
近几个月来,许多端到端的语音对话系统涌现,旨在解决级联系统中交互延迟过高以及基于文本交互下副语言信息丢失的问题。然而,目前大多数语音对话模型依赖于大量的语音对话数据以及高昂的训练代价,且存在响应音色单一的弊端。
近日,上海交通大学计算机系X-LANCE实验室联合微软亚洲研究院推出了面向低资源场景下支持可控音色的语音对话模型——SLAM-Omni。该模型只需要在4张GPU上单阶段训练15小时,即可获得远超此前同等规模模型的对话能力,并且具有优越的语音质量以及生成语音-文本一致性。在更大规模数据集上的实验表明SLAM-Omni在中文对话以及多轮对话上都有不俗的表现。

语音对话系统建模
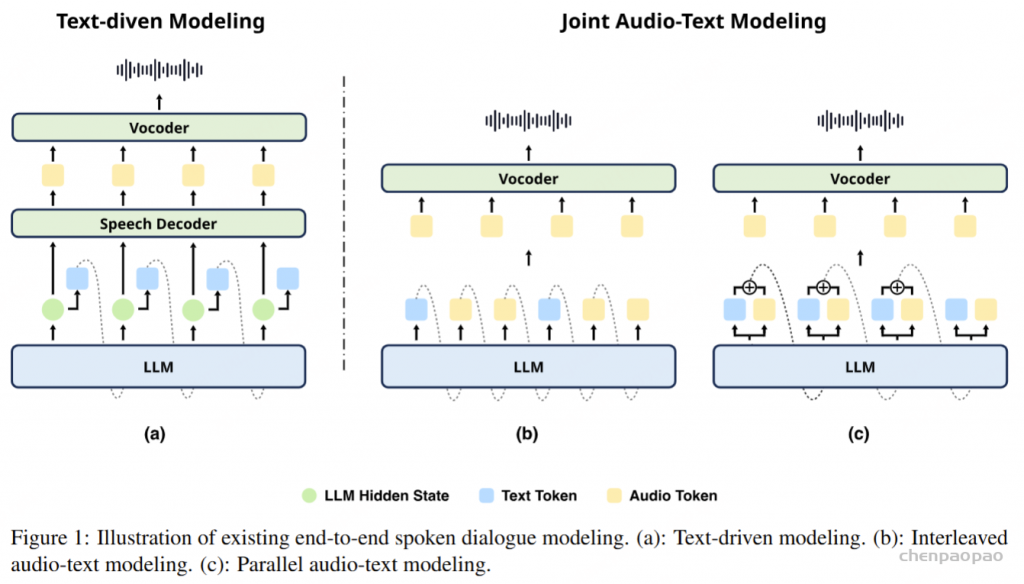
本文首先探索了主流的语音对话系统建模方案,现有端到端系统主要通过将文本作为中间输出或隐藏状态来利用预训练的大语言模型(LLM)。这些方法可以分为文本驱动建模和音频-文本联合建模两类。
文本驱动建模保留了LLM原始架构,将文本隐状态传递给语音解码器生成音频,能够有效保留LLM的知识,使用其隐藏状态作为语音解码器的输入用于音频生成,但由于只使用文本tokens进行自回归建模,难以捕捉音频的情感和语调等副语言特征。音频-文本联合建模分为交替和并行两种范式,均将音频 tokens加入自回归建模,理论上提升对非语言信息的建模能力。交替范式通过交替使用文本和音频tokens进行生成,需要大量的语音-文本交替数据并重新训练LLM。而并行范式则并行地对文本和音频tokens自回归生成。SLAM-Omni在此基础上,通过预测单层语义tokens并结合语义分组建模的方式来加速音频生成,显著降低了训练成本。
主要贡献:
- 提出了第一个针对具有说话者解耦语义token的语音交互系统的零样本音色控制解决方案。
- 提出语义组建模方法来加速单层语义语音标记生成和模型训练。
- 历史文本提示是为了在SDM【Existing spoken dialogue models】 中进行高效的多轮历史建模而提出的。
- SLAM-Omni 是第一个实现单阶段训练的语音助手,需要最少的数据和计算资源。
- 实验表明,SLAM-Omni 在文本相关任务上优于类似规模的先前模型,并且在所有现有 SDM 中在声学质量和语音文本对齐方面表现出卓越的性能。更大数据集上的结果证明了其多语言和多轮对话能力。
方法
模型概述
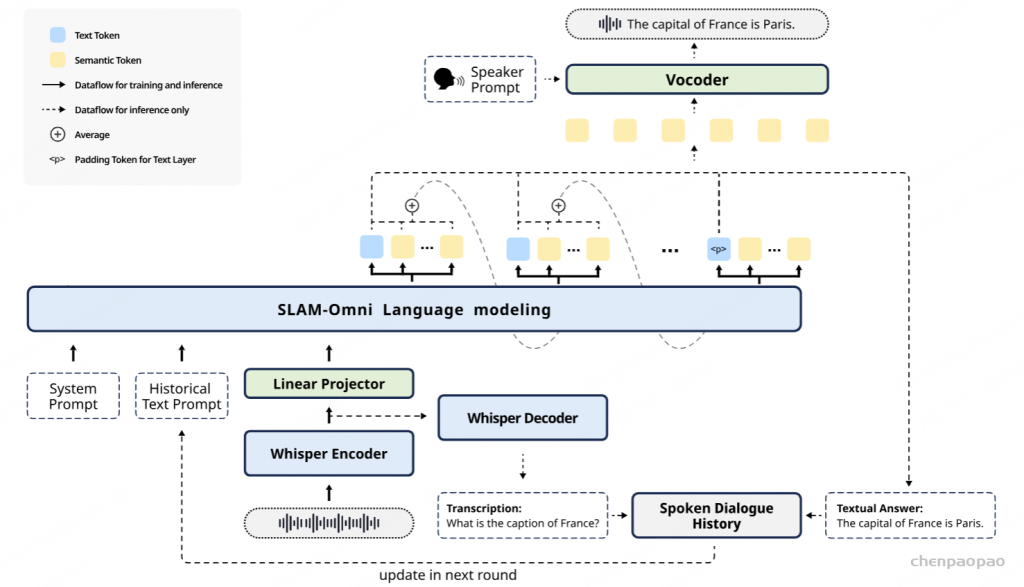
SLAM-Omni通过将系统提示、历史文本提示和用户语音嵌入拼接作为输入,并在Vocoder中通过语者提示来控制音色【 借鉴TTS模型 cosyvoice: 条件流匹配模型 +HifiGAN】;同时,采用语义分组建模加速自回归过程中的语音token生成。
输入语音建模
SLAM-Omni使用Whisper编码器从用户语音指令中提取音频特征(50 Hz)。Whisper作为在大规模跨语言语音数据上训练的语音识别模型,提供了精准的转录和强大的多语言支持,是SLAM-Omni实现多轮多语言对话能力的基础。我们通过降采样处理音频特征,将多个连续帧合并,并通过线性投影将其转换为与LLM嵌入维度对齐的形式。这些处理后的音频特征与文本提示嵌入一起,作为输入传递给LLM。
输出语音建模
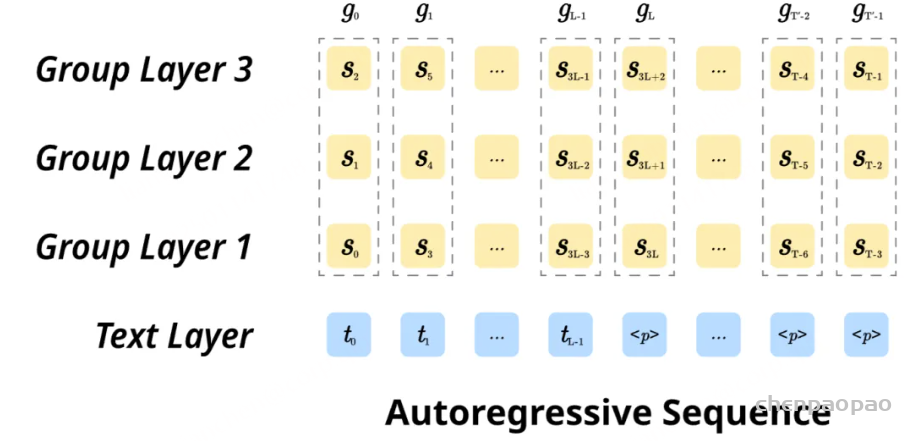
在语音输出方面,SLAM-Omni采用并行的音频-文本联合建模,并行地自回归预测文本和音频的语义tokens。为此,我们扩展了LLM的词表,新增了音频tokens的码本,并将原始的词嵌入矩阵与新嵌入合并。在每个生成步骤中,LLM输出的logits包含了文本和音频tokens的预测分布。然而,由于文本tokens(约为3Hz)和音频语义tokens(50Hz)的频率差异,直接以相同速率生成这两种tokens会导致语音对话模型的训练和推理成本大幅增加,同时增加了实时语音生成的延迟。
为了解决这一问题,本文提出了“语义分组建模”方法,每步生成多个音频tokens,从而缓解频率不匹配带来的挑战。该方法通过线性层将音频logits投影到分组logits中,并对应的在训练过程中将原语义token序列按组进行划分。通过这种方式,模型能够在自回归过程的每步中同时处理多个音频tokens,从而加速语音生成并极大地降低训练和推理的成本。模型的训练目标可以表示为文本层和音频层交叉熵损失的加权和。
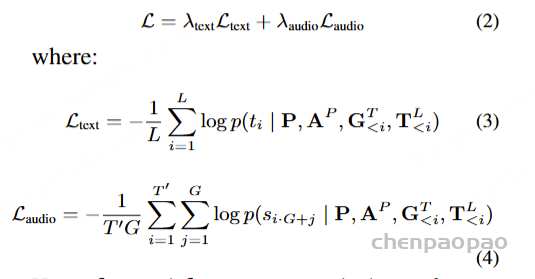
可控音色建模
SLAM-Omni通过将语音内容建模为语义tokens,天然地实现了音色与语言信息的解耦,将zero-shot音色控制从TTS扩展到了语音对话系统上。借鉴TTS模型(Cosyvoice)中的技术,SLAM-Omni使用条件流匹配模型将语义tokens和语者提示信息转换为mel频谱图,并通过HiFi-GAN合成波形。此外,为了支持实时语音生成,SLAM-Omni在流匹配的Transformer架构中采用了块因果注意力机制。
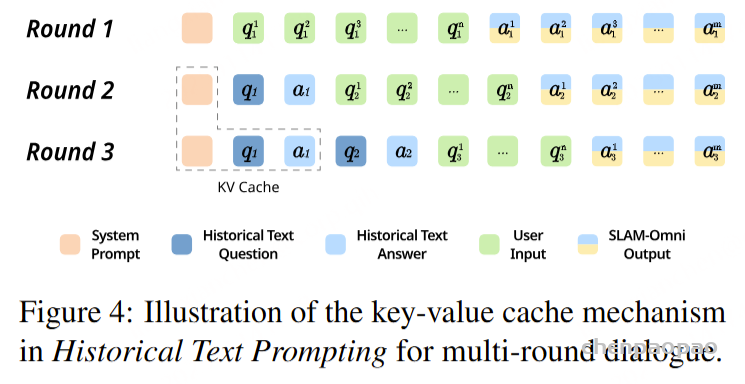
过去的语音对话模型在多轮对话建模上通常将文本和音频tokens交替作为历史,但较长的音频token序列显著提高了训练成本,限制了对话轮次。此外,较长的历史也会影响模型的上下文学习能力,并可能导致早期对话内容的遗忘。为了解决这些问题,SLAM-Omni引入“历史文本提示”(Historical Text Prompting)的方案,仅使用文本模态来表示对话历史。在多轮对话交互中,SLAM-Omni采用模板:<系统提示> <历史文本> <输入> <响应>。其中,系统提示指定模型角色和任务,历史提示则以文本形式存储过去的对话内容。这种方式与LLM的训练模式高度契合,同时避免了长音频序列建模的负担,使得模型能够在受限的上下文窗口内处理更多的对话轮次。在推理过程中,通过Whisper提取的语音特征可以解码成输入语音的转录文本,模型输出的文本tokens则通过分词器转换为文本。每轮对话中,由此得到的问题-响应文本对会被追加到历史对话中,以便下一轮使用。如图所示,第一轮语音对话的转录被纳入历史提示中,第二轮推理时计算得到的KV键值缓存可以在第三轮及以后的对话中复用,从而提高多轮推理的效率。
单阶段训练
此前的端到端语音对话模型通常需要进行模态适配、模态对齐和有监督微调等多阶段训练,这不仅需要精细的训练策略,还涉及多个超参数的调整,带来了显著的时间和计算成本。而SLAM-Omni通过简化为单阶段微调训练,能够在较小的数据集上快速收敛,展现了高效的训练效果。在我们的实验探索中,TTS和ASR的预训练都展示了快速的损失收敛,表明我们的方法无需大规模的模态对齐预训练。同时,进一步的实验还揭示,预训练实际上可能对模型的指令跟随能力和预训练知识保留产生负面影响。
实验设置
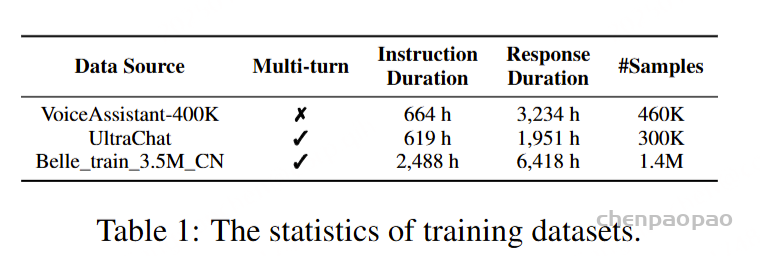
由于大多数开源的对话数据集仅为文本格式,我们通过zero-shot TTS系统合成语音对话语料。具体而言,我们使用CosyVoice模型生成用户输入的语音,同时随机从音色库中抽取语者提示,以控制音色。对于语音响应,我们使用CosyVoice模型生成语义tokens,它们在SLAM-Omni训练过程中作为目标音频tokens使用。我们使用的训练数据集包括VoiceAssistant-400K、英语多轮数据集UltraChat和中文对话数据集Belle_train_3.5M_CN。为了确保数据质量,我们清理了数据中的书面体(如表情符号、URL等),并限制了语音问题和响应的时长,以更好地模拟自然对话场景。在SLAM-Omni的主要实验中,仅使用VoiceAssistant-400K数据集,其他数据集则用于补充实验,评估模型在多轮和多语言对话任务中的表现。
对于用户输入,采用CosyVoice-300M模型来产生相应的语音。声音音色是通过从音色库中随机采样扬声器提示来控制的,该音色库包含来自seed-tts-eval3的1007个英语和1010个中文人类音频提示。对于助理响应,我们使用 CosyVoice-300M-SFT 的文本到令牌 LLM 来生成语义令牌,这些令牌在 SLAM-Omni 训练期间用作目标音频令牌
在训练和推理过程中,为确保在低资源环境下的公平比较,我们使用Qwen2-0.5B作为LLM骨干,并选择Whisper-small作为语音编解码器。在主要实验中,SLAM-Omni采用的语义分组大小为G = 3。在单阶段训练中,SLAM-Omni进行全量微调,只有Whisper编码器保持冻结。整个训练过程大约需要在4个A100 GPU上进行15小时。
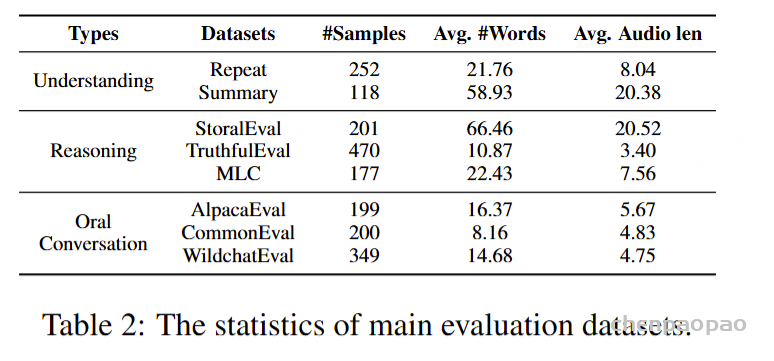
为了全面评估语音对话模型的语音交互能力,本文提出了一个新的评测框架,涵盖理解、推理和口语对话三个关键环节。通过设计八个测试集,我们分别从这三方面考察模型的表现。在“理解”部分,评估模型是否能够理解并跟随用户指令;在“推理”部分,通过逻辑、数学和常识问题测试模型的推理能力;而在“口语对话”部分,我们测试模型在开放式对话场景下的交互能力。评估指标包括内容质量(通过ChatGPT评分)、语音质量(通过UTMOS评分)以及语音与文本的一致性(通过WER评分)。
实验结果
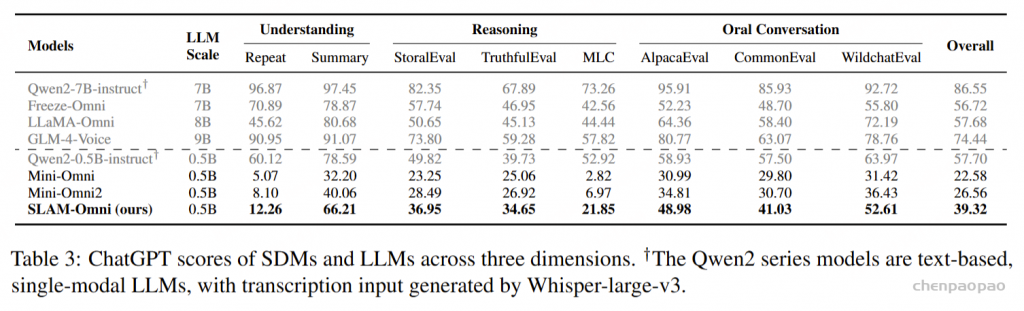
实验结果表明,SLAM-Omni在低资源场景下的表现超越了同规模的语音对话模型,在语音内容、音频质量和语音-文本一致性上显著提升,特别是在UTMOS和ASR-WER评分上表现突出,显示出其在音频建模方面的优势。在ChatGPT评测中,尽管和更大规模的模型相比仍存在差距,SLAM-Omni在理解、推理和口语对话能力上显著超越了同规模的Mini-Omni系列,表明其保留了更多的预训练LLM知识和指令跟随能力。
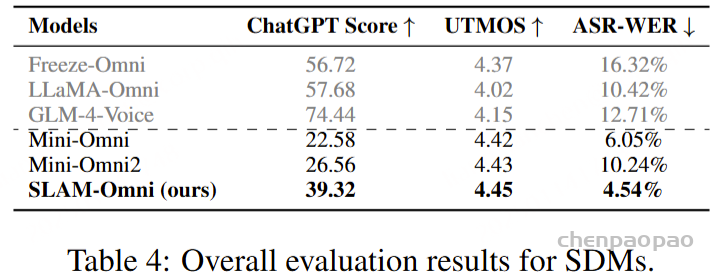
在音频质量和语音-文本一致性上,SLAM-Omni的表现优于所有其他语音对话模型,特别是在ASR-WER指标上,表明其语音-文本对齐更加紧密。而其他模型在生成过程中容易出现生成音频与文本不对齐的情况,尤其在长内容生成时,容易出现音频中断或长时间的静默,导致其UTMOS和ASR-WER评分较低。
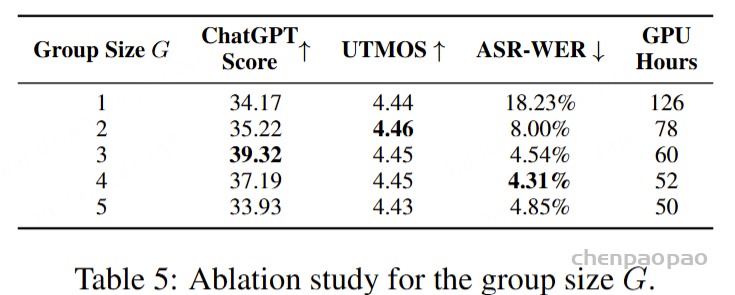
消融实验表明,语义分组建模显著提高了生成语音与文本的对齐度,尤其当组大小G≥3时,ASR-WER低于5%,相比之下,没有执行分组算法的模型(G=1)的ASR-WER高达18.23%。这一差距主要来源于音频和文本token之间的频率不匹配。通过减少音频序列长度,语义分组建模有效缓解了这一问题,同时减少了训练和推理成本,并加速了音频生成,提供了更流畅的用户体验。
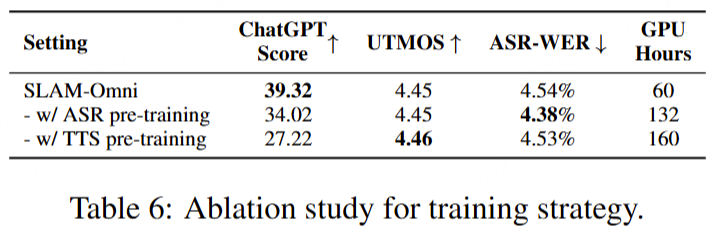
关于训练策略的消融实验表明,传统的多阶段训练方法虽然能略微提高模型的音频-文本对齐度,但在语音交互任务上的整体表现并未显著改善。相比之下,SLAM-Omni采用单阶段训练策略,显著提高了ChatGPT评分,并保持了相当的音频质量。通过直接在语音到语音数据上进行单阶段微调,SLAM-Omni能够更好地保留预训练LLM的知识,避免了传统预训练任务带来的知识流失问题,提高了训练效率。
附录:
Pre-training Details
对于ASR和TTS预训练,专门使用VoiceAssistant-400K数据集来确保一致性并避免引入外部数据。在 ASR 预训练期间,提供语音指令作为输入,其相应的转录文本作为目标输出。相反,对于 TTS 预训练,语音响应的转录被用作输入文本,而相应的语义token被设置为预测目标。优化和学习策略与微调期间采用的策略一致,值得注意的是,在 ASR 预训练期间仅计算文本层损失,而 TTS 预训练专门关注多层音频损失作为训练目标。
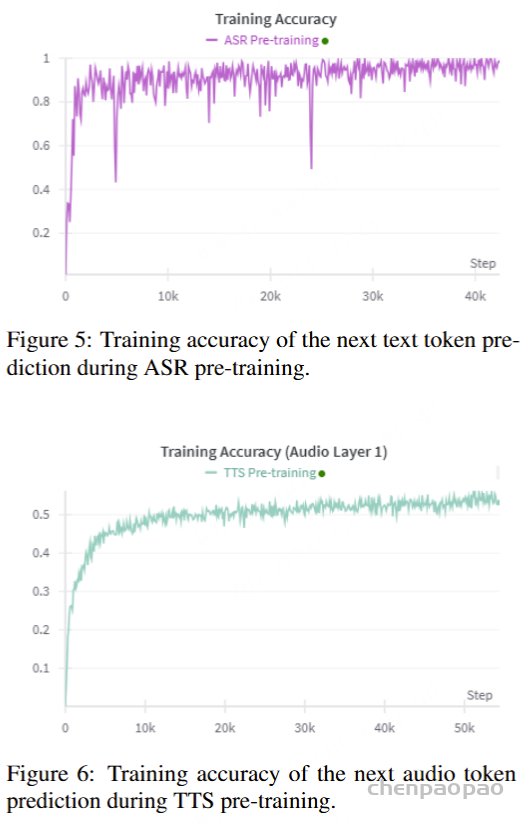
曲线显示,ASR 和 TTS 任务都实现了快速收敛,证明了模型在短时间内有效“理解”和“生成”语音的能力。这一观察表明,理解和生成任务中的模态对齐本质上是简单的,需要最少的预训练工作。此外,如表 6 所强调的,直接对语音到语音任务进行训练可以产生卓越的性能,同时减轻通常与预训练相关的知识退化。
总结
本文提出了SLAM-Omni,一种单阶段训练下支持可控音色的端到端语音对话模型。通过语义分组建模,SLAM-Omni有效地对齐了音频和文本模态,同时加速了训练和推理过程。采用有监督的语义tokens解耦说话人信息,使得SLAM-Omni实现zero-shot音色控制。为了解决长音频历史带来的问题,我们引入了历史文本提示技术,将对话历史存储为文本,并通过键值缓存提高多轮推理效率。在少量数据训练仅仅60个GPU小时下,SLAM-Omni在文本相关能力上超越了同规模的语音对话模型,并在音质和语音-文本对齐方面表现优越。