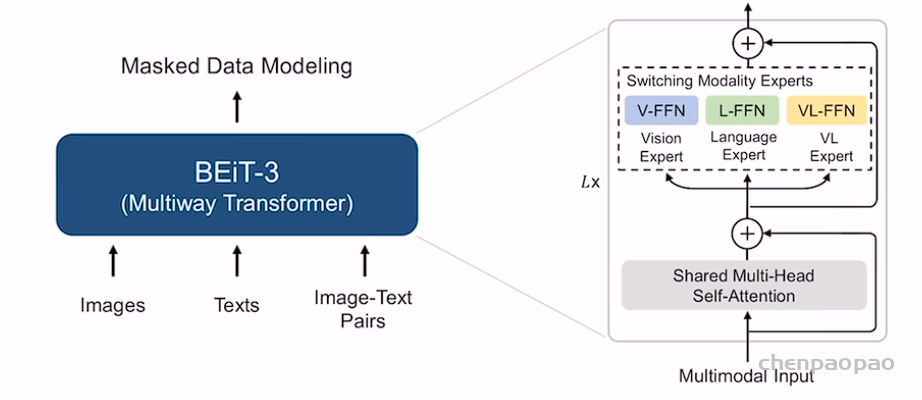
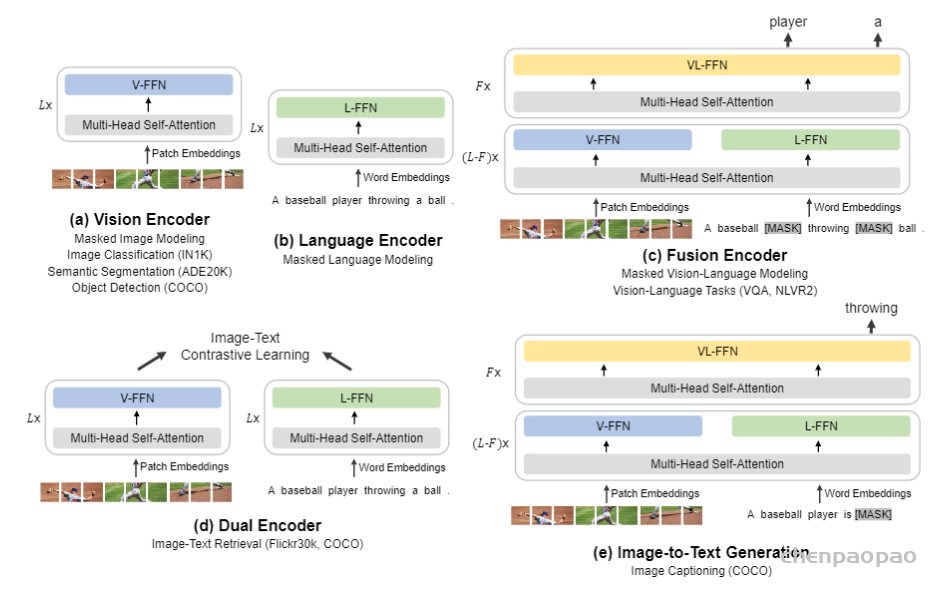
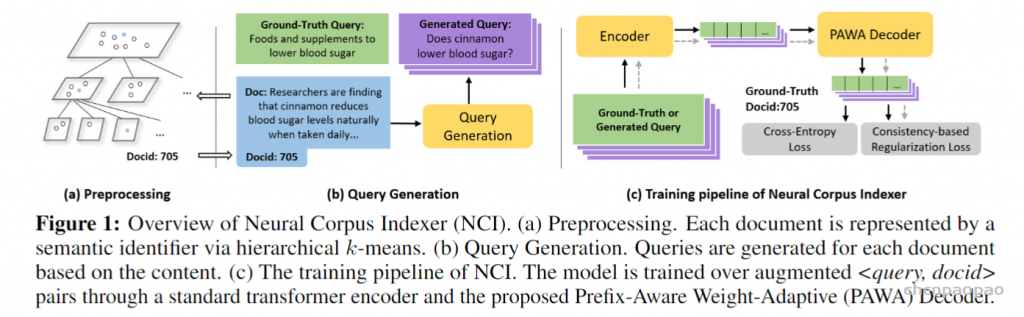
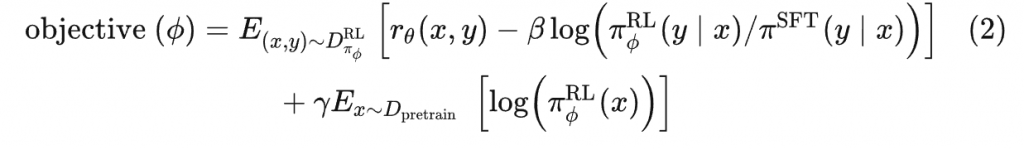NLP中的位置编码
Bert问世后瞬间引爆了NLP领域,同时也让Transformer火了起来,Transformer中特征提取的方式不是传统的CNN,RNN等,而是用attention的形式,这种模式被用在AI的各个领域中,包括CV和语音等。attention提取特征的效果非常好,可以非常有效的提取到上下文的信息,但是在NLP中会有个问题:attention提取特征的时候,当前这个字对上下文的其他字的关联性可以很好的体现出来,但是其他字的位置在哪里都可以,在这个字的前面、后面都可以,间隔的距离也没有要求。但其实这跟我们平时表达的语言肯定是矛盾的,于是在Transformer中加入了位置编码。
虽然说起来主要就是绝对位置编码和相对位置编码两大类,但每一类其实又能衍生出各种各样的变种,为此研究人员可算是煞费苦心、绞尽脑汁了,此外还有一些不按套路出牌的位置编码。本文就让我们来欣赏一下研究人员为了更好地表达位置信息所构建出来的“八仙过海,各显神通”般的编码方案。
绝对位置编码
形式上来看,绝对位置编码是相对简单的一种方案,但即便如此,也不妨碍各路研究人员的奇思妙想,也有不少的变种。一般来说,绝对位置编码会加到输入中:在输入的第k个向量 \(xk\)中加入位置向量 \(pk\)变为\(xk+pk\),其中\(pk\)只依赖于位置编号k。
训练式
很显然,绝对位置编码的一个最朴素方案是不特意去设计什么,而是直接将位置编码当作可训练参数,比如最大长度为512,编码维度为768,那么就初始化一个512×768的矩阵作为位置向量,让它随着训练过程更新。现在的BERT、GPT等模型所用的就是这种位置编码,事实上它还可以追溯得更早,比如2017年Facebook的《Convolutional Sequence to Sequence Learning》就已经用到了它。
对于这种训练式的绝对位置编码,一般的认为它的缺点是没有外推性,即如果预训练最大长度为512的话,那么最多就只能处理长度为512的句子,再长就处理不了了。当然,也可以将超过512的位置向量随机初始化,然后继续微调。但笔者最近的研究表明,通过层次分解的方式,可以使得绝对位置编码能外推到足够长的范围,同时保持还不错的效果,因此,其实外推性也不是绝对位置编码的明显缺点。
三角式
三角函数式位置编码,一般也称为Sinusoidal位置编码,是Google的论文《Attention is All You Need》所提出来的一个显式解:
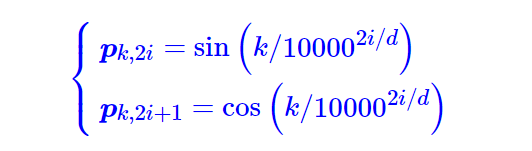

递归式
原则上来说,RNN模型不需要位置编码,它在结构上就自带了学习到位置信息的可能性(因为递归就意味着我们可以训练一个“数数”模型),因此,如果在输入后面先接一层RNN,然后再接Transformer,那么理论上就不需要加位置编码了。同理,我们也可以用RNN模型来学习一种绝对位置编码,比如从一个向量p0出发,通过递归格式pk+1=f(pk)来得到各个位置的编码向量。
ICML 2020的论文《Learning to Encode Position for Transformer with Continuous Dynamical Model》把这个思想推到了极致,它提出了用微分方程(ODE)dpt/dt=h(pt,t)的方式来建模位置编码,该方案称之为FLOATER。显然,FLOATER也属于递归模型,函数h(pt,t)可以通过神经网络来建模,因此这种微分方程也称为神经微分方程,关于它的工作最近也逐渐多了起来。
理论上来说,基于递归模型的位置编码也具有比较好的外推性,同时它也比三角函数式的位置编码有更好的灵活性(比如容易证明三角函数式的位置编码就是FLOATER的某个特解)。但是很明显,递归形式的位置编码牺牲了一定的并行性,可能会带速度瓶颈。
相乘式
刚才我们说到,输入xk与绝对位置编码pk的组合方式一般是xk+pk,那有没有“不一般”的组合方式呢?比如xk⊗pk(逐位相乘)?我们平时在搭建模型的时候,对于融合两个向量有多种方式,相加、相乘甚至拼接都是可以考虑的,怎么大家在做绝对位置编码的时候,都默认只考虑相加了?
很抱歉,笔者也不知道答案。可能大家默认选择相加是因为向量的相加具有比较鲜明的几何意义,但是对于深度学习模型来说,这种几何意义其实没有什么实际的价值。最近笔者看到的一个实验显示,似乎将“加”换成“乘”,也就是xk⊗pk的方式,似乎比xk+pk能取得更好的结果。具体效果笔者也没有完整对比过,只是提供这么一种可能性。关于实验来源,可以参考《中文语言模型研究:(1) 乘性位置编码》。
相对位置编码
相对位置并没有完整建模每个输入的位置信息,而是在算Attention的时候考虑当前位置与被Attention的位置的相对距离,由于自然语言一般更依赖于相对位置,所以相对位置编码通常也有着优秀的表现。对于相对位置编码来说,它的灵活性更大,更加体现出了研究人员的“天马行空”。
经典式
相对位置编码起源于Google的论文《Self-Attention with Relative Position Representations》,华为开源的NEZHA模型也用到了这种位置编码,后面各种相对位置编码变体基本也是依葫芦画瓢的简单修改。
一般认为,相对位置编码是由绝对位置编码启发而来,考虑一般的带绝对位置编码的Attention:


XLNET式
XLNET式位置编码其实源自Transformer-XL的论文《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》,只不过因为使用了Transformer-XL架构的XLNET模型并在一定程度上超过了BERT后,Transformer-XL才算广为人知,因此这种位置编码通常也被冠以XLNET之名。

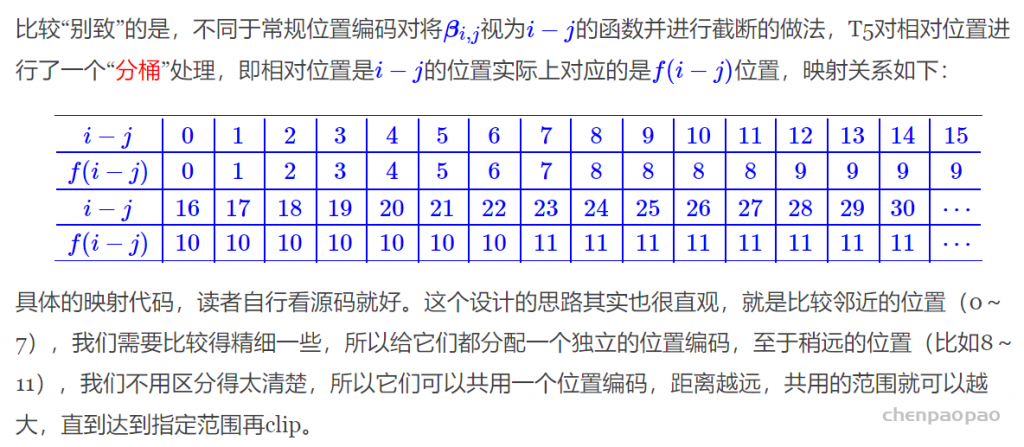
T5式
T5模型出自文章《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》,里边用到了一种更简单的相对位置编码。思路依然源自展开式(7)(7),如果非要分析每一项的含义,那么可以分别理解为“输入-输入”、“输入-位置”、“位置-输入”、“位置-位置”四项注意力的组合。如果我们认为输入信息与位置信息应该是独立(解耦)的,那么它们就不应该有过多的交互,所以“输入-位置”、“位置-输入”两项Attention可以删掉,而piWQW⊤Kp⊤j⊤实际上只是一个只依赖于(i,j)的标量,我们可以直接将它作为参数训练出来,即简化为
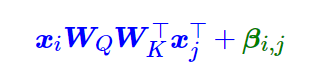
说白了,它仅仅是在Attention矩阵的基础上加一个可训练的偏置项而已,而跟XLNET式一样,在vj上的位置偏置则直接被去掉了。包含同样的思想的还有微软在ICLR 2021的论文《Rethinking Positional Encoding in Language Pre-training》中提出的TUPE位置编码。
DeBERTa式
DeBERTa也是微软搞的,去年6月就发出来了,论文为《DeBERTa: Decoding-enhanced BERT with Disentangled Attention》,最近又小小地火了一把,一是因为它正式中了ICLR 2021,二则是它登上SuperGLUE的榜首,成绩稍微超过了T5。
其实DeBERTa的主要改进也是在位置编码上,同样还是从展开式(7)(7)出发,T5是干脆去掉了第2、3项,只保留第4项并替换为相对位置编码,而DeBERTa则刚刚相反,它扔掉了第4项,保留第2、3项并且替换为相对位置编码(果然,科研就是枚举所有的排列组合看哪个最优):

不过,DeBERTa比较有意思的地方,是提供了使用相对位置和绝对位置编码的一个新视角,它指出NLP的大多数任务可能都只需要相对位置信息,但确实有些场景下绝对位置信息更有帮助,于是它将整个模型分为两部分来理解。以Base版的MLM预训练模型为例,它一共有13层,前11层只是用相对位置编码,这部分称为Encoder,后面2层加入绝对位置信息,这部分它称之为Decoder,还弄了个简称EMD(Enhanced Mask Decoder);至于下游任务的微调截断,则是使用前11层的Encoder加上1层的Decoder来进行。
SuperGLUE上的成绩肯定了DeBERTa的价值,但是它论文的各种命名真的是让人觉得极度不适,比如它自称的“Encoder”、“Decoder”就很容易让人误解这是一个Seq2Seq模型,比如EMD这个简称也跟Earth Mover’s Distance重名。虽然有时候重名是不可避免的,但它重的名都是ML界大家都比较熟悉的对象,相当容易引起误解,真不知道作者是怎么想的…
其他位置编码
绝对位置编码和相对位置编码虽然花样百出,但仍然算是经典范围内,从上述介绍中我们依然可以体会到满满的套路感。除此之外,还有一些并不按照常规套路出牌,它们同样也表达了位置编码。
CNN式
尽管经典的将CNN用于NLP的工作《Convolutional Sequence to Sequence Learning》往里边加入了位置编码,但我们知道一般的CNN模型尤其是图像中的CNN模型,都是没有另外加位置编码的,那CNN模型究竟是怎么捕捉位置信息的呢?
如果让笔者来回答,那么答案可能是卷积核的各项异性导致了它能分辨出不同方向的相对位置。不过ICLR 2020的论文《How Much Position Information Do Convolutional Neural Networks Encode?》给出了一个可能让人比较意外的答案:CNN模型的位置信息,是Zero Padding泄漏的!
我们知道,为了使得卷积编码过程中的feature保持一定的大小,我们通常会对输入padding一定的0,而这篇论文显示该操作导致模型有能力识别位置信息。也就是说,卷积核的各向异性固然重要,但是最根本的是zero padding的存在,那么可以想象,实际上提取的是当前位置与padding的边界的相对距离。
不过,这个能力依赖于CNN的局部性,像Attention这种全局的无先验结构并不适用,如果只关心Transformer位置编码方案的读者,这就权当是扩展一下视野吧。
复数式
复数式位置编码可谓是最特立独行的一种位置编码方案了,它来自ICLR 2020的论文《Encoding word order in complex embeddings》。论文的主要思想是结合复数的性质以及一些基本原理,推导出了它的位置编码形式(Complex Order)为:

代表词j的三组词向量。你没看错,它确实假设每个词有三组跟位置无关的词向量了(当然可以按照某种形式进行参数共享,使得它退化为两组甚至一组),然后跟位置k相关的词向量就按照上述公式运算。
你以为引入多组词向量就是它最特立独行的地方了?并不是!我们看到式(11)(11)还是复数形式,你猜它接下来怎么着?将它实数化?非也,它是将它直接用于复数模型!也就是说,它走的是一条复数模型路线,不仅仅输入的Embedding层是复数的,里边的每一层Transformer都是复数的,它还实现和对比了复数版的Fasttext、LSTM、CNN等模型!这篇文章的一作是Benyou Wang,可以搜到他的相关工作基本上都是围绕着复数模型展开的,可谓复数模型的铁杆粉了~
融合式
无偶独有,利用复数的形式,笔者其实也构思了一种比较巧的位置编码,它可以将绝对位置编码与相对位置编码融于一体,分享在此,有兴趣的读者欢迎一起交流研究。
简单起见,我们先假设qm,kn是所在位置分别为m,n的二维行向量,既然是二维,那么我们可以将它当作复数来运算。我们知道,Attention关键之处在于向量的内积,用复数表示为

来赋予[x,y]绝对位置信息,那么在Attention运算的时候也等价于相对位置编码。如果是多于二维的向量,可以考虑每两维为一组进行同样的运算,每一组的θ可以不一样。
这样一来,我们得到了一种融绝对位置与相对位置于一体的位置编码方案,从形式上看它有点像乘性的绝对位置编码,通过在q,k中施行该位置编码,那么效果就等价于相对位置编码,而如果还需要显式的绝对位置信息,则可以同时在v上也施行这种位置编码。总的来说,我们通过绝对位置的操作,可以达到绝对位置的效果,也能达到相对位置的效果,初步实验显示它是可以work的,但还没有充分验证,欢迎大家尝试交流。