
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
[Paper] [Code] [Studio] [HuggingFace] [ModelScope]
CosyVoice是阿里巴巴通义实验室语音团队于今年7月份开源的语音生成大模型,依托大模型技术,实现自然流畅的语音生成体验。与传统语音生成技术相比,CosyVoice具有韵律自然、音色逼真等特点。自开源以来,CosyVoice凭借高品质的多语言语音生成、零样本语音生成、跨语言语音生成、富文本和自然语言的细粒度控制能力获得了广大社区开发者们的喜爱和支持。
CosyVoice迎来全面升级2.0版本,提供更准、更稳、更快、 更好的语音生成能力。
超低延迟:CosyVoice 2.0提出了离线和流式一体化建模的语音生成大模型技术,支持双向流式语音合成,在基本不损失效果的情况下首包合成延迟可以达到150ms。
高准确度:CosyVoice 2.0合成音频的发音错误相比于CosyVoice 1.0相对下降30%~50%,在Seed-TTS测试集的hard测试集上取得当前最低的字错误率。合成绕口令、多音字、生僻字上具有明显的提升。
强稳定性:CosyVoice 2.0在零样本语音生成和跨语言语音合成上能够出色地保证音色一致性,特别是跨语言语音合成相比于1.0版本具有明显提升。
自然体验:CosyVoice 2.0合成音频的韵律、音质、情感匹配相比于1.0具有明显提升。MOS评测分从5.4提升到5.53(相同评测某商业化语音合成大模型为5.52)。同时, CosyVoice 2.0对于指令可控的音频生成也进行了升级,支持更多细粒度的情感控制,以及方言口音控制。
▎核心模型与算法亮点
CosyVoice 2.0采用和CosyVoice 1一致的LLM+FM的建模框架,但是在具体实现上进行了如下几个要点的算法优化:
1)LLM backbone:CosyVoice 2.0采用预训练好的文本基座大模型(Qwen2.5-0.5B)替换了原来的Text Encoder + random Transformer的结构。采用LLM进行初始化能够更好的进行文本的语义建模,使得在可控生成,音频和文本的情感匹配,多音字发音上会有明显的收益。
2)FSQ Speech Tokenizer:CosyVoice 1.0采用VQ来提取Supervised semantic codec,码本大小为4096,但是有效码本只有963。CosyVoice 2.0采用了FSQ替换VQ,训练了6561的码本,并且码本100%激活。FSQ-Speech Tokenizer的使用使得CosyVoice 2.0在发音准确性上有明显提升。
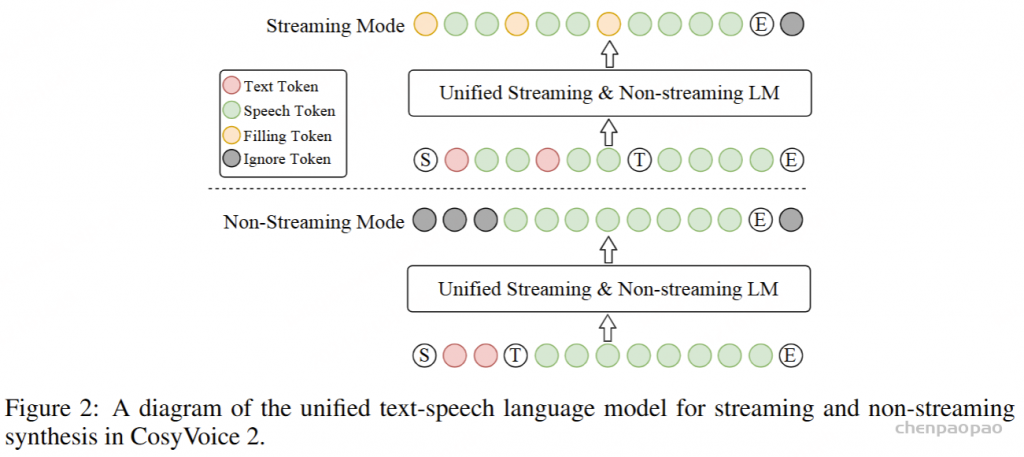
3)离线和流式一体化建模方案:目前主流的语音生成大模型(CosyVoice, F5-TTS,MaskGCT,GPT-SoViTs等)均不支持流式语音生成。CosyVoice 2.0提出了如图2所示的离线和流式一体化建模方案,使得LLM和FM均支持流式推理,接收5个文字就可以合成首包音频,延迟大致在150ms。同时合成音质相比于离线合成基本无损。
4)指令可控的音频生成能力升级:优化后的 CosyVoice 2.0 在基模型和指令模型的整合上取得了重要进展,不仅延续了对情感、说话风格和细粒度控制指令的支持,还新增了中文指令的处理能力。其指令控制功能的扩展尤为显著,现已支持多种主要方言,包括粤语、四川话、郑州话、天津话和长沙话等,为用户提供了更丰富的语言选择。此外,CosyVoice 2.0 也引入了角色扮演的功能,如能够模仿机器人、小猪佩奇的风格讲话等。这些功能的提升还伴随着发音准确性和音色一致性的显著改善,为用户带来了更自然和生动的语音体验。
▎支持的功能:
🎧 音色复刻:语音克隆/Zero-shot In-context Generation(语音续写)
🎧 多语言合成:一个文本,分别用中文,英文,日语,韩语多个语言来说
🎧 混合语种合成:支持 文本中同时出现 中文/英文/日语/韩语等。
🎧 多情感合成:#厌恶# 今天又是打工人的一天;#恐惧#啊已经9点了,怎么办,我要迟到了!#愤怒#都怪昨晚他非要拉我看电影,害我睡晚了!#平静#今年的年假都用光了,#开心#不过没关系,马上要放假啦!
🎧 不同指令合成:
(神秘<|endofprompt|>古老城堡笼罩在神秘的雾气中,吸引着无数冒险者前去探索奥秘。
小猪佩奇<|endofprompt|>在忙碌之余,我和朋友像小猪佩奇一样,常去公园享受简单的快乐。
四川话<|endofprompt|>而这些幽默的瞬间仿佛让我置身于四川的宽窄巷子,享受那份安逸。
用伤心的语气说<|endofprompt|>收到拒信的那一刻,我感到无比伤心。虽然知道失败是成长的一部分,但仍然难以掩饰心中的失落。
慢速<|endofprompt|>听着轻柔的音乐,我在画布上慢慢地涂抹色彩,让每一笔都充满灵感和思考。
追求卓越不是终点,它需要你每天都<strong>付出</strong>和<strong>精进</strong>,最终才能达到巅峰。)
🎧 绕口令:黑化肥发灰,灰化肥发黑,黑化肥挥发会发黑,灰化肥挥发会发灰。
🎧 生僻字:煢煢孑立 沆瀣一氣 踽踽獨行 醍醐灌頂 綿綿瓜瓞 奉為圭臬 龍行龘龘
🎧 多音字:天气暖和,小王在家和泥抹墙;
Demo体验:
>>>创空间地址:https://www.modelscope.cn/studios/iic/CosyVoice2-0.5B
可以支持用户上传音频文件或录音方式进行语音复刻。同时支持流式推理,用户无需等待全部音频合成完毕即可体验效果。
CosyVoice 2支持音色克隆以及自然语言控制的音频生成,可以选择相应的推理模式。
1)3s极速复刻
- 输入待合成文案
- 选择是否流式推理,流式推理具有更低的延迟,离线推理具有更好的上限效果
- 上传prompt音频,或者录制prompt音频
- 点击生成音频,等待一会儿就会听到合成的音频。
2)自然语言控制
- 输入待合成文案
- 上传prompt音频,或者录制prompt音频
- 输入instruct文本:例如“用粤语说这句话”,“用开心的语气说”,“模仿机器人的声音”等
- 点击生成音频,等待一会儿就会听到合成的音频。
补充:v1版本
CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer based on Supervised Semantic Tokens
CosyVoice 1.0: Demos; Paper; Modelscope
论文解读:
摘要
CosyVoice,这是一种基于监督离散语音标记的多语言语音合成模型。通过使用两种流行的生成模型:语言模型 (LM) 和流匹配进行渐进式语义解码,CosyVoice 在语音上下文学习中实现了高韵律自然度、内容一致性和说话人相似性。最近,多模态大型语言模型 (LLMs,其中响应延迟和语音合成的实时因子在交互体验中起着至关重要的作用。因此,在这项工作中,我们引入了一种改进的流式语音合成模型 CosyVoice 2,并进行了全面和系统的优化。首先,我们引入有限标量量化来提高语音标记的码本利用率。其次,我们简化了文本-语音 LM 的模型架构,以便可以直接使用预训练的 LLMs 作为主干。此外,我们还设计了一个 chunk-aware 【数据块感知】因果流匹配模型,以适应不同的 synthesis 场景。因此,我们可以在单个模型中执行 streaming 和非 streaming 合成。通过在大规模多语言数据集上进行训练,CosyVoice 2 实现了与人类相当的合成质量,具有非常低的响应延迟和实时系数。
CosyVoice 2,这是一种流式零样本 TTS 模型,具有改进的韵律自然度、内容一致性和说话人相似性。我们的贡献包括:
- 将流式和非流式合成统一在一个框架中,并提出统一的文本语音语言模型和块感知因果流匹配模型,与离线模式相比,实现了无损流式合成
- 通过移除文本编码器和说话人嵌入来简化 LM 架构,允许预先训练的文本大型语言模型 (LLMs) 作为主干,增强上下文理解。
- 用有限标量量化 (FSQ) 替换语音分词器中的矢量量化 (VQ),提高码本利用率并捕获更多语音信息。
- 升级指示式 TTS 容量以支持更多指令,包括情感、口音、角色风格和精细控制。在 CosyVoice 2 中,指令和零镜头容量集成到一个模型中,实现更通用、更生动的合成。
通过以上系统性的修改和优化,CosyVoice 2 实现了人偶校验的合成质量,并且在 streaming 模式下几乎无损。统一框架放宽了部署要求,使单个模型能够同时支持流式和非流式合成。升级后的 instructed TTS 容量为用户生成各种语音提供了更强大、更轻松的方法。此外,块感知流匹配设计也可以应用于 NAR TTS 模型,这表明了流式 NAR 模型的潜力。
CosyVoice 2
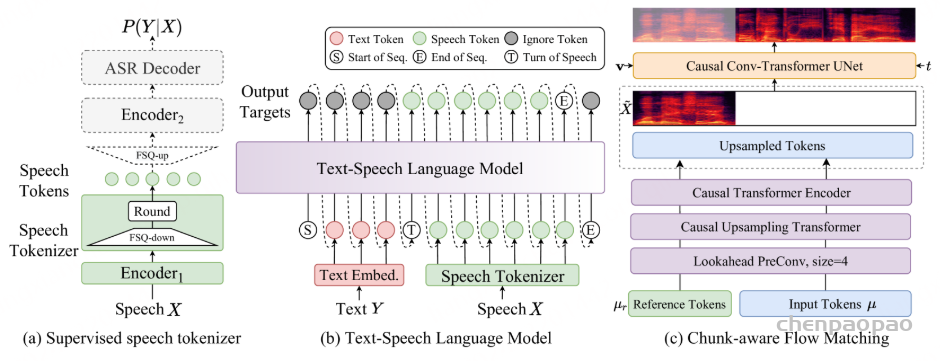
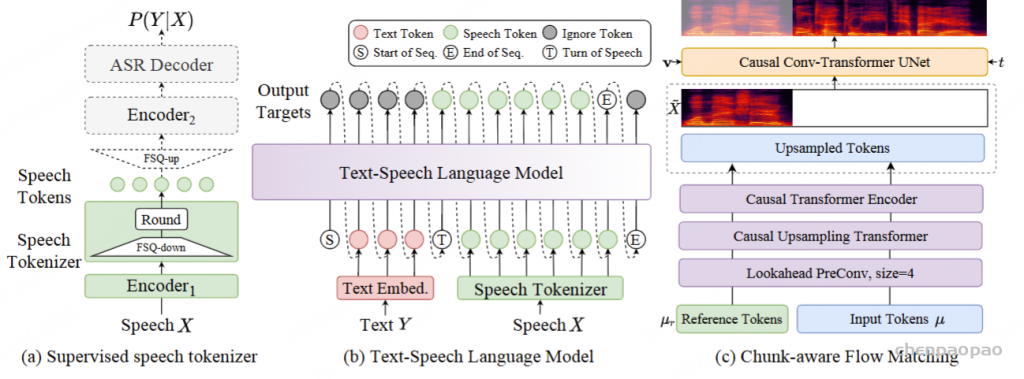
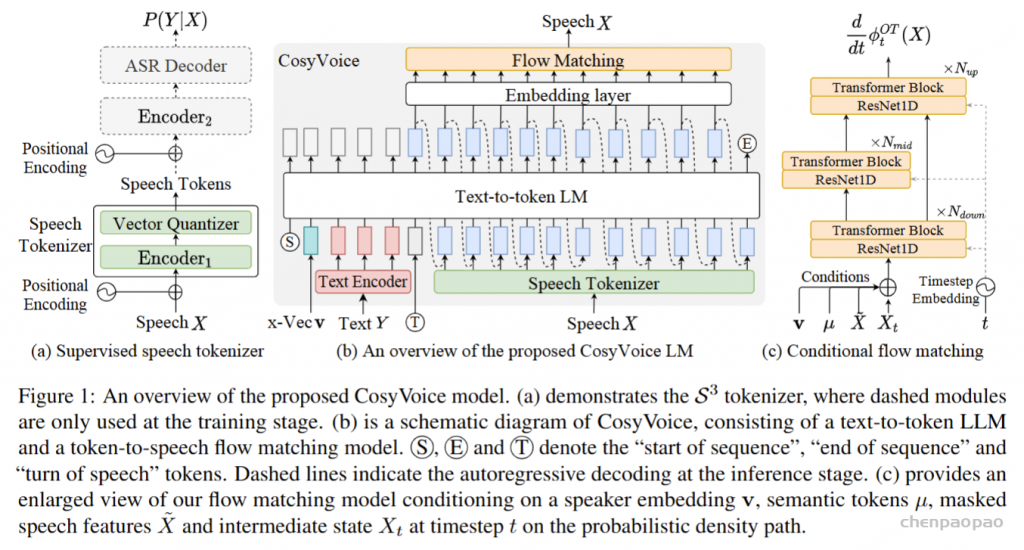
CosyVoice 2 建立在与前代 类似的设计理念之上,将语音信号的语义和声学信息分离出来,并独立建模。语音生成过程被重新定义为一个渐进的语义解码过程,其中条件信息逐渐被纳入。具体来说,文本-语音语言模型 (LM) 只关注语义信息,将高级文本标记解码为监督式语义语音标记。在 Flow Matching 模型中,通过说话人嵌入和参考语音引入声学细节(例如音色),将语音令牌转换为给定说话人的 Mel 频谱。最后,预先训练的声码器模型恢复了相位,将 Mel 频谱转换回原始音频信号。下面将从文本分词器、监督语义语音分词器、流式/非流式合成的统一文本语音 LM 和分块感知流式匹配模型五个方面介绍 CosyVoice 2 的细节和流式合成的修改。
Text Tokenizer
CosyVoice 2 直接使用原始文本作为输入,并使用基于 BPE 的文本分词器进行分词。这消除了对通过字素到音素 (g2p) 转换获取音素的前端模型的需求。这种方法不仅简化了数据预处理工作流程,还使模型能够以端到端的方式学习各种上下文中单词的发音。与文本 LLMs,CosyVoice 2 屏蔽了一对多的分词。这可以防止令牌的发音变得过长,并减少由数据稀疏引起的极端情况。具体来说,如果 BPE 令牌编码多个中文字符,它将被屏蔽掉,并且每个字符将在分词化过程中单独编码。其他语言(如英语、日语和韩语)不受特殊处理。
Supervised Semantic Speech Tokenizer
将有限标量量化 (FSQ) 模块插入 SenseVoice-Large ASR 模型的编码器中。在训练阶段,输入语音 X 通过 获得 Encoder1 中间表示,其中 Encoder1 由六个带有旋转位置嵌入 的 Transformer 块组成。然后,将中间表示馈送到 FSQ 模块进行量化,并将量化表示传递给 SenseVoice-Large 模块的其余部分,包括 Encoder2 和 ASRDecoder ,以预测相应文本标记的后验概率。
补充FSQ:FINITE SCALAR QUANTIZATION: VQ-VAE MADE SIMPLE
2023 年 google 发表的文章,可以用于文本、视频生成领域中。提出一种称为有限标量量化(FSQ)的简单方案来替换 VQ-VAEs 中的向量量化(VQ)。解决传统 VQ 中的两个主要问题:需要避免 codebook collapse (码码本坍塌:就是大部分codebook elements都没有被用到,多个码字可能会变得非常相似,甚至完全相同。)的辅助损失【在损失函数中添加一个辅助损失项,迫使码字之间保持一定的距离,或者保持其多样性】、大 codebook size 情况下码本利用率低。FSQ 作用:消除辅助损失、提高码本利用率、作为 VQ 的可替换组件。
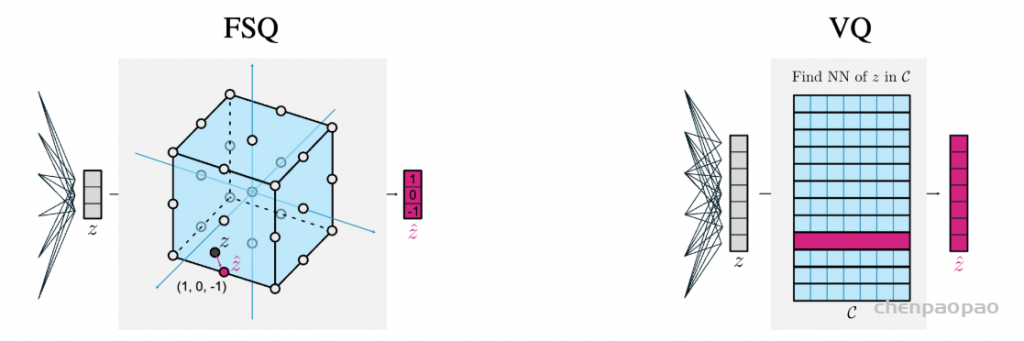

传统的编码器所得到的表征向量z中的每一个元素(标量)的值并没有一个明确的边界,也就是说z在特征空间中不受任何约束。那么,作者就想到了为z中的每个标量都设定好取值的范围和能够取值的个数。假设有一个d维特征向量z,将每个标量zi都限制只能取L个值,将zi→⌊L/2⌋tanh(zi)然后四舍五入为一个整数值。例如图中所示,取d=3,L=3,代表C={(−1,−1,−1),(−1,−1,0),…,(1,1,1)},一共有27种组合,即一个3维向量的每个标量都有三种值的取法。值得一提的是,FSQ中的codebook不像VQ-VAE那样是显式存在的,而是隐式的,编码器直接输出量化后的特征向量z^。因此,FSQ也就没有了VQ-VAE损失的后两项了。
FSQ 的优点是不会遭受码本坍塌(codebook collapse),并且不需要 VQ 中为了避免码本坍塌而使用的复杂机制(承诺损失、码本重新播种、码分割、熵惩罚等)
在 FSQ 模块中,首先 H 将中间表示投影到 D 维低秩空间中,并且每个维度的值通过有界四舍五入操作ROUND 量化到区间[−K,K]。然后,量化后的低秩表示 Hˉ 被投影回原始维度 H~,以供后续模块使用。
在训练阶段, straight-through estimation用于近似 FSQ 模块 和 Encoder1 的梯度。 语音标记 μi 可以通过计算 (2K+1) -ary 系统中量化的低秩表示 h¯i 的索引来获得:
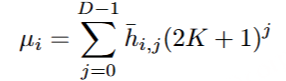
语音分词器以 25 Hz 的令牌速率工作,即每秒 25 个语音令牌。
Unified Text-Speech Language Model
CosyVoice 2 中,使用预训练的文本Qwen2.5-0.5B 作为文本-语音语言模型,以输入文本作为提示自动回归生成语音标记。与其他 LM 类似,文本语音 LM 也采用下一个标记预测方案进行训练,如图 1(b) 所示。与之前的 CosyVoice 不同,我们去除了说话人嵌入,以避免信息泄漏。更重要的是,我们发现这种话语级别的向量不仅包含说话人身份信息,还包含语言和副语言信息,这会影响文本-语音语言模型的韵律自然性和跨语言能力。此外,我们还放弃了之前 CosyVoice 的文本编码器,因为我们发现 Qwen2.5-0.5B 模型已经足够强大,可以对齐文本和语音标记,因此不再需要文本编码器。
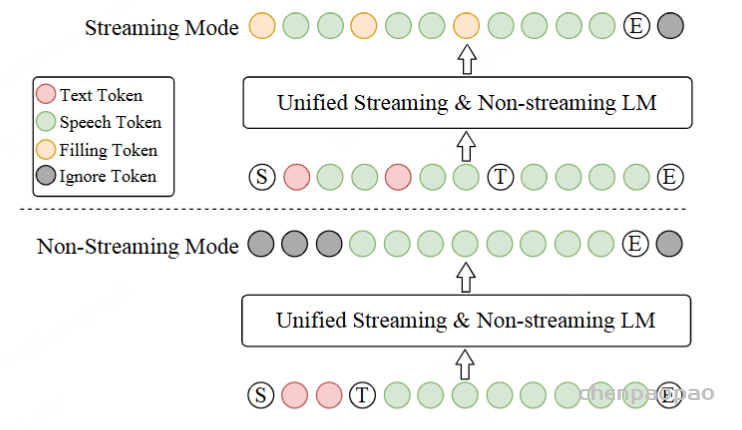
受益于文本语音 LM 的简单性,我们可以为流式和非流式合成构建一个统一的模型。在这里,“流模式”意味着输入文本以连续流的形式接收,而不是提前被称为完整的句子。在 CosyVoice 2 中,推流模式和非推流模式的区别只是 LM 的序列构建方式:
- 对于非流模式,“序列开始”S、所有文本标记、“语音转换”T标记、所有语音标记和“序列结束”E按顺序连接,如图 2 底部所示。Ignore 标记表示忽略它们的损失,同时最小化交叉熵目标函数。
- 在流式模式下,我们将文本和语音标记按预定义的比例 N:M 混合,即每 N 个文本标记后跟着 M 个语音标记,如图 2 的顶部所示。如果下一个标记是文本标记,模型会预测一个填充标记(而不是文本标记),该填充标记表示接下来的 N个文本标记应该在推理阶段进行连接。【方便推理时候获取输出的语义token】,当文本标记用尽时,“语音轮次”标记 T和剩余的语音标记会被顺序连接,形成流式模式下的混合文本-语音标记序列。
通过同时在上述两个序列上训练文本-语音 LM,我们可以在单个统一模型中执行流式和非流式语音生成。在实际场景中,例如说话人微调 (SFT) 和上下文学习 (ICL),推理序列有所不同,如下所示:
ICL,非流式:在 ICL 中,LM 需要来自参考音频的提示文本和语音标记,以模仿重音、韵律、情感和风格。在非流式处理模式下,提示和要合成的文本标记连接为整个实体,提示语音标记被视为预先生成的结果并固定:“S 、 prompt_text、 text 、T、 prompt_speech”。LM 的自回归生成从此类序列开始,直到检测到 “End of sequence” 标记。
ICL,流式处理:在此方案中,我们假设要生成的文本是已知的,并且语音令牌应以流式处理方式生成。同样,我们将 prompt 和 to-generate 文本视为一个整体。然后,我们将其与提示语音标记混合,比例为 N : M : “S, mixed_text_speech,T,remaining_speech”。如果文本长度大于提示语音 Token 的长度,LM 将生成 “filling token”。在这种情况下,我们手动填充 N个文本标记。如果文本令牌用完,将添加“Turn of speech” T 令牌。在流式处理模式下,我们为每个 M 令牌返回生成结果,直到检测到 E为止。
SFT,非流式:在 SFT 场景中,LM 针对特定说话人进行微调,不再需要提示文本和语音。因此,初始序列非常简单:“ S, 文本 ,T ”。从此开始,文本-语音 LM 可以自动回归生成语音标记,直到 E结束。
SFT, Streaming: 在 SFT 的流模式下,我们从以下序列开始语音生成:“ S,first_N_text”。然后,LM 将生成 M 语音令牌,我们手动填充下一N个 文本令牌。我们重复上述过程,直到所有文本标记都用完,然后添加 T 。注意,speech-to-speech多模态大语言模型也可以采用这种模式,以获得极低的延迟。
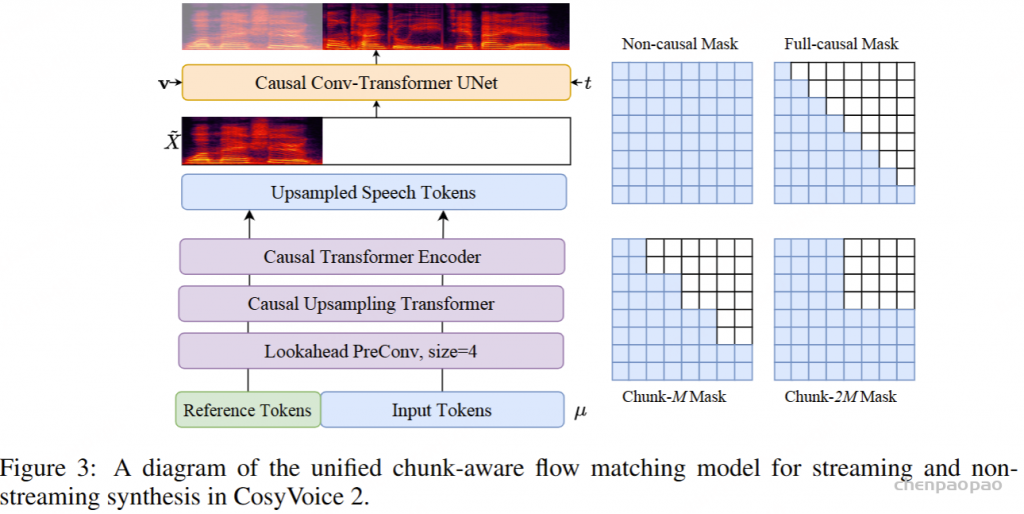
Chunk-aware Flow Matching
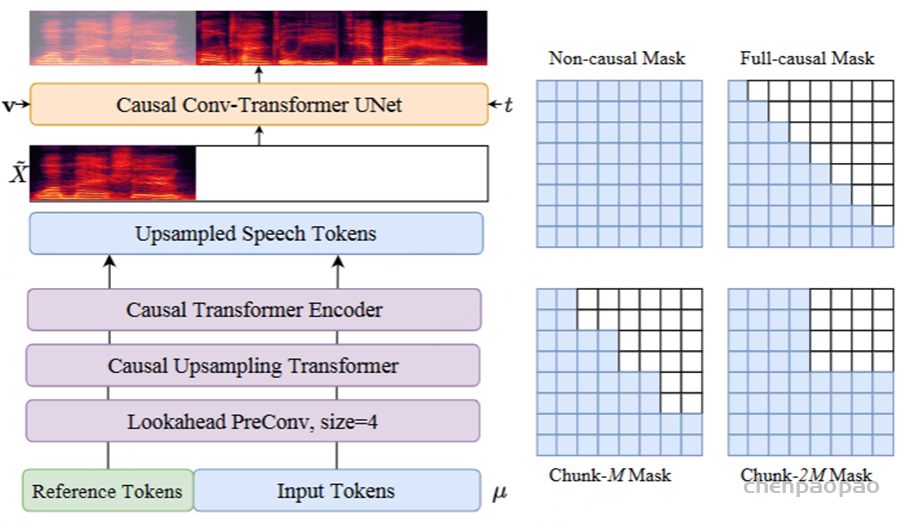
采用梅尔频谱图作为声学特征,帧率为 50 Hz,采样率为 24000。由于语音令牌和 Mel 特征之间的帧速率不匹配,我们以 2 的比率对语音令牌进行上采样,以匹配 Mel 频谱图的帧速率。在上采样操作之前,我们添加了一个额外的前瞻卷积层,以便为以下因果模块提供未来信息。前瞻层由右填充的一维卷积实现,其填充大小为 P, 卷积核大小为 P+1 。在此之后,几个chunk-aware causal Transformer blocks来对齐语音标记的表示空间以匹配声学特征。
随后,我们的目标是将语音标记进一步解码为由说话人嵌入和参考语音指定的 Mel 频谱图。 为了实现这一目标,我们采用条件流匹配 (CFM) 模型对 Mel 频谱图进行采样,给定语音标记、参考语音和说话人嵌入作为条件。 在 CFM 模型中,目标 Mel 三维频谱图的分布由来自先验分布 p0(X) 和数据分布 q(X) 的概率密度路径 来描述。概率密度路径可以由瞬态向量场定义。 为了提高采样效率,我们采用最佳传输 (OT) 流来匹配矢量场 。
在训练阶段,掩码 Mel 频谱图是通过随机掩码 70% 到 100% 的最终帧来获得的 X1 。至于推论,它由从参考语音中提取的 Mel 频谱图提供。 通过最小化预测 ODE 和真实 ODE 之间的 L1 损失,我们可以按如下方式优化 UNet 参数 θ :
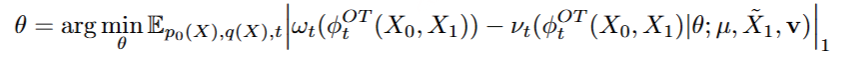
因果流匹配模型:当前的流匹配模型总是以离线模式工作,即只有在生成所有语音标记后,Mel谱图才能被采样,这对于流式合成并不友好。为了解决这个问题,我们将多步流估计视为一个堆叠的深度神经网络,该网络重复使用 UNet 十次。因此,通过使展开的神经网络具有因果性,我们可以将其应用于流式合成。我们构造了四个掩码,以满足不同的应用情况:
Non-causal Mask
非因果掩码 (Non-causal Mask) 用于离线模式,通过满足所有条件帧来实现最佳性能。非因果掩码适用于对延迟不敏感的情况。
Full-causal Mask
全因果掩码 (Full-causal Mask) 适用于需要极低延迟的场景,其中只能观看过去的帧。
Chunk-M Mask
可以通过牺牲更多延迟来实现离线模式的近似性能,这可用于级联生成 Chunk 以获得更好的性能。
Chunk-2M Mask
可以通过牺牲更多延迟来实现离线模式的近似性能,这可用于级联生成 Chunk 以获得更好的性能。
对于小批量中的每个训练案例,我们从均匀分布下的上述四个掩码中随机采样一个掩码。这样,一个流匹配模型可以兼容不同的场景,降低部署复杂度。这种块感知训练的另一个优点是,具有更多上下文的掩码可以作为具有较少上下文的掩码的教师,受益于隐含的自我蒸馏方案。
流式处理模式的延迟分析
首包延迟是流式合成模型的一个重要指标,它显着影响用户体验,尤其是在基于 LLM 的语音聊天应用程序中,例如 GPT-4o 。 在 TTS 的上下文中,要合成的文本是事先已知的,延迟来自语音令牌生成、梅尔频谱图重建和波形合成等方面。 因此,CosyVoice 2 的首包延迟 LTTS 可以得到如下:
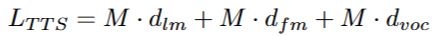
其中 dlm ,表示 LM 生成一个语音词元的计算时间, dfm 表示 Flow Matching 模型生成一个语音词元的梅尔频谱图帧的计算时间, dvoc 表示声码器合成一个语音词元对应的波形的计算时间。 在基于 LLM 的语音聊天上下文中,还应考虑 first-package-required 文本的长度,first-package 延迟 LChat 如下:
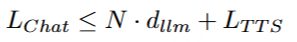
其中 dllm 表示 LLM 生成一个文本 Token 的计算时间。请注意,由于多字符标记在 CosyVoice 2 的文本分词器中被屏蔽,因此文本 LLMs总是比 CosyVoice 2 使用的文本标记编码更长的原始文本。因此,第一个包的延迟 LChat 必须低于 N⋅dllm 和 LTTS的和。
Instructed Generation
为了增强 CosyVoice 2 的可控性,我们将 indirected 数据集集成到基础训练集中。我们收集了 1500 小时的定向训练数据,其中包括自然语言指令和细粒度指令,如表所示。对于自然语言指令,我们在要合成的输入文本之前预置自然语言描述和特殊结束标记“<|endofprompt|>”。这些描述涵盖情感、语速、角色扮演和方言等方面。对于细粒度的指令,我们在文本标记之间插入人声爆发,使用“[laughter]”和“[breath]”等标记。此外,我们将 vocal feature 标签应用于短语;例如,“<strong>XXX</strong>”表示强调某些词,而“<laughter>XXX</laughter>”表示笑声说话。

Multi-Speaker Fine-tuning
在特定说话人 (SFT) 上微调预训练模型可以进一步提高生成质量和说话人相似度。在本报告中,我们介绍了多扬声器微调 (mSFT),其中预训练模型同时在多扬声器上进行微调,而不是在单个扬声器上进行微调。这种方法可确保跨多个说话人的全面韵律和发音覆盖,并减少预训练模型可能出现的灾难性遗忘。为避免不同说话人之间的音色混淆,我们在特定说话人的输入文本前加上说话人提示标记“Speaker A<|endofprompt|>”。如果训练样本未标记为说话人,则使用特殊标签“unknown<|endofprompt|>”。在整个多说话人微调过程中,学习率设置为 1e-5。
Reinforcement Learning for SFT
强化学习是大型语言模型训练中常用的方法,它可以使 LM 输出与人类偏好保持一致。 在 CosyVoice 2 中,我们采用 ASR 系统的说话人相似度 (SS) 和识别词错误率 (WER) 作为奖励函数,以提高微调阶段的说话人相似度和发音准确性。我们使用 WER 和 SS 来区分首选样品 xw 和不合格样品 xl ,并通过直接偏好优化 (DPO) 优化 TTS 系统,如下所示:
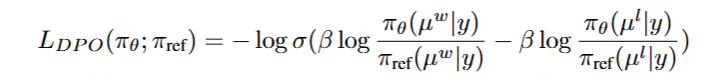


Experimental
Training Data for Speech Tokenizer
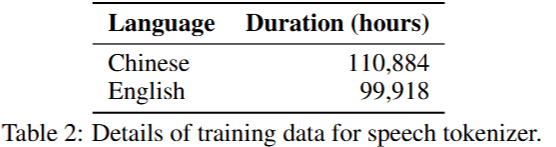
一个 200000 小时的数据集用于训练语音分词器,并将规范化转录作为标签。详细的数据信息如表所示。训练数据来自三种不同的资源:开源 ASR 数据集、内部工业数据集和 TTS 生成数据集。虽然我们在训练语音分词器时只使用了中英文数据,如表 所示,但随后的实验表明,语音分词器对其他语言具有零镜头能力。它还可用于日语和韩语等语言的语音合成。
Training Data for CosyVoice 2
CosyVoice 2 与之前的版本共享相同的训练数据。我们首先使用内部语音处理工具收集纯语音数据。随后,Paraformer 和 SenseVoice分别用于生成中文和其他语言的伪文本标签。我们还采用内部力对齐模型来过滤掉低质量的数据并提高标点符号的准确性。表 3 提供了数据详细信息:

Experimental Results
Evaluations on Speech Tokenizer
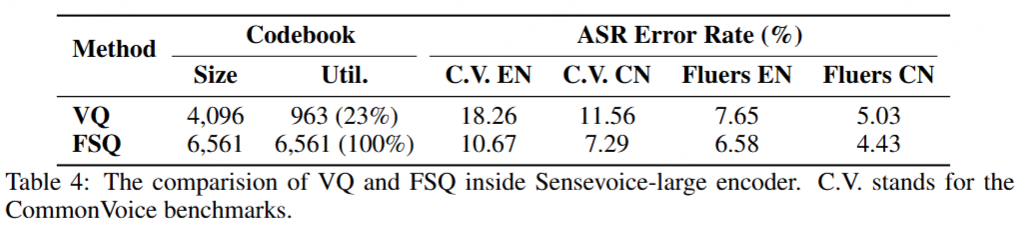
理想的语音分词器应该有效地利用码本,以高保真度保留信息,并展示说话人的独立性。在这部分,我们从四个方面评估我们的监督语音分词器:1) 码本利用率;2) 整个编码器内的 ASR 错误率;3) 不同说话人的令牌可视化;4) 说话人识别培训。表 4 显示了码簿利用率和 ASR 错误率。事实证明,基于 FSQ 的分词器充分利用了码本,从 ASR 方面维护了更有效的信息,表明 FSQ 维护的语义信息更多。
Comparison Results with Baselines:
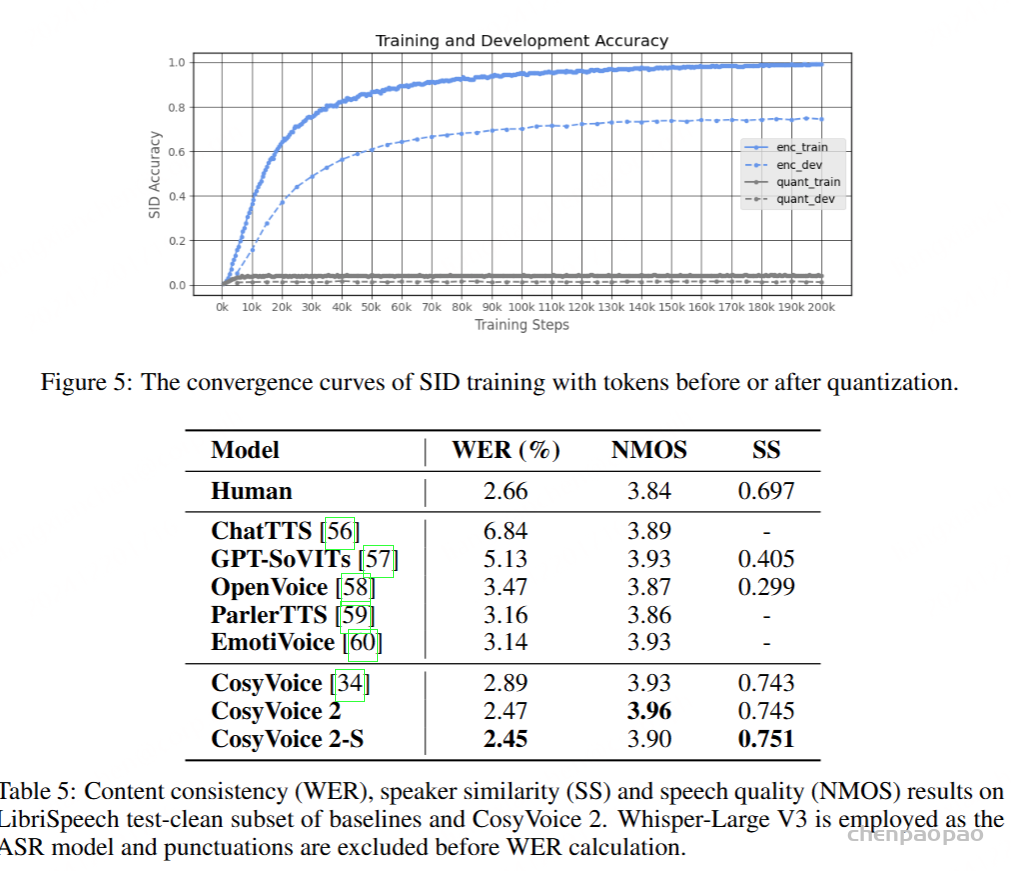
我们首先在有限的英语文本域上评估了我们的 CosyVoice 2 模型,并将其与几个开源模型进行了比较,例如 ChatTTS、GPT-SoVITs 、OpenVoice、ParlerTTS、EmotiVoice 及其前身 CosyVoice。客观结果如表 5 所示,包括内容一致性 (WER)、语音质量 (NMOS) 和说话人相似度 (SS)。从表中我们可以看到,CosyVoice 2 在 Librispeech 测试清理集上实现了最先进的性能,超越了所有基线模型和所有评估指标。值得注意的是,CosyVoice 2 甚至表现出比人类话语更高的内容一致性、语音质量和说话人相似度,这表明其人类奇偶校验的合成质量。

Modular Ablation Study:
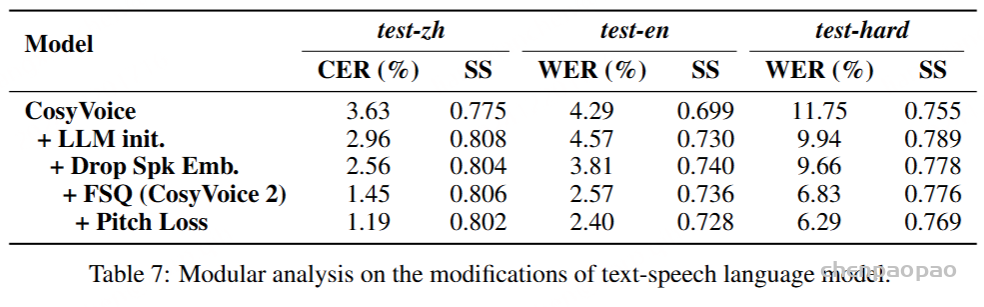
我们对文本语音语言模型进行了模块化消融研究,以评估我们的修改的影响,包括 LLM 初始化、删除说话人嵌入和利用 FSQ。表 7 展示了 CosyVoice 2 在前代产品的基础上的逐步发展。通过将随机初始化的语言模型替换为预训练的 LLM),我们在 test-zh 和 test-hard 集上的内容一致性分别实现了 18.46% 和 15.40% 的相对改进 。接下来,我们从文本转语音语言模型中删除了说话人嵌入,这有助于防止上下文学习中的信息泄露和干扰。这一变化导致内容错误显著减少,同时保持说话人相似性,表明内容信息主要由 LM 建模,说话人信息主要由流匹配模型恢复。最后,通过将 VQ 替换为 FSQ,我们实现了 CosyVoice 2 模型,注意到更高的内容一致性和不变的说话人相似度。通过充分利用码本,FSQ 可以捕获更多的内容信息和上下文变化,从而更好地协调文本和语音令牌。此外,我们通过在基于 FSQ 的语音标记器的训练过程中将音高损失作为约束条件进行了比较实验。我们发现这种方法可以提高下游 TTS 任务的性能,如表 7 的最后一行所示。在 CosyVoice 的未来版本中,我们计划进行更详细的实验和分析。
Results on Japanese and Korean Benchmarks
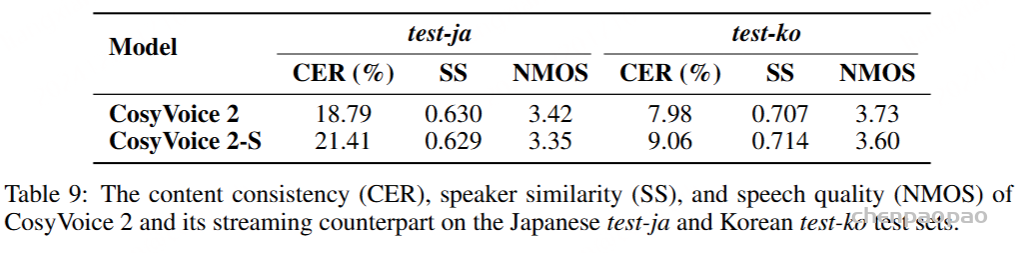
除了中文和英文,CosyVoice 2 还支持日语和韩语。我们在构建的日语和韩语测试集上评估了内容一致性、说话人相似度和语音质量。如表 9 所示,在所有评估指标中,CosyVoice 2 在韩语上的表现明显优于日语。这种差异主要是由于日语和中文之间的字符集重叠,这导致日语上下文中的中文发音。在未来的工作中,我们计划探索增强多语言合成的语言上下文的方法。由于韩语与其他语言没有字符重叠,因此其语音合成性能要好得多。另一个问题是数据不平衡。我们相信,增加训练数据量可以进一步提高日语和韩语的综合性能。
Results on Instructed Generation:
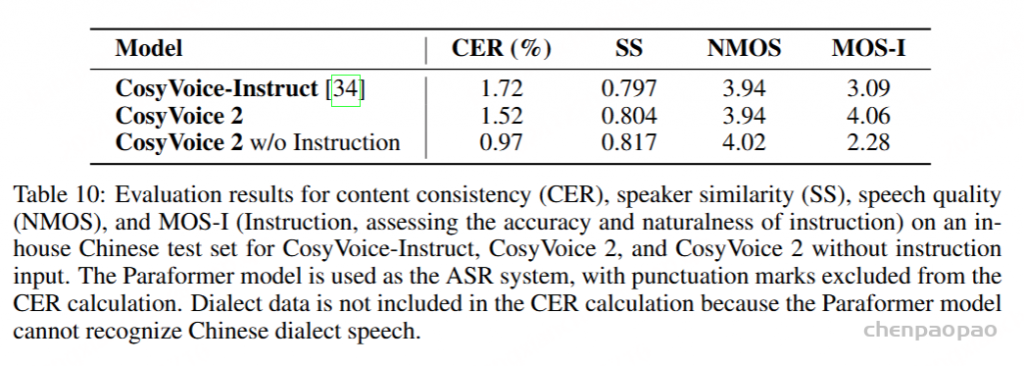
为了评估 instructed generation 的性能,我们创建了一个包含 290 个样本的中文测试集。这组指令包括 29 种类型的指令,如表 2.6 所示,每种指令都有 10 种不同的输入文本。我们使用来自 5 个说话人(3 个女性和 2 个男性)的 5 个音频提示和说话人嵌入作为 flow matching 模型的条件。我们的测试以离线模式进行。我们客观地评估了内容一致性 (CER)、说话人相似度 (SS) 和语音质量 (NMOS)。主观上,我们使用教学平均意见分数 (MOS-I) 评估教学的准确性和自然性,范围从 1 到 5。每个样本由 10 名以中文为母语的人进行评估,分数以 0.5 为增量分配。评估标准侧重于语音是否遵守所有指定的指令,例如情感表达、语速调整、方言使用和角色扮演。精细的控制(包括插入笑声、笑声说话、呼吸控制和强调)将评估其自然性和准确性。如表 10 所示,CosyVoice 2 表现出卓越的内容一致性 (CER)、说话人相似性 (SS) 以及指令控制 (MOS-I) 的准确性和自然性,同时保持了与 CosyVoice-Inspire 相当的语音质量。当从 CosyVoice 2 中删除输入指令时,MOS-I 明显下降;然而,在内容一致性 (CER) 、说话人相似度 (SS) 和语音质量 (NMOS) 方面观察到改善。这表明指令可控性很难从内容文本中隐式出现。
Results on Speaker Fine-tuned Models
在微调阶段,我们对同一扬声器的扬声器嵌入采用无监督聚类,以确保扬声器音色的稳定性。我们已经证明,只有 400 个音频记录的目标说话人可以实现相当好的语音合成性能,在不同说话人之间观察到的客观指标仅存在轻微差异,如图 6 所示。我们的实验表明,大多数说话人可以继承零镜头 TTS 模型的稳健上下文理解和感知,从而自然地表达各种情绪和情绪以响应输入文本。
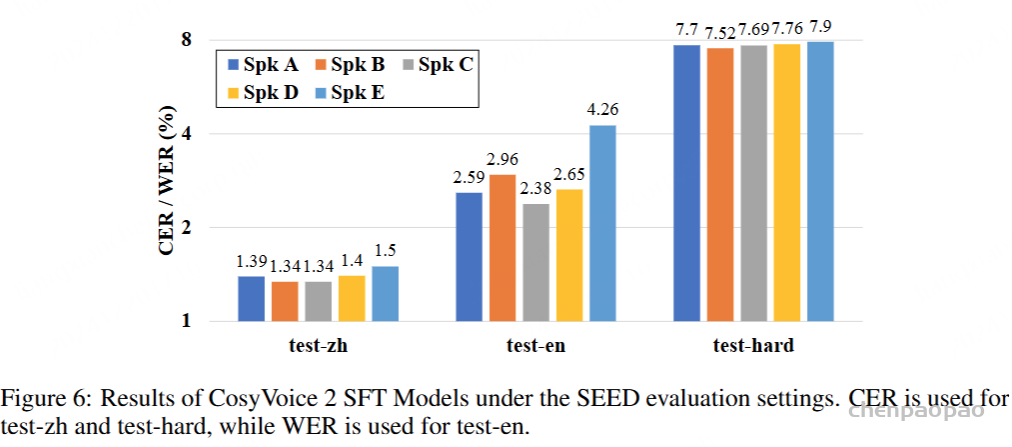
LLM Fine-tuning with Reinforcement Learning
尽管 SFT 可以提高大多数扬声器的性能,但 Spk E 的结果仍然比基本模型差,尤其是在英语上。因为 Spk E 的声音更复杂,说话速度更快。此外,只有 Chinese 录音可用于 Spk E。因此,我们在 Spk E 上应用强化学习以进一步改进。对于 DPO,我们通过 SFT 模型合成了 10,000 个样本对,以改变 ASR 和 SS 奖励对 LM 的偏好偏差。我们还使用可微分的 ASR 奖励来优化 LM 参数。在 RL 之后,我们在 Spk E 测试集上用内容一致性 (WER)、说话人相似度 (SS) 和语音质量 (NMOS) 评估模型,并进一步评估 SeedTTS 测试集上的 WER,以探索模型是否可以保持对域外或跨语言输入文本的鲁棒性。结果如表 11 所示
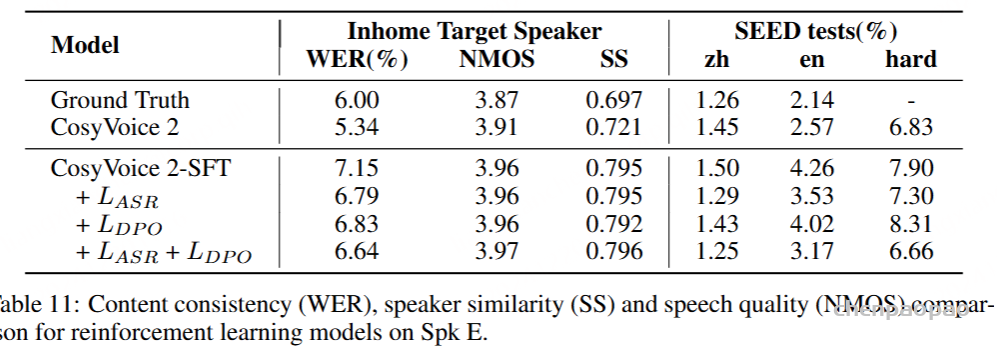
与预先训练的基础模型相比,SFT 模型显示出更高的说话人相似度和语音质量,但是,WER 可能比基础模型差。我们发现,基本模型合成的音频总是比 SFT 和真实值慢,这对 ASR 系统更友好。对于目标说话人数据集,偏好偏差和可微分奖励都可以降低 WER,而对其他两个指标的有害影响很小。但对于 SEED 测试集,基于 DPO 的强化仅对中文和英文子集有益,而硬样本会更差。原因可能是硬样本包含许多重复的单词或短语,在 DPO 训练期间可以被视为被拒绝的样本。但是,可微分的 ASR 奖励不会遇到这个问题,因为它可以直接通过 ASR 后验优化 TTS 系统。这意味着可微分的 ASR 奖励在域外情况下具有更好的泛化能力。最后,我们可以将它们相互组合以进行进一步改进。
Conclusion
在 CosyVoice 成功的基础上,本报告介绍了 CosyVoice 2,这是一种改进的流式语音合成模型,它利用了大型语言模型。通过将流式和非流式合成统一在一个框架中,CosyVoice 2 实现了人类奇偶校验的自然性、最小的响应延迟和流式模式下几乎无损的合成质量。关键创新包括用于充分利用码本的有限标量量化、包含预训练文本LLMs,以及开发块感知因果流匹配模型以支持不同的合成场景。此外,指令 TTS 能力的改进允许通过对情感、口音、角色风格和人声爆发的精细控制,生成多功能和生动的语音。通过系统的修改和优化,CosyVoice 2 不仅提供了卓越的合成质量,而且放宽了部署要求,使其适用于流式和非流式应用。我们相信 CosyVoice 2 代表了可扩展、高质量和交互式文本转语音合成的重大进步。