
- 项目地址:https://github.com/OpenMOSS/MOSS-TTSD
- 在线体验:https://huggingface.co/spaces/fnlp/MOSS-TTSD
- Blog: https://www.open-moss.com/en/moss-ttsd/
当前的文本到语音(TTS)模型在单句或孤立段落的语音生成效果上取得了令人瞩目的进展,合成语音的自然度、清晰度和表现力都已显著提升,甚至接近真人水平。不过,由于缺乏整体的对话情境,这些 TTS 模型仍然无法合成高质量的对话语音。
MOSS-TTSD 是一个口语对话语音生成模型,实现了中英双语的高表现力对话语音生成,支持零样本多说话人音色克隆,声音事件控制以及长语音生成。与传统 TTS 模型只能生成单句语音不同,MOSS-TTSD 能够根据完整的多人对话文本,直接生成高质量对话语音,并准确捕捉对话中的韵律变化和语调特性,实现超高拟人度的逼真对话语音合成。
- 高表现力对话语音:基于统一语义-声学神经音频Codec、预训练大语言模型、百万小时TTS数据与约40万小时的真实/合成对话语音数据,MOSS-TTSD能够生成高表现力,高自然度,具有自然对话韵律的拟人对话语音。
- 双说话人零样本声音克隆:MOSS-TTSD支持零样本双说话人克隆,按脚本精确进行角色/声线切换。只需要提供10到20秒的参考音频片段。
- 中英双语:MOSS-TTSD支持中英两种语言的高表现力语音生成。
- 长音频生成:得益于低码率Codec与训练框架优化,MOSS-TTSD在长音频生成场景进行了大量训练(训练最大长度达到960s),能够单次生成超长音频。
模型概览:

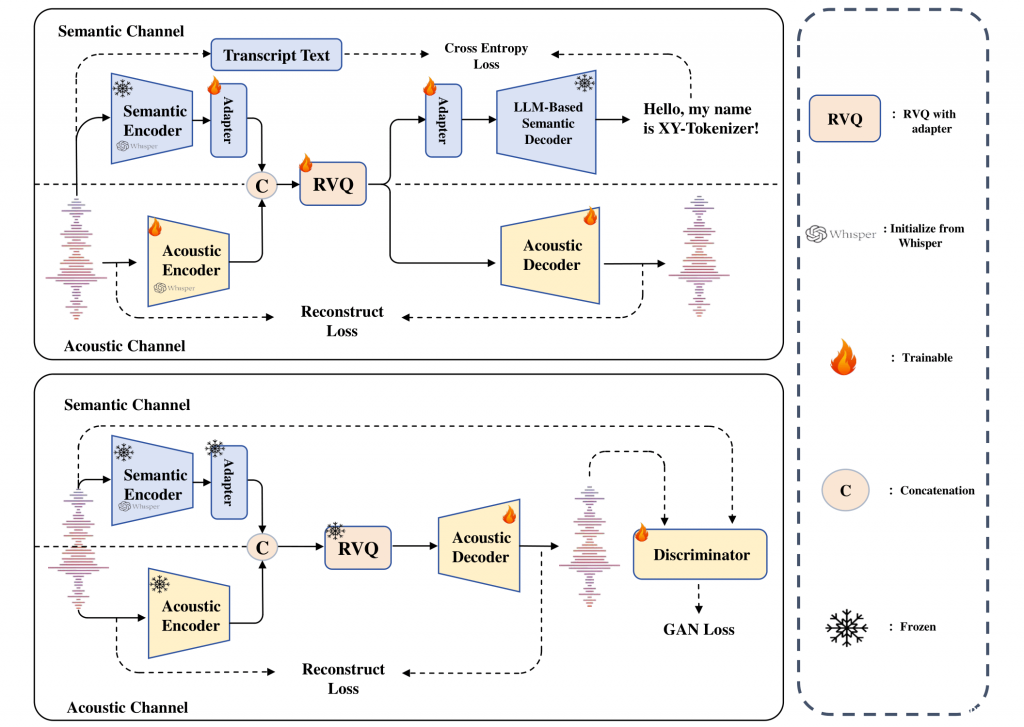
MOSS-TTSD 使用完全离散化的方式进行语音生成。我们训练了一个8层 RVQ 的音频 Codec:XY-Tokenizer,来对原始音频进行量化。 XY-Tokenizer 能够同时编码语音的语义和声学信息,并具有较低的比特率(1kbps),这使得LLM能够有效地学习音频序列并建模细节声学特征。 在序列建模方面,受到 MusicGen 和 VOICECRAFT的启发,我们使用自回归建模加多头 Delay 的方式进行语音 token 生成。
语音离散化: XY-Tokenizer:
为了统一建模语音的语义和声学信息,并实现低比特率,我们构建了 XY-Tokenizer,它使用了双路 Whisper Encoder 进行语音编码,8层 RVQ 量化,两阶段多任务学习的方式进行训练。实现了 1kbps 的比特率和 12.5Hz 的帧率[1024码本大小]。
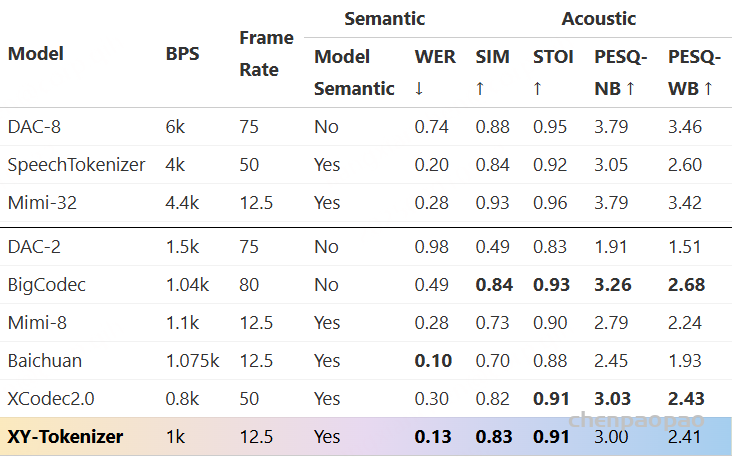
我们扩展了Codec训练的数据量,使用了10万小时带有转录文本的语音数据进行训练。下表对比了在LibriSpeech测试集上不同 Codec 在语义和声学性能上的表现。WER为ASR任务中的词错误率,WER越低表示语音 token 的语义信息与文本对齐程度更好。粗体为低比特率 Codec 组中的最优或次优性能。
为了更好地编码和重建复杂的对话音频,我们扩展了50万小时无转录音频数据进行增强训练,扩展 Codec 对于复杂音频和场景的处理能力。
得益于Codec的超低比特率,我们模型的训练长度最长达到了960s的音频,这使得我们的模型可以一次性地生成超长的语音,避免了拼接语音片段之间的不自然过渡。
数据工程:
TTS 模型的性能与训练数据的质量和数量有着密切的关系,为了规模化高质量 TTS 数据和 TTSD 数据,我们设计了高效的数据处理流水线,可以从海量原始音频中准确筛选出单人语音和多人对话语音并进行标注。
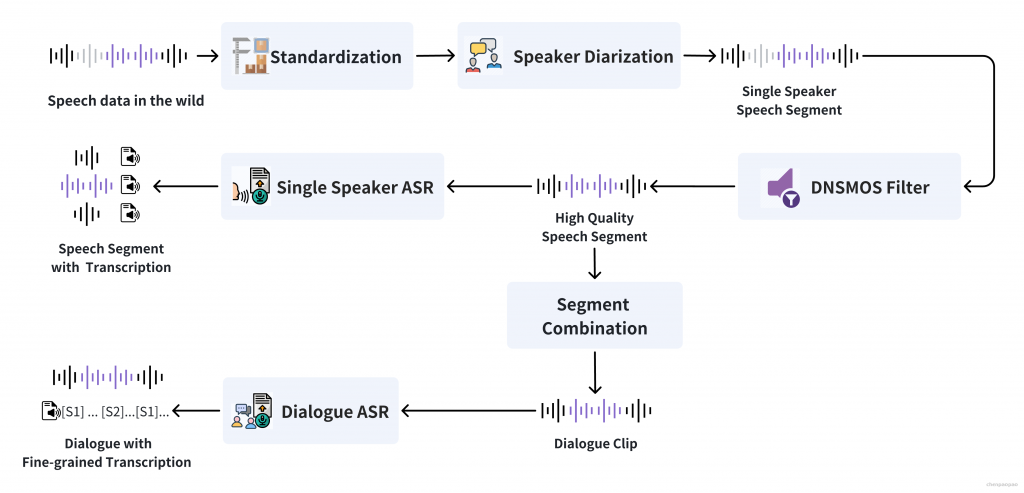
对于原始音频,我们首先使用内部的说话人分离模型进行语音分段和说话人标注。 基于预训练基模,我们的说话人分离模型性能已经优于开源说话人分离模型 pyannote-speaker-diarization-3.1 及其商用版本 pyannoteAI 。

我们使用 DNSMOS 分数来作为语音质量的评估标准,我们假设 DNSMOS 分数高的语音大概率不包含背景噪声。 为了保证语音的质量和较少的噪声,我们只保留 DNSMOS >=2.8的语音片段。 对于高质量的音频片段,我们直接对语音进行转录,作为 TTS 训练数据。 此外,我们设计了一套规则来将 Diarization 分离的语音片段组合成双人对话的片段用作 TTSD 训练,这样得到的对话片段我们称之为粗粒度对话片段。 虽然说话人分离模型能够较准确地分离说话人,但是我们发现它对一些较短的 Backchannel 不是特别敏感,存在漏分离的情况。 此外,当前的 ASR 模型无法准确地转录对话中重叠的语音。 因此,受 Parakeet[4] 的启发,我们训练了中文版的 Whisper-d 模型来对中文数据进行细粒度说话人标注和文本转录。对于英文数据我们直接使用 Parakeet 的开源 Whisper-d。 最终,我们使用说话人分离模型的粗粒度标签和 Whipser-d 模型的细粒度标签来将短对话片段组成长对话片段。
TTS 预训练:
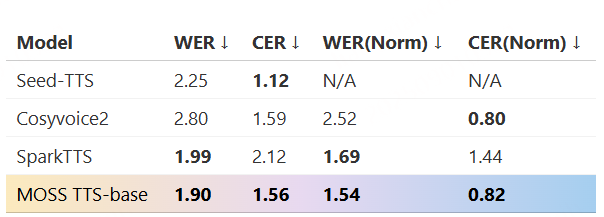
我们使用了110万小时的中英文 TTS 数据对模型进行了预训练,大规模的 TTS 预训练可以显著增强 TTSD 模型的语音韵律和表现力,并提升模型泛化能力。 我们使用了 Seed-tts-eval评测了 TTS 预训练模型的性能,取得了和当前顶尖闭源模型 Seed-TTS 相当的性能。 经过 TTS 预训练后的模型已经有了较强的语音生成能力和零样本音色克隆能力。
TTSD 后训练:
最终,我们收集了10万小时中文对话数据和27万小时英文对话数据。 此外,为了增强模型的说话人切换准确率,我们合成了4万小时中文对话数据和4万小时英文对话数据。 为了增强模型对于中文标点符号的感知能力,我们使用 Gemini 对部分数据(约7万小时)中的转录文本进行了修正。
在训练阶段,我们基于 TTS 预训练的检查点,使用 WSD Scheduler 进行训练,我们没有针对 Decay 阶段做特殊的数据规划。 此外,我们发现无法通过验证集挑选表现最好的检查点,因此我们通过人工评估的方式挑选了主观表现最好的检查点。