C:\Users\User>g++ --versiong++ (x86_64-posix-seh-rev0, Built by MinGW-W64 project) 8.1.0Copyright (C) 2018 Free Software Foundation, Inc.This is free software; see the source for copying conditions. There is NOwarranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
在安装部分有个小问题,我的本机已经安装完opencv-python,然后我们再去安装albumentations的时候,出现了一个问题,就是我们的opencv-python阻止albumentations的安装,报错如下:# Could not install packages due to anEnvironmentError: [WinError 5] 拒绝访问,是因为在安装albumentations的时候还要安装opencv-python-headless,这个库和opencv冲突。
import albumentations as A
import cv2
import matplotlib.pyplot as plt
# Declare an augmentation pipeline
transform = A.Compose([
A.RandomCrop(width=512, height=512),
A.HorizontalFlip(p=0.8),
A.RandomBrightnessContrast(p=0.5),
])
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = transform(image=image)
transformed_image = transformed["image"]
plt.imshow(transformed_image)
plt.show()
详细使用案例:
1、VerticalFlip 围绕X轴垂直翻转输入
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.VerticalFlip(always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('Blur后的图像')
plt.imshow(transformed_image)
plt.show()
2、Blur模糊输入图像
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.Blur(blur_limit=15,always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('Blur后的图像')
plt.imshow(transformed_image)
plt.show()
3、HorizontalFlip 围绕y轴水平翻转输入
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.HorizontalFlip(always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('HorizontalFlip后的图像')
plt.imshow(transformed_image)
plt.show()
4、Flip水平,垂直或水平和垂直翻转输入
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.Flip(always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('Flip后的图像')
plt.imshow(transformed_image)
plt.show()
5、Transpose, 通过交换行和列来转置输入
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.Transpose(always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('Transpose后的图像')
plt.imshow(transformed_image)
plt.show()
6、RandomCrop 随机裁剪
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.RandomCrop(512, 512,always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('RandomCrop后的图像')
plt.imshow(transformed_image)
plt.show()
7、RandomGamma 随机灰度系数
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.RandomGamma(gamma_limit=(20, 20), eps=None, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('RandomGamma后的图像')
plt.imshow(transformed_image)
plt.show()
8、RandomRotate90 将输入随机旋转90度,N次
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.RandomRotate90(always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('RandomRotate90后的图像')
plt.imshow(transformed_image)
plt.show()
10、ShiftScaleRotate 随机平移,缩放和旋转输入
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.ShiftScaleRotate(shift_limit=0.0625, scale_limit=0.1, rotate_limit=45, interpolation=1, border_mode=4, value=None, mask_value=None, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') #第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title('ShiftScaleRotate后的图像')
plt.imshow(transformed_image)
plt.show()
11、CenterCrop 裁剪图像的中心部分
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.CenterCrop(256, 256, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("CenterCrop后的图像")
plt.imshow(transformed_image)
plt.show()
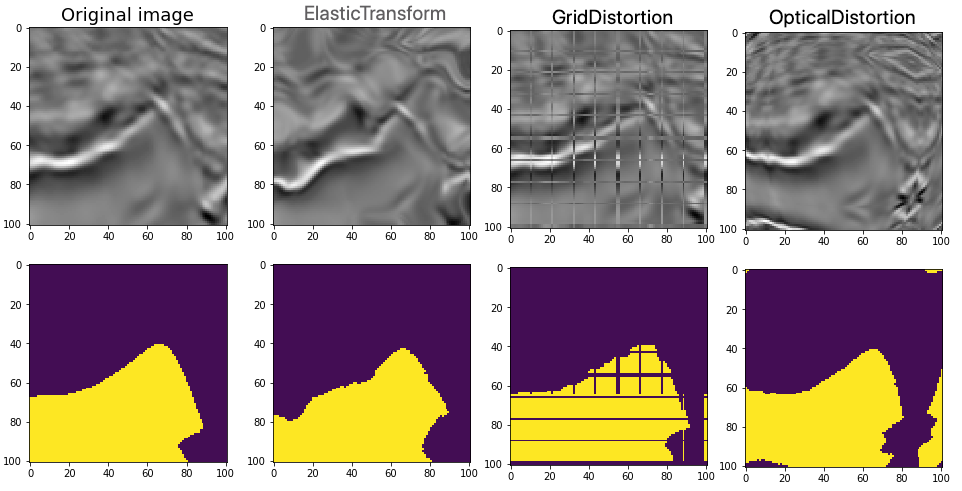
12、GridDistortion网格失真
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.GridDistortion(num_steps=10, distort_limit=0.3,border_mode=4, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("GridDistortion后的图像")
plt.imshow(transformed_image)
plt.show()
13、ElasticTransform 弹性变换
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.ElasticTransform(alpha=5, sigma=50, alpha_affine=50, interpolation=1, border_mode=4,always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("ElasticTransform后的图像")
plt.imshow(transformed_image)
plt.show()
14、RandomGridShuffle把图像切成网格单元随机排列
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.RandomGridShuffle(grid=(3, 3), always_apply=False, p=1) (image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("RandomGridShuffle后的图像")
plt.imshow(transformed_image)
plt.show()
15、HueSaturationValue随机更改图像的颜色,饱和度和值
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.HueSaturationValue(hue_shift_limit=20, sat_shift_limit=30, val_shift_limit=20, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("HueSaturationValue后的图像")
plt.imshow(transformed_image)
plt.show()
16、PadIfNeeded 填充图像
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.PadIfNeeded(min_height=2048, min_width=2048, border_mode=4, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("PadIfNeeded后的图像")
plt.imshow(transformed_image)
plt.show()
17、RGBShift,对图像RGB的每个通道随机移动值
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.RGBShift(r_shift_limit=10, g_shift_limit=20, b_shift_limit=20, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("RGBShift后的图像")
plt.imshow(transformed_image)
plt.show()
18、GaussianBlur 使用随机核大小的高斯滤波器对图像进行模糊处理
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.GaussianBlur(blur_limit=11, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("GaussianBlur后的图像")
plt.imshow(transformed_image)
plt.show()
CLAHE自适应直方图均衡
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.CLAHE(clip_limit=4.0, tile_grid_size=(8, 8), always_apply=False, p=0.5)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("CLAHE后的图像")
plt.imshow(transformed_image)
plt.show()
ChannelShuffle随机重新排列输入RGB图像的通道
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.ChannelShuffle(always_apply=False, p=0.5)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("ChannelShuffle后的图像")
plt.imshow(transformed_image)
plt.show()
InvertImg反色
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.InvertImg(always_apply=False, p=0.5)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("InvertImg后的图像")
plt.imshow(transformed_image)
plt.show()
Cutout 随机擦除
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.Cutout(num_holes=20, max_h_size=20, max_w_size=20, fill_value=0, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("Cutout后的图像")
plt.imshow(transformed_image)
plt.show()
RandomFog随机雾化
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.RandomFog(fog_coef_lower=0.3, fog_coef_upper=1, alpha_coef=0.08, always_apply=False, p=1)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("RandomFog后的图像")
plt.imshow(transformed_image)
plt.show()
GridDropout网格擦除
import albumentations as A
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("aa.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = A.GridDropout(ratio=0.5, unit_size_min=None, unit_size_max=None, holes_number_x=None, holes_number_y=None,
shift_x=0, shift_y=0, always_apply=False, p=0.5)(image=image)
transformed_image = transformed["image"]
plt.subplot(1, 2, 1)
plt.title('原图') # 第一幅图片标题
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.title("GridDropout后的图像")
plt.imshow(transformed_image)
plt.show()
### 附加资源 1. Bertalmio, Marcelo, Andrea L. Bertozzi, and Guillermo Sapiro. “Navier-stokes, fluid dynamics, and image and video inpainting.” In Computer Vision and Pattern Recognition, 2001. CVPR 2001. Proceedings of the 2001 IEEE Computer Society Conference on, vol. 1, pp. I-355. IEEE, 2001. 2. Telea, Alexandru. “An image inpainting technique based on the fast marching method.” Journal of graphics tools 9.1 (2004): 23-34.
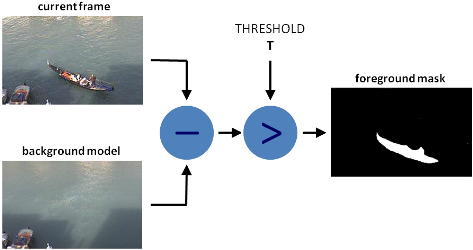
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
cap = cv.VideoCapture('vtest.avi')
# 创建5个帧的列表
img = [cap.read()[1] for i in xrange(5)]
# 将所有转化为灰度
gray = [cv.cvtColor(i, cv.COLOR_BGR2GRAY) for i in img]
# 将所有转化为float64
gray = [np.float64(i) for i in gray]
# 创建方差为25的噪声
noise = np.random.randn(*gray[1].shape)*10
# 在图像上添加噪声
noisy = [i+noise for i in gray]
# 转化为unit8
noisy = [np.uint8(np.clip(i,0,255)) for i in noisy]
# 对第三帧进行降噪
dst = cv.fastNlMeansDenoisingMulti(noisy, 2, 5, None, 4, 7, 35)
plt.subplot(131),plt.imshow(gray[2],'gray')
plt.subplot(132),plt.imshow(noisy[2],'gray')
plt.subplot(133),plt.imshow(dst,'gray')
plt.show()
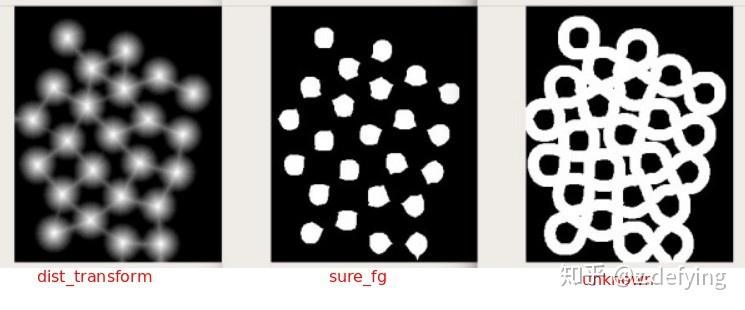
# Marker labelling
ret, markers = cv2.connectedComponents(sure_fg)
# Add one to all labels so that sure background is not 0, but 1
markers = markers+1
# Now, mark the region of unknown with zero
markers[unknown==255] = 0