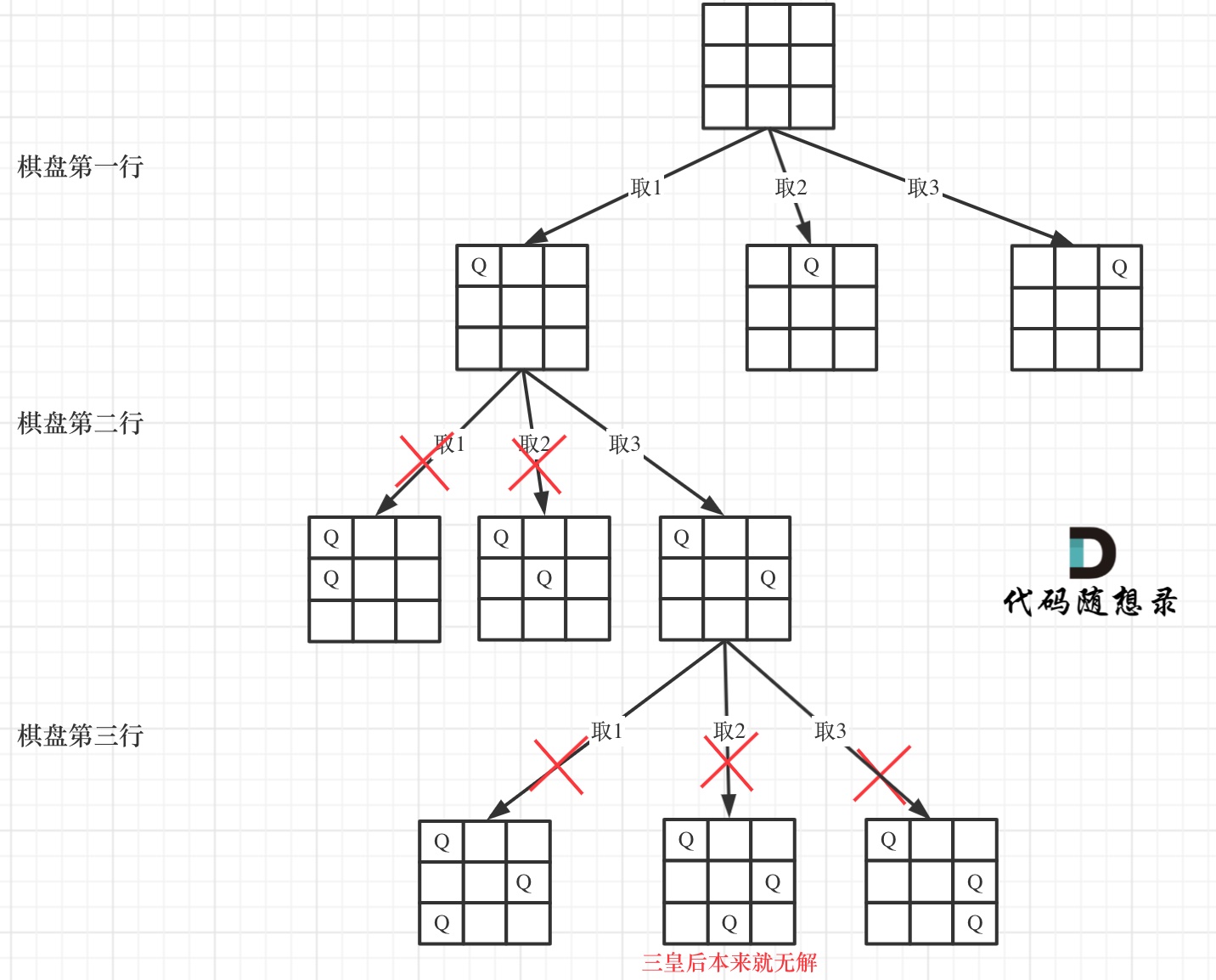
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
示例 1:

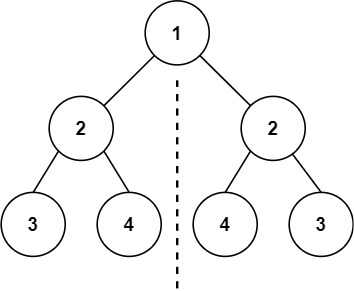
输入:root = [3,9,20,null,null,15,7]
输出:[[3],[9,20],[15,7]]示例 2:
输入:root = [1]
输出:[[1]]示例 3:
输入:root = []
输出:[]层序遍历思路(队列): 二叉树的节点加入队列, 出队的同时将其非空左右孩子依次入队,出队到队列为空即完成遍历。
#
# @lc app=leetcode.cn id=102 lang=python3
#
# [102] 二叉树的层序遍历
#思路就是将二叉树的节点加入队列,
# 出队的同时将其非空左右孩子依次入队,出队到队列为空即完成遍历。
# @lc code=start
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def levelOrder(self, root: TreeNode) -> List[List[int]]:
"""
:type root: TreeNode
:rtype: List[List[int]]
"""
if not root: return [] #注意特殊情况:树为空返回[]
queue = [root]
list1 = []
while queue:
list2 = []
for i in range(len(queue)):
a = queue.pop(0)#元素出队列
if a.left:
queue.append(a.left)
if a.right:
queue.append(a.right)
list2.append(a.val)
list1.append(list2)
return list1
# @lc code=end