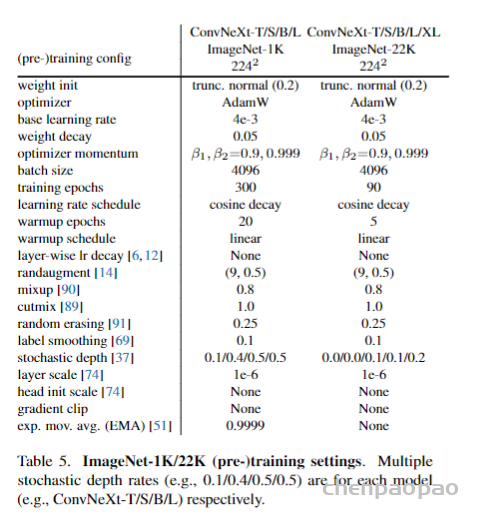
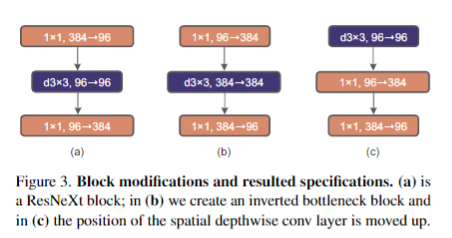
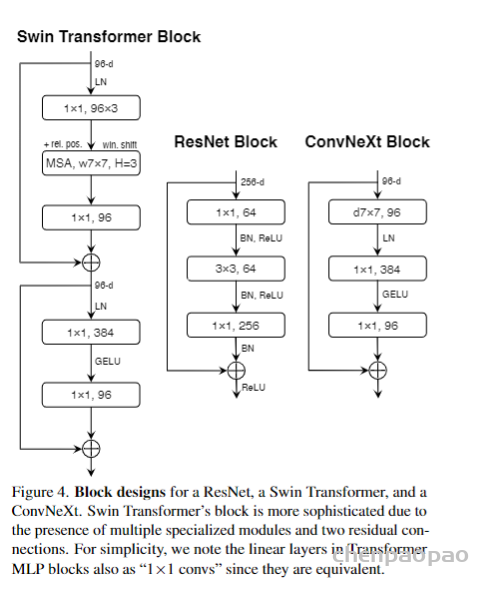
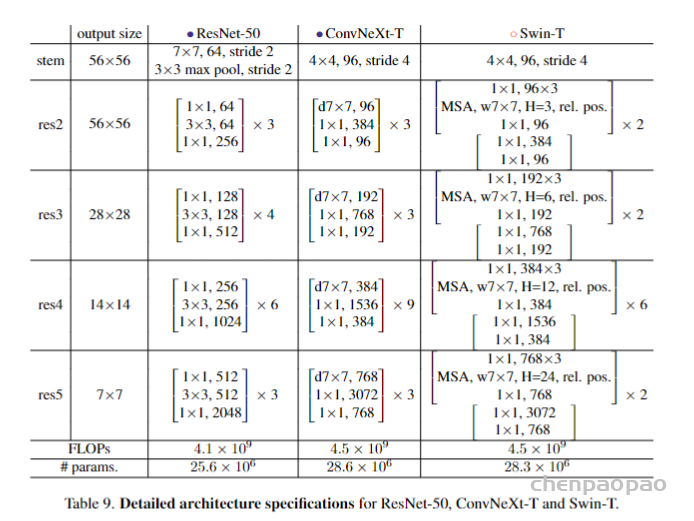
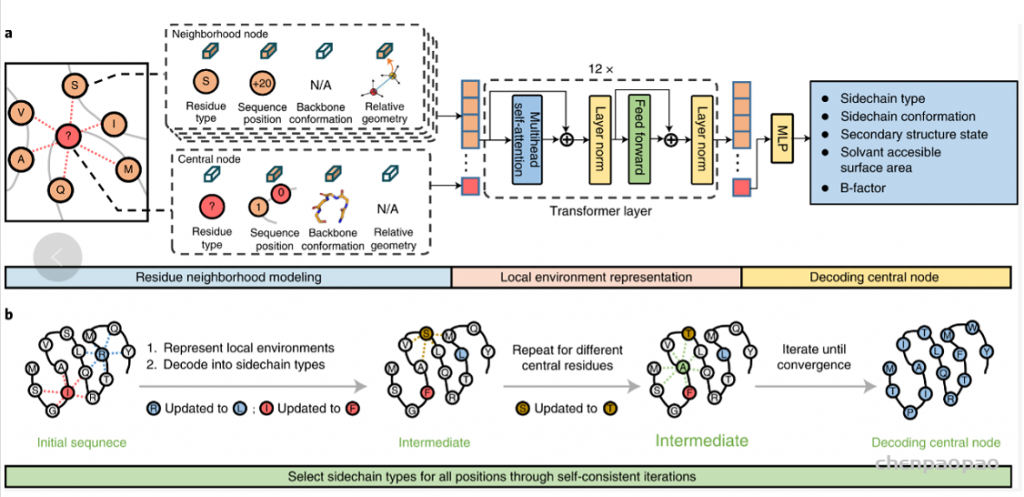
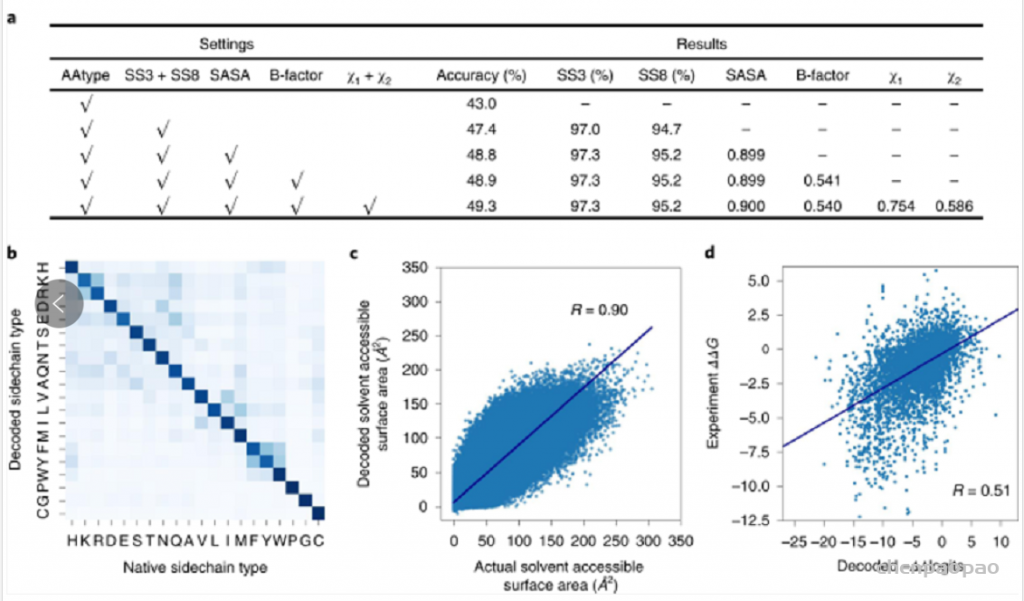
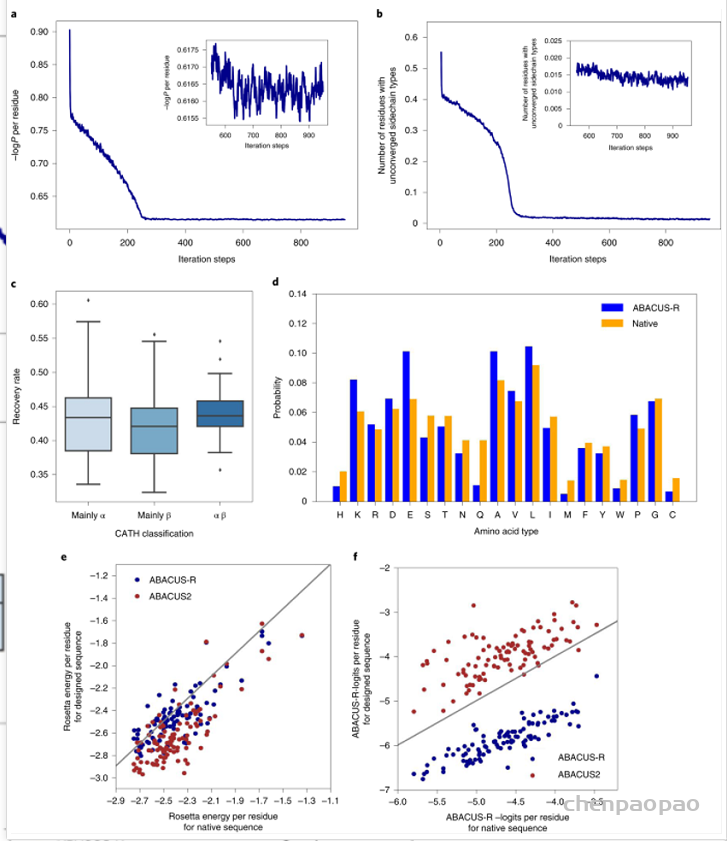
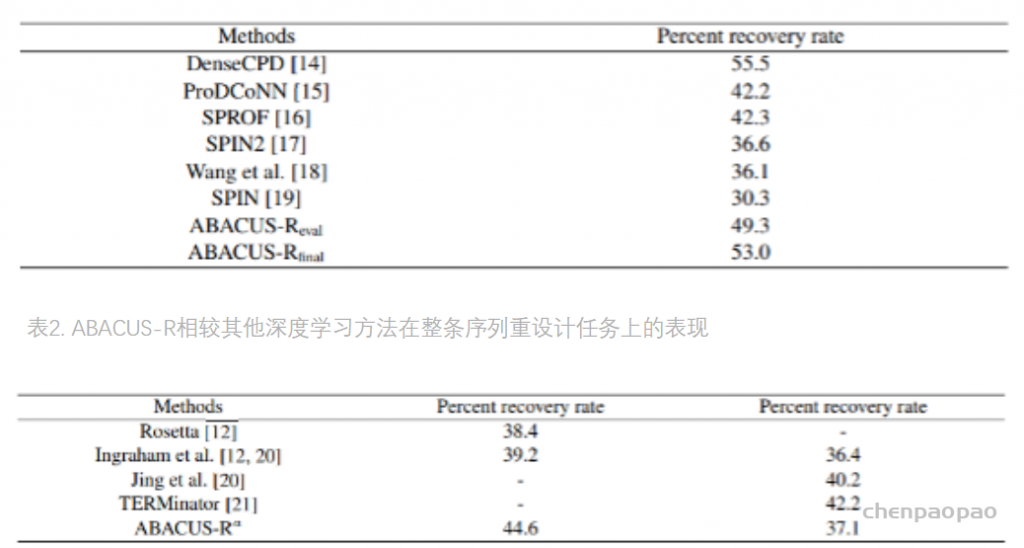
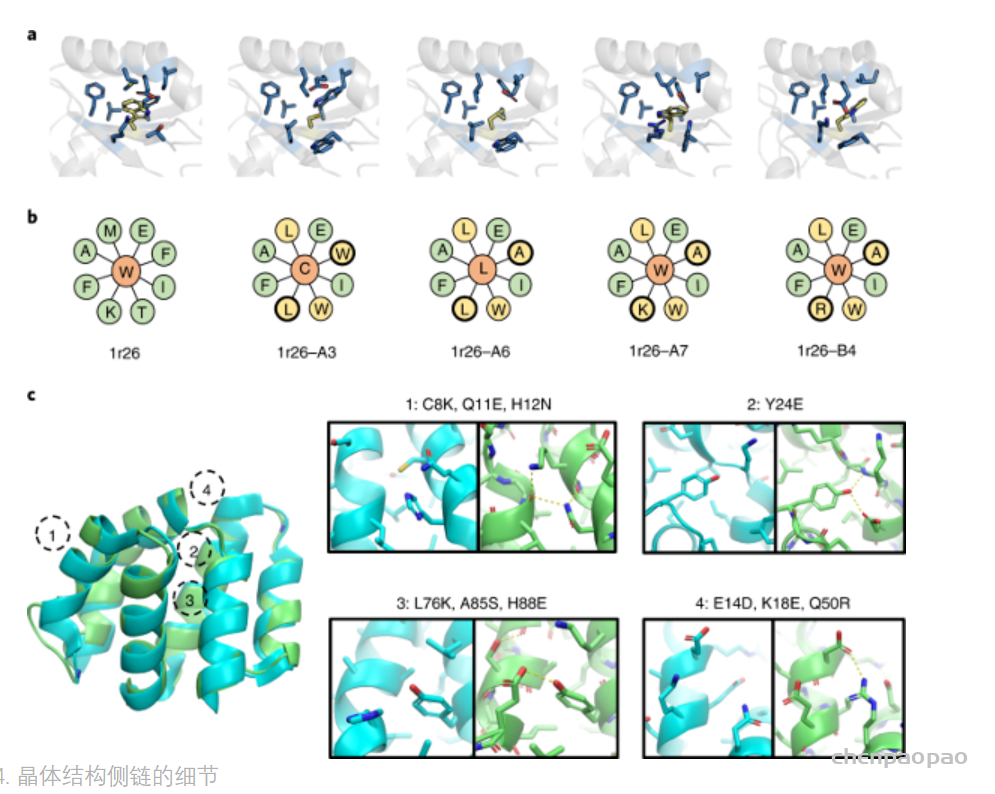
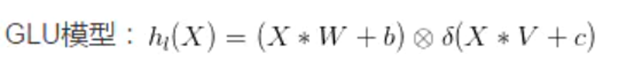现有的基于蛋白结构的深度学习序列设计方法,虽然在测试的计算指标上取得了很好的成果,但是还鲜有方法经过实验的考验仍然超越传统的能量函数方法。基于这一挑战,中国科学技术大学的刘海燕教授课题组,发展了名为ABACUS-R方法,相关工作名为Rotamer-free protein sequence design based on deep learning and self-consistency,于近期发表在Nature Computational Science上。
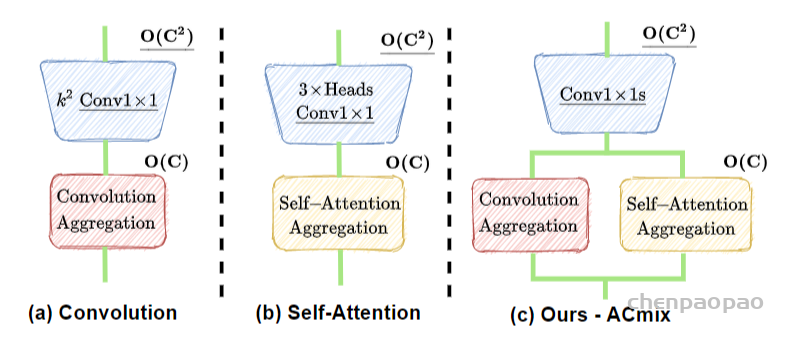
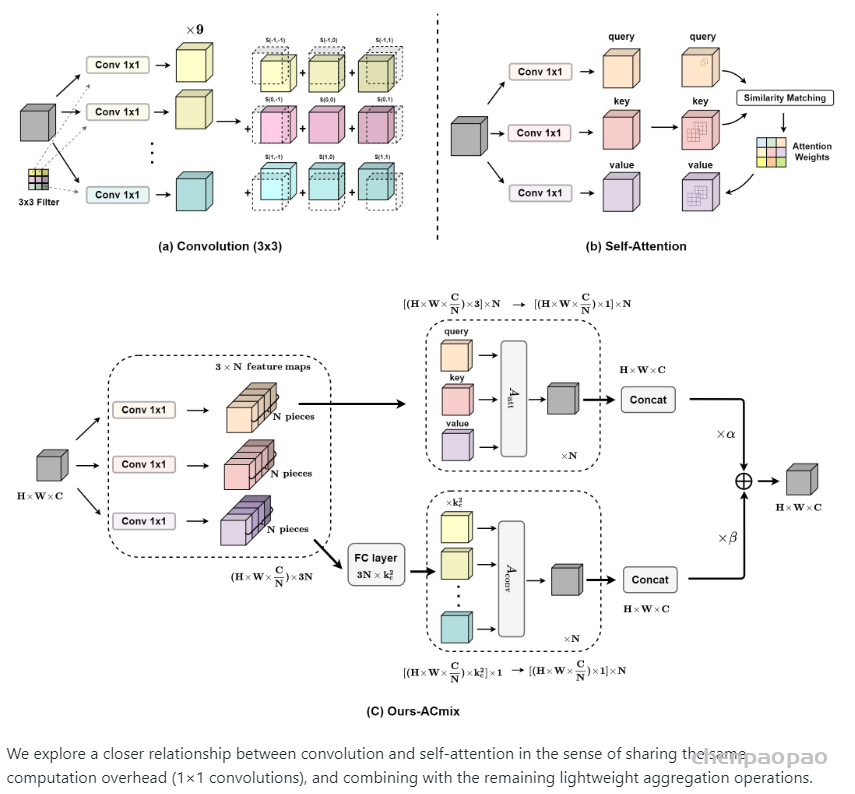
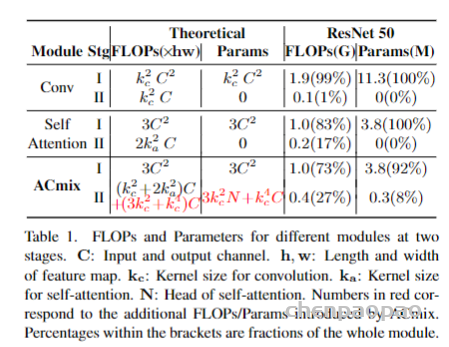
标准卷积可以分为两个部分,第一个阶段为一个特征学习模块,通过执行1 x 1的卷积共享相同的操作将特征投影到更深的空间,第二阶段对应于特征聚合的过程。作为结论,分析表明卷积和自注意力在通过1 x 1的卷积投影输入特征图实际上共享相同的操作,聚合操作是轻量级的,并不需要获取额外的学习参数。卷积和自注意力的示意图如下图所示。
2、将self-attention和convolution进行整合
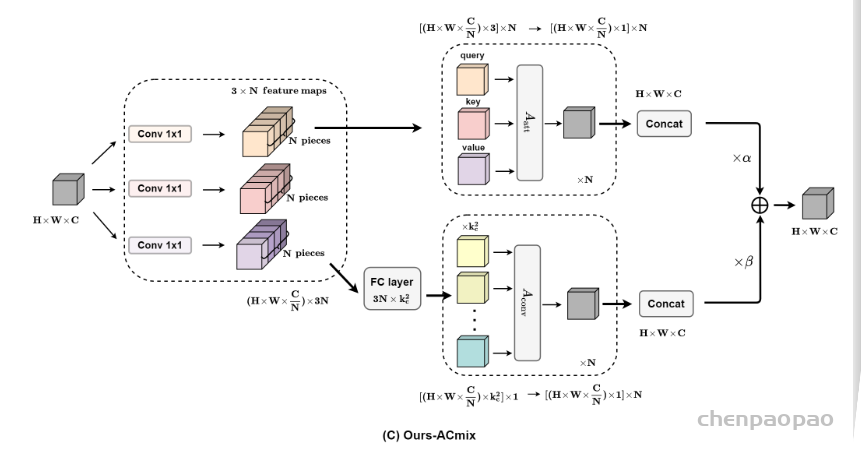
作者根据上述的分析提出ACmix模型,如下图所示:
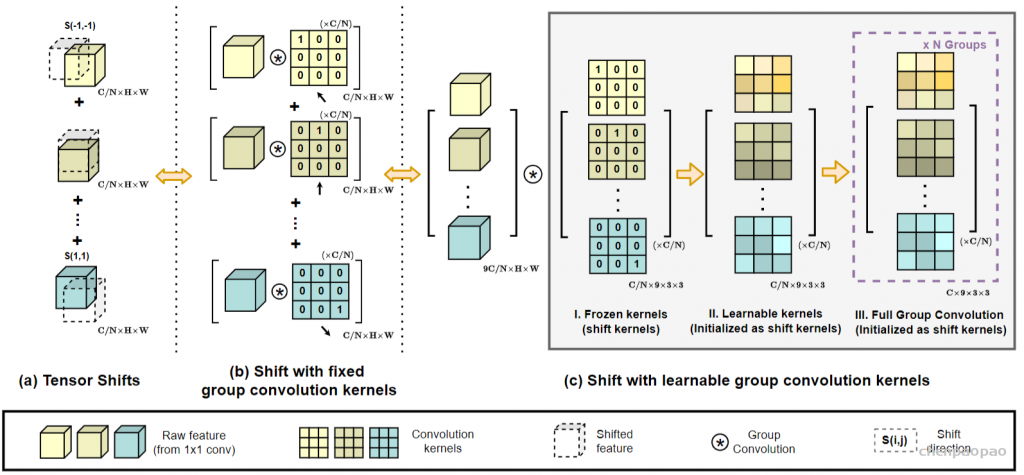
ACmix模型分为两个阶段,在阶段一,输入特征由三个1 x 1的卷积操作并被reshape成N块,由此获得丰富的3 x N的特征图;在阶段二,对于self-attention,作者将中间特征收集到N组中,每组包含三个部分特征,其中每个1 x 1卷积对应一个。通过移动和聚合生成的特征(用以下公式表达),并像传统方法一样从本地感受野中收集信息。
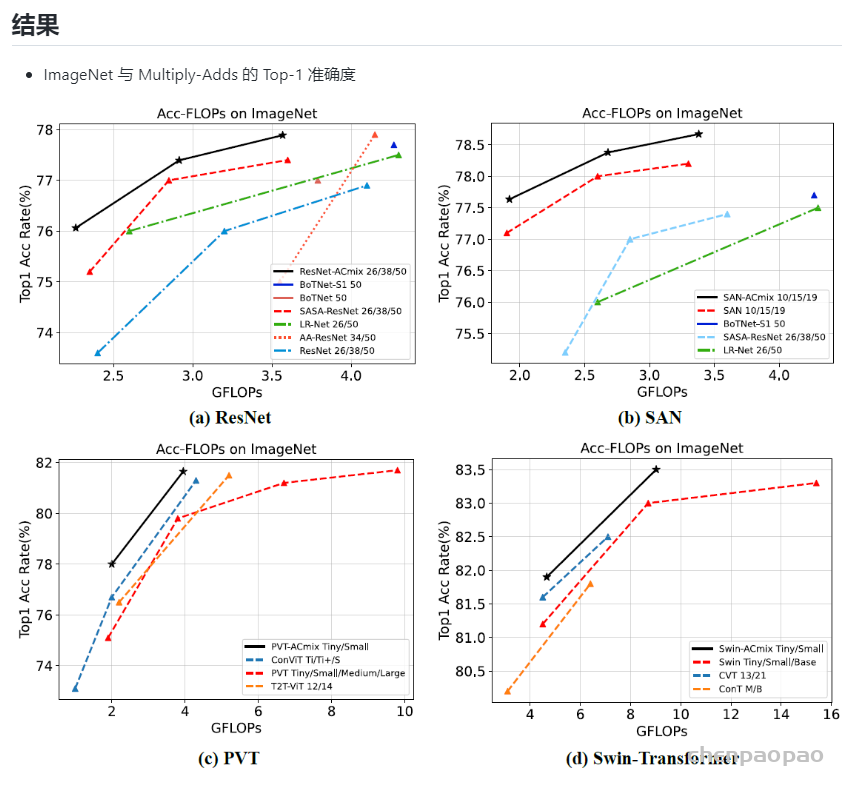
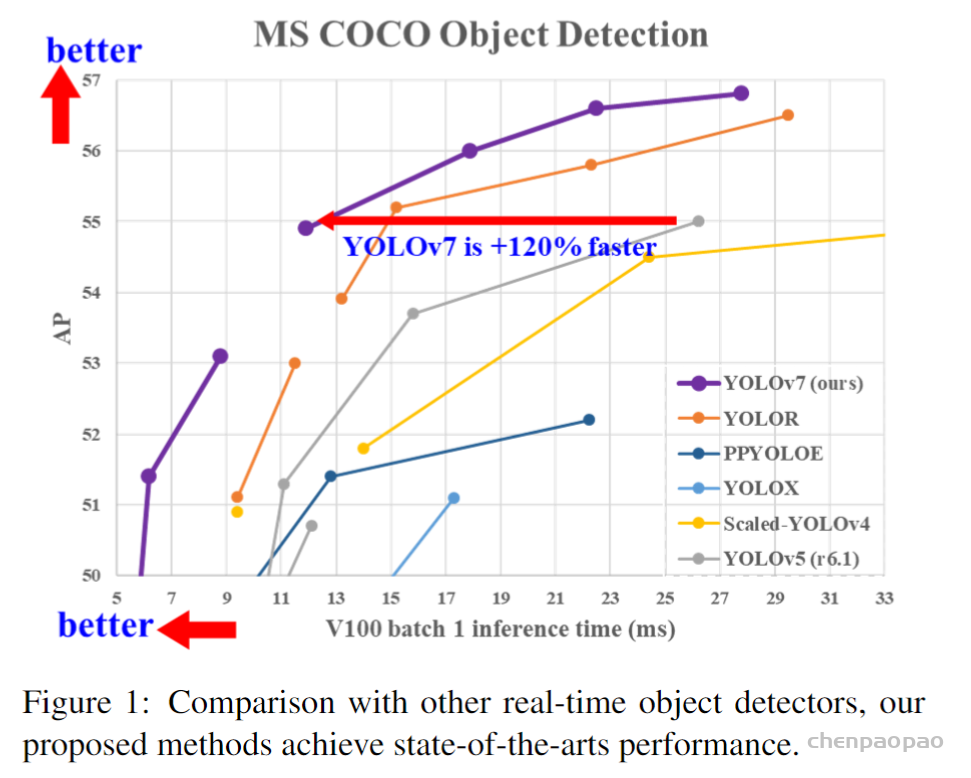
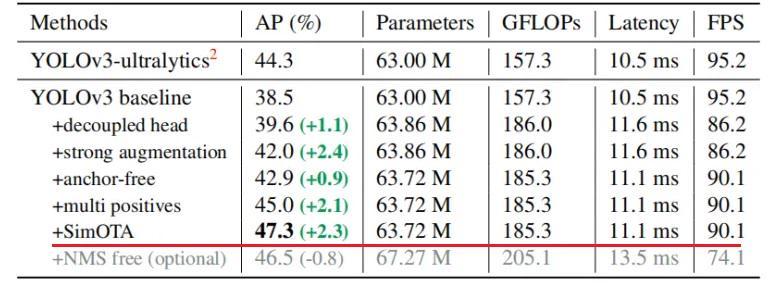
作者为实时探测器提出了“扩展”和“复合缩放”(extend” and “compound scaling”)方法,可以更加高效地利用参数和计算量,同时,作者提出的方法可以有效地减少实时探测器50%的参数,并且具备更快的推理速度和更高的检测精度。(这个其实和YOLOv5或者Scale YOLOv4的baseline使用不同规格分化成几种模型类似,既可以是width和depth的缩放,也可以是module的缩放)
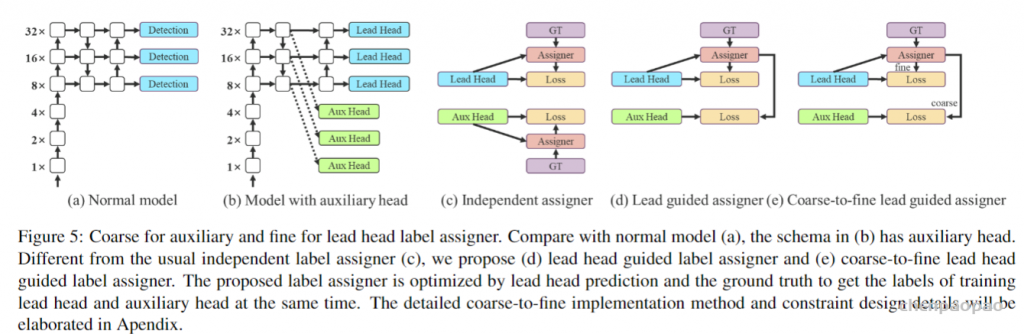
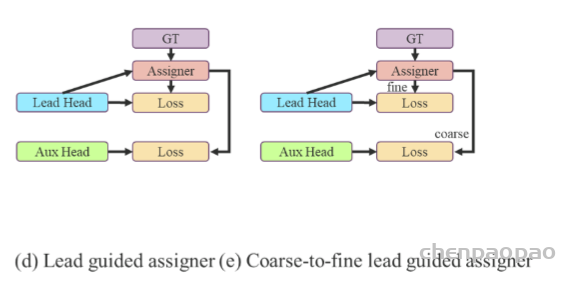
Lead head guided label assigner: 引导头引导“标签分配器”预测结果和ground truth进行计算,并通过优化(在utils/loss.py的SigmoidBin()函数中,传送门:https://github.com/WongKinYiu/yolov7/blob/main/utils/loss.py 生成软标签。这组软标签将作为辅助头和引导头的目标来训练模型。(之前写过一篇博客,【浅谈计算机视觉中的知识蒸馏】]https://zhuanlan.zhihu.com/p/497067556)详细讲过soft label的好处)这样做的目的是使引导头具有较强的学习能力,由此产生的软标签更能代表源数据与目标之间的分布差异和相关性。此外,作者还可以将这种学习看作是一种广义上的余量学习。通过让较浅的辅助头直接学习引导头已经学习到的信息,引导头能更加专注于尚未学习到的残余信息。
Coarse-to-fine lead head guided label assigner: Coarse-to-fine引导头使用到了自身的prediction和ground truth来生成软标签,引导标签进行分配。然而,在这个过程中,作者生成了两组不同的软标签,即粗标签和细标签,其中细标签与引导头在标签分配器上生成的软标签相同,粗标签是通过降低正样本分配的约束,允许更多的网格作为正目标(可以看下FastestDet的label assigner,不单单只把gt中心点所在的网格当成候选目标,还把附近的三个也算进行去,增加正样本候选框的数量)。原因是一个辅助头的学习能力并不需要强大的引导头,为了避免丢失信息,作者将专注于优化样本召回的辅助头。对于引导头的输出,可以从查准率中过滤出高精度值的结果作为最终输出。然而,值得注意的是,如果粗标签的附加权重接近细标签的附加权重,则可能会在最终预测时产生错误的先验结果。
EMA Model:EMA 是一种在mean teacher中使用的技术,作者使用 EMA 模型作为最终的推理模型。
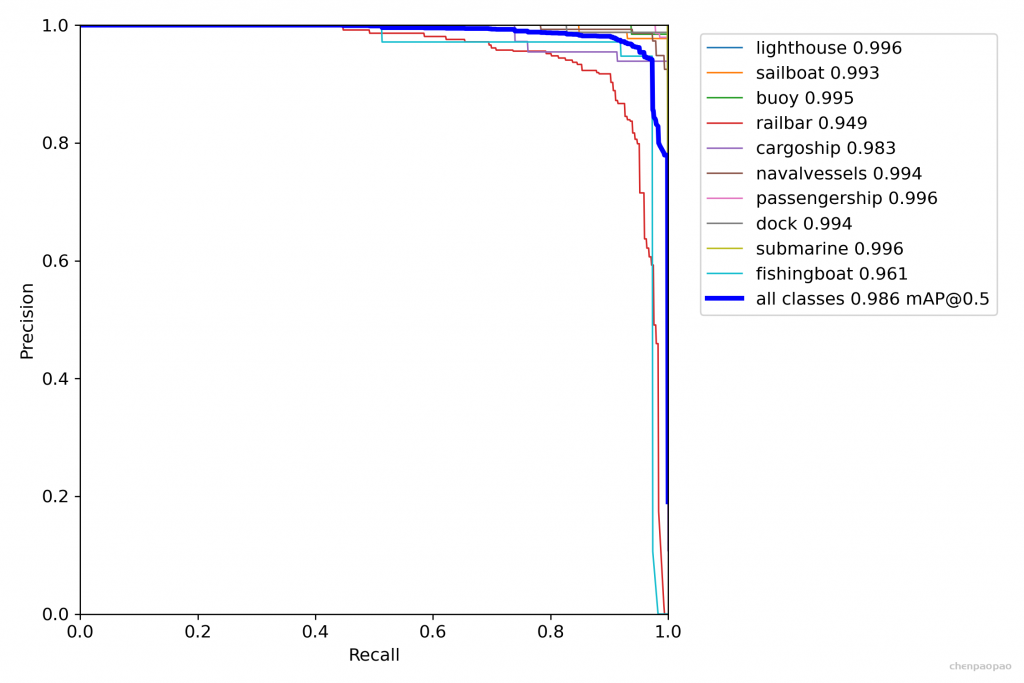
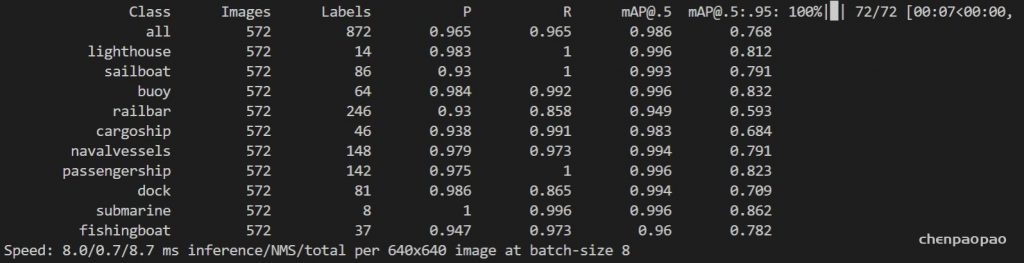
五、实验
5.1 实验环境
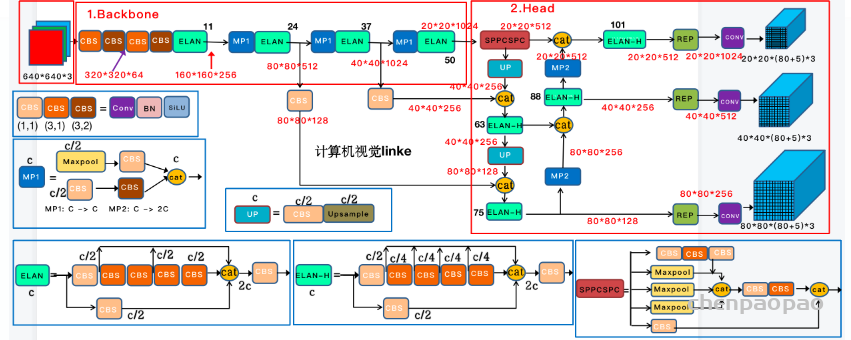
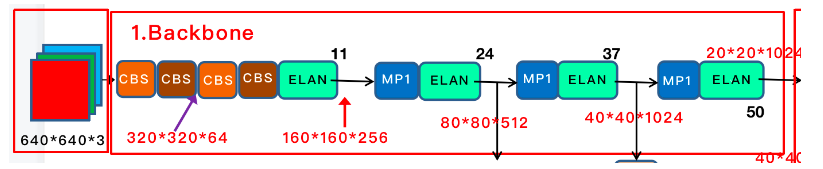
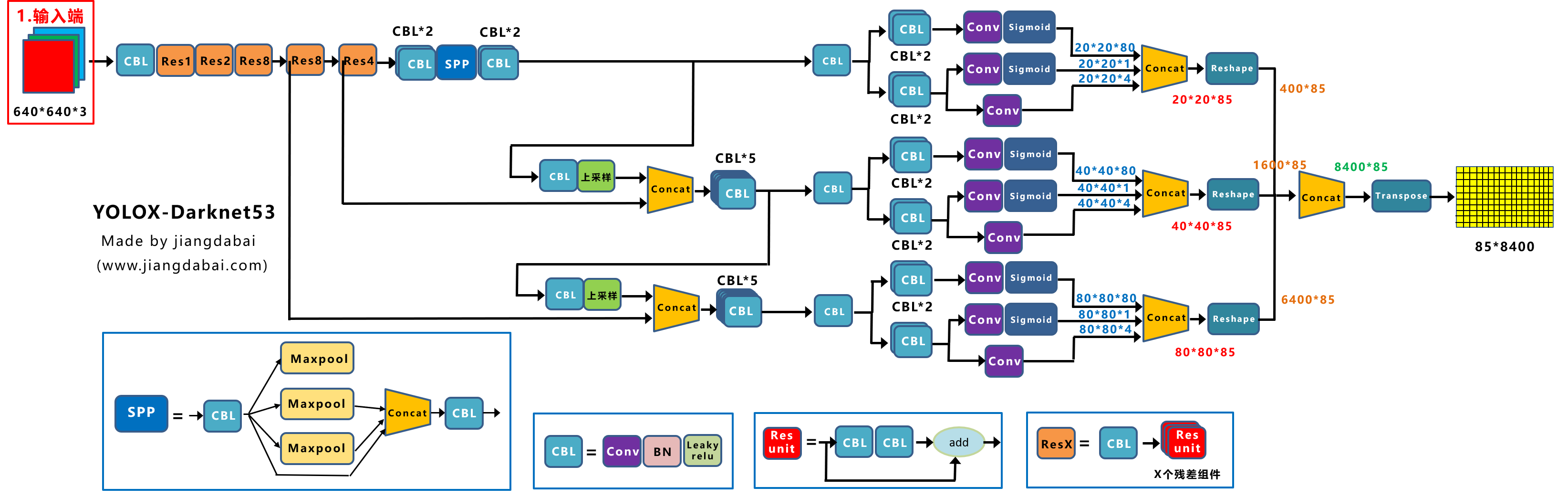
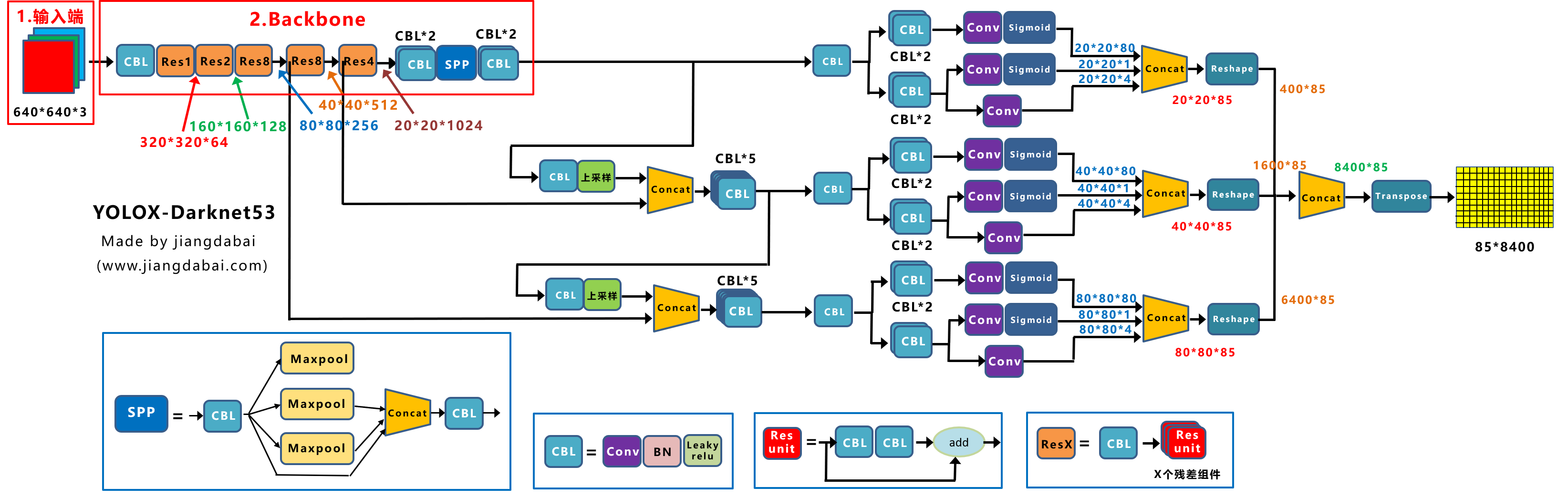
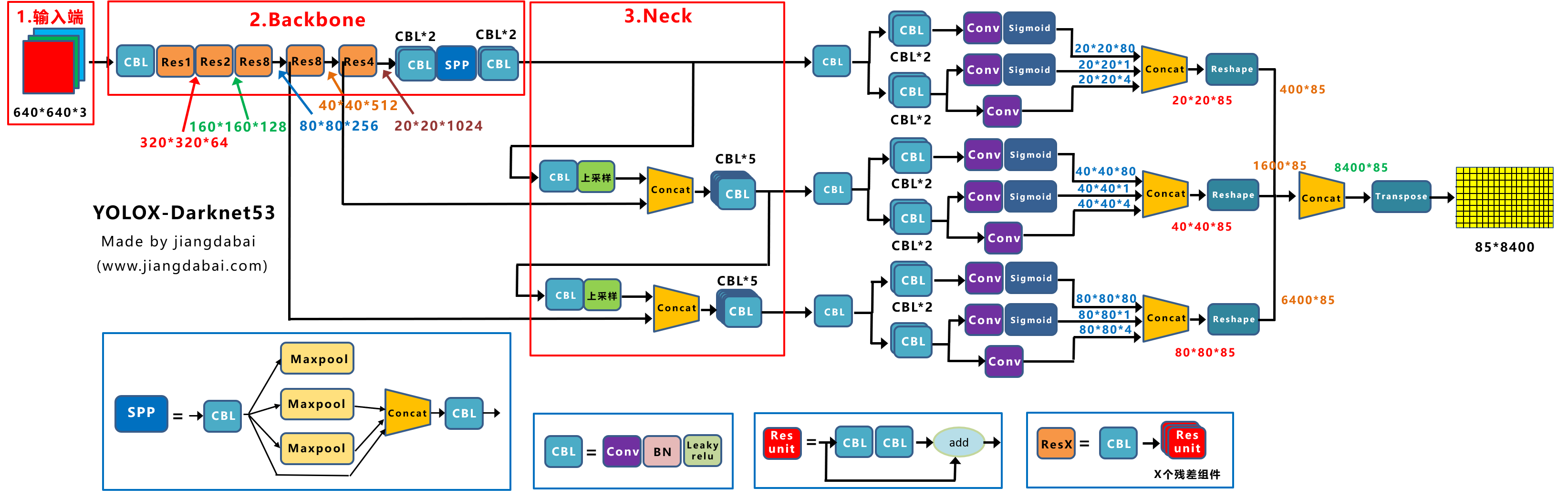
作者为边缘GPU、普通GPU和云GPU设计了三种模型,分别被称为YOLOv7-Tiny、YOLOv7和YOLOv7-W6。同时,还使用基本模型针对不同的服务需求进行缩放,并得到不同大小的模型。对于YOLOv7,可进行颈部缩放(module scale),并使用所提出的复合缩放方法对整个模型的深度和宽度进行缩放(depth and width scale),此方式获得了YOLOv7-X。对于YOLOv7-W6,使用提出的缩放方法得到了YOLOv7-E6和YOLOv7-D6。此外,在YOLOv7-E6使用了提出的E-ELAN,从而完成了YOLOv7-E6E。由于YOLOv7-tincy是一个面向边缘GPU架构的模型,因此它将使用ReLU作为激活函数。作为对于其他模型,使用SiLU作为激活函数。
Considering YOLOv4 and YOLOv5 may be a little over-optimized for the anchor-based pipeline, we choose YOLOv3 [25] as our start point (we set YOLOv3-SPP as the default YOLOv3)。
AP % AP at IoU=0.50:0.05:0.95 (primary challenge metric)
APIoU=.50 % AP at IoU=0.50 (PASCAL VOC metric)
APIoU=.75 % AP at IoU=0.75 (strict metric)
AP Across Scales:
APsmall % AP for small objects: area < 322
APmedium % AP for medium objects: 322 < area < 962
APlarge % AP for large objects: area > 962
Average Recall (AR):
ARmax=1 % AR given 1 detection per image
ARmax=10 % AR given 10 detections per image
ARmax=100 % AR given 100 detections per image
AR Across Scales:
ARsmall % AR for small objects: area < 322
ARmedium % AR for medium objects: 322 < area < 962
ARlarge % AR for large objects: area > 962
1)除非另有说明,否则AP和AR在多个交汇点(IoU)值上取平均值。具体来说,我们使用10个IoU阈值0.50:0.05:0.95。这是对传统的一个突破,其中AP是在一个单一的0.50的IoU上计算的(这对应于我们的度量APIoU=.50 )。超过均值的IoUs能让探测器更好定位(Averaging over IoUs rewards detectors with better localization.)。
2)AP是所有类别的平均值。传统上,这被称为“平均精确度”(mAP,mean average precision)。我们没有区分AP和mAP(同样是AR和mAR),并假定从上下文中可以清楚地看出差异。
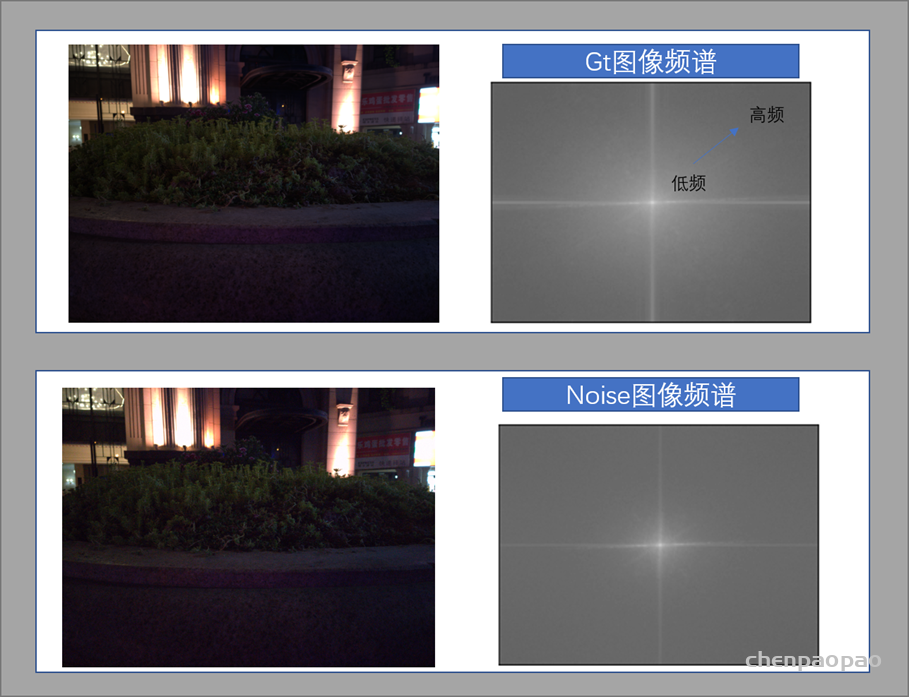
图像去噪赛题背景图像去噪是机器视觉领域重要任务,图像去噪模块在安防,自动驾驶,传感,医学影像,消费电子等领域都是重要的前端图像处理模块。消费级电子产品(例如手机)出于成本考虑,在低照度和高ISO条件下,噪声对成像质量的降级更加严重。对于传统图像处理算法,常见去噪算法包含双边(bilateral)滤波,NLM (non local mean)滤波,BM3D,多帧(3D)降噪方案等多种方案,产品实现上需要兼顾性能和复杂度。 AI可进一步提升图像主客观质量在学术和工业界得到了广泛认证。对于手机产品,AI正快速补充和替代传统手机ISP(Image signal processing)中的痛点难点,例如可进行AI-based去噪,动态范围增强,超分辨,超级夜景,甚至AI ISP等。
【ChannelNets: Compact and Efficient Convolutional Neural Networks via Channel-Wise Convolutions:论文提出channel-wise卷积的概念,将输入输出的维度连接进行稀疏化而非全连接,区别于分组卷积的严格分组,让卷积在channel维度上进行滑动,能够更好地保留channel间的信息交流。基于channel-wise卷积的思想,论文进一步提出了channel-wise深度可分离卷积,并基于该结构替换网络最后的全连接层+全局池化的操作,搭建了ChannelNets。Channel-wise卷积的核心在于输入和输出连接的稀疏化,每个输出仅与部分输入相连,概念上区别于分组卷积,没有对输入进行严格的区分,而是以一定的stride去采样多个相关输入进行输出(在channel维度滑动),能够降少参数量以及保证channel间一定程度的信息流。】
参考论文:Fouier Space Losses for Efficient Perceptual Image Super-Resolution,在改论文中利用transformer实现图像去雨,提出了Fourier Space Losses,单张图像超分方法在重构高分辨率图像时缺失高频细节。这通常通过有监督的训练来执行,其中使用已知核对真实图像 y 进行下采样,例如 bicubic,得到LR输入图像x。虽然这种方法能够在某种应用中尽可能恢复频率信息,但高频信息却难以恢复,容易出现模糊情况。近几年,许多研究者使用GAN,用于学习高频空间的分布。丢失了频谱空间的高频信息。因此,文章提出了一种用于频域的损失函数。首先,将真实图像和生成图像经过Hann window预处理。接着,计算傅里叶频域损失函数,包括L1范数度量的频谱差异,以及相位角差异
Improving Generalization Performance by Switching from Adam to SGD 提出了Adam+SGD 组合策略。前期用Adam,享受Adam快速收敛的优势;后期切换到SGD,慢慢寻找最优解。这一方法以前也被研究者们用到,不过主要是根据经验来选择切换的时机和切换后的学习率。这篇文章把这一切换过程傻瓜化,给出了切换SGD的时机选择方法,以及学习率的计算方法,效果看起来也不错。
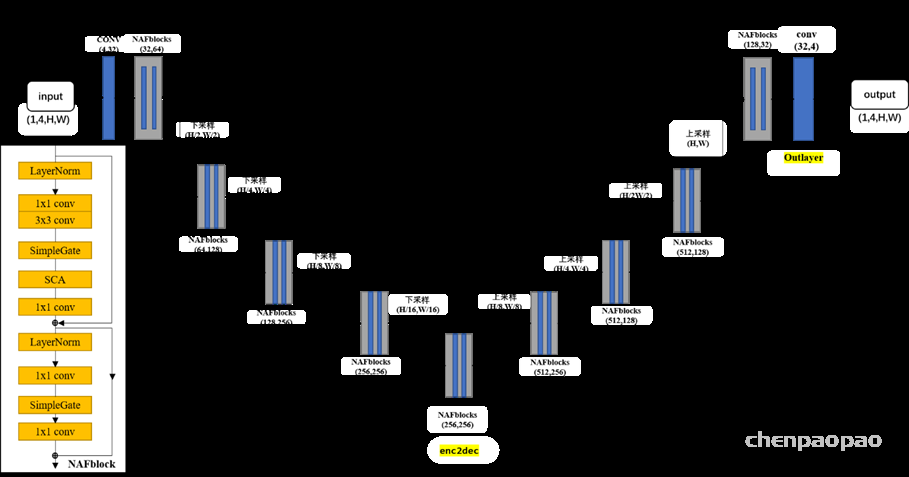
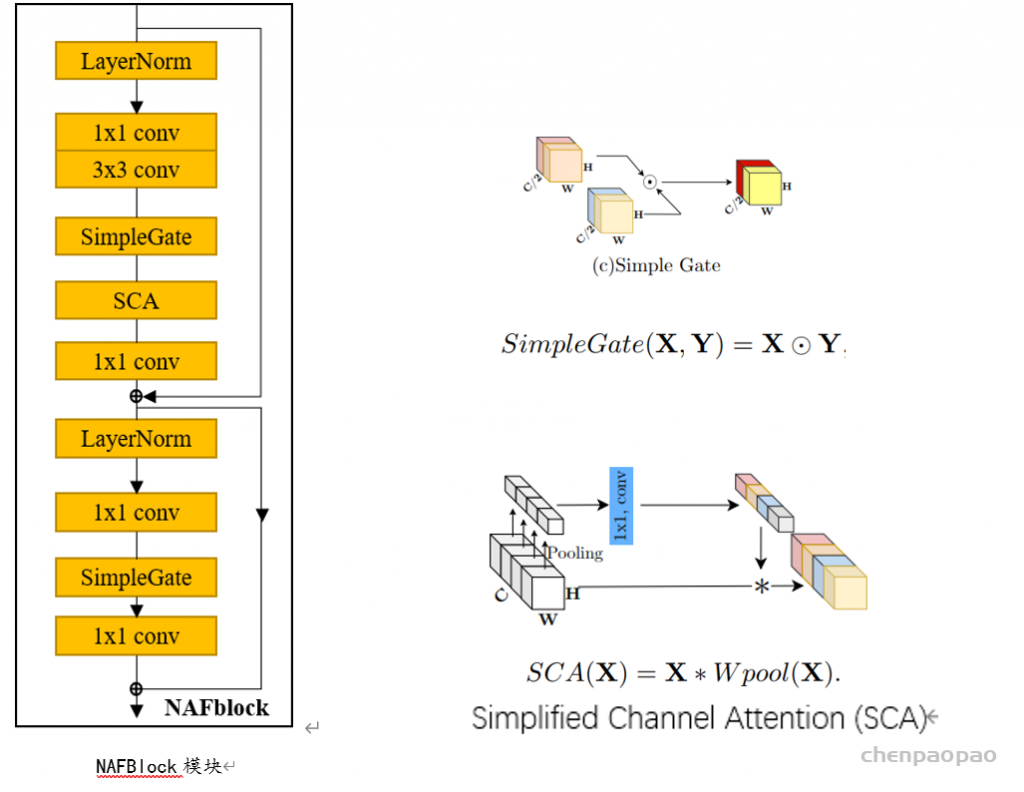
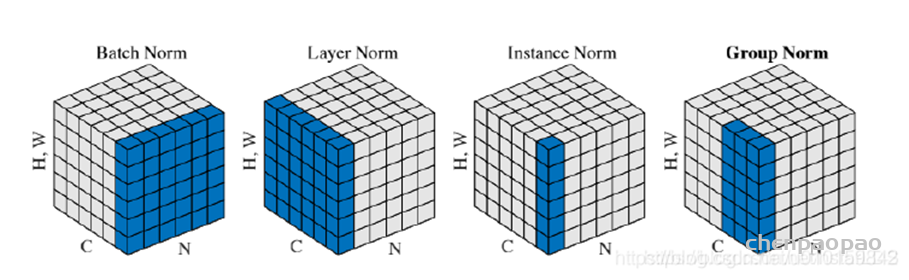
[1] Chen L, Chu X, Zhang X, et al. Simple Baselines for Image Restoration[J]. arXiv preprint arXiv:2204.04676, 2022.
[2] Huang H, Lin L, Tong R, et al. Unet 3+: A full-scale connected unet for medical image segmentation[C]//ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020: 1055-1059.
[3] Wang Y, Huang H, Xu Q, et al. Practical deep raw image denoising on mobile devices[C]//European Conference on Computer Vision. Springer, Cham, 2020: 1-16.
[5] Chen, H., Wang, Y., Guo, T., Xu, C., Deng, Y., Liu, Z., Ma, S., Xu, C., Xu, C., Gao,W.: Pre-trained image processing transformer. In: Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition. pp. 12299–12310 (2021)
[6] Cheng, S., Wang, Y., Huang, H., Liu, D., Fan, H., Liu, S.: Nbnet: Noise basis learning for image denoising with subspace projection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4896–4906 (2021)
[7] Language Modeling with Gated Convolutional Networks
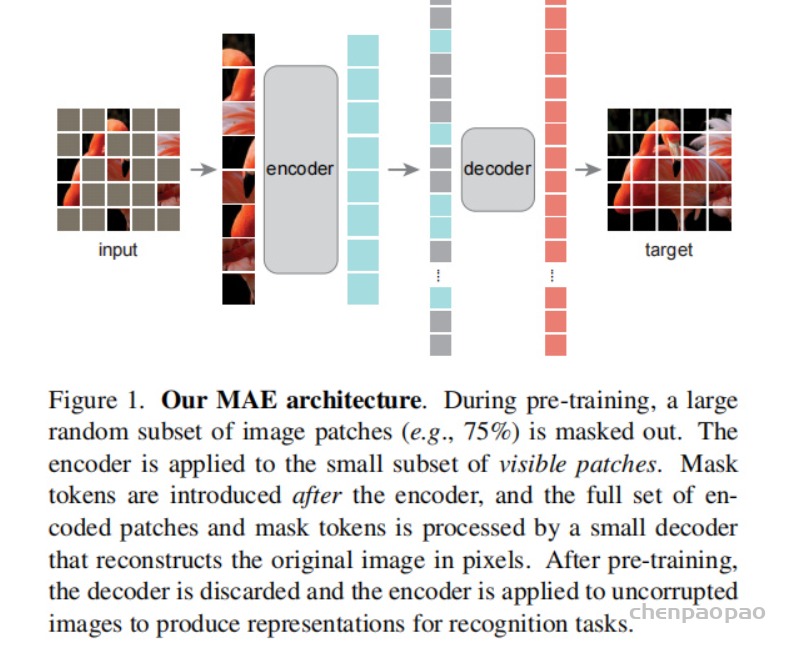
MAE Encoder MAE中的编码器是一种ViT,但仅作用于可见的未被Mask的块。类似于标准ViT,该编码器通过线性投影于位置嵌入对块进行编码,然后通过一系列Transformer模块进行处理。然而,由于该编解码仅在较小子集块(比如25%)进行处理,且未用到掩码Token信息。这就使得我们可以训练一个非常大的编码器 。
MAE Decoder MAE解码器的输入包含:(1) 编码器的输出;(2) 掩码token。正如Figure1所示,每个掩码Token共享的可学习向量,它用于指示待预测遗失块。此时,我们对所有token添加位置嵌入信息。解码器同样包含一系列Transformer模块。



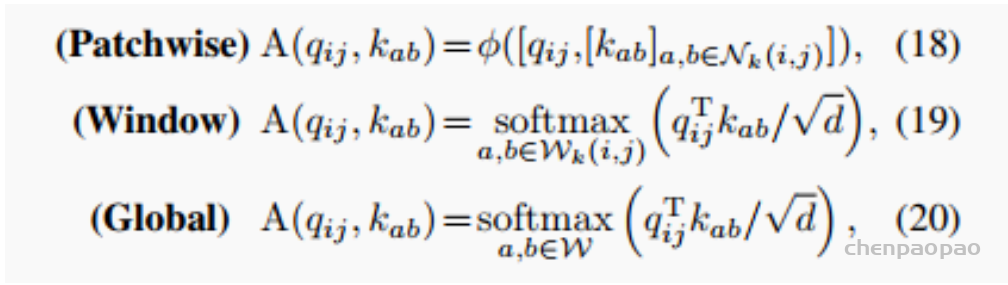

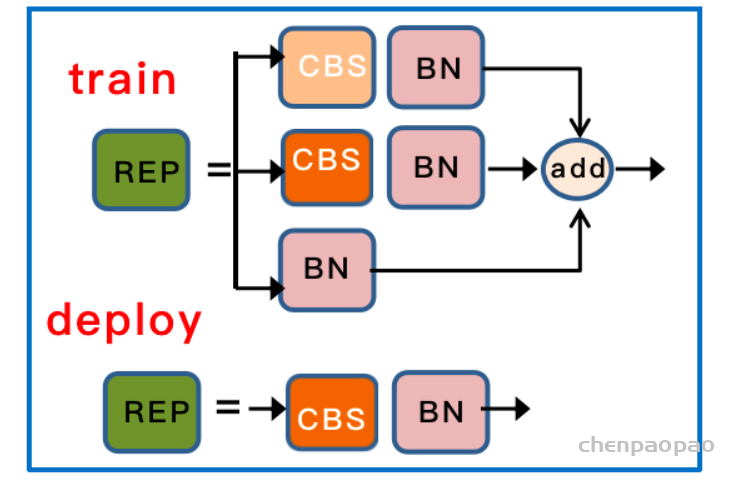
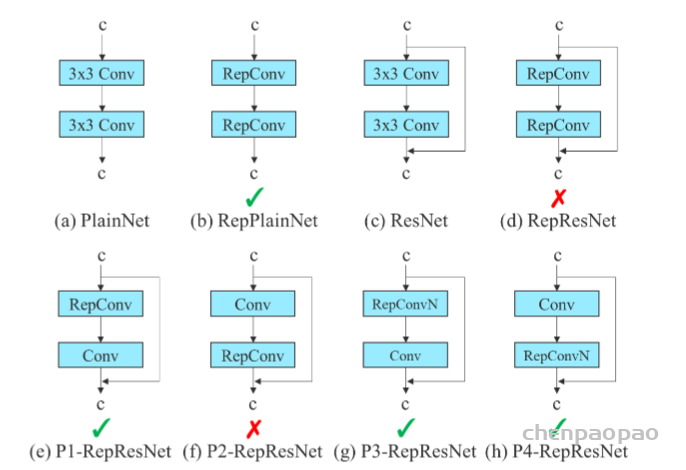

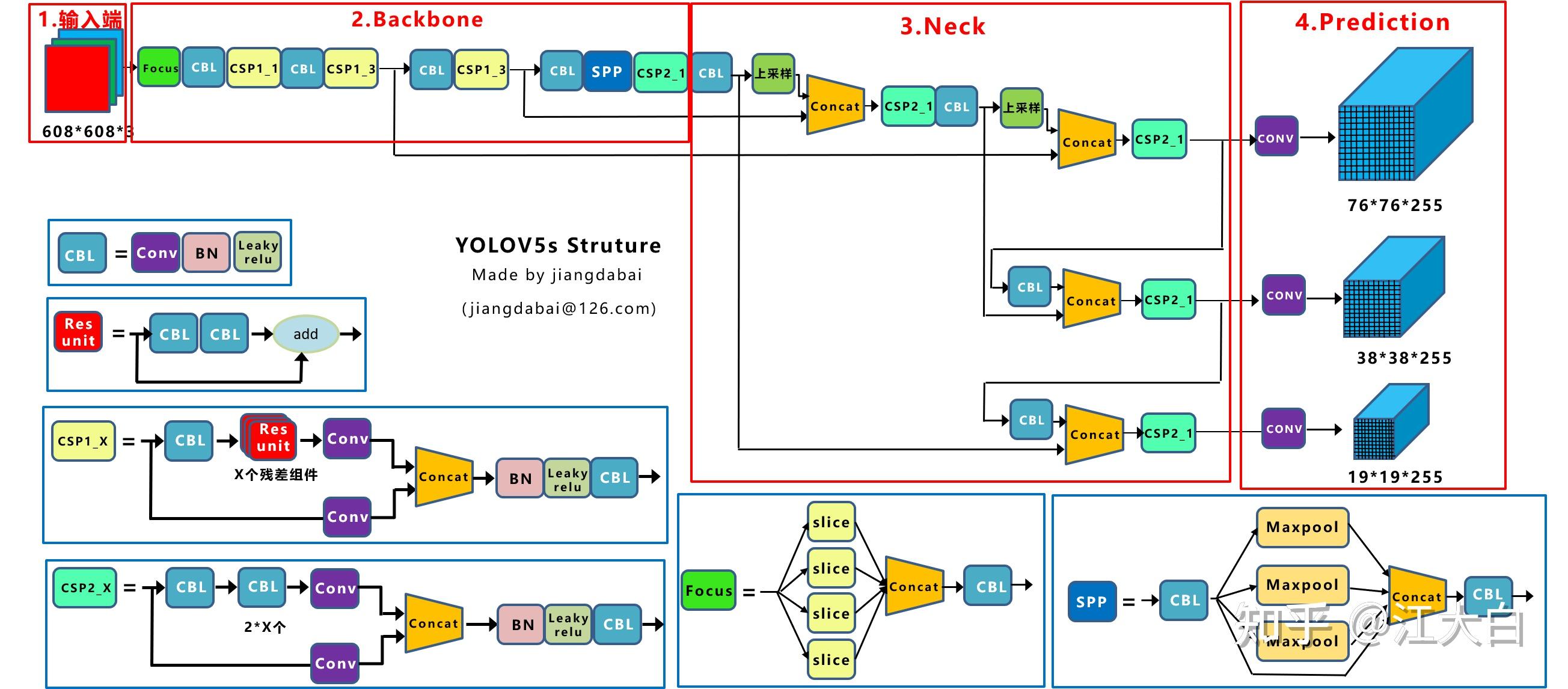
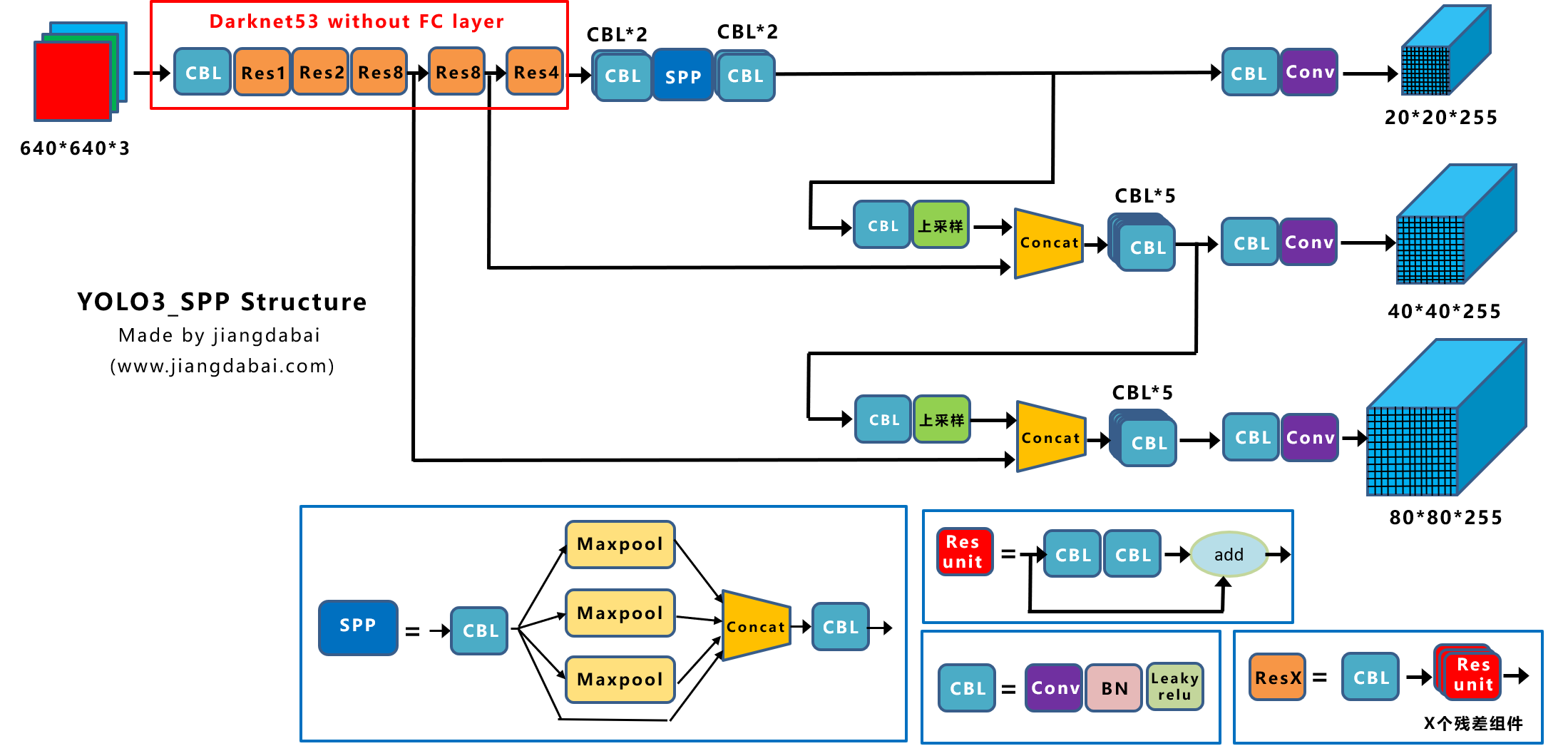
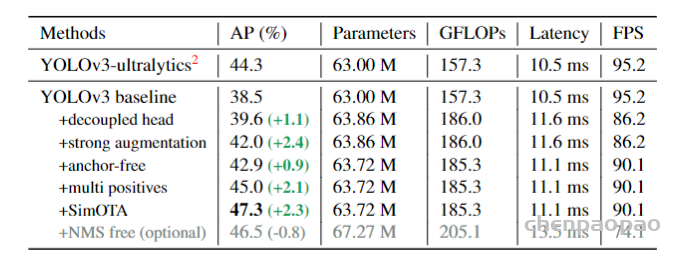
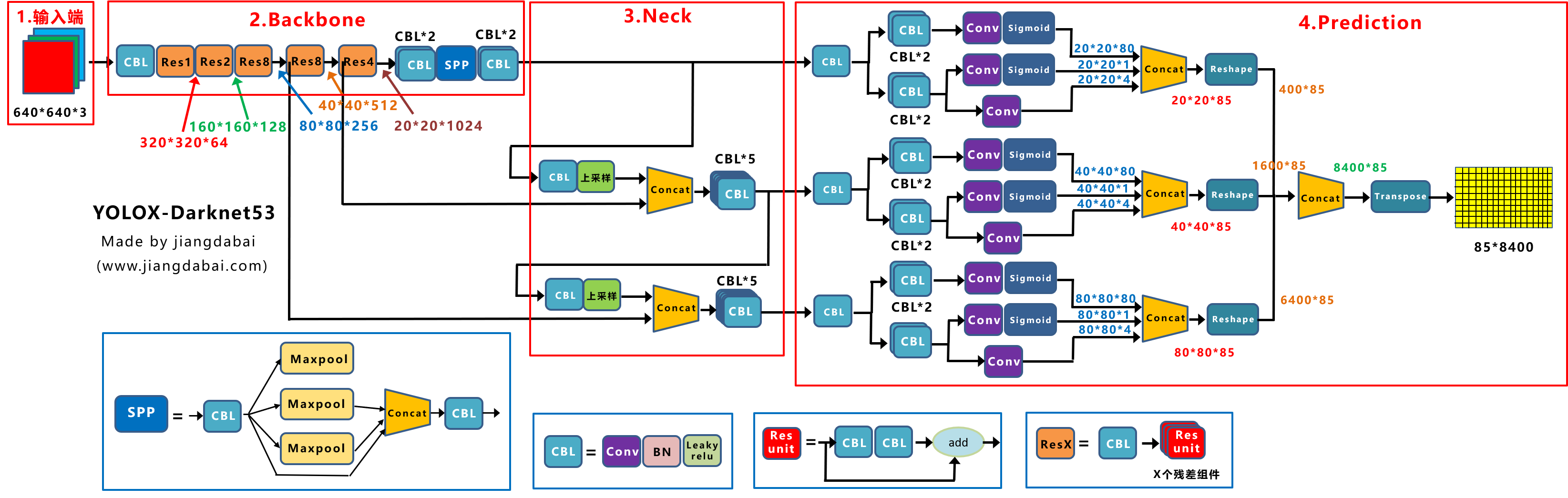





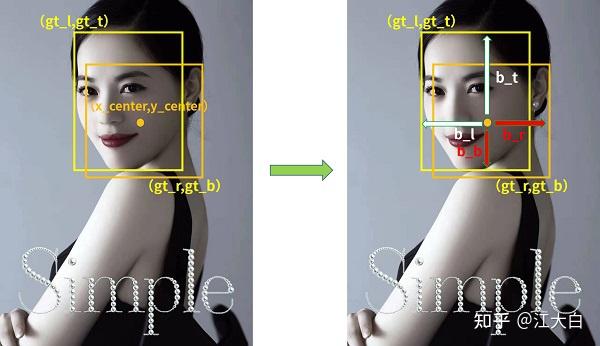
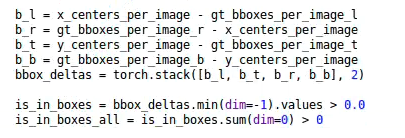

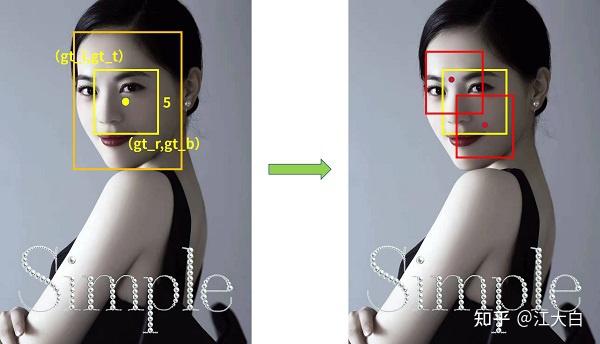

















![图3 Rep算子的融合过程[4]](https://p0.meituan.net/travelcube/9f7878c7872787f9b8706b28e5e7c611237315.png)