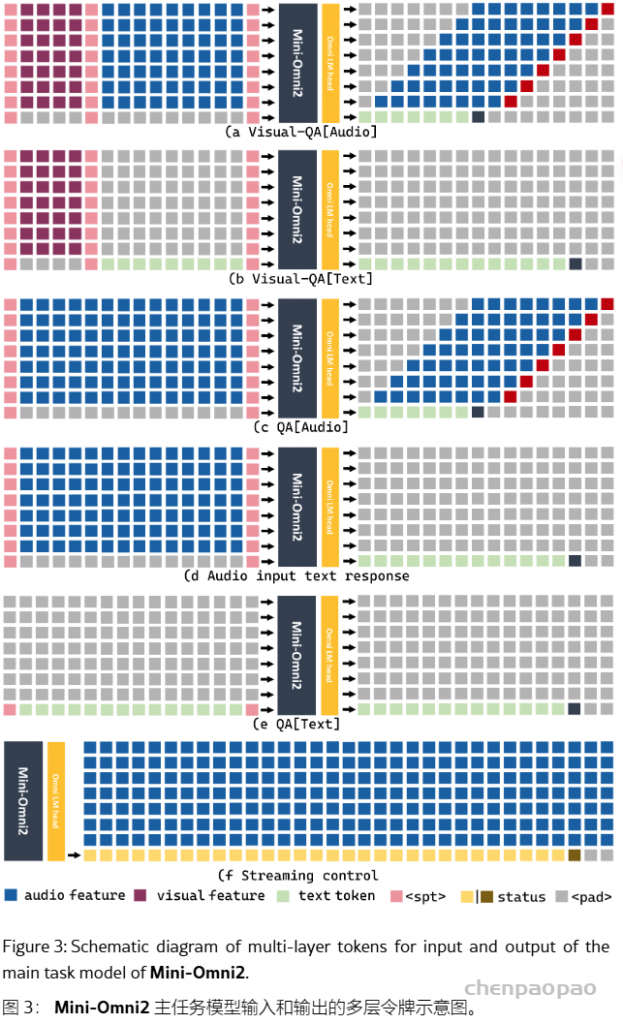
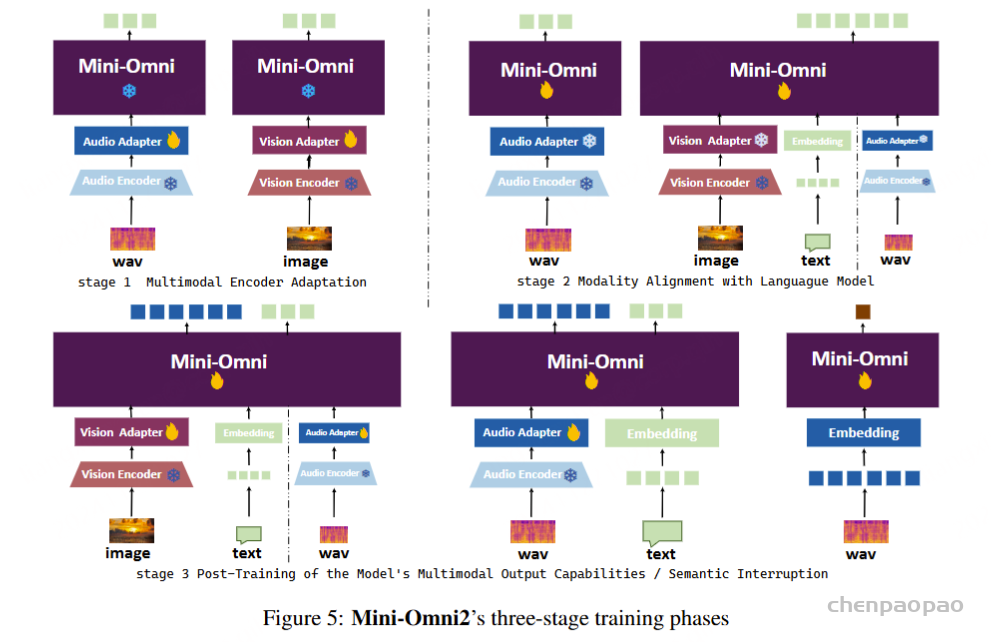
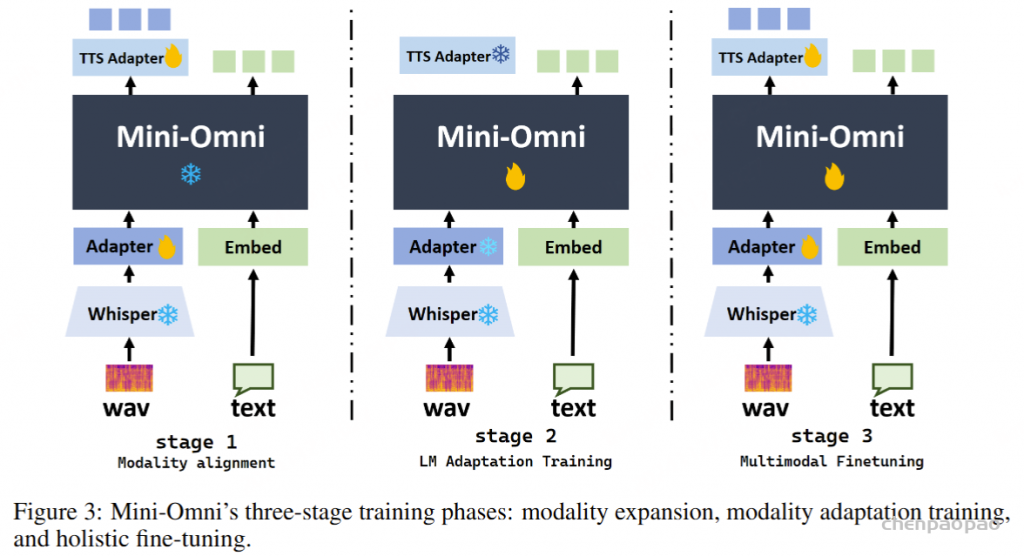
三阶段训练。 我们的训练方法分为三个不同的阶段:(1) 模态对齐。此阶段的目标是增强文本模型理解和生成语音的能力。Mini-Omni 的核心模型完全冻结,只允许在两个适配器中使用gradients 。在此阶段,我们使用来自语音识别和语音合成的数据来训练模型的语音识别和合成能力。(2) 适应训练。一旦新模态与文本模型的输入对齐,适配器就会被冻结。在这个阶段,我们只专注于在给定音频输入时训练模型的文本功能,因为音频输出只是从文本合成的。该模型使用来自语音识别、语音问答和其他文本响应的任务【 TextQA 和 AudioQA 】的数据进行训练。(3) 多模态微调。在最后阶段,使用综合数据对整个模型进行微调。此时,所有模型权重都已解冻并训练。由于主要模态对齐任务是在适配器训练期间处理的,因此最大限度地保留了原始模型的功能。
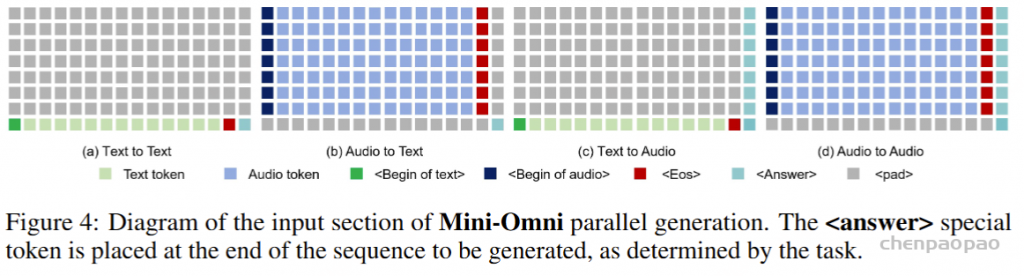
模型输入 ID。给定 8 个并行输出序列,输入也需要 8 个序列,这导致了极大的复杂性。因此,我们在这里简要概述了模型输入的组织。该模型可以接受文本或音频输入,这些输入被放置在相应的模态序列中。对于音频输入,输入token和 Whisper 特征通过适配器转换为相同维度的张量,然后连接起来。根据任务的不同,我们将特殊 token 放置在不同的位置,引导模型的输出,实现多模态输出。一些任务的组织如图 4 所示。在输入模型之前,所有序列都会相加并求平均值以集成特征。
实验
数据:
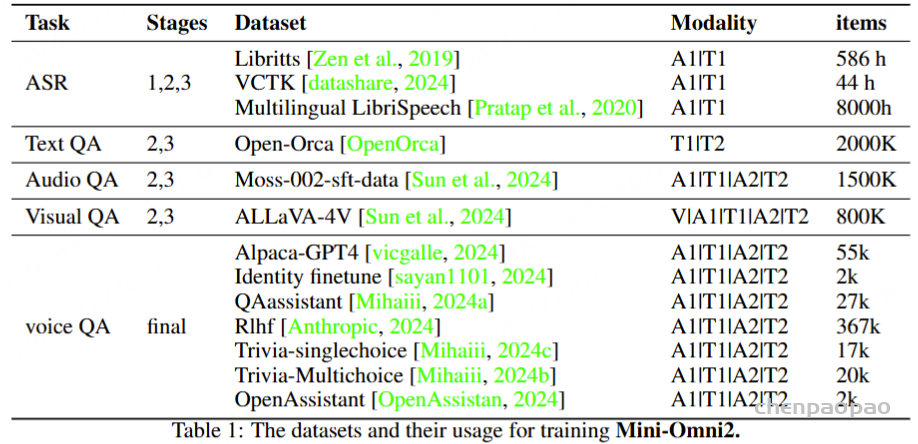
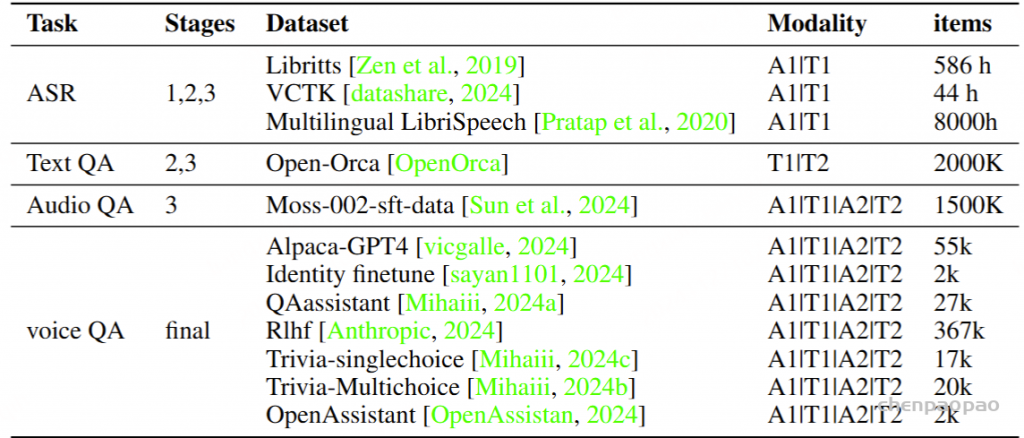
为了建立基础语音功能,我们使用三个语音识别数据集训练了模型,总计约 8,000 小时,专注于语音理解和合成。对于文本模态,我们整合了来自 Open-Orca (OpenOrca,) 数据集的 200 万个数据点,并将它们与其他模态集成以保持文本准确性。Moss 的 SFT 数据集 (Sun et al., 2024) 与零样本 TTS 一起使用,合成了 150 万个语音 QA 对。为避免不合适的代码和符号输出,我们使用 GPT-4o 创建了 VoiceAssistant-400K 数据集。表 1 中详细介绍了数据集。阶段 1 涉及用于训练语音适配器的 ASR 数据。阶段 2 使用 TextQA 和 AudioQA 进行音频/文本输入和文本响应训练。第 3 阶段侧重于使用 AudioQA 的音频模态进行多模态交互。最后阶段的培训包括退火和语音 QA 微调。
训练参数:
模型在 8 个 A100 GPU 上进行训练,使用余弦退火学习率调度器,最小学习率为 4e-6,最大学习率为 4e-4。每个训练 epoch 由 40000 个步骤组成,每个步骤的批次大小为 192。基本语言模型采用 Qwen2-0.5B ,这是一种具有 24 个块且内部维度为 896 的 transformer 架构。语音编码器使用 Whisper-small 编码器,ASR 适配器通过两层 MLP 连接,TTS 适配器通过添加 6 个额外的transformer 块来扩展原始模型。在微调过程中,我们使用从 4e-6 到 5e-5 的学习率。
实验结果:
首先评估了该模型在 ASR 任务上的性能,以评估其语音理解能力。使用 LibriSpeech 的四个测试集。
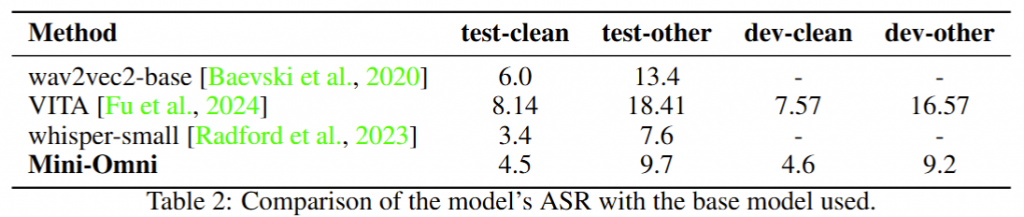
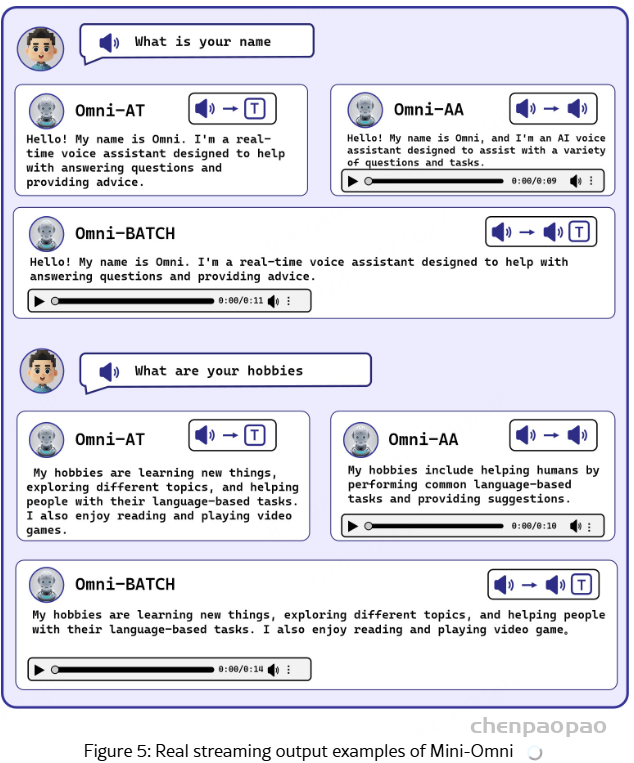
Case Study
我们展示了几个案例来演示 Mini-Omni 在语音理解和推理方面的能力。这些示例表明,与基于文本的推理相比,基于语音的推理要弱一些,这凸显了批量生成的必要性。更多令人印象深刻的例子,请参考 https://github.com/gpt-omni/mini-omni。
总结
Mini-Omni,这是第一个具有直接语音转语音功能的多模态模型。在以前使用文本引导语音生成的方法的基础上,我们提出了一种并行文本和音频生成方法,该方法利用最少的额外数据和模块将语言模型的文本功能快速传输到音频模态,支持具有高模型和数据效率的流式输出交互。我们探索了文本指令流式并行生成和批量并行生成,进一步增强了模型的推理能力和效率。我们的方法使用只有 5 亿个参数的模型成功地解决了具有挑战性的实时对话任务。我们开发了基于前适配器和后适配器设计的 Any Model Can Talk 方法,以最少的额外训练促进其他模型的快速语音适应。此外,我们还发布了 VoiceAssistant-400K 数据集,用于微调语音输出,旨在最大限度地减少代码符号的生成,并以类似语音助手的方式帮助人类。我们所有的数据、推理和训练代码都将在 https://github.com/gpt-omni/mini-omni 逐步开源。