
- GitHub:https://github.com/ga642381/speech-trident/tree/master
- GitHub:https://github.com/dreamtheater123/Awesome-SpeechLM-Survey
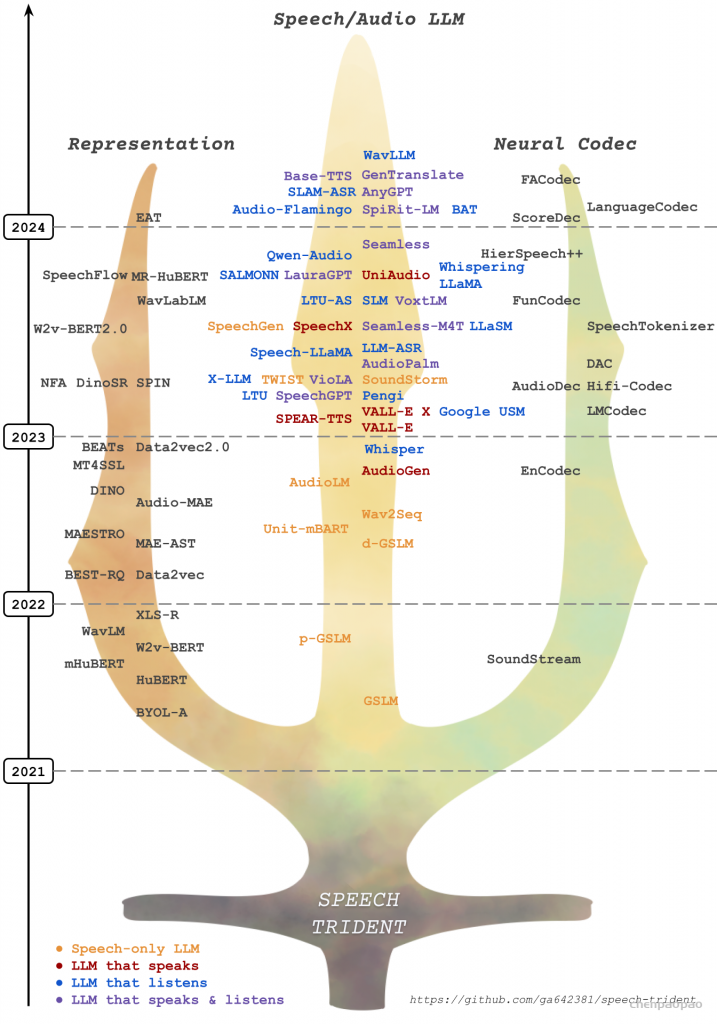
在这个代码库中,我们研究了以下三个关键领域:(1) 表征学习,(2) 神经编解码器,以及 (3) 语言模型,这些领域共同推动了语音/音频大语言模型的发展。
- ⚡ 语音表征模型:这些模型专注于学习语音的结构化表征,随后将其量化为离散的语音标记,通常被称为语义tokens。
- ⚡ 语音神经编解码模型:这些模型旨在学习语音和音频的离散标记,通常被称为声学tokens,同时保持良好的重构能力和低比特率。
- ⚡ 语音大语言模型:这些模型基于语音和声学token,采用语言建模方法进行训练,在语音理解和语音生成任务中展现出较高的能力。
内容
隐藏

Existing SpeechLMs
| Model | Title | Url |
|---|---|---|
| OpenAI Advanced Voice Mode | OpenAI Advanced Voice Mode | Link |
| Claude Voice Mode | Claude Voice Mode | Link |
| MindGPT-4o-Audio | 理想同学MindGPT-4o-Audio实时语音对话大模型发布 | Link |
| VITA-Audio | VITA-Audio: Fast Interleaved Cross-Modal Token Generation for Efficient Large Speech-Language Model | Link |
| Voila | Voila: Voice-Language Foundation Models for Real-Time Autonomous Interaction and Voice Role-Play | Link |
| Kimi-Audio | Kimi-Audio Technical Report | Link |
| Lyra | Lyra: An Efficient and Speech-Centric Framework for Omni-Cognition | Link |
| Flow-Omni | Continuous Speech Tokens Makes LLMs Robust Multi-Modality Learners | Link |
| NTPP | NTPP: Generative Speech Language Modeling for Dual-Channel Spoken Dialogue via Next-Token-Pair Prediction | Link |
| Qwen2.5-Omni | Qwen2.5-Omni Technical Report | Link |
| CSM | Conversational Speech Generation Model | Link |
| Minmo | MinMo: A Multimodal Large Language Model for Seamless Voice Interaction | Link |
| Slamming | Slamming: Training a Speech Language Model on One GPU in a Day | Link |
| VITA-1.5 | VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction | Link |
| Baichuan-Audio | Baichuan-Audio: A Unified Framework for End-to-End Speech Interaction | Link |
| Step-Audio | Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction | Link |
| MiniCPM-o | A GPT-4o Level MLLM for Vision, Speech and Multimodal Live Streaming on Your Phone | Link |
| SyncLLM | Beyond Turn-Based Interfaces: Synchronous LLMs as Full-Duplex Dialogue Agents | Link |
| OmniFlatten | OmniFlatten: An End-to-end GPT Model for Seamless Voice Conversation | Link |
| SLAM-Omni | SLAM-Omni: Timbre-Controllable Voice Interaction System with Single-Stage Training | Link |
| GLM-4-Voice | GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot | Link |
| – | Scaling Speech-Text Pre-training with Synthetic Interleaved Data | Link |
| SALMONN-omni | SALMONN-omni: A Codec-free LLM for Full-duplex Speech Understanding and Generation | Link |
| Mini-Omni2 | Mini-Omni2: Towards Open-source GPT-4o with Vision, Speech and Duplex Capabilities | Link |
| Uniaudio | Uniaudio: An audio foundation model toward universal audio generation | Link |
| Parrot | Parrot: Autoregressive Spoken Dialogue Language Modeling with Decoder-only Transformers | Link |
| Moshi | Moshi: a speech-text foundation model for real-time dialogue | Link |
| Freeze-Omni | Freeze-Omni: A Smart and Low Latency Speech-to-speech Dialogue Model with Frozen LLM | Link |
| EMOVA | EMOVA: Empowering Language Models to See, Hear and Speak with Vivid Emotions | Link |
| IntrinsicVoice | IntrinsicVoice: Empowering LLMs with Intrinsic Real-time Voice Interaction Abilities | Link |
| LSLM | Language Model Can Listen While Speaking | Link |
| SpiRit-LM | SpiRit-LM: Interleaved Spoken and Written Language Model | Link |
| SpeechGPT-Gen | SpeechGPT-Gen: Scaling Chain-of-Information Speech Generation | Link |
| Spectron | Spoken Question Answering and Speech Continuation Using Spectrogram-Powered LLM | Link |
| SUTLM | Toward Joint Language Modeling for Speech Units and Text | Link |
| tGSLM | Generative Spoken Language Model based on continuous word-sized audio tokens | Link |
| LauraGPT | LauraGPT: Listen, Attend, Understand, and Regenerate Audio with GPT | Link |
| VoxtLM | VoxtLM: Unified Decoder-Only Models for Consolidating Speech Recognition, Synthesis and Speech, Text Continuation Tasks | Link |
| VITA | VITA: Towards Open-Source Interactive Omni Multimodal LLM | Link |
| FunAudioLLM | FunAudioLLM: Voice Understanding and Generation Foundation Models for Natural Interaction Between Humans and LLMs | Link |
| Voicebox | Voicebox: Text-guided multilingual universal speech generation at scale | Link |
| LLaMA-Omni | LLaMA-Omni: Seamless Speech Interaction with Large Language Models | Link |
| Mini-Omni | Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming | Link |
| TWIST | Textually pretrained speech language models | Link |
| GPST | Generative pre-trained speech language model with efficient hierarchical transformer | Link |
| AudioPaLM | AudioPaLM: A Large Language Model That Can Speak and Listen | Link |
| VioLA | VioLA: Unified Codec Language Models for Speech Recognition, Synthesis, and Translation | Link |
| SpeechGPT | Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities | Link |
| dGSLM | Generative spoken dialogue language modeling | Link |
| pGSLM | Text-Free Prosody-Aware Generative Spoken Language Modeling | Link |
| GSLM | On generative spoken language modeling from raw audio | Link |
SpeechLM Tokenizers
Semantic Tokenizers
| Name | Title | Url |
|---|---|---|
| Whisper | Robust Speech Recognition via Large-Scale Weak Supervision | Link |
| CosyVoice | CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer based on Supervised Semantic Tokens | Link |
| Google USM | Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages | Link |
| WavLM | WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing | Link |
| HuBERT | HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units | Link |
| W2v-bert | W2v-BERT: Combining Contrastive Learning and Masked Language Modeling for Self-Supervised Speech Pre-Training | Link |
| Wav2vec 2.0 | wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations | Link |
Acoustic Tokenizers
| Name | Title | Url |
|---|---|---|
| WavTokenizer | WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling | Link |
| SNAC | SNAC: Multi-Scale Neural Audio Codec | Link |
| Encodec | High Fidelity Neural Audio Compression | Link |
| SoundStream | SoundStream: An End-to-End Neural Audio Codec | Link |
Mixed Tokenizers
| Name | Title | Url |
|---|---|---|
| SpeechTokenizer | SpeechTokenizer: Unified Speech Tokenizer for Speech Large Language Models | Link |
| Mimi | Moshi: a speech-text foundation model for real-time dialogue | Link |
Popular Training Datasets
| Dataset | Type | Phase | Hours | Year |
|---|---|---|---|---|
| LibriSpeech | ASR | Pre-Training | 1k | 2015 |
| Multilingual LibriSpeech | ASR | Pre-Training | 50.5k | 2020 |
| LibriLight | ASR | Pre-Training | 60k | 2019 |
| People dataset | ASR | Pre-Training | 30k | 2021 |
| VoxPopuli | ASR | Pre-Training | 1.6k | 2021 |
| Gigaspeech | ASR | Pre-Training | 40k | 2021 |
| Common Voice | ASR | Pre-Training | 2.5k | 2019 |
| VCTK | ASR | Pre-Training | 0.3k | 2017 |
| WenetSpeech | ASR | Pre-Training | 22k | 2022 |
| LibriTTS | TTS | Pre-Training | 0.6k | 2019 |
| CoVoST2 | S2TT | Pre-Training | 2.8k | 2020 |
| CVSS | S2ST | Pre-Training | 1.9k | 2022 |
| VoxCeleb | Speaker Identification | Pre-Training | 0.4k | 2017 |
| VoxCeleb2 | Speaker Identification | Pre-Training | 2.4k | 2018 |
| Spotify Podcasts | Podcast | Pre-Training | 47k | 2020 |
| Fisher | Telephone conversation | Pre-Training | 2k | 2004 |
| SpeechInstruct | Instruction-following | Instruction-Tuning | – | 2023 |
| InstructS2S-200K | Instruction-following | Instruction-Tuning | – | 2024 |
| VoiceAssistant-400K | Instruction-following | Instruction-Tuning | – | 2024 |
Evaluation Benchmarks
| Name | Eval Type | # Tasks | Audio Type | I/O |
|---|---|---|---|---|
| ABX | Representation | 1 | Speech | A→− |
| sWUGGY | Linguistic | 1 | Speech | A→− |
| sBLIMP | Linguistic | 1 | Speech | A→− |
| sStoryCloze | Linguistic | 1 | Speech | A/T→− |
| STSP | Paralinguistic | 1 | Speech | A/T→A/T |
| MMAU | Downstream | 27 | Speech, Sound, Music | A→T |
| Audiobench | Downstream | 8 | Speech, Sound | A→T |
| AIR-Bench | Downstream | 20 | Speech, Sound, Music | A→T |
| SD-Eval | Downstream | 4 | Speech | A→T |
| SUPERB | Downstream | 10 | Speech | A→T |
| Dynamic-SUPERB | Downstream | 180 | Speech, Sound, Music | A→T |
| SALMON | Downstream | 8 | Speech | A→− |
| VoiceBench | Downstream | 8 | Speech | A→A |
| VoxEval | Downstream | 56 | Speech | A→A |
🔱 Speech/Audio Language Models
| Date | Model Name | Paper Title | Link |
|---|---|---|---|
| 2024-11 | — | Building a Taiwanese Mandarin Spoken Language Model: A First Attempt | Paper |
| 2024-11 | Ultravox | Ultravox: An open-weight alternative to GPT-4o Realtime | Blog |
| 2024-11 | hertz-dev | blog | GitHub |
| 2024-11 | Freeze-Omni | Freeze-Omni: A Smart and Low Latency Speech-to-speech Dialogue Model with Frozen LLM | paper |
| 2024-11 | Align-SLM | Align-SLM: Textless Spoken Language Models with Reinforcement Learning from AI Feedback | paper |
| 2024-10 | Ichigo | Ichigo: Mixed-Modal Early-Fusion Realtime Voice Assistant | paper, code |
| 2024-10 | OmniFlatten | OmniFlatten: An End-to-end GPT Model for Seamless Voice Conversation | paper |
| 2024-10 | GPT-4o | GPT-4o System Card | paper |
| 2024-10 | Baichuan-OMNI | Baichuan-Omni Technical Report | paper |
| 2024-10 | GLM-4-Voice | GLM-4-Voice | GitHub |
| 2024-10 | — | Roadmap towards Superhuman Speech Understanding using Large Language Models | paper |
| 2024-10 | SALMONN-OMNI | SALMONN-OMNI: A SPEECH UNDERSTANDING AND GENERATION LLM IN A CODEC-FREE FULL-DUPLEX FRAMEWORK | paper |
| 2024-10 | Mini-Omni 2 | Mini-Omni2: Towards Open-source GPT-4o with Vision, Speech and Duplex Capabilities | paper |
| 2024-10 | HALL-E | HALL-E: Hierarchical Neural Codec Language Model for Minute-Long Zero-Shot Text-to-Speech Synthesis | paper |
| 2024-10 | SyllableLM | SyllableLM: Learning Coarse Semantic Units for Speech Language Models | paper |
| 2024-09 | Moshi | Moshi: a speech-text foundation model for real-time dialogue | paper |
| 2024-09 | Takin AudioLLM | Takin: A Cohort of Superior Quality Zero-shot Speech Generation Models | paper |
| 2024-09 | FireRedTTS | FireRedTTS: A Foundation Text-To-Speech Framework for Industry-Level Generative Speech Applications | paper |
| 2024-09 | LLaMA-Omni | LLaMA-Omni: Seamless Speech Interaction with Large Language Models | paper |
| 2024-09 | MaskGCT | MaskGCT: Zero-Shot Text-to-Speech with Masked Generative Codec Transformer | paper |
| 2024-09 | SSR-Speech | SSR-Speech: Towards Stable, Safe and Robust Zero-shot Text-based Speech Editing and Synthesis | paper |
| 2024-09 | MoWE-Audio | MoWE-Audio: Multitask AudioLLMs with Mixture of Weak Encoders | paper |
| 2024-08 | Mini-Omni | Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming | paper |
| 2024-08 | Make-A-Voice 2 | Make-A-Voice: Revisiting Voice Large Language Models as Scalable Multilingual and Multitask Learner | paper |
| 2024-08 | LSLM | Language Model Can Listen While Speaking | paper |
| 2024-06 | SimpleSpeech | SimpleSpeech: Towards Simple and Efficient Text-to-Speech with Scalar Latent Transformer Diffusion Models | paper |
| 2024-06 | UniAudio 1.5 | UniAudio 1.5: Large Language Model-driven Audio Codec is A Few-shot Audio Task Learner | paper |
| 2024-06 | VALL-E R | VALL-E R: Robust and Efficient Zero-Shot Text-to-Speech Synthesis via Monotonic Alignment | paper |
| 2024-06 | VALL-E 2 | VALL-E 2: Neural Codec Language Models are Human Parity Zero-Shot Text to Speech Synthesizers | paper |
| 2024-06 | GPST | Generative Pre-trained Speech Language Model with Efficient Hierarchical Transformer | paper |
| 2024-04 | CLaM-TTS | CLaM-TTS: Improving Neural Codec Language Model for Zero-Shot Text-to-Speech | paper |
| 2024-04 | RALL-E | RALL-E: Robust Codec Language Modeling with Chain-of-Thought Prompting for Text-to-Speech Synthesis | paper |
| 2024-04 | WavLLM | WavLLM: Towards Robust and Adaptive Speech Large Language Model | paper |
| 2024-02 | MobileSpeech | MobileSpeech: A Fast and High-Fidelity Framework for Mobile Zero-Shot Text-to-Speech | paper |
| 2024-02 | SLAM-ASR | An Embarrassingly Simple Approach for LLM with Strong ASR Capacity | paper |
| 2024-02 | AnyGPT | AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling | paper |
| 2024-02 | SpiRit-LM | SpiRit-LM: Interleaved Spoken and Written Language Model | paper |
| 2024-02 | USDM | Integrating Paralinguistics in Speech-Empowered Large Language Models for Natural Conversation | paper |
| 2024-02 | BAT | BAT: Learning to Reason about Spatial Sounds with Large Language Models | paper |
| 2024-02 | Audio Flamingo | Audio Flamingo: A Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities | paper |
| 2024-02 | Text Description to speech | Natural language guidance of high-fidelity text-to-speech with synthetic annotations | paper |
| 2024-02 | GenTranslate | GenTranslate: Large Language Models are Generative Multilingual Speech and Machine Translators | paper |
| 2024-02 | Base-TTS | BASE TTS: Lessons from building a billion-parameter Text-to-Speech model on 100K hours of data | paper |
| 2024-02 | — | It’s Never Too Late: Fusing Acoustic Information into Large Language Models for Automatic Speech Recognition | paper |
| 2024-01 | — | Large Language Models are Efficient Learners of Noise-Robust Speech Recognition | paper |
| 2024-01 | ELLA-V | ELLA-V: Stable Neural Codec Language Modeling with Alignment-guided Sequence Reordering | paper |
| 2023-12 | Seamless | Seamless: Multilingual Expressive and Streaming Speech Translation | paper |
| 2023-11 | Qwen-Audio | Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models | paper |
| 2023-10 | LauraGPT | LauraGPT: Listen, Attend, Understand, and Regenerate Audio with GPT | paper |
| 2023-10 | SALMONN | SALMONN: Towards Generic Hearing Abilities for Large Language Models | paper |
| 2023-10 | UniAudio | UniAudio: An Audio Foundation Model Toward Universal Audio Generation | paper |
| 2023-10 | Whispering LLaMA | Whispering LLaMA: A Cross-Modal Generative Error Correction Framework for Speech Recognition | paper |
| 2023-09 | VoxtLM | Voxtlm: unified decoder-only models for consolidating speech recognition/synthesis and speech/text continuation tasks | paper |
| 2023-09 | LTU-AS | Joint Audio and Speech Understanding | paper |
| 2023-09 | SLM | SLM: Bridge the thin gap between speech and text foundation models | paper |
| 2023-09 | — | Generative Speech Recognition Error Correction with Large Language Models and Task-Activating Prompting | paper |
| 2023-08 | SpeechGen | SpeechGen: Unlocking the Generative Power of Speech Language Models with Prompts | paper |
| 2023-08 | SpeechX | SpeechX: Neural Codec Language Model as a Versatile Speech Transformer | paper |
| 2023-08 | LLaSM | Large Language and Speech Model | paper |
| 2023-08 | SeamlessM4T | Massively Multilingual & Multimodal Machine Translation | paper |
| 2023-07 | Speech-LLaMA | On decoder-only architecture for speech-to-text and large language model integration | paper |
| 2023-07 | LLM-ASR(temp.) | Prompting Large Language Models with Speech Recognition Abilities | paper |
| 2023-06 | AudioPaLM | AudioPaLM: A Large Language Model That Can Speak and Listen | paper |
| 2023-05 | Make-A-Voice | Make-A-Voice: Unified Voice Synthesis With Discrete Representation | paper |
| 2023-05 | Spectron | Spoken Question Answering and Speech Continuation Using Spectrogram-Powered LLM | paper |
| 2023-05 | TWIST | Textually Pretrained Speech Language Models | paper |
| 2023-05 | Pengi | Pengi: An Audio Language Model for Audio Tasks | paper |
| 2023-05 | SoundStorm | Efficient Parallel Audio Generation | paper |
| 2023-05 | LTU | Joint Audio and Speech Understanding | paper |
| 2023-05 | SpeechGPT | Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities | paper |
| 2023-05 | VioLA | Unified Codec Language Models for Speech Recognition, Synthesis, and Translation | paper |
| 2023-05 | X-LLM | X-LLM: Bootstrapping Advanced Large Language Models by Treating Multi-Modalities as Foreign Languages | paper |
| 2023-03 | Google USM | Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages | paper |
| 2023-03 | VALL-E X | Speak Foreign Languages with Your Own Voice: Cross-Lingual Neural Codec Language Modeling | paper |
| 2023-02 | SPEAR-TTS | Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision | paper |
| 2023-01 | VALL-E | Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers | paper |
| 2022-12 | Whisper | Robust Speech Recognition via Large-Scale Weak Supervision | paper |
| 2022-10 | AudioGen | AudioGen: Textually Guided Audio Generation | paper |
| 2022-09 | AudioLM | AudioLM: a Language Modeling Approach to Audio Generation | paper |
| 2022-05 | Wav2Seq | Wav2Seq: Pre-training Speech-to-Text Encoder-Decoder Models Using Pseudo Languages | paper |
| 2022-04 | Unit mBART | Enhanced Direct Speech-to-Speech Translation Using Self-supervised Pre-training and Data Augmentation | paper |
| 2022-03 | d-GSLM | Generative Spoken Dialogue Language Modeling | paper |
| 2021-10 | SLAM | SLAM: A Unified Encoder for Speech and Language Modeling via Speech-Text Joint Pre-Training | paper |
| 2021-09 | p-GSLM | Text-Free Prosody-Aware Generative Spoken Language Modeling | paper |
| 2021-02 | GSLM | Generative Spoken Language Modeling from Raw Audio | paper |
🔱 Speech/Audio Codec Models
| Date | Model Name | Paper Title | Link |
|---|---|---|---|
| 2024-11 | PyramidCodec | PyramidCodec: Hierarchical Codec for Long-form Music Generation in Audio Domain | paper |
| 2024-11 | UniCodec | Universal Speech Token Learning Via Low-Bitrate Neural Codec and Pretrained Representations | paper |
| 2024-11 | SimVQ | Addressing Representation Collapse in Vector Quantized Models with One Linear Layer | paper |
| 2024-11 | MDCTCodec | MDCTCodec: A Lightweight MDCT-based Neural Audio Codec towards High Sampling Rate and Low Bitrate Scenarios | paper |
| 2024-10 | APCodec+ | APCodec+: A Spectrum-Coding-Based High-Fidelity and High-Compression-Rate Neural Audio Codec with Staged Training Paradigm | paper |
| 2024-10 | – | A Closer Look at Neural Codec Resynthesis: Bridging the Gap between Codec and Waveform Generation | paper |
| 2024-10 | SNAC | SNAC: Multi-Scale Neural Audio Codec | paper |
| 2024-10 | LSCodec | LSCodec: Low-Bitrate and Speaker-Decoupled Discrete Speech Codec | paper |
| 2024-10 | Co-design for codec and codec-LM | TOWARDS CODEC-LM CO-DESIGN FOR NEURAL CODEC LANGUAGE MODELS | paper |
| 2024-10 | VChangeCodec | VChangeCodec: A High-efficiency Neural Speech Codec with Built-in Voice Changer for Real-time Communication | paper |
| 2024-10 | DC-Spin | DC-Spin: A Speaker-invariant Speech Tokenizer For Spoken Language Models | paper |
| 2024-10 | TAAE | Scaling Transformers for Low-Bitrate High-Quality Speech Coding | paper |
| 2024-10 | DM-Codec | DM-Codec: Distilling Multimodal Representations for Speech Tokenization | paper |
| 2024-09 | Mimi | Moshi: a speech-text foundation model for real-time dialogue | paper |
| 2024-09 | NDVQ | NDVQ: Robust Neural Audio Codec with Normal Distribution-Based Vector Quantization | paper |
| 2024-09 | SoCodec | SoCodec: A Semantic-Ordered Multi-Stream Speech Codec for Efficient Language Model Based Text-to-Speech Synthesis | paper |
| 2024-09 | BigCodec | BigCodec: Pushing the Limits of Low-Bitrate Neural Speech Codec | paper |
| 2024-08 | X-Codec | Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model | paper |
| 2024-08 | WavTokenizer | WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling | paper |
| 2024-07 | Super-Codec | SuperCodec: A Neural Speech Codec with Selective Back-Projection Network | paper |
| 2024-07 | dMel | dMel: Speech Tokenization made Simple | paper |
| 2024-06 | CodecFake | CodecFake: Enhancing Anti-Spoofing Models Against Deepfake Audios from Codec-Based Speech Synthesis Systems | paper |
| 2024-06 | Single-Codec | Single-Codec: Single-Codebook Speech Codec towards High-Performance Speech Generation | paper |
| 2024-06 | SQ-Codec | SimpleSpeech: Towards Simple and Efficient Text-to-Speech with Scalar Latent Transformer Diffusion Models | paper |
| 2024-06 | PQ-VAE | Addressing Index Collapse of Large-Codebook Speech Tokenizer with Dual-Decoding Product-Quantized Variational Auto-Encoder | paper |
| 2024-06 | LLM-Codec | UniAudio 1.5: Large Language Model-driven Audio Codec is A Few-shot Audio Task Learner | paper |
| 2024-05 | HILCodec | HILCodec: High Fidelity and Lightweight Neural Audio Codec | paper |
| 2024-04 | SemantiCodec | SemantiCodec: An Ultra Low Bitrate Semantic Audio Codec for General Sound | paper |
| 2024-04 | PromptCodec | PromptCodec: High-Fidelity Neural Speech Codec using Disentangled Representation Learning based Adaptive Feature-aware Prompt Encoders | paper |
| 2024-04 | ESC | ESC: Efficient Speech Coding with Cross-Scale Residual Vector Quantized Transformers | paper |
| 2024-03 | FACodec | NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models | paper |
| 2024-02 | AP-Codec | APCodec: A Neural Audio Codec with Parallel Amplitude and Phase Spectrum Encoding and Decoding | paper |
| 2024-02 | Language-Codec | Language-Codec: Reducing the Gaps Between Discrete Codec Representation and Speech Language Models | paper |
| 2024-01 | ScoreDec | ScoreDec: A Phase-preserving High-Fidelity Audio Codec with A Generalized Score-based Diffusion Post-filter | paper |
| 2023-11 | HierSpeech++ | HierSpeech++: Bridging the Gap between Semantic and Acoustic Representation of Speech by Hierarchical Variational Inference for Zero-shot Speech Synthesis | paper |
| 2023-10 | TiCodec | FEWER-TOKEN NEURAL SPEECH CODEC WITH TIME-INVARIANT CODES | paper |
| 2023-09 | RepCodec | RepCodec: A Speech Representation Codec for Speech Tokenization | paper |
| 2023-09 | FunCodec | FunCodec: A Fundamental, Reproducible and Integrable Open-source Toolkit for Neural Speech Codec | paper |
| 2023-08 | SpeechTokenizer | Speechtokenizer: Unified speech tokenizer for speech large language models | paper |
| 2023-06 | VOCOS | VOCOS: CLOSING THE GAP BETWEEN TIME-DOMAIN AND FOURIER-BASED NEURAL VOCODERS FOR HIGH-QUALITY AUDIO SYNTHESIS | paper |
| 2023-06 | Descript-audio-codec | High-Fidelity Audio Compression with Improved RVQGAN | paper |
| 2023-05 | AudioDec | Audiodec: An open-source streaming highfidelity neural audio codec | paper |
| 2023-05 | HiFi-Codec | Hifi-codec: Group-residual vector quantization for high fidelity audio codec | paper |
| 2023-03 | LMCodec | LMCodec: A Low Bitrate Speech Codec With Causal Transformer Models | paper |
| 2022-11 | Disen-TF-Codec | Disentangled Feature Learning for Real-Time Neural Speech Coding | paper |
| 2022-10 | EnCodec | High fidelity neural audio compression | paper |
| 2022-07 | S-TFNet | Cross-Scale Vector Quantization for Scalable Neural Speech Coding | paper |
| 2022-01 | TFNet | End-to-End Neural Speech Coding for Real-Time Communications | paper |
| 2021-07 | SoundStream | SoundStream: An End-to-End Neural Audio Codec | paper |
Speech/Audio Representation Models
| Date | Model Name | Paper Title | Link |
|---|---|---|---|
| 2024-09 | NEST-RQ | NEST-RQ: Next Token Prediction for Speech Self-Supervised Pre-Training | paper |
| 2024-01 | EAT | Self-Supervised Pre-Training with Efficient Audio Transformer | paper |
| 2023-10 | MR-HuBERT | Multi-resolution HuBERT: Multi-resolution Speech Self-Supervised Learning with Masked Unit Prediction | paper |
| 2023-10 | SpeechFlow | Generative Pre-training for Speech with Flow Matching | paper |
| 2023-09 | WavLabLM | Joint Prediction and Denoising for Large-scale Multilingual Self-supervised Learning | paper |
| 2023-08 | W2v-BERT 2.0 | Massively Multilingual & Multimodal Machine Translation | paper |
| 2023-07 | Whisper-AT | Noise-Robust Automatic Speech Recognizers are Also Strong General Audio Event Taggers | paper |
| 2023-06 | ATST | Self-supervised Audio Teacher-Student Transformer for Both Clip-level and Frame-level Tasks | paper |
| 2023-05 | SPIN | Self-supervised Fine-tuning for Improved Content Representations by Speaker-invariant Clustering | paper |
| 2023-05 | DinoSR | Self-Distillation and Online Clustering for Self-supervised Speech Representation Learning | paper |
| 2023-05 | NFA | Self-supervised neural factor analysis for disentangling utterance-level speech representations | paper |
| 2022-12 | Data2vec 2.0 | Efficient Self-supervised Learning with Contextualized Target Representations for Vision, Speech and Language | paper |
| 2022-12 | BEATs | Audio Pre-Training with Acoustic Tokenizers | paper |
| 2022-11 | MT4SSL | MT4SSL: Boosting Self-Supervised Speech Representation Learning by Integrating Multiple Targets | paper |
| 2022-08 | DINO | Non-contrastive self-supervised learning of utterance-level speech representations | paper |
| 2022-07 | Audio-MAE | Masked Autoencoders that Listen | paper |
| 2022-04 | MAESTRO | Matched Speech Text Representations through Modality Matching | paper |
| 2022-03 | MAE-AST | Masked Autoencoding Audio Spectrogram Transformer | paper |
| 2022-03 | LightHuBERT | Lightweight and Configurable Speech Representation Learning with Once-for-All Hidden-Unit BERT | paper |
| 2022-02 | Data2vec | A General Framework for Self-supervised Learning in Speech, Vision and Language | paper |
| 2021-10 | WavLM | WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing | paper |
| 2021-08 | W2v-BERT | Combining Contrastive Learning and Masked Language Modeling for Self-Supervised Speech Pre-Training | paper |
| 2021-07 | mHuBERT | Direct speech-to-speech translation with discrete units | paper |
| 2021-06 | HuBERT | Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units | paper |
| 2021-03 | BYOL-A | Self-Supervised Learning for General-Purpose Audio Representation | paper |
| 2020-12 | DeCoAR2.0 | DeCoAR 2.0: Deep Contextualized Acoustic Representations with Vector Quantization | paper |
| 2020-07 | TERA | TERA: Self-Supervised Learning of Transformer Encoder Representation for Speech | paper |
| 2020-06 | Wav2vec2.0 | wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations | paper |
| 2019-10 | APC | Generative Pre-Training for Speech with Autoregressive Predictive Coding | paper |
| 2018-07 | CPC | Representation Learning with Contrastive Predictive Coding | paper |
🔱 Related Repository
- https://github.com/liusongxiang/Large-Audio-Models
- https://github.com/kuan2jiu99/Awesome-Speech-Generation
- https://github.com/ga642381/Speech-Prompts-Adapters
- https://github.com/voidful/Codec-SUPERB
- https://github.com/huckiyang/awesome-neural-reprogramming-prompting
- https://github.com/dreamtheater123/Awesome-SpeechLM-Survey