- 论文题目:Dolphin: A Large-Scale Automatic Speech Recognition Model for Eastern Languages
- 论文链接:https://arxiv.org/abs/2503.20212
- Github:https://github.com/DataoceanAI/Dolphin
- Huggingface:https://huggingface.co/DataoceanAI
- Modelscope:https://www.modelscope.cn/organization/DataoceanAI
- OpenI启智社区:https://openi.pcl.ac.cn/DataoceanAI/Dolphin
- 支持的语种:https://github.com/DataoceanAI/Dolphin/blob/main/languages.md
在当今数字化时代,语音识别技术已成为人机交互的关键桥梁,广泛应用于智能客服、语音助手、会议转录等众多领域。然而,对于东方语言的识别如越南语、缅甸语等,现有模型往往表现不佳,难以满足用户的需求。为解决这一难题,海天瑞声携手清华大学电子工程系语音与音频技术实验室,共同推出了Dolphin —— 一款专为东方语言设计的语音大模型。
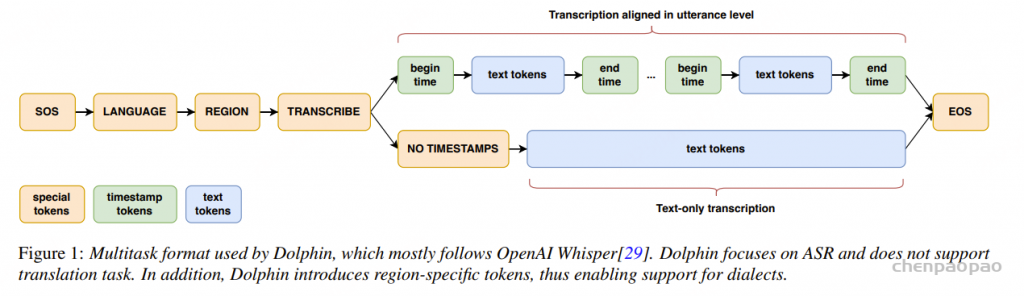
格式。Dolphin 专注于自动语音识别 (ASR),不支持翻译任务。此外,Dolphin 引入了特定区域的标记,从而支持方言。
Dolphin 是由 Dataocean AI 与清华大学合作开发的多语言、多任务 ASR 模型。它支持东亚、南亚、东南亚和中东地区的 40 种东方语言,同时还支持 22 种中国方言。该模型基于超过 21 万小时的数据进行训练,其中包括 DataoceanAI 的专有数据集和开源数据集。该模型可以执行语音识别、语音活动检测 (VAD)、语音分割和语言识别 (LID)。
二、创新技术架构
- 模型结构
Dolphin网络结构基于CTC-Attention架构,E-Branchformer编码器和Transformer解码器,并引入了4倍下采样层,以实现高效的大规模多语言语音识别模型的训练。CTC-Attention架构结合了CTC的序列建模能力和注意力机制的上下文捕捉能力,能够有效提升模型的识别准确性和效率。E-Branchformer编码器采用并行分支结构,能够更有效地捕捉输入语音信号的局部和全局依赖关系,为模型提供了更丰富的特征表示。解码器部分则采用了在序列到序列任务中表现出色的Transformer,能够生成高质量的文本输出。为了进一步提高训练效率和性能,我们在模型中引入了4倍下采样层。这一层可以减少输入特征的序列长度,从而加速计算过程,同时保留关键的语音信息,确保模型的识别效果不受影响。
- 多任务格式
Dolphin 借鉴了 Whisper 和 OWSM 的创新设计方法,但专注于ASR 进行了若干关键修改。Dolphin 不支持翻译任务,并且去掉了previous text及其相关标记的使用,这简化了输入格式并减少了潜在的复杂性。Dolphin引入了两级语种标签系统,以便更好地处理语言和地区的多样性。第一个标签指定语种(例如: <zh> 、 <ja>),第二个标签指定地区(例如 <CN> 、 <JP>)。 比如:<ru><RU> 表示俄罗斯的俄语,而 <ru><BY> 表示白俄罗斯的俄语。这种分层方法使模型能够捕捉同一种语言内不同方言和口音之间的差异,以及同一地区内不同语言之间的相似性,从而提高了模型区分密切相关的方言的能力,并通过在语言和地区之间建立联系增强了其泛化能力。
三、强大的数据基础
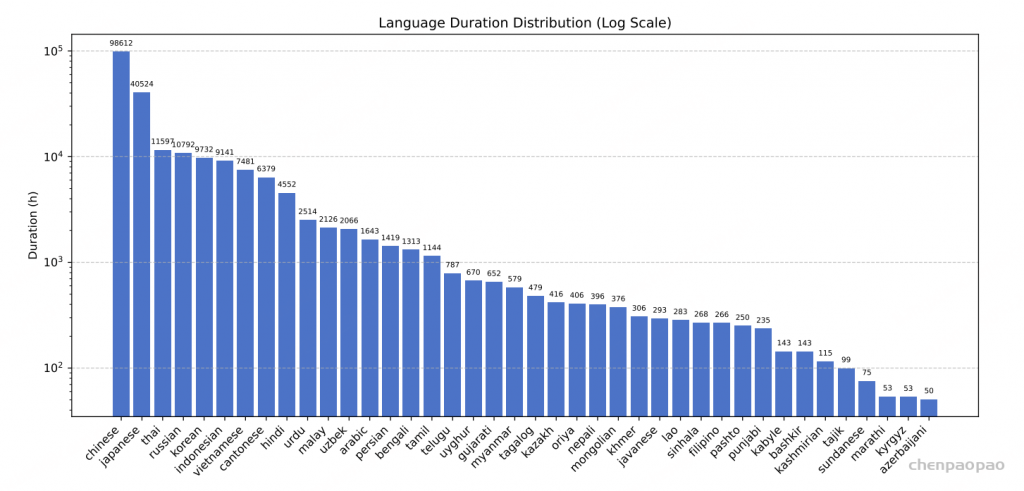
Dolphin的训练数据集整合了海天瑞声【Dataocean AI】的专有数据和多个开源数据集,总时长超过20万小时,涵盖40个东方语种。其中,海天瑞声数据集包含137,712小时的音频,覆盖38个东方语种。这些高质量、多样化的数据为模型的训练提供了坚实的基础,使其能够更好地适应不同语言和方言的语音特征。
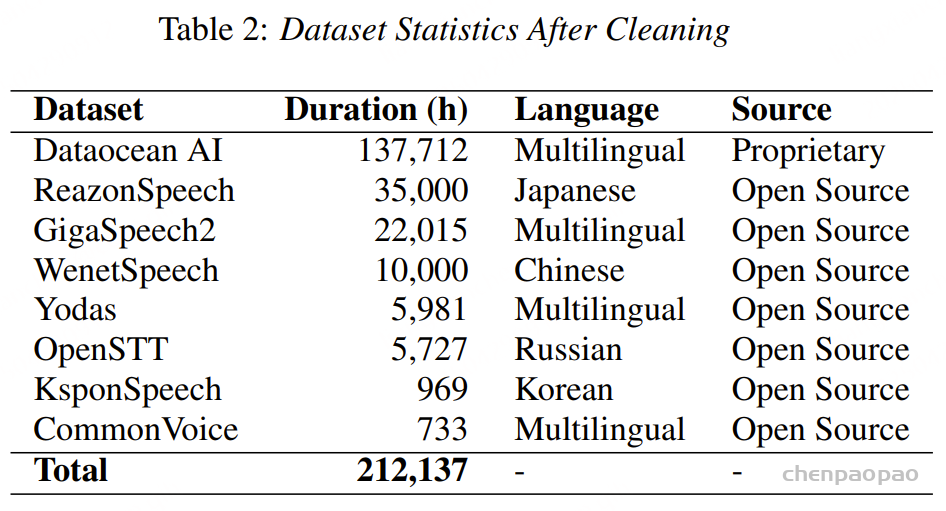
数据处理:对于像 YODAS 这样包含人工注释和 ASR 生成的转录本的数据集,我们只使用人工注释的部分。因此,我们的大部分训练数据都是手动转录的,以确保更高的转录质量。这种数据质量,尤其是转录本的质量,是使模型即使在模型规模较小的情况下也能实现显著优于 Whisper 识别性能的关键因素。对于时间戳,采用与 Whisper 相同的句子级时间戳方法,其中时间戳标记标记每个句子的起始和结束。对于长音频录音(通常长达几分钟),会在数据预处理过程中将其分割成较小的片段,然后将它们合并为长音频序列。
训练优化:
在训练数据的初始版本中,我们直接使用了清理后的数据集。然而,一个主要问题是短音频样本的比例过高。大多数音频片段的时长约为 5 秒,导致跨多种语言的删除错误率过高。这个问题与大多数训练数据由短音频样本组成这一事实相符。
为了解决这个问题,尝试了一种替代方法,将清理后的音频数据连接成 25-30 秒的长片段。这显著降低了较高的删除错误率。虽然这种方法导致插入错误率略有增加,但整体识别性能有所提升,平均字词错误率 (WER) 降低了 9.01%。
四、卓越性能表现
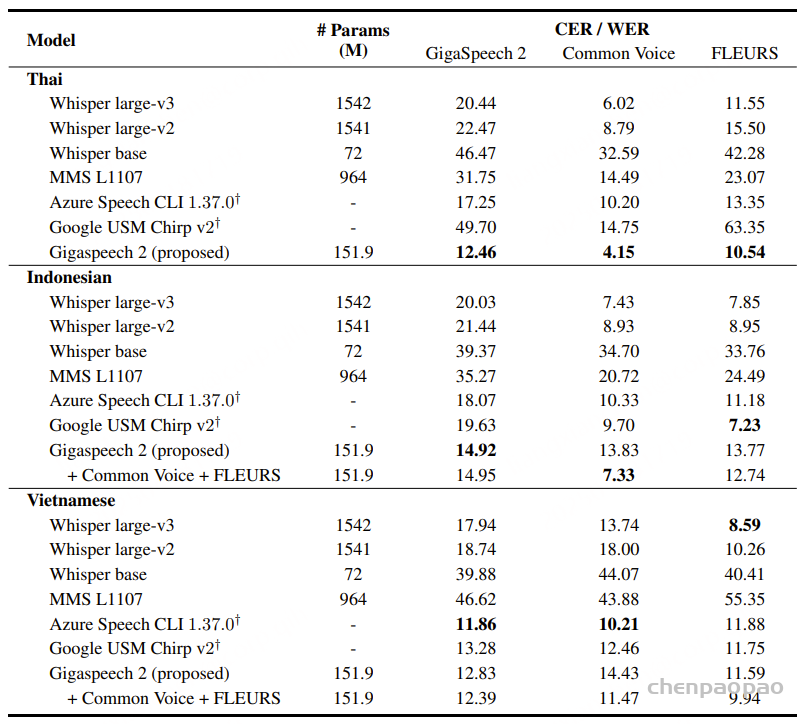
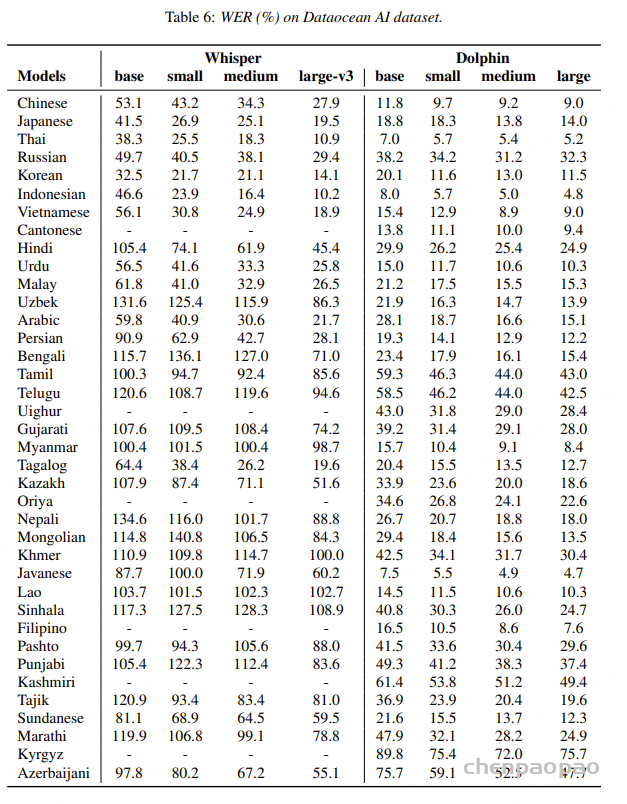
通过精心设计的架构和大规模的训练数据,Dolphin在多种语言上的词错误率(WER)显著低于现有开源模型。
例如,在海天瑞声数据集上,Dolphin 模型的平均WER为31.5%,small模型为24.5%,medium模型为22.2%;在CommonVoice数据集上,Dolphin 模型的平均WER为37.2%,small模型为27.4%,medium模型为25.0%。即使与Whisper large-v3模型相比,Dolphin在模型规模更小的情况下,性能也更为出色。以中文为例,Dolphin中模型的WER仅为9.2%,而Whisper large-v3模型为27.9%。 在KeSpeech (包含一个普通话子集和八个中国方言子集)测试集上,Dolphin模型表现出了卓越的效果.
五、技术挑战
内存占用问题
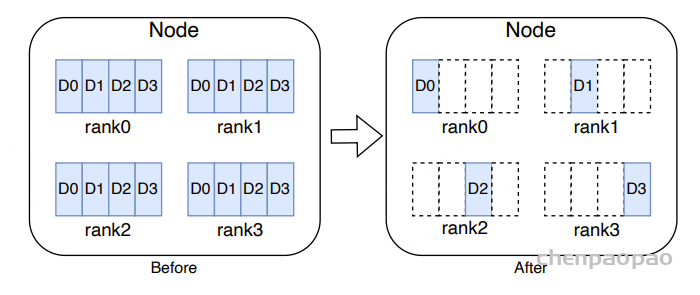
我们的训练集包含 1.6 亿条话语,在数据处理阶段遇到了内存不足 (OOM) 问题。我们对数据处理的 sampler、dataset、dataloader 模块进行了深入分析,发现大量的 utterances 导致了内存溢出。PyTorch 支持两种类型的数据集:map-style 和 iterable-style。ESPnet 使用的是 map-style。map-style 数据集将 utterance 的元数据(utterance id 与文本、音频的映射)加载到内存中,内存占用随着训练数据 utterances 的数量线性增长。为了提高数据加载速度,dataloader 内部会有多个 worker 进行数据预取,这进一步增加了物理机的内存占用,最终导致 OOM。
受 Zero-DP的启发,我们提出了图 3 中的数据分片策略。我们不再加载整个数据集副本,而是优化每个 Rank,使其仅加载数据集中必要的子集。这种方法显著减少了每个 Rank 的内存占用,从而降低了物理机上的整体内存消耗。此外,随着数据并行度的提高,单个节点的内存占用呈线性下降。
训练效率:
将短音频合并成长音频可以显著提高 GPU 的计算密度和利用率,从而显著提高训练效率。在我们的数据集中,音频时长呈现出明显的左偏分布,短音频(1-10 秒)占比较高,长音频(11-30 秒)占比较低。为了使音频时长分布更加均衡,我们将短音频合并,并将它们均匀地重新分配到 0-30 秒范围内以 5 秒为间隔的桶中。
在处理 21 万小时的大规模数据集时,使用 ffmpeg 将多个短音频物理合并成长音频会非常耗时。为此,我们采用了更高效的逻辑合并策略。具体来说,在数据准备阶段,我们使用字典来表示音频合并前后的映射关系,并在训练过程中动态地合并音频。
通过优化合并策略,小模型单次 epoch 训练时间从 64 小时大幅缩短至 28.6 小时,训练速度提升 123.78%,大大加速了模型迭代进程。
六、开源与社区贡献
为促进语音识别技术的进一步发展,Dolphin的训练模型和推理源代码已公开发布。这一举措不仅为研究人员提供了宝贵的研究基础,也为开源社区注入了新的活力,鼓励更多创新与合作。通过共享技术成果,我们希望能够吸引更多的开发者和研究机构参与到东方语言语音识别的研究中来,共同推动技术的进步。
Dolphin,一个大规模多语言多任务自动语音识别 (ASR) 模型。Dolphin 构建于 Whisper 风格的架构之上,并基于 OWSM,集成了专有和公开可用的数据集。实验结果表明,Dolphin 在各种语言和模型规模上始终优于现有的 SOTA 模型,有效弥合了东西方语言之间的性能差距。值得一提的是,Dolphin 基础模型的性能甚至优于 Whisper large-v3 版本。通过开源 Dolphin 基础模型、小型模型以及推理代码,我们旨在为多语言语音处理的进一步发展做出贡献。
支持的语言列表:
Language code
| Language Code | English Name | Chinese Name |
|---|---|---|
| zh | Mandarin Chinese | 中文 |
| ja | Japanese | 日语 |
| th | Thai | 泰语 |
| ru | Russian | 俄语 |
| ko | Korean | 韩语 |
| id | Indonesian | 印度尼西亚语 |
| vi | Vietnamese | 越南语 |
| ct | Yue Chinese | 粤语 |
| hi | Hindi | 印地语 |
| ur | Urdu | 乌尔都语 |
| ms | Malay | 马来语 |
| uz | Uzbek | 乌兹别克语 |
| ar | Arabic | 阿拉伯语 |
| fa | Persian | 波斯语 |
| bn | Bengali | 孟加拉语 |
| ta | Tamil | 泰米尔语 |
| te | Telugu | 泰卢固语 |
| ug | Uighur | 维吾尔语 |
| gu | Gujarati | 古吉拉特语 |
| my | Burmese | 缅甸语 |
| tl | Tagalog | 塔加洛语 |
| kk | Kazakh | 哈萨克语 |
| or | Oriya / Odia | 奥里亚语 |
| ne | Nepali | 尼泊尔语 |
| mn | Mongolian | 蒙古语 |
| km | Khmer | 高棉语 |
| jv | Javanese | 爪哇语 |
| lo | Lao | 老挝语 |
| si | Sinhala | 僧伽罗语 |
| fil | Filipino | 菲律宾语 |
| ps | Pushto | 普什图语 |
| pa | Panjabi | 旁遮普语 |
| kab | Kabyle | 卡拜尔语 |
| ba | Bashkir | 巴什基尔语 |
| ks | Kashmiri | 克什米尔语 |
| tg | Tajik | 塔吉克语 |
| su | Sundanese | 巽他语 |
| mr | Marathi | 马拉地语 |
| ky | Kirghiz | 吉尔吉斯语 |
| az | Azerbaijani | 阿塞拜疆语 |
Language Region Code
| Language Region Code | English Name | Chinese Name |
|---|---|---|
| zh-CN | Chinese (Mandarin) | 中文(普通话) |
| zh-TW | Chinese (Taiwan) | 中文(台湾) |
| zh-WU | Chinese (Wuyu) | 中文(吴语) |
| zh-SICHUAN | Chinese (Sichuan) | 中文(四川话) |
| zh-SHANXI | Chinese (Shanxi) | 中文(山西话) |
| zh-ANHUI | Chinese (Anhui) | 中文(安徽话) |
| zh-TIANJIN | Chinese (Tianjin) | 中文(天津话) |
| zh-NINGXIA | Chinese (Ningxia) | 中文(宁夏话) |
| zh-SHAANXI | Chinese (Shaanxi) | 中文(陕西话) |
| zh-HEBEI | Chinese (Hebei) | 中文(河北话) |
| zh-SHANDONG | Chinese (Shandong) | 中文(山东话) |
| zh-GUANGDONG | Chinese (Guangdong) | 中文(广东话) |
| zh-SHANGHAI | Chinese (Shanghai) | 中文(上海话) |
| zh-HUBEI | Chinese (Hubei) | 中文(湖北话) |
| zh-LIAONING | Chinese (Liaoning) | 中文(辽宁话) |
| zh-GANSU | Chinese (Gansu) | 中文(甘肃话) |
| zh-FUJIAN | Chinese (Fujian) | 中文(福建话) |
| zh-HUNAN | Chinese (Hunan) | 中文(湖南话) |
| zh-HENAN | Chinese (Henan) | 中文(河南话) |
| zh-YUNNAN | Chinese (Yunnan) | 中文(云南话) |
| zh-MINNAN | Chinese (Minnan) | 中文(闽南语) |
| zh-WENZHOU | Chinese (Wenzhou) | 中文(温州话) |
| ja-JP | Japanese | 日语 |
| th-TH | Thai | 泰语 |
| ru-RU | Russian | 俄语 |
| ko-KR | Korean | 韩语 |
| id-ID | Indonesian | 印度尼西亚语 |
| vi-VN | Vietnamese | 越南语 |
| ct-NULL | Yue (Unknown) | 粤语(未知) |
| ct-HK | Yue (Hongkong) | 粤语(香港) |
| ct-GZ | Yue (Guangdong) | 粤语(广东) |
| hi-IN | Hindi | 印地语 |
| ur-IN | Urdu | 乌尔都语(印度) |
| ur-PK | Urdu (Islamic Republic of Pakistan) | 乌尔都语 |
| ms-MY | Malay | 马来语 |
| uz-UZ | Uzbek | 乌兹别克语 |
| ar-MA | Arabic (Morocco) | 阿拉伯语(摩洛哥) |
| ar-GLA | Arabic | 阿拉伯语 |
| ar-SA | Arabic (Saudi Arabia) | 阿拉伯语(沙特) |
| ar-EG | Arabic (Egypt) | 阿拉伯语(埃及) |
| ar-KW | Arabic (Kuwait) | 阿拉伯语(科威特) |
| ar-LY | Arabic (Libya) | 阿拉伯语(利比亚) |
| ar-JO | Arabic (Jordan) | 阿拉伯语(约旦) |
| ar-AE | Arabic (U.A.E.) | 阿拉伯语(阿联酋) |
| ar-LVT | Arabic (Levant) | 阿拉伯语(黎凡特) |
| fa-IR | Persian | 波斯语 |
| bn-BD | Bengali | 孟加拉语 |
| ta-SG | Tamil (Singaporean) | 泰米尔语(新加坡) |
| ta-LK | Tamil (Sri Lankan) | 泰米尔语(斯里兰卡) |
| ta-IN | Tamil (India) | 泰米尔语(印度) |
| ta-MY | Tamil (Malaysia) | 泰米尔语(马来西亚) |
| te-IN | Telugu | 泰卢固语 |
| ug-NULL | Uighur | 维吾尔语 |
| ug-CN | Uighur | 维吾尔语 |
| gu-IN | Gujarati | 古吉拉特语 |
| my-MM | Burmese | 缅甸语 |
| tl-PH | Tagalog | 塔加洛语 |
| kk-KZ | Kazakh | 哈萨克语 |
| or-IN | Oriya / Odia | 奥里亚语 |
| ne-NP | Nepali | 尼泊尔语 |
| mn-MN | Mongolian | 蒙古语 |
| km-KH | Khmer | 高棉语 |
| jv-ID | Javanese | 爪哇语 |
| lo-LA | Lao | 老挝语 |
| si-LK | Sinhala | 僧伽罗语 |
| fil-PH | Filipino | 菲律宾语 |
| ps-AF | Pushto | 普什图语 |
| pa-IN | Panjabi | 旁遮普语 |
| kab-NULL | Kabyle | 卡拜尔语 |
| ba-NULL | Bashkir | 巴什基尔语 |
| ks-IN | Kashmiri | 克什米尔语 |
| tg-TJ | Tajik | 塔吉克语 |
| su-ID | Sundanese | 巽他语 |
| mr-IN | Marathi | 马拉地语 |
| ky-KG | Kirghiz | 吉尔吉斯语 |
| az-AZ | Azerbaijani | 阿塞拜疆语 |