
OSUM: Advancing Open Speech Understanding Models with Limited Resources in Academia
- 技术报告v2版:https://www.arxiv.org/pdf/2501.13306v2
- 项目页面:https://github.com/ASLP-lab/OSUM
- 测试体验页面:https://huggingface.co/spaces/ASLP-lab/OSUM
大型语言模型(LLMs)在各种下游任务中取得了显著进展,启发了业界对语音理解语言模型(speech understanding language models, SULMs)的研发,以期实现基于语音情感、性别等副语言的高表现力交互。然而,大多数先进的SULM是由行业头部公司开发的,消耗大规模的数据和计算资源。而这些资源在学术界并不容易获得。此外,虽然训练好的模型和推理代码被开源了,但训练框架和数据处理流程依然缺乏透明度,这也为进一步研究产生了障碍。在本研究中,我们提出了OSUM,一个开放的语音理解模型,旨在探索在有限的学术资源下训练SLUM的潜力。OSUM模型将Whisper编码器与Qwen2 LLM相结合,支持广泛的语音任务,包括语音识别(ASR)、带时间戳的语音识别(SRWT)、语音事件检测(VED)、语音情感识别(SER)、说话风格识别(SSR)、说话者性别分类(SGC)、说话者年龄预测(SAP)和语音转文本聊天(STTC)。通过采用ASR+X训练策略,OSUM通过同时优化模态对齐和目标任务,实现了高效稳定的多任务训练。除了提供强大的性能,OSUM还强调透明度,提供公开可用的代码,并详细介绍了数据处理流程,以期为学术界提供有价值的参考,旨在加速先进SULM技术的研究和创新。
方案设计
OSUM模型将Whisper编码器与Qwen2 LLM相结合,支持广泛的语音任务,包括语音识别(ASR)、带时间戳的语音识别(SRWT)、语音事件检测(VED)、语音情感识别(SER)、说话风格识别(SSR)、说话者性别分类(SGC)、说话者年龄预测(SAP)和语音转文本聊天(STTC)。通过采用ASR+X训练策略,OSUM通过同时优化模态对齐和目标任务,实现了高效稳定的多任务训练。
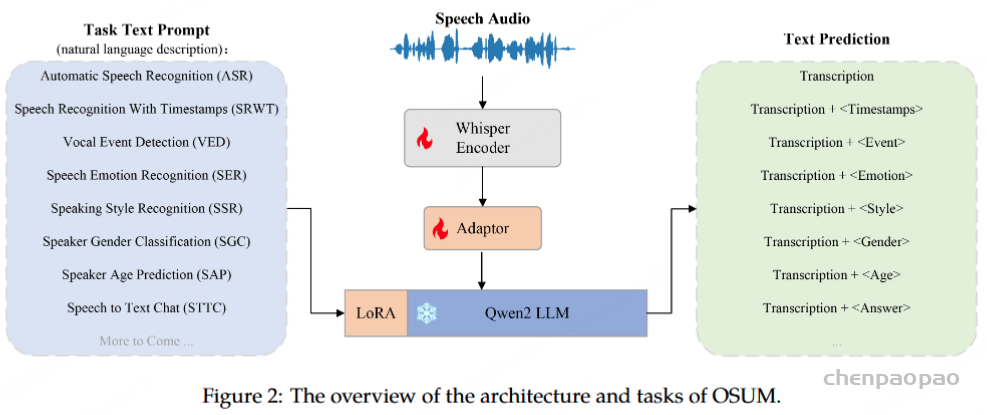
模型结构
模型的输入包括语音和自然语言提示。不同于 Whisper 和Qwen-Audio 依靠指令标签,Osum采用描述性文本,将所有八个支持任务转换为图2所示。当前,我们的模型仅支持基于文本的响应,但是音频输出功能正在积极开发。
如图2所示,OSUM模型由一个Speech Encoder、一个Adaptor和一个LLM组成。在训练过程中,Speech Encoder和Adaptor中的所有参数都会更新,而大语言模型则使用LoRA方法进行微调。各部分具体配置如下:
- Speech Encoder: Whisper-Medium (769M);
- Adaptor: Conv1D * 3 + Transformer * 4,4倍下采样;
- LLM: Qwen2-7B-Instruct带LoRA。LoRA hyperparameters-α, rank, and dropout ratio are set to 32, 8, and 0.1,
多任务监督训练
训练过程包括两个阶段:
首先,在没有LLM的情况下,对原始的Whisper模型进行多任务监督微调,多任务数据微调了 Whisper ,以确保OSUM模型的更快收敛。此外,此阶段使我们能够验证多任务数据的可靠性。具体来说,我们扩展了Whisper的指示标签,以适应更多的任务,每个前向推理仅执行一个任务。
其次,将微调后的Whisper编码器与Qwen2大语言模型相结合,构建出完整的OSUM系统,然后使用更大的数据集进行进一步的监督训练。
OSUM模型的输入包括一段语音和一个自然语言描述的prompt,而输出在现阶段仅支持文本回复,音频输出功能正在开发中。为节省计算资源,OSUM的多任务训练引入了一种“ASR+X”范式,即同时训练ASR任务和一个附加任务X。这在加速训练的同时,允许执行X任务时参考文本和声学两种特征,从而提升性能和训练稳定性。“ASR+X”范式是在LLM的自回归框架内通过调整预测标签来实现的,无需对模型架构或损失函数进行修改。执行不同的X任务是通过给LLM不同的自然语言prompt来实现的,每个任务有5个候选prompt,训练时随机选择一个。prompt的示例如表1所示。

训练数据
OSUM旨在使用多样化的语音数据集进行多任务训练,目标是构建一个能够在对话场景中全面理解输入语音的统一模型。多任务训练过程使各个任务能够从共享学习中获益,从而提升模型的整体性能。有关用于训练的数据集的详细信息见表2所示,本版本模型的训练数据规模大约为5万小时。

技术性能
总览
如图2所示,OSUM 模型和Qwen2-Audio 相比,在大多数任务中,尽管 OSUM 使用的计算资源和训练数据明显更少,但它的表现优于Qwen2-Audio。
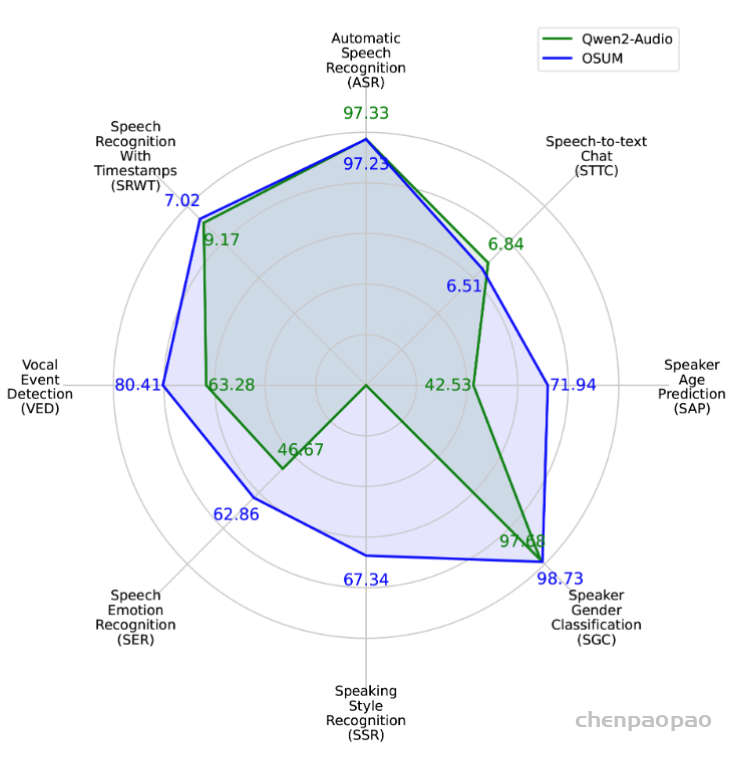
图2 OSUM与Qwen2-Audio各项任务性能对比的雷达图。雷达图中每个模型各项任务的值是基于公开测试集和内部测试集的平均结果得出的
各项指标与性能演示
ASR(语音识别):如表4所示,OSUM在中文ASR上表现优越,具体地,在WenetSpeech test meeting、3个AISHELL-2子测试集以及4个内部使用的SpeechIO测试集上优于其他模型。OSUM在英语测试集上性能也可与SenseVoice-S相媲美。值得注意的是,这些结果是在使用少得多的训练数据的情况下取得的。此外,我们发现,即使在训练过程中未纳入中英混语料数据集,OSUM在识别中英混语音方面也展现出了令人惊讶的出色能力。
表4公开测试集和内部测试集上ASR任务的评估结果。加粗字体表示同一测试集中的最佳结果。所有内部测试结果均由我们自行推理得出
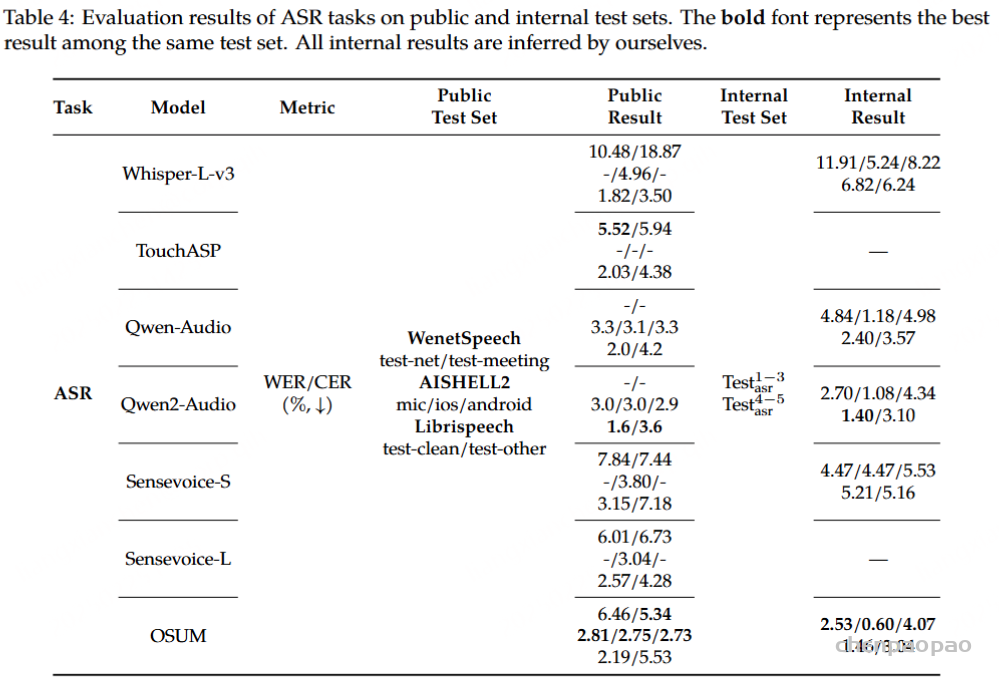
表45公开测试集和内部测试集上多任务的评估结果。每个测试集的最佳结果都用粗体突出显示。蓝色字体显示的结果以及内部测试集的结果,均是我们使用原始发布的模型自行推理得出的

SRWT(带时间戳的语音识别):如表5所示,OSUM模型在SRWT任务上的性能显著优于Whisper-Large-v3,相对优势达到了36.70%,并且也超过了Qwen-Audio。此外,OSUM的表现甚至略微超过了GMM-HMM模型,而后者在时间戳预测任务被广泛使用。另外,此功能不仅使得OSUM能够以端到端的方式预测时间戳,更重要的是,它引导OSUM模型理解了“时间”这一概念。在将来,我们将会利用这一能力继续开发更灵活的应用,例如判断音频中何时出现了语音事件,何时出现了说话人转换等。
VED(语音事件检测):我们首先在公开测试集ESC-50和VocalSound上评估OSUM的性能。ESC-50包含大量的非人声音频事件,我们将它们归类为“其他”。表45示的实验结果表明,OSUM可以成功地将这些非人声音频事件归类为“其他”。此外,在VocalSound数据集上的结果显示,OSUM与Qwen2-audio相比虽然存在一定差距,但也取得了超过80%的准确率。值得注意的是,为更加符合真实使用场景,我们的训练数据是语音和音频事件拼接而成,但公开测试集只有孤立的音频事件而没有说话语音。即便存在这一不匹配的情况,OSUM模型的在公开测试集上的结果也证明了其有效性和泛化性。与公开测试集不同,我们人工录制了同时包含语音和声学事件的内部测试集。表45结果表明,PANNs由于其仅为孤立音频事件检测而设计,在我们内部测试集中基本处于不可用状态。Qwen2-audio的表现相对较好,但也出现了性能下降。相比之下,OSUM模型在公开测试集和内部测试集上都取得了较为均衡的结果,展现出了更强的泛化能力。
SER(语音情感识别):如表45示,对于SER任务,使用公开数据集的实验中,OSUM在MER2023测试集上展现出了卓越的性能,超过了一些近期的公开基准模型。在MELD数据集上,OSUM的性能略低于SenseVoice-L模型,这很可能是因为后者在更大规模的语音情感数据集上进行了训练。此外,OSUM在内部测试集上的结果与EmoBox模型相当,显著优于其他对比方法。但是,我们也观察到,厌恶和恐惧这两种情感尤其难以识别,其归因于这两种情感的训练数据更加稀缺,也容易和其他情感混淆。
SSR(说话风格识别):表5中实验表明,OSUM所采用的声学-文本双模态风格分类方法的表现显著优于GLM-4-9B-Chat所采用的单文本模态方法,这充分证明了“ASR+X”策略的价值。现阶段OSUM能够区分八种风格:“新闻科普”,“恐怖故事”,“童话故事”,“客服”,“诗歌散文”,“有声书”,“日常口语”以及“其他”。我们详细分析了测试集上各类别的准确率,发现OSUM在对“新闻科普”、“有声书”、“童话故事”以及“客服”风格类别上表现出色;然而,在“诗歌散文”、“恐怖故事”类别上仍有提升空间。有趣的是,我们发现从实际测试的主观体验上来说,OSUM风格分类正确率是超过测试集的,总体来说可以让人满意。
SGC(说话者性别分类):在SGC公开测试集上的结果表明,OSUM在AISHELL-1测试集上达到了100%的准确率。这一结果在一定程度上表明该任务上存在说话人过拟合现象。此外,在Kaggle测试集上,我们的方法略优于Qwen2-Audio。但在我们的内部测试集上,OSUM的性能略低于Qwen2-Audio,但依然超过了95%。总之,OSUM在SGC任务上展现出了不错的性能,而且实测效果很少出现性别判断错误的情况。
SAP(说话者年龄预测):在SAP任务上,由于我们发现青少年和成年人的声学相似度非常高,这使得有效区分他们变得很复杂。因此,我们将年龄分为三类:儿童、成年人和老年人。尽管我们努力调试了prompt,但Qwen2-Audio在Kaggle测试集和我们的内部测试集上,年龄分类准确率都较低。这可能是因为这些模型对年龄的分类过于细致,从而影响了Qwen2-Audio模型的最终效果。表4中结果显示,OSUM在Kaggle测试集上显著优于Qwen2-Audio,达到了76.52%的准确率。在我们的内部测试集上OSUM分类准确率虽然略有下降,但仍然超过了Qwen2-Audio。这表明OSUM在不同的数据上表现出了很强的泛化能力。
STTC(语音转文本聊天):如表5所示,在STTC任务中,我们在所有测试集上都遵循了AirBench的评估协议。这包括提供音频查询的文本以及两个不同答案的文本,让基于文本的大语言模型(LLM)给出1到10的主观评分。这两个答案一个是真实回复,另一个是语音大语言模型(SULM)生成的答案。测试结果表明,在AirBench的官方speech子测试集上,OSUM的得分虽然低于Qwen2-Audio,但也处于一个合理范围。这主要是因为我们没有使用英语对话数据进行训练,目前的得分完全依赖于大语言模型自身的表现。反之,在我们内部的中文对话测试集上,OSUM的表现优于Qwen2-Audio,这充分证明了OSUM在中文对话任务上性能是不错的。总体而言,我们的OSUM模型在对话能力方面与Qwen2-Audio相当。
更多功能
OSUM理解大模型在将来会提供更多的功能,可作为通用语音打标工具使用。此外,我们正在开发的功能包括:
- 同时支持ASR+X和单X任务模式,在执行单X任务打标时推理速度更快。
- 同时输出ASR+X1+X2+..Xn的多任务打标模式,一次性提供几乎全部所需标签。
- 增加更多的理解任务。