给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
叶子节点 是指没有子节点的节点。
示例 1: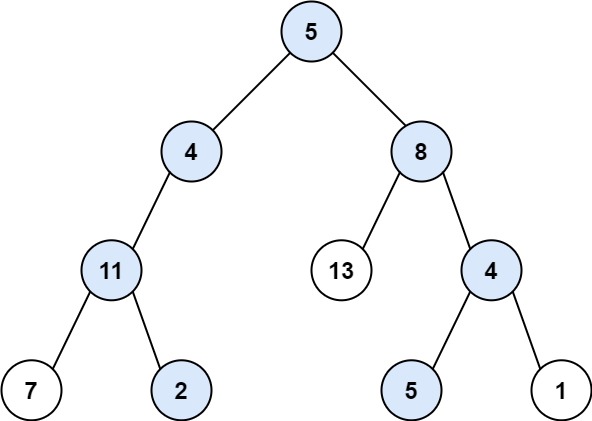
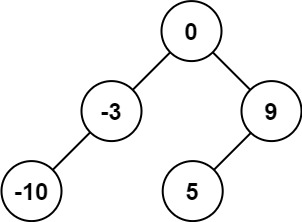
输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22
输出:[[5,4,11,2],[5,8,4,5]]示例 2: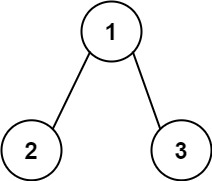
输入:root = [1,2,3], targetSum = 5
输出:[]示例 3:
输入:root = [1,2], targetSum = 0
输出:[]# [113] 路径总和 II
#
# @lc code=start
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def pathSum(self, root: Optional[TreeNode], targetSum: int) -> List[List[int]]:
res=list()
rev=list()
def subisBalanced(root,deep,target,rev):
if root.left==None and root.right==None and deep==target:
res.append(rev)
return
if root.left!=None:
deepl=deep+ root.left.val
subisBalanced(root.left,deepl,target,rev+ [root.left.val])
if root.right!=None:
deepr=deep+root.right.val
subisBalanced(root.right,deepr,target,rev+[root.right.val])
if root==None:
return []
else:
rev.append(root.val)
subisBalanced(root,root.val, targetSum,rev)
return res
# @lc code=end