
- 技术报告:https://arxiv.org/abs/2502.11946
- 推理代码和模型权重Step-Audio-Chat, Step-Audio-TTS-3B 和 Step-Audio-Tokenizer
- Github:https://github.com/stepfun-ai/Step-Audio
- Step-Audio-AQAA: a Fully End-to-End Expressive Large Audio Language Model
- 技术详解:https://www.zhihu.com/question/12539093156/answer/105904691498
由阶跃星辰发布并开源的130B参数的语音大模型Step-Audio(跃问),具备实时对话、生成语音的风格控制(情感、方言、唱歌等),此外还具体工具调用、角色扮演的能力。
阶跃星辰:Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤),方言(如 粤语,四川话),可控制语速及韵律风格,支持RAP和哼唱等。其核心技术突破体现在以下四大技术亮点:
- 1300亿多模态模型: 单模型能实现理解生成一体化完成语音识别、语义理解、对话、语音克隆、语音生成等功能,开源千亿参数多模态模型 Step-Audio-Chat。
- 高效数据生成链路: 基于130B 突破传统 TTS 对人工采集数据的依赖,生成高质量的合成音频数据,并同步开源首个基于大规模合成数据训练,支持 RAP 和哼唱的指令加强版语音合成模型 Step-Audio-TTS-3B ,该模型具有增强的指令遵循功能以控制语音综合的能力。
- 精细语音控制: 支持多种情绪(如生气,高兴,悲伤)、方言(包括粤语、四川话等)和唱歌(包括 RAP、干声哼唱)的精准调控,满足用户对多样化语音生成的需求。
- 扩展工具调用: 通过 ToolCall 机制和角色扮演增强,进一步提升其在 Agents 和复杂任务中的表现。
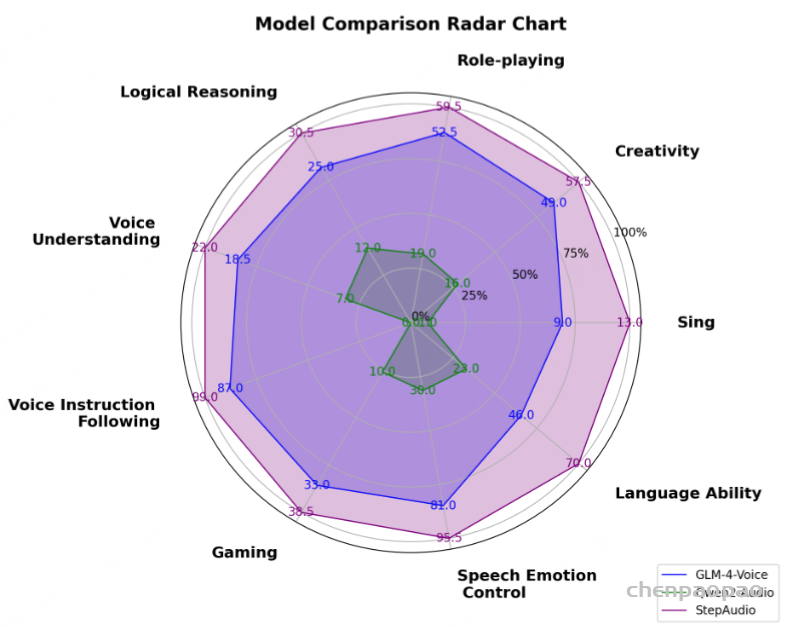
模型组成
Step-Audio的体系结构。 Step-Adio主要由三个组成部分组成:语音令牌,LLM和语音解码器。语音令牌器负责将输入语音离散到令牌中。LLM模型接收文本和语音令牌,输出文本,而语音解码器生成波形输出。
传统的语音对话系统通常采用包括ASR的级联建筑,LLM和TTS模块。但是,我们提出的模型在训练阶段进行了全面的多模式培训以及对文本和音频的一致性,已经具有端到端的语音对话功能。尽管对替代设计进行了广泛的探索,但我们最终采用了AQTA(音频输入,文本输出) + TTS框架 进行实时语音对话,如图2所示,这是由以下考虑的驱动的:
- 高质量的纯净对话数据的稀缺性:纯净对话数据的可用性有限,再加上其受限的场景,限制了端到端语音对话模型的训练效率。
- 输出语音的可控性和自定义:通过引入TTS模块,我们可以灵活地控制语音参数,例如音色和音调,以满足用户的个性化需求,同时不断增强模型的表现力能力。
在Step-Audio系统中,音频流采用Linguistic tokenizer【语义】(码率16.7Hz,码本大小1024)与Semantice tokenizer【声学】(码率25Hz,码本大小4096)并行的双码本编码器方案,双码本在排列上使用了2:3时序交错策略。通过音频语境化持续预训练和任务定向微调强化了130B参数量的基础模型(Step-1),最终构建了强大的跨模态语音理解能力。为了实现实时音频生成,系统采用了混合语音解码器,结合流匹配(flow matching)与神经声码技术。此外,采用语音活动检测(VAD)模块提取声段。
Tokenizer
语言分词器用于提取结构化的高级表征,包括音素和语言特征;而语义分词器则用于编码语义和粗粒度的声学特征。
我们通过token级交错方法实现Linguistic token与Semantic token的有效整合。Linguistic tokenizer的码本大小是1024,码率16.7Hz;而Semantic tokenizer则使用4096的大容量码本来捕捉更精细的声学细节,码率25Hz。鉴于两者的码率差异,我们建立了2:3的时间对齐比例——每两个Linguistic token对应三个Linguistic token形成时序配对。
linguistic tokenization 利用 Paraformer 编码器的输出,该输出以 16.7 Hz 【60ms一帧】 的token 速率量化为离散表示。对于语义标记化,采用 CosyVoice的 tokenization ,该 tokenization 专门设计用于高效编码生成自然且富有表现力的语音输出所必需的特征,以 25 Hz 的标记速率运行。
语言模型
为了提升Step-Audio有效处理语音信息的能力,并实现精准的语音-文本对齐,我们在Step-1(一个拥有1300亿参数的基于文本的大型语言模型LLM)的基础上进行了音频持续预训练。
在多轮对话系统中,音频令牌和文本令牌之间的长度差异需要有效的处理策略。为了解决这个问题,历史信息最初是在系统输入之前使用ASR模型转录为文本格式的,从而优化了计算效率。但是,应注意的是,该模型架构保留了在需要时处理和利用音频标记作为历史上下文的能力。
语音解码器
Step-Audio语音解码器主要是将包含语义和声学信息的离散标记信息转换成连续的语音信号。该解码器架构结合了一个30亿参数的语言模型、流匹配模型(flow matching model)和梅尔频谱到波形的声码器(mel-to-wave vocoder)。为优化合成语音的清晰度(intelligibility)和自然度(naturalness),语音解码器采用双码交错训练方法(dual-code interleaving),确保生成过程中语义与声学特征的无缝融合。
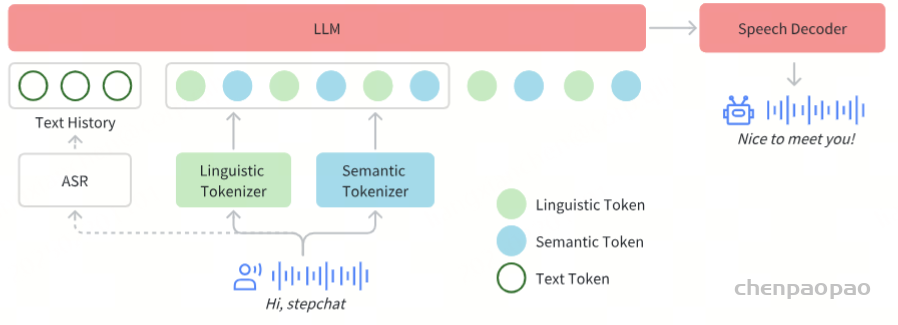
实时推理管线
为了实现实时的语音交互,我们对推理管线进行了一系列优化。其中最核心的是控制模块(Controller),该模块负责管理状态转换、协调响应生成,并确保关键子系统间的无缝协同。这些子系统包括:
- 语音活动检测(VAD):实时检测用户语音起止
- 流式音频分词器(Streaming Audio Tokenizer):实时音频流处理。输入音频流是通过两个平行的令牌管道处理的,每个管道都采用固定持续分段。将所得令牌无缝合并为2:3交织比的单个序列。如果没有流音频令牌,根据音频输入的长度,推理时间将明显较慢。
- Step-Audio语言模型与语音解码器:多模态回复生成
- 上下文管理器(Context Manager):动态维护对话历史与状态。我们的系统利用文本转录而不是原始的音频令牌来实现历史上下文,因为它提供了更紧凑的表示(平均文本审计代币比率为1:14),提高性能,并启用更长的对话,对质量的影响最小的影响很小。 ASR异步将用户语音转录为文本,并保持准确,最新的对话历史记录。
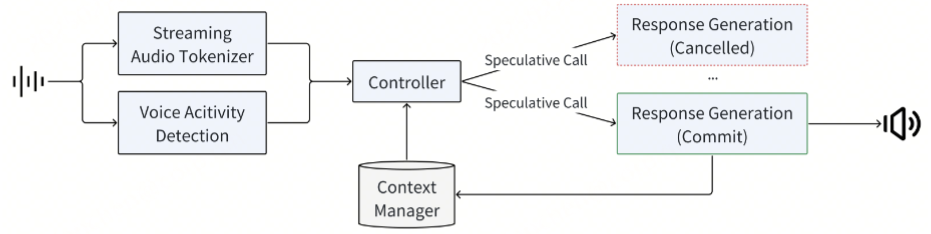
为了减少交互延迟,系统会预先生成推测响应。这最大限度地减少了感知延迟并增强了响应速度,但代价是丢弃推测响应时偶尔会产生冗余计算。系统初始状态为 Silence ,等待用户输入。当语音激活检测 (VAD) 检测到活动语音时,系统将转换到 UserSpeaking 状态。在此状态下,流音频标记器 (Streaming Audio Tokenizer) 开始将音频转换为标记。如果用户短暂暂停,系统将进入 UserPaused 状态,并触发推测响应生成。通过预先生成响应以预期输入完成,系统可以在对话恢复时减少延迟。如果用户继续说话,则丢弃推测响应。一旦系统确信用户已结束说话,它将转换到 BotReplying 状态,提交最新的推测响应并输出其音频。如果被用户语音打断,系统将优先处理新的输入,同时保持对话的连续性。完成响应后,系统返回静默状态,准备进行下一次交互。经验分析表明,大约 40% 的推测响应能够成功提交。与非推测方法相比,此机制可将每次响应的延迟缩短约 500 毫秒。
数据集:
多模态预训练数据集整合了音频、文本、图像三大类数据资源。音频部分包含 1.1 万亿个音频连续数据(约 730 万小时)、1130 亿个 TTS(文本转语音)合成语音数据(约 70 万小时)、1050 亿个 ASR(自动语音识别)数据(约 65 万小时)和 3500 亿个音文交替数据(约 200 万小时)。文本数据总计 8000 亿个,涵盖网页文档、书籍、代码和专有资料。图像部分包含 8000 亿个图文配对/交替数据,来源于网页、书籍和专有资源。
三阶段训练
阶段 1:我们通过添加 5,120 个音频 token 来扩展预训练文本模型的词汇量,并集成预训练图像编码器,形成 Step-Omni 模型。在训练过程中,为了最大程度地降低文本模型能力的损失,文本模型主干网络的学习率始终保持在较低水平 (2e-5)。然而,嵌入和语言模型 (LM) 头的学习率设置为主干网络的五倍,以促进新添加 token 的更快收敛。同时,图像编码器在整个训练过程中保持冻结状态。在此阶段,音频、文本和图像数据的使用比例为 2:1:1,音频数据仅由纯音频延续任务组成。
Stage2:在 Stage1 阶段使用 1.2T 个 token 进行训练后,我们将音频文本交错数据纳入进一步训练,音频后续数据与音频文本交错数据的比例为 1:1。在此阶段,音频、文本和图像数据的比例仍为 2:1:1。
阶段 3:在阶段 2 阶段使用 800B token进行训练后,我们将 ASR 和 TTS 数据纳入进一步训练。音频连续数据、音文交织数据、ASR 数据和 TTS 数据的比例设置为 1:1:1:1。在此阶段,音频、文本和图像数据的比例调整为 4:3:3。此外,嵌入层和 LM 头的学习率与主干网络同步,采用余弦算法,学习率从 2e-5 递减至 5e-6。
后训练细节
在后训练阶段,我们针对自动语音识别(ASR)与文本转语音(TTS)任务进行了专项监督微调(Supervised Fine-Tuning, SFT)。对于音频输入-文本输出(Audio Question Text Answer, AQTA)任务,我们采用多样化高质量数据集进行SFT,并采用了基于人类反馈的强化学习(RLHF)以提升响应质量,从而实现对情感表达、语速、方言及韵律的细粒度控制。
TTS模型:
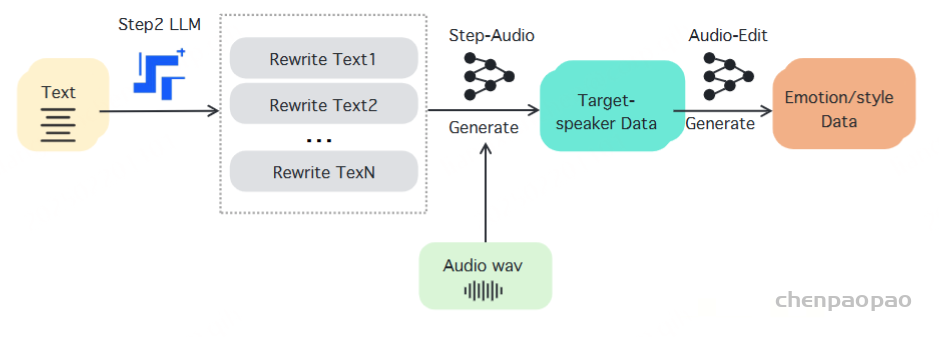
Training Detail:
与传统的语音合成(TTS)系统注重对说话人特征、情感表达、语言特征和风格元素的精细控制不同,我们的方法采用了基于聊天的范式和大型语言模型(LLMs)的训练方法。这一战略对齐显著增强了系统的灵活性,同时建立了一个可扩展的框架,以支持未来模型和数据的扩展,从而解决了语音合成系统在可扩展性方面的关键挑战。
监督的微调格式:
SFT格式包括三个基本组成部分:系统提示、人类输入和助手回复,采用两轮对话结构。在这种格式中,系统提示作为指定说话人属性和定义支持的指令标签的基础元素。人类输入和助手回复部分则专门用于处理文本内容和双词典表示。第一轮的文本和音频标记可以用来保持领域内说话人的音色和风格一致性,同时也支持领域外的零样本克隆。
指令标签 :
指令标签分为两种不同的类别:描述性标签和比较性标签。描述性标签用于控制语言、方言、声音和风格等方面,而比较性标签则用于情感和语速控制的层次化区分。描述性标签的数据是通过Step-Audio模型克隆生成的,支持包括日语、韩语、粤语、四川方言、可爱声音、说唱和唱歌等语言和风格。比较性标签的数据则是通过Audio Edit模型生成的,支持诸如快乐、愤怒、悲伤等情感,以及快慢等语速变化,每种变化都被分为五个层级。
我们使用第5.1.1节中概述的SFT数据,并采用一个具有30亿参数的模型,训练一个周期,初始学习率为 2×10−5。学习率采用余弦衰减策略进行调整,最低值设置为 2×10−6。
AQTA:
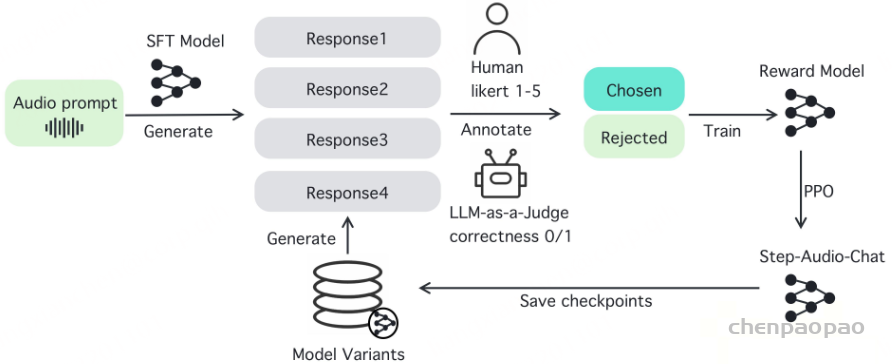
我们为AQTA任务应用了基于人类反馈的强化学习(RLHF),从而创建了Step-Audio-Chat模型,如图6所示。
Exploring Tokenizer for Audio Pretraining
研究了使用单码本的训练方法。在实验中,我们发现,当仅使用语义分词训练模型时,下一个分词的预测困惑度相对较低,并且生成内容与前文的语义一致性良好。然而,由于丢弃过多语义分词会导致声学信息大量丢失,后续通过声码器进行的音频恢复在音色和韵律方面会严重受损,导致听觉质量不佳。当仅使用语言分词进行训练时,声码器从模型的后续部分恢复的音频听起来不错,但下一个分词的预测困惑度非常高,并且后续部分与前文的语义一致性较差。
当使用交错的语义标记和语言标记进行训练时,语义标记确保了后续内容与前一上下文的语义一致性,而语言标记则确保了重建音频的听觉质量。由于语义标记和语言标记之间的相互参考,我们观察到当使用双码本训练时,与使用单码本相比,语义标记和语言标记的下一个标记预测困惑度都有所降低。
将语言离散标记和语义离散标记按 2:3 的比例分组交织,有助于加快训练损失的收敛速度。更重要的是,将语言标记扩展至 CosyVoice 语义标记,增强了模型理解和遵循多轮历史指令的能力,并有效缓解发音不清、吐字不清等问题,显著提升了 CosyVoice 单码性能。
说明:
用了AQTA(音频输入,文本输出) + TTS框架 情况下是如何实现多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤),方言(如 粤语,四川话),可控制语速及韵律风格,支持RAP和哼唱 ?
通过TTS【cosyvoice】代码可知,LLM的文本输出中会包含 {语言}【情感】 [语速] 这样的文本输出,然后TTS用于合成对应的音频: 使用[{}]的声音,根据这些情感标签的指示,调整你的情感、语气、语调和哼唱节奏
self.sys_prompt_dict = {
"sys_prompt_for_rap": "请参考对话历史里的音色,用RAP方式将文本内容大声说唱出来。",
"sys_prompt_for_vocal": "请参考对话历史里的音色,用哼唱的方式将文本内容大声唱出来。",
"sys_prompt_wo_spk": '作为一名卓越的声优演员,你的任务是根据文本中()或()括号内标注的情感、语种或方言、音乐哼唱、语音调整等标签,以丰富细腻的情感和自然顺畅的语调来朗读文本。\n# 情感标签涵盖了多种情绪状态,包括但不限于:\n- "高兴1"\n- "高兴2"\n- "生气1"\n- "生气2"\n- "悲伤1"\n- "撒娇1"\n\n# 语种或方言标签包含多种语言或方言,包括但不限于:\n- "中文"\n- "英文"\n- "韩语"\n- "日语"\n- "四川话"\n- "粤语"\n- "广东话"\n\n# 音乐哼唱标签包含多种类型歌曲哼唱,包括但不限于:\n- "RAP"\n- "哼唱"\n\n# 语音调整标签,包括但不限于:\n- "慢速1"\n- "慢速2"\n- "快速1"\n- "快速2"\n\n请在朗读时,根据这些情感标签的指示,调整你的情感、语气、语调和哼唱节奏,以确保文本的情感和意义得到准确而生动的传达,如果没有()或()括号,则根据文本语义内容自由演绎。',
"sys_prompt_with_spk": '作为一名卓越的声优演员,你的任务是根据文本中()或()括号内标注的情感、语种或方言、音乐哼唱、语音调整等标签,以丰富细腻的情感和自然顺畅的语调来朗读文本。\n# 情感标签涵盖了多种情绪状态,包括但不限于:\n- "高兴1"\n- "高兴2"\n- "生气1"\n- "生气2"\n- "悲伤1"\n- "撒娇1"\n\n# 语种或方言标签包含多种语言或方言,包括但不限于:\n- "中文"\n- "英文"\n- "韩语"\n- "日语"\n- "四川话"\n- "粤语"\n- "广东话"\n\n# 音乐哼唱标签包含多种类型歌曲哼唱,包括但不限于:\n- "RAP"\n- "哼唱"\n\n# 语音调整标签,包括但不限于:\n- "慢速1"\n- "慢速2"\n- "快速1"\n- "快速2"\n\n请在朗读时,使用[{}]的声音,根据这些情感标签的指示,调整你的情感、语气、语调和哼唱节奏,以确保文本的情感和意义得到准确而生动的传达,如果没有()或()括号,则根据文本语义内容自由演绎。',
}