
InspireMusic是由通义实验室开源的音乐生成技术,旨在打造一款集音乐生成、歌曲生成、音频生成能力为一体的开源AIGC工具包。
为研究者和开发者提供音乐/歌曲/音频生成模型的训练和调优工具及模型,方便优化生成效果;同时为音乐爱好者提供一个易于使用的文本生成音乐/歌曲/音频创作工具,可通过文字描述或音频提示来控制生成内容。
目前,InspireMusic已开源了音乐生成的训练和推理代码,支持通过简单的文字描述或音频提示,快速生成多种风格的音乐作品。
InspireMusic的文生音乐创作模式涵盖了多种曲风、情感表达和复杂的音乐结构控制,提供了极大的创作自由度和灵活性。未来计划进一步开放歌唱生成和音频生成的基础模型,欢迎研究者、开发者及用户积极参与体验和研发。该开源工具包为社区开发者提供了丰富的技术资源,支持从学术研究到产品开发的广泛应用。
🎶 主要特点
- 统一的音频生成框架:基于音频大模型技术,InspireMusic支持音乐、歌曲及音频的生成,为用户提供多样化选择;
- 灵活可控生成:基于文本提示和音乐特征描述,用户可精准控制生成音乐的风格和结构;
- 简单易用:简便的模型微调和推理工具,为用户提供高效的训练与调优工具。
🌟代码仓库
- GitHub 仓库:InspireMusic(https://github.com/FunAudioLLM/InspireMusic)
- Online Demo:ModelScope创空间:https://modelscope.cn/studios/iic/InspireMusic/summary
核心模型
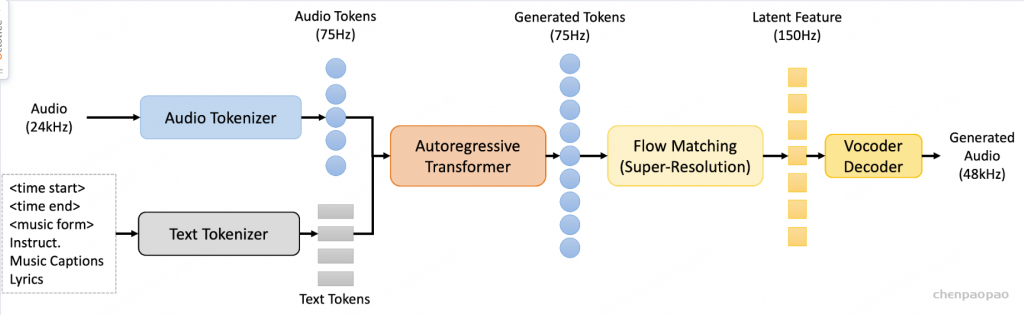
InspireMusic由音频tokenizer、自回归Transformer模型、基于常微分方程的扩散模型即Conditional Flow Matching (CFM)模型、Vocoder所组成,可支持文本生成音乐、音乐续写等任务。通过具有高压缩比的单码本WavTokenizer将输入的连续音频特征转换成离散音频token,然后利用基于Qwen模型初始化的自回归Transformer模型预测音频token,再由CFM扩散模型重建音频的潜层特征,最终通过Vocoder输出高质量的音频波形。两种推理模式的设计:fast模型和高音质模型,为不同需求的用户提供了灵活的选择。
工具包安装使用指南
第一步:下载代码库
git clone --recursive https://github.com/FunAudioLLM/InspireMusic.git # If you failed to clone submodule due to network failures, please run the following command until success cd InspireMusic git submodule update --init --recursive
第二步:安装代码库
conda create -n inspiremusic python=3.8 conda activate inspiremusic cd InspireMusic # pynini is required by WeTextProcessing, use conda to install it as it can be executed on all platforms. conda install -y -c conda-forge pynini==2.1.5 pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com # install flash attention to speedup training, support version 2.6.3 pip install flash-attn --no-build-isolation
第三步:下载模型
InspireMusic-Base模型(https://www.modelscope.cn/iic/InspireMusic)# git模型下载,请确保已安装git lfsmkdir -p pretrained_modelsgit clone https://www.modelscope.cn/iic/InspireMusic.git pretrained_models/InspireMusic-Base
第四步:基本用法说明快速开始
cd InspireMusic/examples/music_generation/bash run.sh
训练LLM和flow matching模型样例脚本。
torchrun --nnodes=1 --nproc_per_node=8 \
--rdzv_id=1024 --rdzv_backend="c10d" --rdzv_endpoint="localhost:0" \
inspiremusic/bin/train.py \
--train_engine "torch_ddp" \
--config conf/inspiremusic.yaml \
--train_data data/train.data.list \
--cv_data data/dev.data.list \
--model llm \
--model_dir `pwd`/exp/music_generation/llm/ \
--tensorboard_dir `pwd`/tensorboard/music_generation/llm/ \
--ddp.dist_backend "nccl" \
--num_workers 8 \
--prefetch 100 \
--pin_memory \
--deepspeed_config ./conf/ds_stage2.json \
--deepspeed.save_states model+optimizer \
--fp16
torchrun --nnodes=1 --nproc_per_node=8 \
--rdzv_id=1024 --rdzv_backend="c10d" --rdzv_endpoint="localhost:0" \
inspiremusic/bin/train.py \
--train_engine "torch_ddp" \
--config conf/inspiremusic.yaml \
--train_data data/train.data.list \
--cv_data data/dev.data.list \
--model flow \
--model_dir `pwd`/exp/music_generation/flow/ \
--tensorboard_dir `pwd`/tensorboard/music_generation/flow/ \
--ddp.dist_backend "nccl" \
--num_workers 8 \
--prefetch 100 \
--pin_memory \
--deepspeed_config ./conf/ds_stage2.json \
--deepspeed.save_states model+optimizer
推理脚本
cd InspireMusic/examples/music_generation/ bash infer.sh
带有CFM的推理模式
pretrained_model_dir = "pretrained_models/InspireMusic/"
for task in 'text-to-music' 'continuation'; do
python inspiremusic/bin/inference.py --task $task \
--gpu 0 \
--config conf/inspiremusic.yaml \
--prompt_data data/test/parquet/data.list \
--flow_model $pretrained_model_dir/flow.pt \
--llm_model $pretrained_model_dir/llm.pt \
--music_tokenizer $pretrained_model_dir/music_tokenizer \
--wavtokenizer $pretrained_model_dir/wavtokenizer \
--result_dir `pwd`/exp/inspiremusic/${task}_test \
--chorus verse \
--min_generate_audio_seconds 8 \
--max_generate_audio_seconds 30
done
不带CFM的fast推理模式
pretrained_model_dir = "pretrained_models/InspireMusic/"
for task in 'text-to-music' 'continuation'; do
python inspiremusic/bin/inference.py --task $task \
--gpu 0 \
--config conf/inspiremusic.yaml \
--prompt_data data/test/parquet/data.list \
--flow_model $pretrained_model_dir/flow.pt \
--llm_model $pretrained_model_dir/llm.pt \
--music_tokenizer $pretrained_model_dir/music_tokenizer \
--wavtokenizer $pretrained_model_dir/wavtokenizer \
--result_dir `pwd`/exp/inspiremusic/${task}_test \
--chorus verse \
--fast \
--min_generate_audio_seconds 8 \
--max_generate_audio_seconds 30
done