
一个革命性的开源音频模型——Hertz-dev 横空出世,凭借其惊人的性能指标,让全球开发者为之震撼。这款拥有 85 亿参数的 AI 语音巨兽,通过 2000 万小时高质量音频数据的训练,成功实现了人类梦寐以求的全双工实时对话。最令人惊叹的是其 120 毫秒的超低延迟表现,较现有公开模型足足提升了一倍,让人机对话体验提升到了一个全新境界。想象一下,当你在和 AI 对话时,不必再等待对方说完就能自然插话,就像真实的人类对话一样流畅自然。
Hertz-dev 的核心突破包括:
–突破性全双工技术: 彻底颠覆传统轮流发言模式,实现真正的双向实时交流。
– 卓越音频压缩: 在保证高音质的同时,大幅降低带宽占用。
– 超长对话能力: 轻松理解和生成持续性对话内容。
– 革命性低延迟: 120 毫秒的响应速度,开创实时互动新纪元。
官方介绍:Hertz-dev 在 RTX 4090 上的理论延迟为 65 毫秒,实际平均延迟为 120 毫秒。这比世界上任何公共模型的延迟都低约 2 倍——这是模型能够以类似人类的方式与您互动的先决条件,而不是感觉像延迟、断断续续的电话通话。作者目前正在训练更大、更先进的 Hertz 版本,它将使用缩放的基础模型配方和 RL 调整来大幅提高模型的原始功能和最终一致性。Hertz-dev 是实时语音交互未来的一瞥,也是世界上最容易让研究人员进行微调和构建的对话音频模型。

代码地址:https://github.com/Standard-Intelligence/hertz-dev
体验地址:https://si.inc/hertz-dev/
在过去的几个月里,Standard Intelligence 团队一直在进行跨模态学习研究。我们很高兴地宣布,我们将开源这项研究的早期产品,即 8.5B、全双工、纯音频基础模型:hertz-dev。
音频模态对于创建感觉自然的交互式代理至关重要。目前,利用音频与生成式 AI 的两种方法是基于扩散的方法或自回归方法。虽然基于扩散的音频模型被证明擅长音乐生成和小样本,但真正的交互式音频生成需要是自回归的。
该领域最大的问题是 1) 获得听起来像人类的音频生成(即非合成的以及很好地处理中断)和 2) 使用两个实时频道处理实时生成,这两个频道都在产生信息,就像正常的人类对话一样。
我们的模型处于这两者的最前沿,原生适应双扬声器格式,具有比人类更快的反应时间,并且完全能够解析和生成重叠的双扬声器音频。我们通过在潜在空间中操作以及使用量化语音位来实现这一点,从而允许 80ms 的理论平均延迟,每个时间步长只有一个采样的延迟。目前,我们在单个 RTX 4090 上对 120ms 的实际延迟进行了基准测试,比之前最先进的延迟低 2 倍。
模型架构:
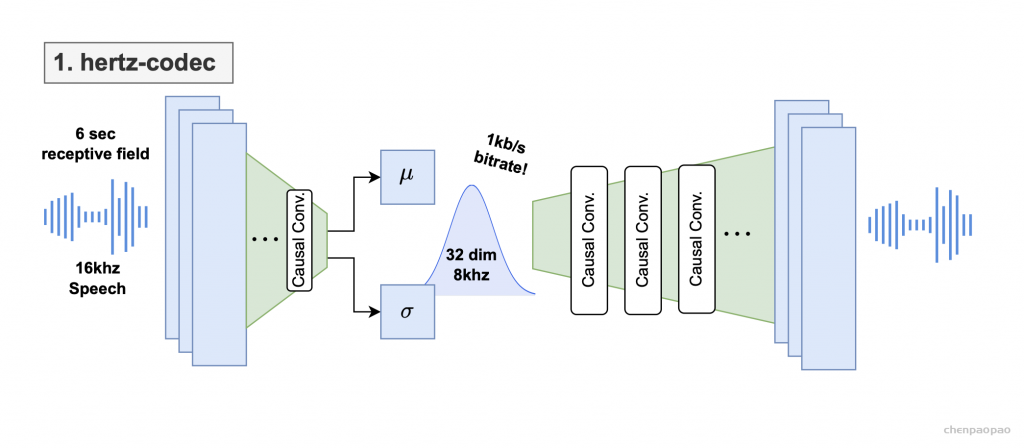
hertz-codec architecture diagram for our VAE. The input is 6s 16kHz mono audio and the output is a 32-dim latent.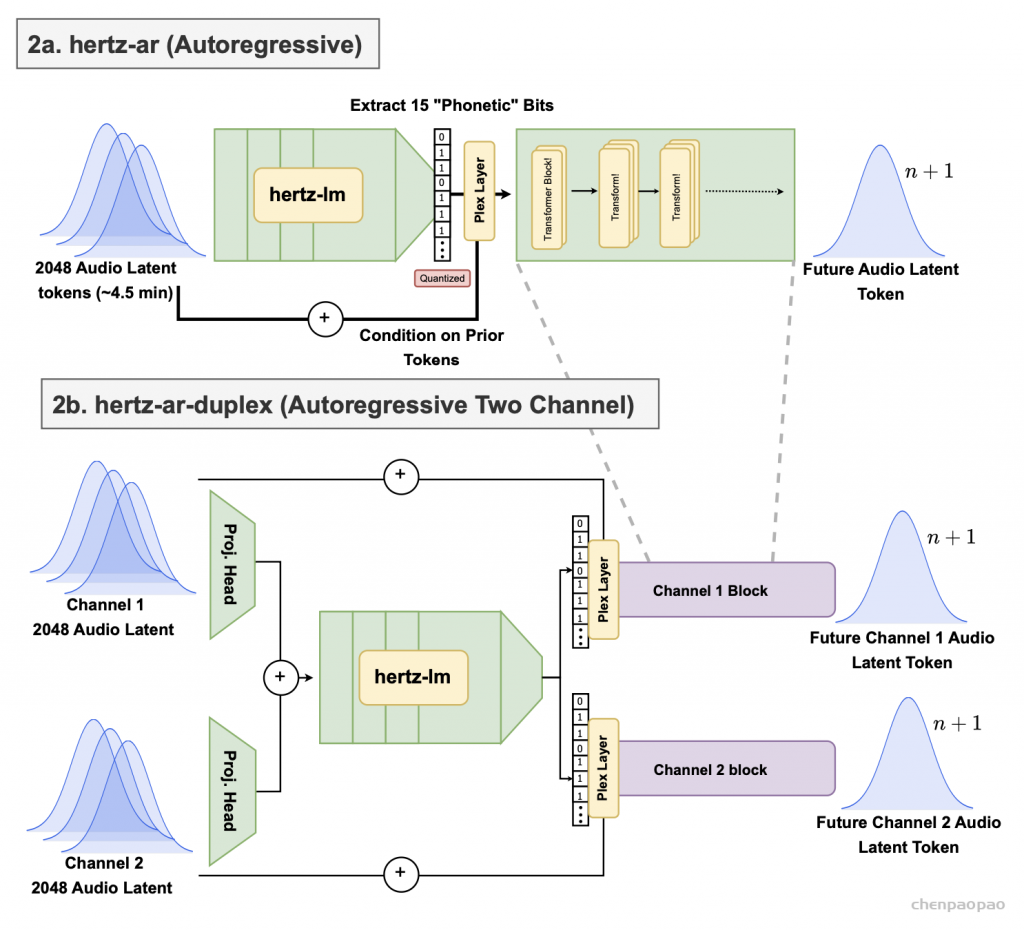
hertz-ar 架构图。(2a) 是单通道自回归潜在预测,(2b) 是双工自回归潜在预测。hertz-dev 由两部分组成 – 产生音频latents的 hertz-codec 和根据过去音频latents未来音频latents的 hertz-ar。音频latents是极其丰富的先验数据,可用于许多下游任务。
hertz-codec:卷积音频 VAE,采用单声道、16kHz 语音,并使用 KL 正则化的 1kbps 比特率编码 8Hz latents数据。我们利用因果卷积(功能上在序列左侧添加填充)来实现流式推理。
编解码器输出高斯参数(均值和方差),这些参数每 125ms 帧仅被采样为单层 32 维latent数据。在主观评估中,Hertz-codec 在 6kbps 时优于 Soundstream 和 Encodec,在 8kbps 时与 DAC 相当,同时每秒的标记数低于任何流行的标记器,这对于语言建模至关重要。 Hertz-codec 有 500 万个编码器参数和 9500 万个解码器参数。
inference_apatosaurus_95000.pt — 在混合重建、对抗和 KL 正则化损失上训练的 hertz-codec 权重。
inference_volcano_3.pt — hertz-codec 量化器,一种学习投影,可提取每个潜在语音中最相关的 15 位。
hertz-ar:40 层 84 亿参数解码器专用转换器,上下文为 2048 个输入token(约 4.5 分钟)。输出是可以传递到 hertz-codec 的latent数据。前 32 层接收潜在历史作为输入,并预测下一个latent音频token的 15 位量化投影。我们称之为 hertz-lm,因为它可以独立训练或从语言模型权重初始化。
最后 8 层网络利用潜在历史和 15 位量化latent来预测未来的潜在音频标记。
双工音频作为后训练任务处理,两个投影头连接在一起,然后分成两个量化投影管道,以各自的残差为条件。
inference_caraway_112000.pt — 从在 2T 标记上训练的语言模型初始化的hertz-lm 权重。
inference_syrup_110000.pt — 随机初始化的hertz-lm 权重,并完全在音频潜在上进行训练。
inference_whip_72000.pt — 最后 8 层的hertz-ar 权重
inference_care_50000.pt & inference_scion_54000.pt — hertz-ar 的双工检查点
Hertz-dev 是第一个公开发布的对话音频基础模型。基础模型可以准确预测训练数据的分布,而那些经过大量强化学习调优以压缩生成分布的模型则不同。这使得这些模型成为大量不同任务的下游微调的最佳起点。我们目前正在训练更大、更先进的 Hertz 版本,它将使用缩放的基础模型配方和强化学习调优来大幅提高模型的原始能力和最终一致性。Hertz-dev 是实时语音交互未来的一瞥,也是世界上最容易让研究人员进行微调和构建的对话音频模型。
训练选择
- 因果卷积网络:
在 hertz-codec 中使用了因果卷积网络进行并行解码,同时实现对潜在变量生成的更细粒度控制。 - 15位量化潜变量:
- 潜变量最初被训练用于包含语音的音素信息,从而帮助模型生成语法正确的语音。
- 量化过程通过一个多层感知机(MLP)投射到有限标量量化(Finite Scalar Quantization)层中完成。
- 初始化策略对比:
- 对 hertz-lm 测试了两种不同的初始化策略。
- 实验结果表明,模型配方在有或没有文本模型初始化的情况下,都能有效学习语言学特征。
性能表现
- 实时推理:
- 在实时推理中,模型需要每秒进行 8次前向传播,并持续执行自回归生成。
- 输入包含两个独立的信道,但在对话中仅返回其中一个信道的结果。
- 每一步操作中,模型接收用户的音频,将其标记为潜变量,并将其与模型上一步生成的潜变量结合,一起输入到 hertz-ar。
- 延迟:
- 延迟由以下部分组成:
- 用户语音和模型响应之间的平均时间(62.5毫秒),即从任何给定语音片段到一个标记生成完成的时间。
- 前向传播的计算时间。
- 网络往返的延迟。
- 在本地 RTX 4090 上运行时,实际测得的平均延迟为 120毫秒。
- 延迟由以下部分组成:
- 对比表现:
- 这种延迟是其他音频模型的 2倍低,极大地提升了实时交互的流畅性。
- 它能够以类似人类的方式进行互动,而不会让用户感受到像延迟、断续电话一样的不自然体验。
类似的端到端的音频模型:
2、mini-omni2
https://github.com/gpt-omni/mini-omni2…
3、GLM-4-Voice
https://github.com/THUDM/GLM-4-Voice…
4、moshi
5、Spiritlm