
- 论文:LongAlign: A Recipe for Long Context Alignment of Large Language Models
- 文章:https://huggingface.co/blog/sirluk/llm-sequence-packing
- code实现:https://github.com/THUDM/LongAlign
要让大型语言模型更有效地处理长文本上下文,需要在相似长度的输入序列上进行指令微调。LongAlign 方法,它可以帮助大型语言模型有效处理长达 64k 的长上下文,并展现出强大的长文本理解和生成能力。
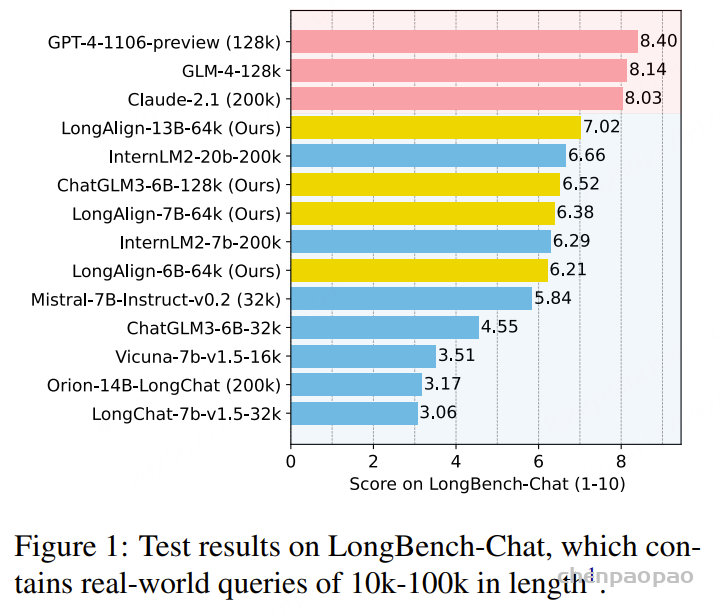
LongAlign :
动机:
- 目前缺乏用于有监督微调(SFT)的长文本指令跟随数据集,更缺乏构建此类数据的方法。
- 长上下文数据的长度分布差异较大,在多GPU环境中严重降低了传统批处理方法的训练效率——处理较短输入的GPU必须等待处理较长输入的GPU完成任务后才能继续运行。
- 亟需一个强健的基准评估体系,用于衡量大型语言模型在面对真实世界长文本查询时的处理能力。
贡献:
LongAlign 方法,分别从数据构建、高效训练和评估三个方面入手:
在数据方面,为构建一个多样化的长文本指令跟随数据集,从九个来源收集了长文本序列,并使用 Self-Instruct生成了 1 万条长度在 8k 到 64k 之间的指令数据。
在训练方面,为应对不均匀批处理导致的效率问题,采用了 packing 策略,即在将数据分发到 GPU 之前,将多个序列打包为接近最大长度的组合。但我们发现这种打包训练中的损失计算存在偏差:不同数量序列的打包在最终损失计算中被赋予相同权重。为缓解这一问题,我们提出了“损失加权策略”,对每条文本的损失进行加权平均,以平衡不同序列对整体损失的贡献。此外,我们还引入了“排序批处理”方法,将长度相近的序列分组,从而减少批内空闲时间。
在评估方面,开发了 LongBench-Chat 基准测试,它包含长度为 10k-100k 的开放式问题,这些问题由博士生进行标注。评估内容涵盖推理、编程、摘要以及多语种翻译等多种长文本指令跟随能力。使用 GPT-4(OpenAI,2023b)结合人工标注结果和少量示例,对模型生成的回答进行评分。
结论:
数据量与多样性的影响:长文本指令数据的数量和多样性都会显著影响模型处理长上下文的能力,最终性能差异最高可达 30%。
长文本指令数据的益处:增加长文本指令数据有助于提升模型在长上下文任务中的表现,同时不会削弱其处理短上下文任务的能力。
训练策略的有效性:采用的打包和排序批处理策略可将训练速度提升超过 100%,且不影响模型性能。此外,提出的损失加权技术还能将长文本任务的性能提升 10%。
数据集构建:
构建了一个包含10,000条长度在8k-64k之间的长文指令跟随数据集,这些数据来自于9个不同的数据源,包括学术论文、书籍、百科全书等,覆盖了多样化的任务类型。

高效训练方法:
为了确保模型在有监督微调(SFT)后依然具备处理长文本和短文本(即通用能力)的能力,将长文本指令数据与通用指令数据集混合用于训练。这种训练策略使得大量通用短文本数据与相对较少的长指令数据结合,从而形成了一个“长尾”式的数据长度分布。探索了两种训练方法:packing 和 sorted batching。
Packing(打包)
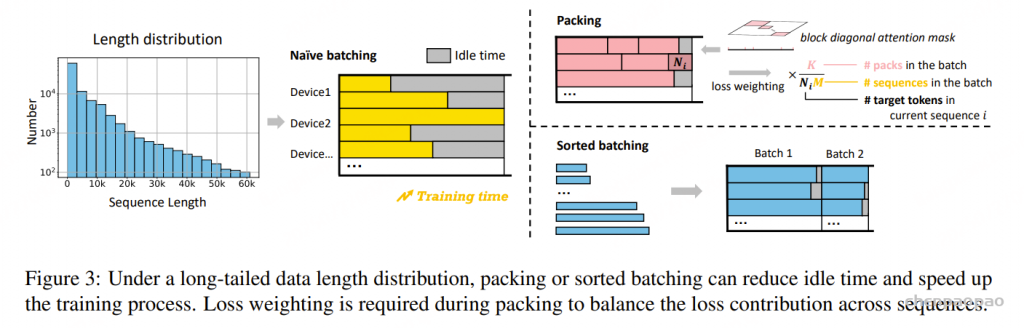
该方法通过将不同长度的数据拼接,直至达到最大长度,生成的打包数据整体长度接近最大限值。这些打包后的数据再进行批处理并在多 GPU 上处理,有效减少了每个批次中的空转时间。
此外,为防止同一 pack 中的不同序列在自注意力计算中发生“交叉污染”,我们传入了每个序列的起始与结束位置列表,并使用了 FlashAttention 2 中的 flash_attn_varlen_func 该方法支持高效的块对角注意力计算,计算量与 IO 时间均优于传统的二维注意力掩码。
Packing 策略存在的偏差
不过我们注意到,packing 会带来对长序列和目标 token 较多的序列的偏向。这是因为:不同的打包组(pack)在最终损失计算中被赋予相同权重,而每个打包组中包含的序列数量和每个序列的目标 token 数量却不同。
因此,在对每个批次求平均损失时,包含序列较少(通常是较长序列)或目标 token 较多的 pack,会对最终损失产生更大影响。
形式上,设将 M 个序列打包成 K 个 pack,第 i 个 pack 包含索引区间为 [Pi−1,Pi)的序列,其中 P0=1,PK=M+1。设 Li 为第 i个序列在其 Ni 个目标 token 上的总损失。如果我们希望对每个序列赋予相等的权重[ SFT中算loss ],则损失应当为:
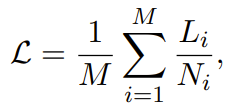
而在 packing 情况下计算得到的损失为:
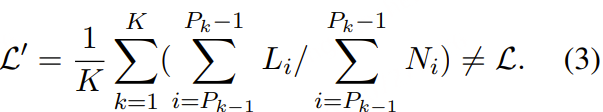
(3)与公式 (2) 相比,在 packing 情况下,相当于为第 j个序列分配了一个权重:
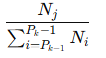
也就是说,损失更偏向于目标 token 数较多的序列,以及位于pack 较小的组中的序列。
为了解决这种不公平,我们提出对第 i 个序列的损失进行缩放,缩放因子为:K/(NiM),然后对每个 pack 中缩放后的损失求和,这样得到的总损失将与公式 (2)(即平均每个序列损失)保持一致,从而消除了不同序列在损失计算中所受到的偏倚。
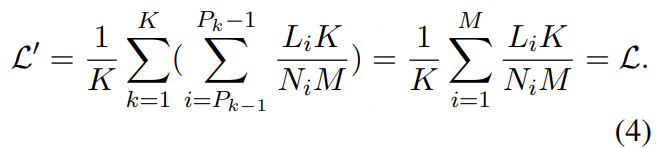
损失加权策略在下游任务中带来了约 10% 的性能提升。
Sorted Batching(排序批处理)
还提出了一种高效的 排序批处理策略。为确保每个 batch 中的序列长度相近,我们先按照序列长度对数据进行排序,然后在每轮训练中从中随机选取一段连续的数据组成一个 batch,且不重复使用。
不过,该方法不可避免地会引入 批次间数据分布的不均衡:某些 batch 可能全部由长序列组成,另一些则全是短序列。这种偏差可能对 SGD(随机梯度下降)优化过程造成严重影响。
尽管如此,我们在实验中发现,排序批处理显著加快了训练速度,且几乎不会对模型性能产生负面影响。这可能得益于我们使用了较大的梯度累积步数(gradient accumulation steps)和优化器本身较强的适应能力。
训练方法细节
这里介绍 packing 策略与损失加权的具体实现方式。
Packing 策略实现
在打包训练过程中,每个数据批次会传入一个特殊的一维注意力掩码。在该掩码中,第 i个元素表示第 i 个序列在该批次中的起始位置。掩码的第一个元素为 0,最后一个元素等于 batch_size × seq_len。
在注意力计算时,我们使用 FlashAttention 2 提供的 flash_attn_varlen_func 函数,并将该掩码传入其参数 cu_seqlens_q 和 cu_seqlens_k。该函数会根据掩码中相邻元素表示的起始和结束位置,在每个序列内部进行注意力计算。因此,每个序列的 Query 只能与自身的 Key 进行注意力操作,实现了“序列内独立注意”。
损失加权策略实现
在实现损失加权策略时,首先对训练数据进行预处理:为每个 pack 中的序列生成一个加权的一维掩码。该掩码中,对应目标 token 的位置权重为 1/N(其中 N 是当前序列的目标 token 数),其他位置为 0。
训练时,根据当前配置动态设置 M 和 K,表示即当前批次中序列的数量和 pack 的数量。然后,损失计算方法为:对每个 token 的交叉熵损失乘以比例系数 K/(MN),再求和得到最终损失值。
Packing 加权loss代码实现:
SFT中算loss通常来讲都是样本内作token-level mean,样本间作sequence-level mean,也就是等式(2)的计算方式。如果不同样本间作token-level mean,则会使target token数量多的样本更受重视(相当于被upsample),从而引入不同样本间的不平衡。
### Support loss weighting for packing ###
loss = None
if labels is not None:
lm_logits = lm_logits.to(torch.float32)
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
if isinstance(labels, tuple) or isinstance(labels, list):
labels, weights = labels
shift_labels = labels[..., 1:].contiguous()
if self.pack_loss:
shift_weights = weights[..., 1:].contiguous()
loss_fct = CrossEntropyLoss(ignore_index=-100, reduction='none')
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
loss = (loss * shift_weights).sum()
else:
loss_fct = CrossEntropyLoss(ignore_index=-100)
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
lm_logits = lm_logits.to(hidden_states.dtype)
loss = loss.to(hidden_states.dtype)
### -------------------------------------- ###