
文章来源:每周一个大模型应用

Whisper、SenseVoice、sherpa-onnx……开源 ASR 选择越来越多,但真正上线后,你很可能遇到两个经典抱怨:「专有名词老读错」和「实时跟不上说话」。本文把优化手段整理成可执行的决策树与分层机制,帮你少踩坑、少试错。
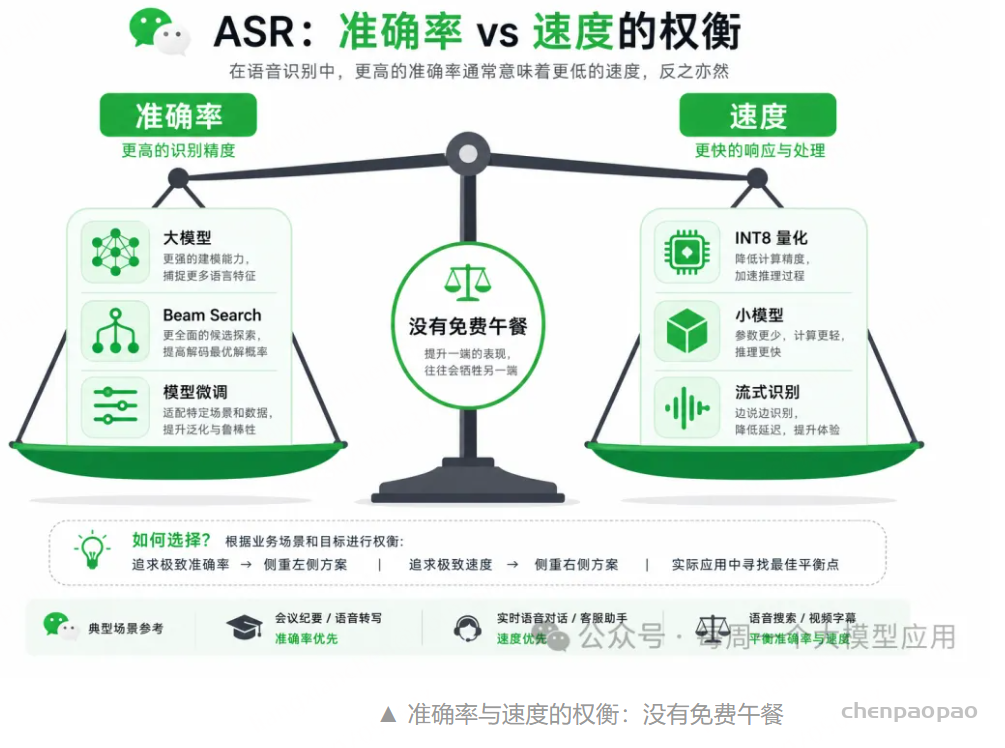
结论先行:「不够准」和「不够快」是两条优化路线,但底层机制有重叠。准确率优先从音频质量、热词、语言模型、换中文基座到领域微调;速度优先从小模型、INT8 量化、合适运行时(流式用 sherpa-onnx,离线用 faster-whisper)入手。二者通常互相拉扯——没有「又准又快又免费」的万能方案。
一、先分清:你要优化的是哪一类问题
很多团队一上来就换更大的模型,结果延迟翻倍、GPU 成本飙升,准确率却只涨一点点。
其实 ASR 的「不准」和「不快」,背后是完全不同的瓶颈。
▎ 常见现象对照表
● 专有名词、行业词错 → 训练数据里没有,优先热词 / 微调 / 语言模型
● 噪声、远场、混响 → 前端音频差,优先降噪 + VAD + 换模型
● 方言、口音 → 基座覆盖不足,换中文/方言模型或微调
● 延迟高、跟不上说话 → 流式配置或模型太大,小模型 + INT8 + 真流式
● 长音频转写慢 → 非批处理或 CPU 推理,faster-whisper / GPU / 分段并行

「准确率和速度通常互相拉扯:模型越大越准但越慢;beam 越大越准但越慢;INT8 更快但可能略损精度。优化前先明确你的主 KPI 是 CER 还是 RTF。」
二、五层优化框架:从输入到后处理
不管用哪套开源 ASR,都可以按五层来思考优化路径。
自下而上分别是:改输入、改模型、改解码、改部署、改后处理。
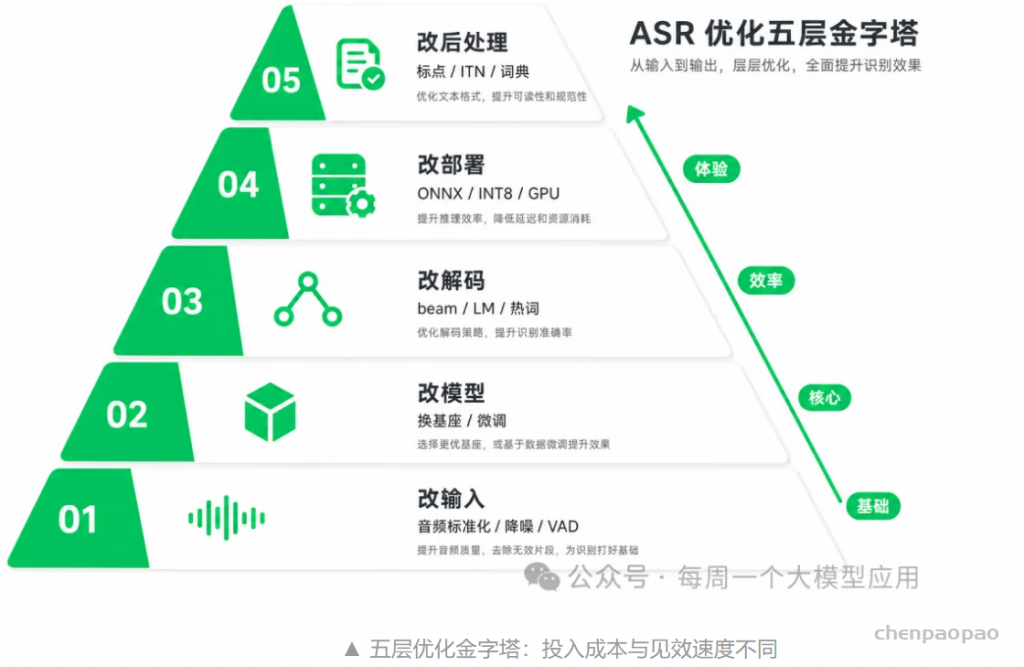
① 改输入:16 kHz 单声道、降噪、VAD 切静音——零成本,often 被忽略
② 改模型:换更强基座(SenseVoice / Qwen3-ASR)或领域微调
③ 改解码:beam size、热词偏置、LM 重打分
④ 改部署:ONNX + INT8、sherpa-onnx 流式、faster-whisper 批处理
⑤ 改后处理:标点模型、ITN 数字规整、自定义词典替换
很多「模型不准」其实是输入音频和训练分布不一致。
先把音频标准化做好,再谈换模型,往往事半功倍。
三、提升识别率的六大机制
下面按「不改模型 → 换模型 → 微调 → 解码 → 后处理」的顺序,从易到难梳理提升准确率的手段。
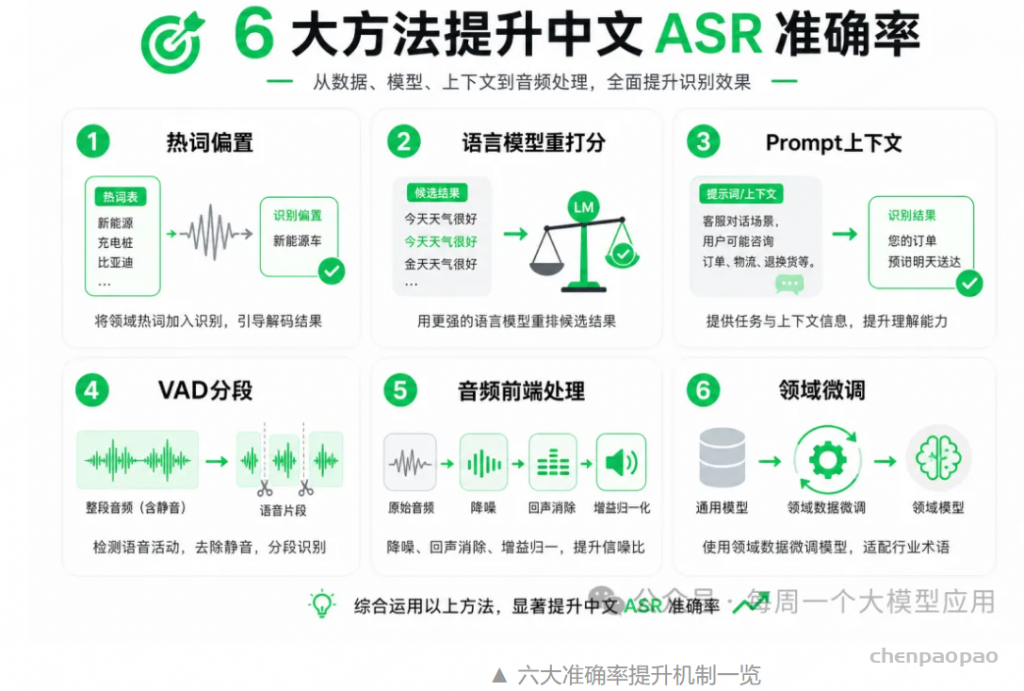
1. 热词 / 上下文偏置(最快见效)
机制:在解码时提高特定词(公司名、产品名、人名)的得分权重。
FunASR、WeNet、sherpa-onnx 等均支持,几乎不用重训,改配置即可。
适合词表固定、领域术语多的场景。
▎ 2. 语言模型重打分(LM Rescoring)
机制:ASR 先出 N 个候选(beam search),再用 N-gram 或神经网络 LM 选更「像人话」的结果。
适合同音字、语法约束(如「在/再」「的/地/得」)。
icefall / WeNet 训练链里常见,可导出到 sherpa-onnx 部署。
▎ 3. Prompt / 上下文(大模型 ASR)
Qwen3-ASR、Fun-ASR-Nano 等支持在输入里加提示,例如「语音转写成英文:」或「Speech transcription without text normalization:」。
利用 LLM 的语义先验,约束输出格式和领域。
▎ 4. VAD + 分段
先切掉静音和无效段,只对有效语音做识别,减少「把噪声当字」的幻觉。
FunASR 自带 FSMN-VAD;本地实时工具 asr_tool 用 endpoint 检测句末。
▎ 5. 音频前端处理
● 重采样到 16 kHz 单声道:与模型训练分布一致
● 降噪(RNNoise、DeepFilterNet):远场、会议场景
● AGC / 音量归一化:避免过小或削波
▎ 6. 领域微调(ROI 通常最高)
用你自己的「音频 + 标注」把模型拉向目标分布。
数据 < 10h 建议热词 + LM;10~100h 可 LoRA / adaptor 微调;100~1000h 微调 encoder + adaptor;> 1000h 可考虑全参。
同一套医疗/法律语料微调后,专有名词准确率 often 明显提升。
四、提升识别速度的五条路径
速度优化和准确率往往是反向的。
实时场景要的是首字延迟和 RTF(实时率),离线场景要的是吞吐。
别用离线大模型硬做流式——延迟会非常高。

模型侧:变小、变轻
● 蒸馏(distil-whisper):大模型教小模型,6~10× 加速,精度略降
● 量化 INT8:权重 8bit,CPU 友好,2~4× 加速
● 换小架构:Zipformer 14M vs 1.7B LLM,数量级差异
▎ 运行时:换引擎
● sherpa-onnx:CPU 流式、低延迟,Rust 集成,适合桌面实时
● faster-whisper(CTranslate2):GPU 批处理长音频快
● whisper.cpp:边缘设备、无 Python
● vLLM:Qwen3-ASR 等服务化部署
▎ 流式架构(延迟的关键)
真流式 pipeline:麦克风 → 固定 chunk(如 100ms)→ 增量 decode → partial 结果 → endpoint 检测 → final → reset。
chunk_size 越小延迟越低,但 CPU 调度开销上升;num_threads 4~8 常是 CPU 甜点。
▎ 系统级优化
● GPU / NPU:离线批处理、大模型必备
● 跳过静音(VAD):不算无效段,总耗时下降
● 并行分段:长音频切多段多 GPU 跑
● 减小 beam:beam=1 often 快 2~3×
五、按投入产出排序的推荐
▎ 想提升准确率(从易到难)
① 音频标准化(16 kHz、降噪、VAD)—— 零成本
② 热词 / Prompt —— 几小时配置
③ 调 beam + 加标点/ITN —— 一天内
④ 换更强的中文基座(SenseVoice / Qwen3-ASR)—— 改部署
⑤ LM 重打分 —— 需额外 LM 资源
⑥ 领域微调 —— 需标注数据,ROI 通常最高
▎ 想提升速度(从易到难)
① INT8 量化 + 减 beam —— 立刻见效
② 换 faster-whisper / sherpa-onnx —— 改运行时
③ 换小模型 / 蒸馏模型 —— 接受略降精度
④ GPU + 批处理 —— 离线场景
⑤ 真流式架构 —— 实时场景必做
· · ·
六、场景化落地组合
结合 voice_repo 里的工具链,以下是几种常见场景的组合建议。
▎ 桌面实时中文
准确率:热词 + 更好的ASR模型。
速度:保持sherpa-onnx INT8 真流式。
默认模型 streaming-***-zh-14M INT8,面向 CPU 实时。
▎ 会议录音转写
准确率:SenseVoice / Qwen3-ASR + 标点模型。
速度:faster-whisper GPU 批处理,长音频分段并行。
▎ 垂直领域(医疗 / 法律 / 金融)
准确率:FunASR 微调 + 热词 + LM 重打分。
速度:微调后导出 ONNX 到 sherpa-onnx,接自研服务。
▎ 多语种 / 方言
准确率:Qwen3-ASR + Prompt 约束。
速度:vLLM 服务化,或 0.6B 小模型做边缘部署。
· · ·
七、怎么验证「真的变好了」
别凭感觉,用同一套 test set 对比。
固定 100~500 条代表性样本,每次只改一个变量(例如只加热词、只换模型),否则无法判断哪招有效。
● CER / WER:字/词错误率,中文常用 CER
● RTF:实时率,< 1 才算实时
● 首字延迟:流式场景的关键指标
● 领域词准确率:单独统计热词表命中率
「开源 ASR 的优化不是「换一个更大的模型就完事」,而是按场景选对机制、按数据量选对深度、用指标验证每一步。」
总结
不够准:音频质量 → 热词/LM → 换中文模型 → 领域微调
• 不够快:小模型 + INT8 + 合适运行时(流式 sherpa-onnx,离线 faster-whisper)
• 五层框架:改输入 → 改模型 → 改解码 → 改部署 → 改后处理
• 准确与速度互相拉扯,优化前先明确主 KPI
• 固定 test set,每次只改一个变量,用 CER/RTF 验证