
- https://www.wolai.com/suprit/heU7bADzdRaJje1jdeoVLp
- https://github.com/espnet/espnet/blob/master/espnet2/text/sentencepiece_tokenizer.py
- https://github.com/rsennrich/subword-nmt/tree/master 【最经典的BPE包,Paraformer分词大概率跟该仓库类似】
三种主流的Subword算法,它们分别是:Byte Pair Encoding (BPE)、WordPiece和Unigram Language Model。
执行分词的算法模型称为分词器(Tokenizer),划分好的一个个词称为Token(中文叫词元,为啥不直接叫Word?接着往后看),这个过程称为Tokenization。
我们将一个个的token(可以理解为小片段)表示向量,我们分词的目的就是尽可能的让这些向量蕴含更多有用的信息,然后把这些向量输入到算法模型中。
由于一篇文本的词往往太多了,为了方便算法模型训练,我们会选取出频率(也可能是其它的权重)最高的若干个词组成一个词表(Vocabulary)。
‼️古典分词方法的缺点
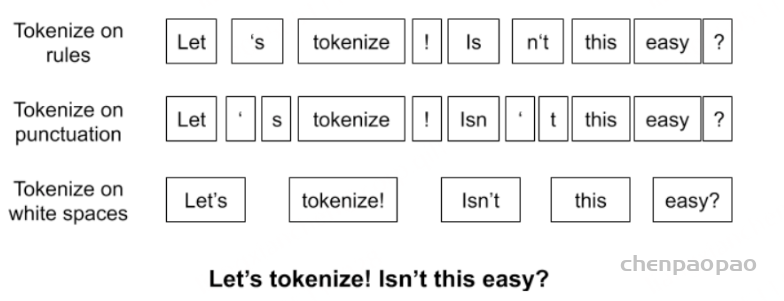
一个句子,使用不同的规则,将有许多种不同的分词结果。古典分词方法的缺点非常明显:
- 对于未在词表中出现的词(Out Of Vocabulary, OOV),模型将无法处理(未知符号标记为
[UNK])。 - 词表中的低频词/稀疏词在模型训无法得到训练(因为词表大小有限,太大的话会影响效率)。
- ⭐️很多语言难以用空格进行分词,例如英语单词的多形态,”look”衍生出的”looks”, “looking”, “looked”,其实都是一个意思,但是在词表中却被当作不同的词处理,模型也无法通过
old, older, oldest之间的关系学到smart, smarter, smartest之间的关系。这一方面增加了训练冗余,另一方面也造成了大词汇量问题。
Character embedding,是一种更为极端的分词方法,直接把一个词分成一个一个的字母和特殊符号。虽然能解决OOV问题,也避免了大词汇量问题,但缺点也太明显了,粒度太细,训练花费的成本太高,但这种思想或许我们后面会用到。

BERT算法的横空出世,NLP中的很多领域都被颠覆性的改变了,BERT也称为了一个非常主流的NLP算法。由于BERT的特性,要求分词方法也必须作出改变。这就对应提出了Subword算法(或成为WordPiece),该算法已经成为一种标配。
基于子词的分词方法(Subword Tokenization)
可见不论是传统分词算法的局限性,还是BERT的横空出世,都要求我们提出新的分词算法,下面就轮到本文的主角登场:基于子词的分词方法(Subword Tokenization),简称为Subword算法,意思就是把一个词切成更小的一块一块的子词。如果我们能使用将一个token分成多个subtokens,上面的问题就能很好的解决。
这种方法的目的是通过一个有限的词表来解决所有单词的分词问题,同时尽可能将结果中token的数目降到最低。例如,可以用更小的词片段来组成更大的词,例如:
“unfortunately” = “un” + “for” + “tun” + “ate” + “ly”。
可以看到,有点类似英语中的词根词缀拼词法,其中的这些小片段又可以用来构造其他词。可见这样做,既可以降低词表的大小,同时对相近词也能更好地处理。
Subword与传统分词方法的比较
- 传统词表示方法无法很好的处理未知或罕见的词汇(OOV问题)。
- 传统词tokenization方法不利于模型学习词缀之间的关系,例如模型学到的“old”, “older”, and “oldest”之间的关系无法泛化到“smart”, “smarter”, and “smartest”。
- Character embedding作为OOV的解决方法粒度太细。
- Subword粒度在词与字符之间,能够较好的平衡OOV问题。
目前有三种主流的Subword算法,它们分别是:Byte Pair Encoding (BPE)、WordPiece和Unigram Language Model。
字节对编码(BPE, Byte Pair Encoding)
字节对编码(BPE, Byte Pair Encoder),又称digram coding双字母组合编码,是一种数据压缩算法,用来在固定大小的词表中实现可变⻓度的子词。该算法简单有效,因而目前它是最流行的方法。
BPE首先将词分成单个字符,然后依次用另一个字符替换频率最高的一对字符,直到循环次数结束。

接下来详细介绍BPE在分词中的算法过程:
算法过程
- 准备语料库,确定期望的subword词表大小等参数
-
通常在每个单词末尾添加后缀
</w>,统计每个单词出现的频率,例如,low的频率为5,那么我们将其改写为"l o w </ w>”:5注:停止符</w>的意义在于标明subword是词后缀。举例来说:st不加</w>可以出现在词首,如st ar;加了</w>表明该子词位于词尾,如we st</w>,二者意义截然不同 - 将语料库中所有单词拆分为单个字符,用所有单个字符建立最初的词典,并统计每个字符的频率,本阶段的subword的粒度是字符
-
挑出频次最高的符号对,比如说
t和h组成的th,将新字符加入词表,然后将语料中所有该字符对融合(merge),即所有t和h都变为th。 注:新字符依然可以参与后续的merge,有点类似哈夫曼树,BPE实际上就是一种贪心算法。 - 重复遍历 2和 3 操作,直到词表中单词数达到设定量或下一个最高频数为1,如果已经打到设定量,其余的词汇直接丢弃
注:看似我们要维护两张表,一个词表,一个字符表,实际上只有一张,词表只是为了我们方便理解。</w> 是为了明确 subword 是否是词尾,它在训练、merge 过程中和普通字符一样对待,在最终输出时作为重建原词的标记使用。
我们举一个完整的例子,来直观地看一下这个过程:
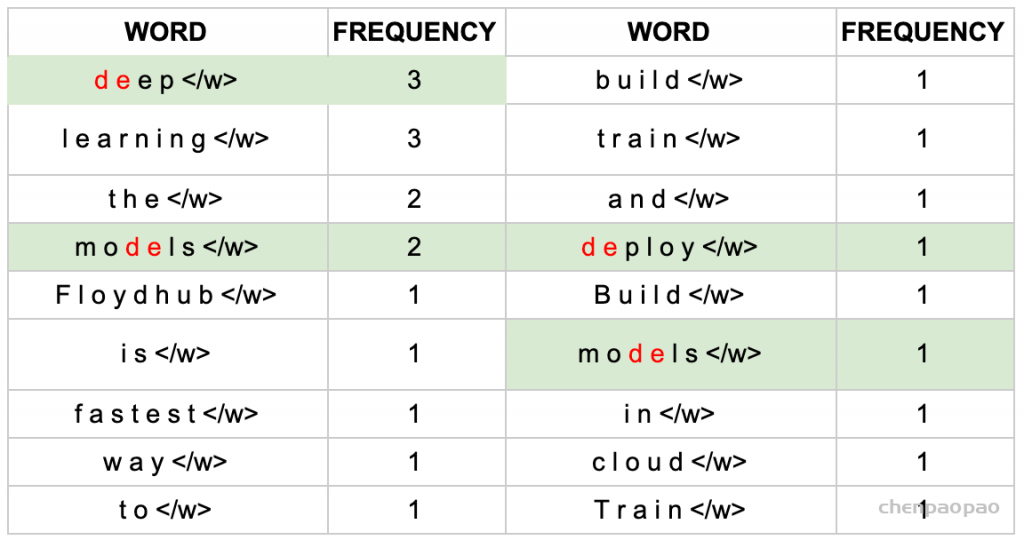
1、获取语料库,这样一段话为例:“FloydHub is the fastest way to build, train and deploy deep learning models. Build deep learning models in the cloud. Train deep learning models.”
2、拆分,加后缀,统计词频:
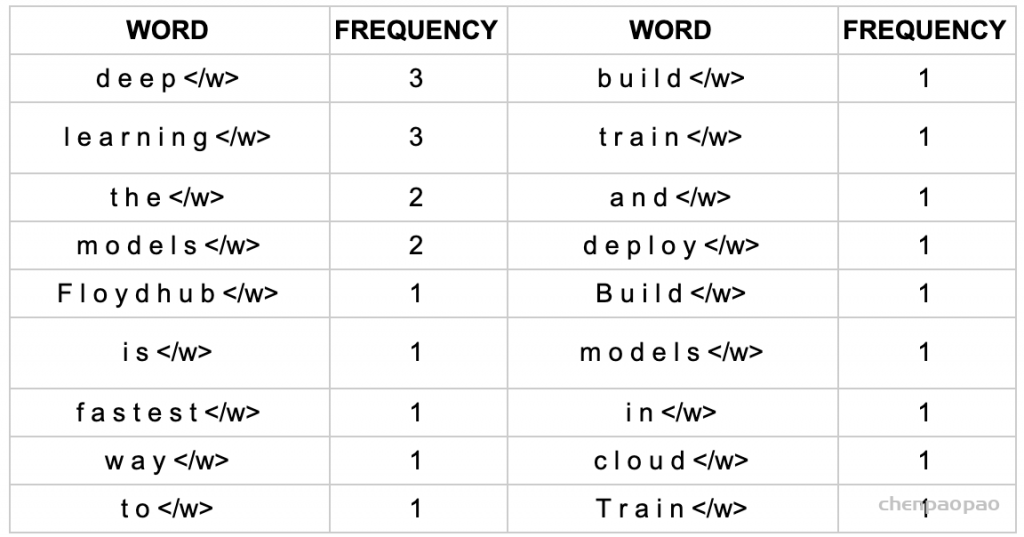
3、建立词表,统计字符频率(顺便排个序):
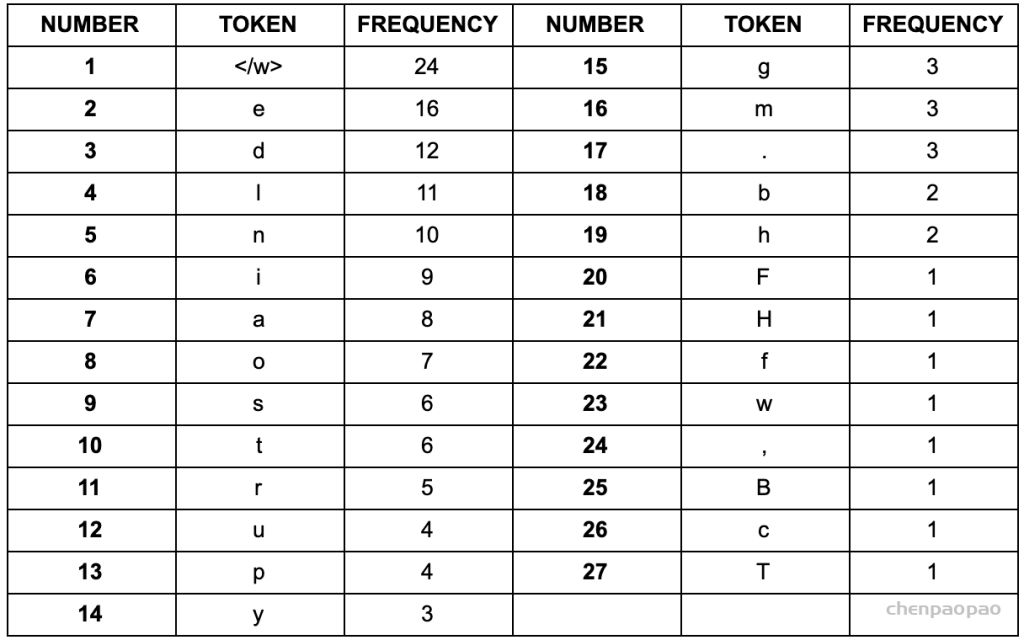

4、以第一次迭代为例,将字符频率最高的d和e替换为de,后面依次迭代:
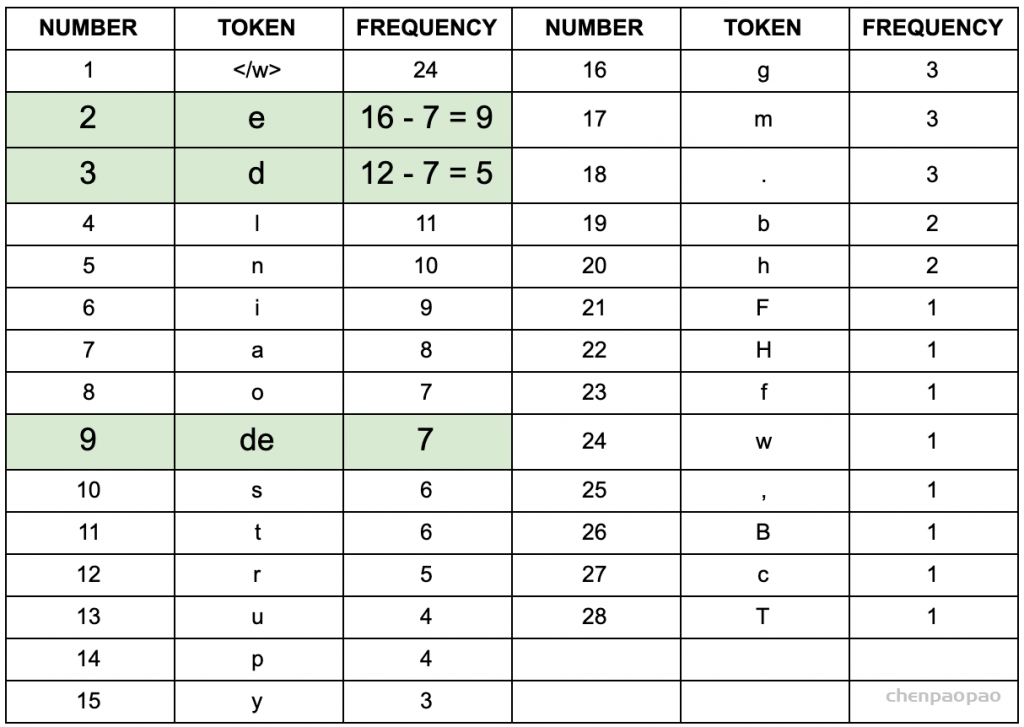
5、更新词表  继续迭代直到达到预设的subwords词表大小或下一个最高频的字节对出现频率为1。
继续迭代直到达到预设的subwords词表大小或下一个最高频的字节对出现频率为1。
如果将词表大小设置为10,最终的结果为:
d e
r n
rn i
rni n
rnin g</w>
o de
ode l
m odel
l o
l e这样我们就得到了更加合适的词表,这个词表可能会出现一些不是单词的组合,但是其本身有意义的一种形式
BPE的优点
上面例子中的语料库很小,知识为了方便我们理解BPE的过程,但实际中语料库往往非常非常大,无法给每个词(token)都放在词表中。BPE的优点就在于,可以很有效地平衡词典大小和编码步骤数(将语料编码所需要的token数量)。
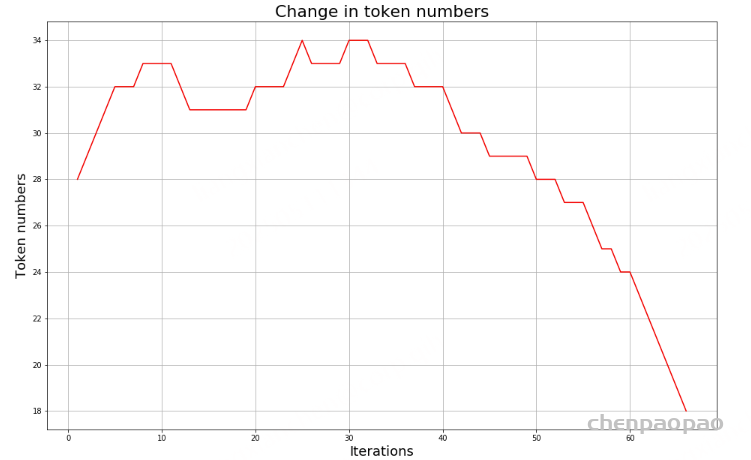
随着合并的次数增加,词表大小通常先增加后减小。迭代次数太小,大部分还是字母,没什么意义;迭代次数多,又重新变回了原来那几个词。所以词表大小要取一个中间值。
BPE的缺点
- 对于同一个句子, 例如Hello world,如图所示,可能会有不同的Subword序列。不同的Subword序列会产生完全不同的id序列表示,这种歧义可能在解码阶段无法解决。在翻译任务中,不同的id序列可能翻译出不同的句子,这显然是错误的。

- 在训练任务中,如果能对不同的Subword进行训练的话,将增加模型的健壮性,能够容忍更多的噪声,而BPE的贪心算法无法对随机分布进行学习。
个人理解:我感觉缺点直接可以忽略
BPE的适用范围
BPE一般适用在欧美语言拉丁语系中,因为欧美语言大多是字符形式,涉及前缀、后缀的单词比较多。而中文的汉字一般不用BPE进行编码,因为中文是字无法进行拆分。对中文的处理通常只有分词和分字两种。理论上分词效果更好,更好的区别语义。分字效率高、简洁,因为常用的字不过3000字,词表更加简短。
BPE的实现
实现代码如下:
import re, collections
def get_vocab(filename):
vocab = collections.defaultdict(int)
with open(filename, 'r', encoding='utf-8') as fhand:
for line in fhand:
words = line.strip().split()
for word in words:
vocab[' '.join(list(word)) + ' </w>'] += 1
return vocab
def get_stats(vocab):
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i],symbols[i+1]] += freq
return pairs
def merge_vocab(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
def get_tokens(vocab):
tokens = collections.defaultdict(int)
for word, freq in vocab.items():
word_tokens = word.split()
for token in word_tokens:
tokens[token] += freq
return tokens跑一个例子试一下,这里已经对原句子进行了预处理:
vocab = {'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3}
print('==========')
print('Tokens Before BPE')
tokens = get_tokens(vocab)
print('Tokens: {}'.format(tokens))
print('Number of tokens: {}'.format(len(tokens)))
print('==========')
num_merges = 5
for i in range(num_merges):
pairs = get_stats(vocab)
if not pairs:
break
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
print('Iter: {}'.format(i))
print('Best pair: {}'.format(best))
tokens = get_tokens(vocab)
print('Tokens: {}'.format(tokens))
print('Number of tokens: {}'.format(len(token结果:
==========
Tokens Before BPE
Tokens: defaultdict(<class 'int'>, {'l': 7, 'o': 7, 'w': 16, '</w>': 16, 'e': 17, 'r': 2, 'n': 6, 's': 9, 't': 9, 'i': 3, 'd': 3})
Number of tokens: 11
==========
Iter: 0
Best pair: ('e', 's')
Tokens: defaultdict(<class 'int'>, {'l': 7, 'o': 7, 'w': 16, '</w>': 16, 'e': 8, 'r': 2, 'n': 6, 'es': 9, 't': 9, 'i': 3, 'd': 3})
Number of tokens: 11
==========
Iter: 1
Best pair: ('es', 't')
Tokens: defaultdict(<class 'int'>, {'l': 7, 'o': 7, 'w': 16, '</w>': 16, 'e': 8, 'r': 2, 'n': 6, 'est': 9, 'i': 3, 'd': 3})
Number of tokens: 10
==========
Iter: 2
Best pair: ('est', '</w>')
Tokens: defaultdict(<class 'int'>, {'l': 7, 'o': 7, 'w': 16, '</w>': 7, 'e': 8, 'r': 2, 'n': 6, 'est</w>': 9, 'i': 3, 'd': 3})
Number of tokens: 10
==========
Iter: 3
Best pair: ('l', 'o')
Tokens: defaultdict(<class 'int'>, {'lo': 7, 'w': 16, '</w>': 7, 'e': 8, 'r': 2, 'n': 6, 'est</w>': 9, 'i': 3, 'd': 3})
Number of tokens: 9
==========
Iter: 4
Best pair: ('lo', 'w')
Tokens: defaultdict(<class 'int'>, {'low': 7, '</w>': 7, 'e': 8, 'r': 2, 'n': 6, 'w': 9, 'est</w>': 9, 'i': 3, 'd': 3})
Number of tokens: 9
==========编码与解码
上面的过程称为编码。解码过程比较简单,如果相邻子词间没有中止符,则将两子词直接拼接,否则两子词之间添加分隔符。 如果仍然有子字符串没被替换但所有token都已迭代完毕,则将剩余的子词替换为特殊token,如<unk>。例如:
# 编码序列
["the</w>", "high", "est</w>", "moun", "tain</w>"]
# 解码序列
"the</w> highest</w> mountain</w>"如何调包使用BPE
BPE 可以直接用最经典的 subword-nmt 包,不需要自己实现