
因果卷积:
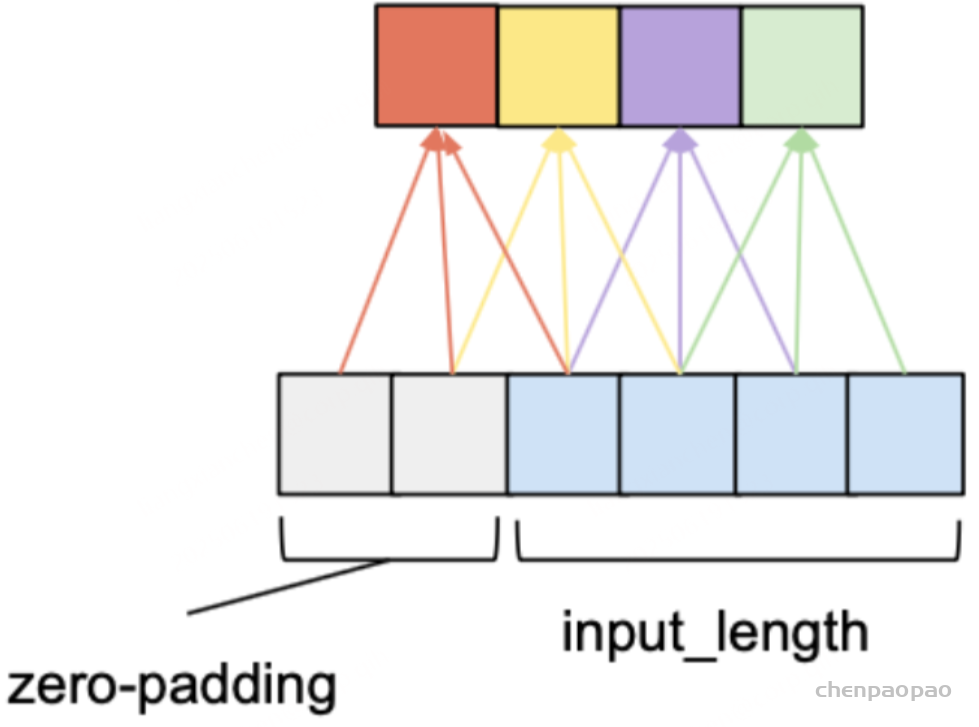
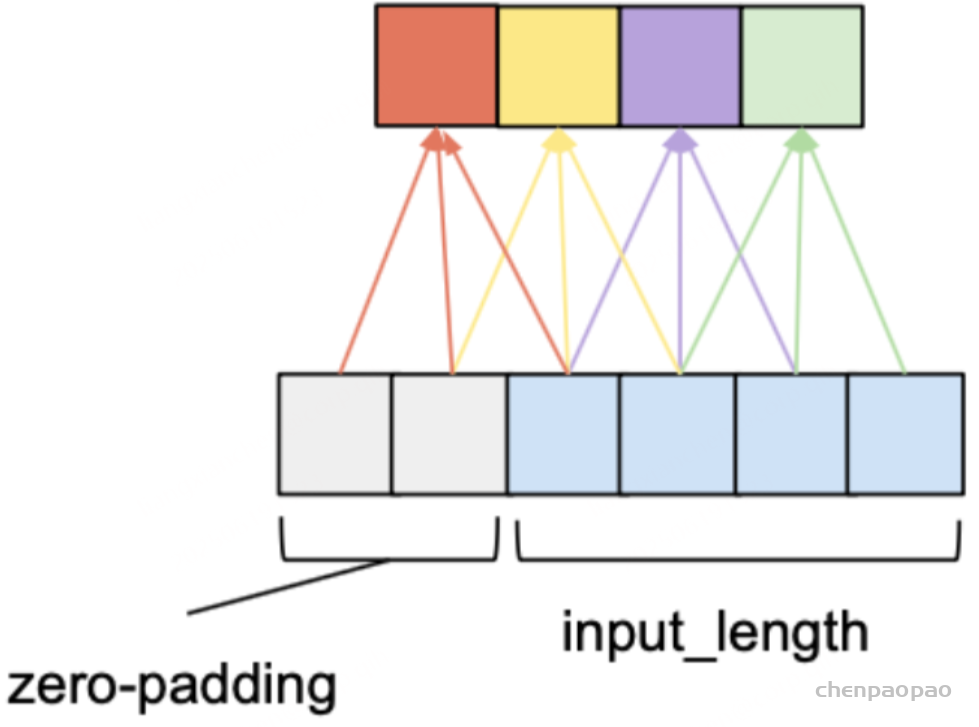
因果卷积可以用上图直观表示。即对于上一层t时刻的值,只依赖于下一层t时刻及其之前的值。和传统的卷积神经网络的不同之处在于,因果卷积不能看到未来的数据,它是单向的结构,不是双向的。也就是说只有有了前面的因才有后面的果,是一种严格的时间约束模型,因此被成为因果卷积。
上面的图片可以详细的解释因果卷积,但是问题就来,如果我要考虑很久之前的变量x,那么卷积层数就必须增加(自行体会)。。。卷积层数的增加就带来:梯度消失,训练复杂,拟合效果不好的问题,为了决绝这个问题,出现了扩展卷积(dilated)
(1) 流式推理中的卷积要求
- 无未来信息依赖:卷积核只能访问当前及之前的输入,不允许访问未来输入。
- 因果卷积(Causal Convolution):通过调整卷积核的 Padding,使卷积操作仅依赖历史时间步的数据。
(2) Padding 设计
- 普通卷积的 Padding:在非流式模型中,通常使用
SAMEPadding(如 TensorFlow 或 PyTorch 的对称填充),填充方式使得输入和输出长度一致。这会导致卷积核访问未来时间步数据,无法实现流式推理。 - 因果卷积的 Padding:
- 对卷积核进行不对称填充(如只在输入前侧填充),使得卷积操作仅依赖于当前及之前的时间步。
- 具体填充量 = 卷积核大小 – 1,例如 3×1 卷积核的填充量是 2。
import torch
import torch.nn as nn
from torch.autograd import Variable
__CUDA__ = torch.cuda.is_available()
class CausalConv1d(nn.Module):
"""
A causal 1D convolution.
"""
def __init__(self, kernel_size, in_channels, out_channels, dilation):
super(CausalConv1d, self).__init__(self)
# attributes:
self.kernel_size = kernel_size
self.in_channels = in_channels
self.dilation = dilation
# modules:
self.conv1d = torch.nn.Conv1d(in_channels, out_channels,
kernel_size, stride=1,
padding=padding = (kernel_size-1) * dilation,
dilation=dilation)
def forward(self, seq):
"""
Note that Conv1d expects (batch, in_channels, in_length).
We assume that seq ~ (len(seq), batch, in_channels), so we'll reshape it first.
"""
seq_ = seq.permute(1,2,0)
conv1d_out = self.conv1d(seq_).permute(2,0,1)
# remove k-1 values from the end:
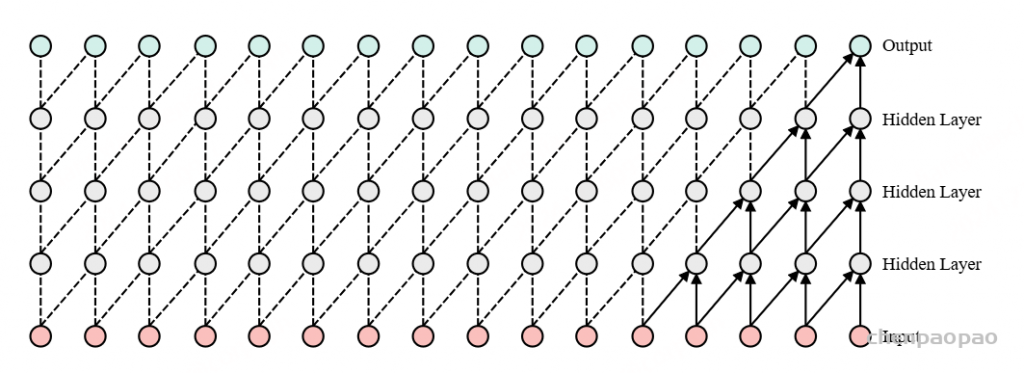
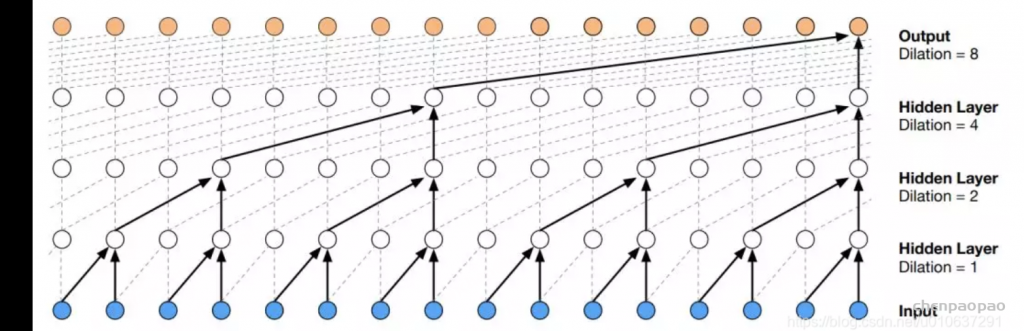
return conv1d_out[0:-(self.kernel_size-1)]扩展因果卷积:【空洞因果卷积 Dilated causal Conv】
对于因果卷积,存在的一个问题是需要很多层或者很大的filter来增加卷积的感受野。扩大卷积(dilated convolution)是通过跳过部分输入来使filter可以应用于大于filter本身长度的区域。等同于通过增加零来从原始filter中生成更大的filter。
dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。在图像需要全局信息或者语音文本需要较长的sequence信息依赖的问题中,都能很好的应用dilated conv,比如图像分割、语音合成WaveNet、机器翻译ByteNet中.
Normalization 层的选择与调整
Normalization 是流式推理中另一个关键挑战。普通的批归一化(Batch Normalization, BN)需要计算全局统计量(如均值和方差),这在流式推理中是不可能实现的。
(1) Batch Normalization 的问题
- 需要整个批次的数据来计算统计量,无法在单步流式推理中实现。
- 通常在训练阶段使用
batch statistics,在推理阶段使用running statistics。
(2) 解决方法
Layer Normalization (LN):
- 不依赖于批次,而是对每个样本的特征维度进行归一化,非常适合流式推理。
Instance Normalization (IN):
- 类似于 Layer Normalization,但操作在每个样本的空间维度上进行归一化。
Group Normalization (GN):
- 介于 Batch 和 Layer Normalization 之间,将特征划分为组,并在组内进行归一化。
Online Normalization(自回归统计):
- 通过滑动窗口或指数移动平均(EMA)计算局部统计量,仅依赖过去的信息。
- 这种方法特别适合流式推理,但实现较为复杂。
实践中的流式推理设置
结合以上两点,具体实现流式模型时需要注意以下步骤:
- 卷积层:
- 替换普通卷积为因果卷积。
- 如果使用扩张卷积(Dilated Convolution),需要保证所有层的 Padding 符合因果逻辑。
- 归一化层:
- 替换
BatchNorm为LayerNorm。 - 在需要时,引入自回归统计机制。
- 替换
- 框架支持:
- 确保模型在流式输入中可以逐步更新输入窗口(如时间序列切片)。