
- 论文:https://aclanthology.org/2024.acl-long.485.pdf
- 代码:https://github.com/ictnlp/StreamSpeech
- 模型:https://huggingface.co/ICTNLP/StreamSpeech_Models
- Demo:https://ictnlp.github.io/StreamSpeech-site/
- 语音翻译综述:Recent Advances in Direct Speech-to-text Translation
2024年6月,中国科学院计算技术研究所自然语言处理团队发布“All in One”流式语音模型——StreamSpeech。该模型可以在用户说话的同时,以端到端的方式实现语音识别、语音翻译、语音合成的多任务实时处理,延时低至320毫秒。StreamSpeech是能够以端到端方式同时完成多项离线和流式语音任务的开源模型。StreamSpeech可以部署在手机、耳机、AR眼镜等设备,助力国际会议、跨国旅行等场景下的低延时跨语言交流需求。
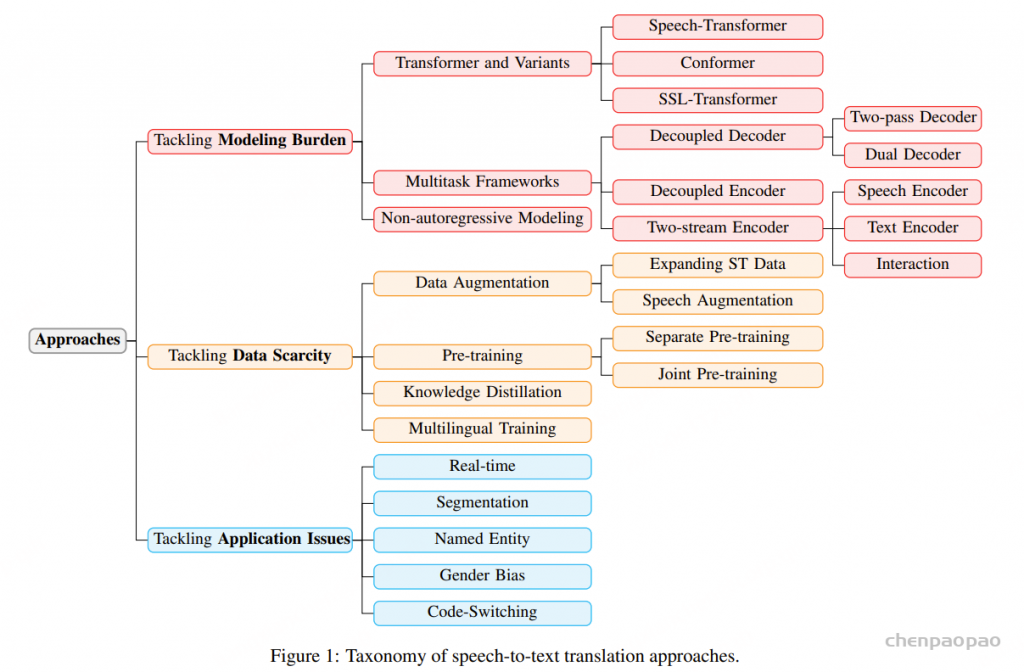
StreamSpeech采用先进的two-pass架构,集成了流式语音编码器、实时文本解码器和同步的文本到语音合成模块。通过引入连接时序分类(Connectionist temporal classification,CTC)对齐机制,StreamSpeech能够控制模型在用户说话的同时理解并生成语音识别、翻译和合成结果。StreamSpeech在离线和实时语音到语音翻译上超过Meta的UnitY架构,在开源数据集上取得当前的最佳性能。此外,StreamSpeech还能在翻译过程中生成中间文本结果,为用户提供“边听边看”的流畅体验。
StreamSpeech 采用两遍架构,首先将源语音转换为目标文本隐藏状态(自回归语音到文本翻译,AR-S2TT),然后通过非自回归文本到单元生成生成目标语音。引入源/目标/单元 CTC 解码器,通过语音识别 (ASR)、非自回归语音到文本翻译 (NAR-S2TT) 和语音到单元翻译 (S2UT) 等多个任务学习对齐,从而指导 StreamSpeech 何时开始识别、翻译和合成。
- 1. StreamSpeech 在离线和同步语音到语音翻译方面都实现了最先进的性能 。
- 2. StreamSpeech 可以通过 “All in One”无缝模型执行流式 ASR、同步语音到文本翻译和同步语音到语音翻译。
- 3. StreamSpeech 可以在同声翻译过程中呈现中间结果(即 ASR 或翻译结果) ,提供更全面的低延迟通信体验。
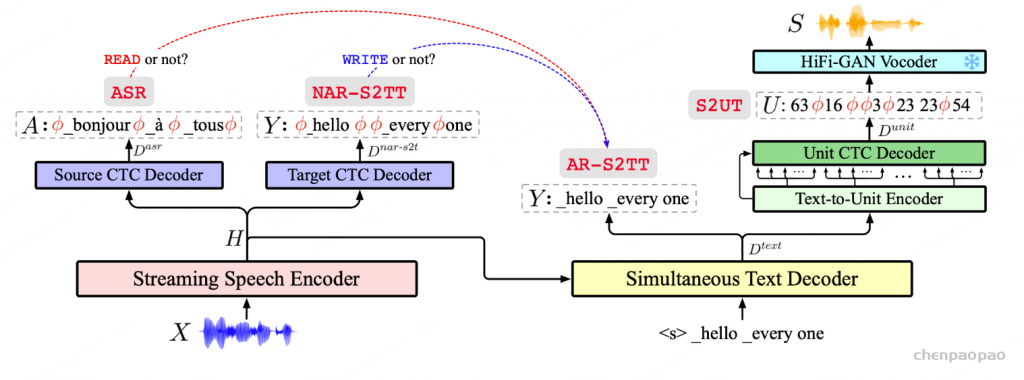
(自回归语音到文本翻译,AR-S2TT),然后通过非自回归文本到单元生成生成目标语音。引入源/目标/单元 CTC 解码器,通过语音识别 (ASR)、非自回归语音到文本翻译 (NAR-S2TT) 和语音到单元翻译 (S2UT) 等多个任务学习对齐,从而指导 StreamSpeech 何时开始识别、翻译和合成。
StreamSpeech:

Architecture
StreamSpeech 由三部分组成:流式语音编码器、同步文本解码器和同步文本到单元生成模块。引入多个 CTC 解码器,通过辅助任务学习对齐,并据此指导策略。
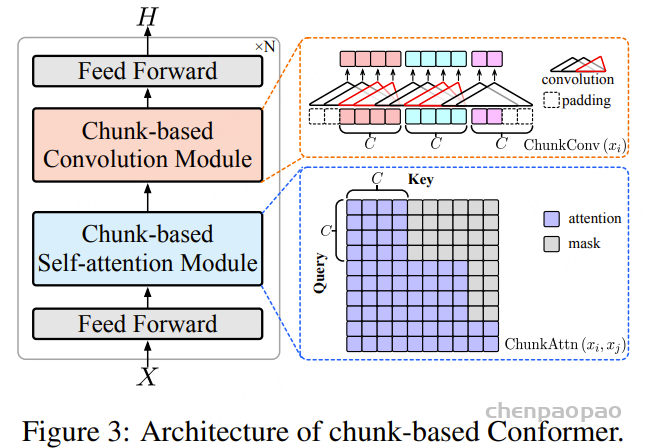
流式语音编码器: Conformer 架构通过堆叠注意力模块和卷积模块。在语音建模方面展现出显著优势,但在流式语音输入建模方面却存在困难,这主要是由于双向自注意力和卷积运算涉及整个序列的感受野。为此,我们提出了基于块的 Conformer 架构,旨在赋予 Conformer 架构编码流式输入的能力,同时保留局部块内的双向编码。
图 3 展示了基于块(chunk-based)的 Conformer 架构。首先,原始语音输入会被转换为语音特征(在我们的工作中使用的是滤波器组特征,每个语音特征通常对应约 40 毫秒的时长。基于块的 Conformer 会将流式语音划分为若干个块(chunk),每个块包含 C 个语音特征,其中 C 是一个控制块大小的超参数。在基于块的 Conformer 中,自注意力(self-attention)和卷积操作在块内部是双向的,在块之间则是单向的,从而能够处理流式输入。
对于基于块的自注意力机制,特征 xi 会关注那些位于相同块内或前面块内的特征 xj,其计算方式如下:
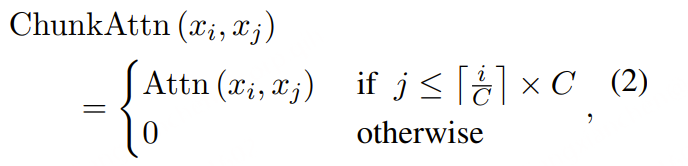
其中,Attn(xi,xj)是标准的多头注意力机制,而⌈⋅⌉ 表示向上取整操作。
对于基于块的卷积(chunk-based convolution),卷积操作的上界会被截断在当前块的边界处。即当使用核大小为 k 的卷积时,其计算方式为:
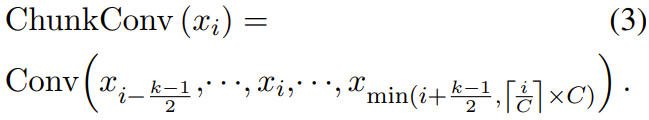
在实现上,基于块的卷积可以通过掩码操作(屏蔽掉那些被截断的位置)并行计算。通过流式编码器,计算源语音的隐藏状态,记为 H=(h1,⋯,h|H|) 。基于块的 Conformer 使得流式语音编码器不仅能够满足流式编码的需求,还能对语音进行局部双向编码。
H≤g(i) 的语义范围:
- 包括了从起始到第 g(i) 帧为止的语音输入(多个 chunk 累积的结果);
- 每一个帧的表示都融合了:
- chunk 内的 双向上下文(强表征)
- chunk 之间的 单向依赖(因果性)
同步文本解码器: 在流式编码器之后,文本解码器通过关注源语音隐藏状态 H ,同时生成目标文本 Y 。为了实现这一点,StreamSpeech 需要一个策略来决定何时生成每个目标标记(即,解码器可以关注多少个语音状态)。合理的策略应该确保模型等到识别源语音中的源文本(读取),然后再生成相应的目标文本(写入)。
Simultaneous Text Decoder(同步文本解码器)是在流式语音编码器之后,边接收源语音隐藏状态 H,边生成目标文本 Y。为实现低延迟输出,需要一个策略(policy)来判断:
- 何时 READ(读取更多源语音)
- 何时 WRITE(生成目标 token)
核心做法:通过 CTC 对齐引导策略
1. 引入两个 CTC 解码器:
- Source CTC Decoder:对齐源语音 → 源文本(ASR)
- Target CTC Decoder:对齐源语音 → 目标文本(NAR-S2TT)
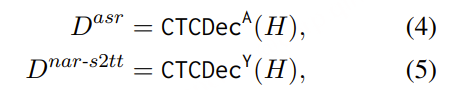
分别计算两个任务的 CTC Loss:
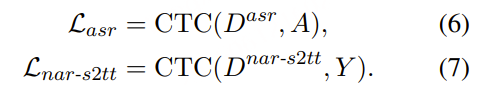
构建 READ / WRITE 策略函数。用上面两个 CTC 的输出计算当前语音段 X≤j对应的:
- 已识别的源 token 数 Njasr
- 已预测的目标 token 数 Njnar-s2tt
然后定义策略函数 g(i),表示在什么时间步 j可以生成目标 token yi:
StreamSpeech 在接收到语音 X≤g(i) 后自回归生成目标标记 yi
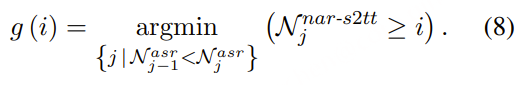
READ 检测(左条件):ASR 模块识别出一个新的源 token,说明我们“听”到了新语义,应该考虑进入写入阶段。
WRITE 准备(右条件):非自回归模块预测当前语音内容足以包含第 iii 个目标 token,我们可以放心翻译了。
尽管 NAR-S2TT 用来预测 token 数以对齐,但最终目标 token yi 是通过 AR-S2TT 来生成的,以提升翻译质量:
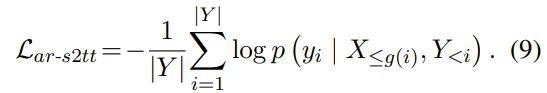
基于由 ASR 和 NAR-S2TT 派生的对齐策略指导的策略,同步文本解码器在接收到语音 X≤g(i) 后生成 yi ,并通过自回归语音转文本翻译(AR-S2TT, X→Y )的交叉熵损失进行优化
Non-autoregressive Text-to-Unit Generation:为了同步生成当前目标文本所对应的语音单位(unit),StreamSpeech 采用了一种 非自回归的文本到单位(T2U)架构(Gu et al., 2018),该架构由一个 T2U 编码器 和一个 单位 CTC 解码器 组成。
- T2U 编码器的输入是来自同步文本解码器生成的隐藏状态 Dtext。
- 鉴于音频单位序列 U 通常比文本序列 Y 更长,我们将 T2U 编码器的输出上采样 r 倍作为解码器输入
ith 输入对应于 D⌈i/r⌉text 。然后,单元 CTC 解码器通过关注位于 D⌈i/r⌉text 之前的 T2U 编码器输出,以非自回归的方式生成单元序列 U 。正式地,单元 CTC 解码器 CTCDecU 的输出 Dunit 计算如下:

NAR T2U 生成通过 CTC 损失在语音到单元翻译任务(S2UT, S→U )上进行了优化:
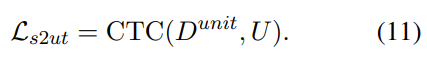
最终,使用一个基于单位的 HiFi-GAN 声码器(Kong et al., 2020)来根据生成的单位序列合成目标语音。注意,这个声码器是预训练的并被冻结,不参与 StreamSpeech 的联合训练。
训练(Training):
StreamSpeech 中涉及的所有任务都是通过**多任务学习(multi-task learning)以端到端(end-to-end)**的方式联合优化的。总体训练目标L 包括以下几个任务的损失:
- S2UT(语音到单位翻译)
- AR-S2TT(自回归语音到文本翻译)
- ASR(语音识别)
- NAR-S2TT(非自回归语音到文本翻译)
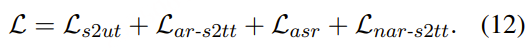
多任务学习能够有效地将同步策略的学习与翻译能力的学习整合进一个统一框架中。此外,像 ASR 和 AR-S2TT 等辅助任务生成的高质量中间结果,也可以在推理过程中展示给用户,作为补充参考内容。
多块训练(Multi-chunk Training):在推理过程中,Simul-S2ST(流式语音到语音翻译)可能会面临不同的延迟需求。为每种延迟分别训练一个模型代价很高。为了解决这个问题,我们提出了 多块训练(multi-chunk training),以提升 StreamSpeech 在不同延迟水平下的性能表现。
在多块训练中:
- 流式语音编码器的块大小 C不是固定的,
- 而是从 U(1,∣X∣) 的均匀分布中随机采样,其中 ∣X∣ 表示整个输入语音序列的长度;
- 特殊情况C=∣X∣ 即对应于离线 S2ST设置。
通过多块训练,单个 StreamSpeech 模型就能适应不同的延迟需求。
Inference:
在推理过程中,StreamSpeech 会基于设定的块大小 C 来处理流式语音输入,其中每个语音特征通常对应 40 毫秒的音频时长(例如,C=8 表示每 320 毫秒处理一次语音输入)。
然后,StreamSpeech 会使用 ASR 和 NAR-S2TT 的 CTC 解码器对当前接收到的语音 X^ 进行解码,分别生成源语言 token A^ 和目标语言 token Y^。
当满足以下两个条件时:
- 识别出了新的源 token(即 ∣A^∣>∣A∣)
- 当前语音中预测的目标 token 数超过已生成的目标 token(即 ∣Y^∣>∣Y∣)
模型将会进入 WRITE 阶段:
- 更新源文本 A
- 持续自回归地生成新的目标 token,直到达到 Y^ 的数量上限或遇到
<eos>结束符 - 根据目标文本生成对应的单位序列 U
- 使用声码器合成出目标语音 S
否则,如果上述条件不满足,模型会进入 READ 阶段,等待接收下一个大小为 C 的语音块。
由于引入了多块训练(multi-chunk training),StreamSpeech 可以通过动态调整块大小 C 来控制推理延迟。其中:
- 较小的 C 意味着更低的延迟;
- 较大的 C 则带来更完整的上下文,提升质量。

实验
预处理
源语音转换为 16000Hz,将目标语音生成为 22050Hz。对于源语音,我们计算 80 维的 Mel 滤波器组特征,并进行全局的倒谱均值-方差归一化,每个语音特征对应 40 毫秒的时长。对于目标语音,通过 mHuBERT3提取离散单元,并使用预训练的基于单元的 HiFi-GAN 语音生成器进行语音合成。对于源文本和目标文本,我们分别使用 SentencePiece生成大小为 6000 的 unigram 词汇表。
离线语音到语音翻译(Offline S2ST):StreamSpeech 采用 双阶段(two-pass)架构,相比使用单阶段(one-pass)架构的 S2UT 和 Translatotron,在性能上取得了显著提升。多任务学习(multi-task learning)不仅能指导策略学习,还能为翻译提供中间监督信号,从而进一步提升了离线 S2ST 的性能。
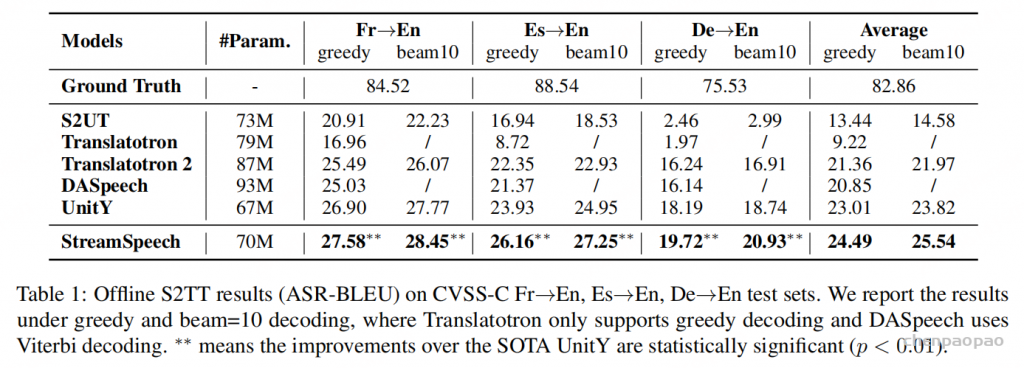
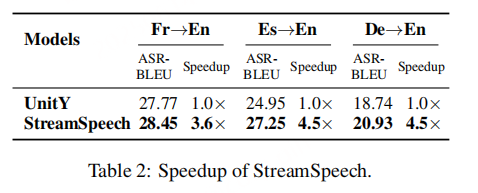
StreamSpeech 推理加速效果
为评估 StreamSpeech 的推理效率,表 2 报告了其相对于 UnitY 的加速比(speedup)。
在该双阶段架构中,StreamSpeech:
- 第一阶段翻译使用自回归结构(更适合处理复杂语言重排);
- 第二阶段语音合成使用非自回归结构(尽管序列较长,但几乎单调对齐,易于并行)。
这种 先 AR 后 NAR 的两阶段架构,在保持翻译质量的同时,实现了 显著的推理速度提升。
Simul-S2ST(同步语音到语音翻译):
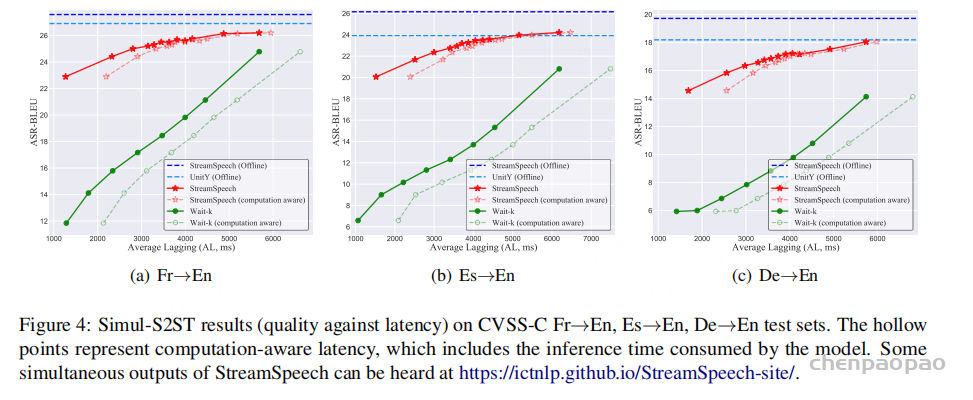
在所有延迟设置下,StreamSpeech 的表现都优于 Wait-k,尤其是在低延迟条件下,BLEU 分数提升约 10 分。
Wait-k 策略是目前使用最广泛的同步策略,在同步文本到文本(T2TT)和语音到文本(S2TT)任务中表现良好。StreamSpeech 在同步语音到语音翻译中,不仅兼顾了延迟与质量,还通过对齐驱动策略实现了更自然的发声节奏,在多个基线之上取得了系统性提升。