- model:https://huggingface.co/FireRedTeam
- code:https://github.com/FireRedTeam/FireRedASR2S
- paper:https://arxiv.org/pdf/2603.10420
FireRedASR: Open-Source Industrial-Grade
Mandarin Speech Recognition Models
from Encoder-Decoder to LLM Integration
FireRedASR2S 是一款最先进的(SOTA)工业级一体化 ASR 系统,包含 ASR、VAD、LID 和 Punc 模块。所有模块均达到 SOTA 性能水平。其核心定位是解决传统语音识别方案功能单一、多语言支持差、方言识别精度低、模块衔接繁琐等问题,打造一套集语音识别、语音活动检测、语言识别、标点预测于一体的端到端解决方案。FireRedASR2S的命名中,2代表第二代FireRedASR模型,S代表扩展为全功能的语音识别系统(System),区别于单一的语音识别模型,实现了语音处理全流程的覆盖。
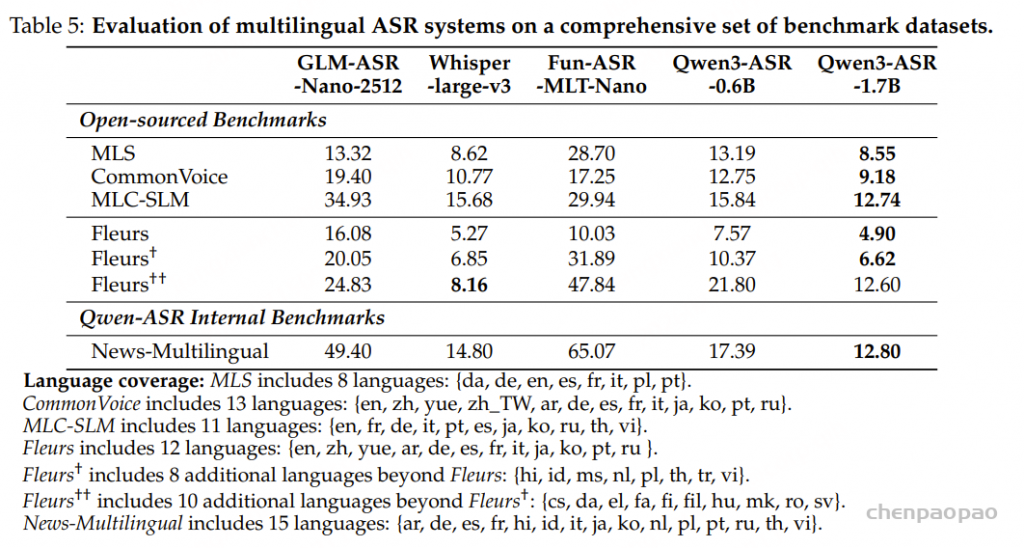
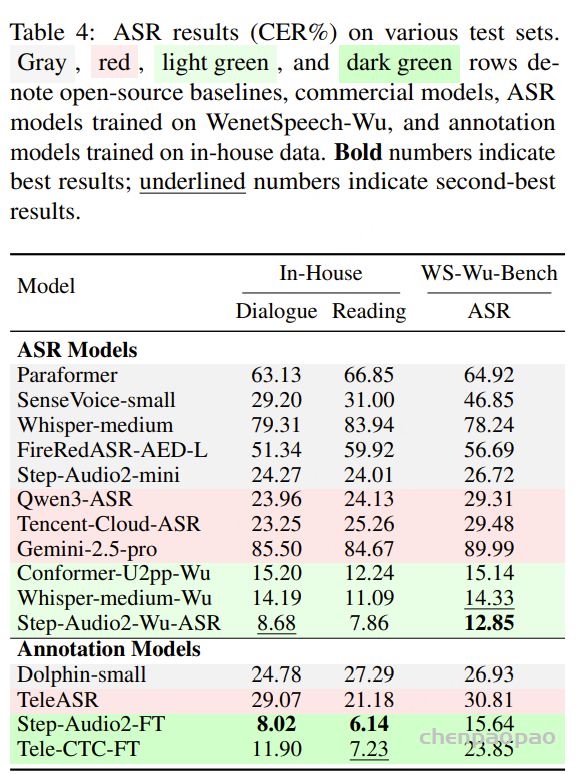
FireRedASR2:将有监督训练数据扩充至约 20 万小时,覆盖更多领域、语种与方言场景。支持中文(普通话及 20+ 种方言/口音)、英文、代码混说以及歌曲歌词识别。在普通话 4 个测试集上平均字符错误率(CER)为 2.89%,在 19 个中文方言测试集上平均 CER 为 11.55%,性能优于 Doubao-ASR、Qwen3-ASR-1.7B、Fun-ASR 和 Fun-ASR-Nano-2512。FireRedASR2-AED 版本还支持词级时间戳和置信度输出,能精准定位语音对应文字的时间区间,满足字幕制作、语音标注等精细化需求。FireRedASR2-AED 支持最长 60 秒的音频输入,FireRedASR2-LLM 支持最长 30 秒的音频输入。
- FireRedASR2-LLM:采用编码器-适配器-大语言模型(Encoder-Adapter-LLM)架构,借助大语言模型的语义理解能力,实现端到端的语音交互,追求极致的识别精度,适合对准确率要求高的场景(如会议转写);
- FireRedASR2-AED:基于注意力机制的编码器-解码器(Attention-based Encoder-Decoder)架构,在精度和计算效率间做平衡,是LLM-based语音模型的高效语音表征模块,支持时间戳输出,适合轻量化落地场景,解码端增加CTC分支,用于对齐音频和文本获取词级别的时间戳信息。
FireRedVAD:语音活动检测(VAD)基于数千小时人工精标声学事件数据训练,支持 100+ 种语言的语音、歌声及音乐检测,F1 值达到 97.57%,优于 Silero-VAD、TEN-VAD 和 FunASR-VAD。支持流式与非流式 VAD,以及音频事件检测。能精准区分语音、歌唱、音乐三类音频事件,输出各事件的时间区间和占比。
- 基于深度前馈序列记忆网络(DFSMN)打造,针对多语言音频做了特征适配,通过滑动窗口平滑、阈值筛选等策略,降低误检和漏检率;同时设计了流式和非流式两种推理逻辑,流式VAD支持实时音频检测,适配直播、语音通话等实时场景。
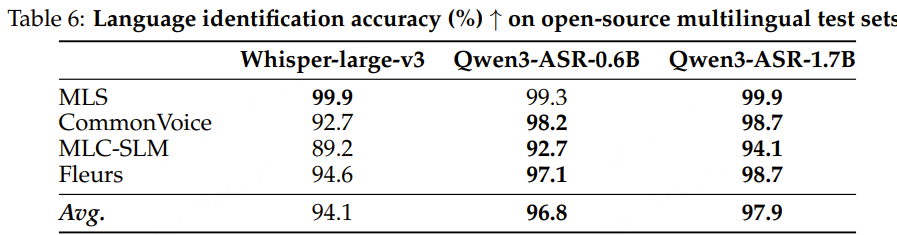
FireRedLID:口语语言识别(LID)支持 100+ 种语言及 20+ 种中文方言/口音识别,准确率达 97.18%,优于 Whisper 和 SpeechBrain-LID。对汉语方言的识别准确率达88.47%,能精准区分粤语、四川话、上海话、闽南语等主流方言,适配国内多语言交流场景。
- 依托FireRedASR2的编码器提取语音的深层特征,再通过分类器实现语言/方言的识别,利用ASR模型的多语言特征学习能力,提升小语种和方言的识别准确率,无需单独为LID做大量数据训练。
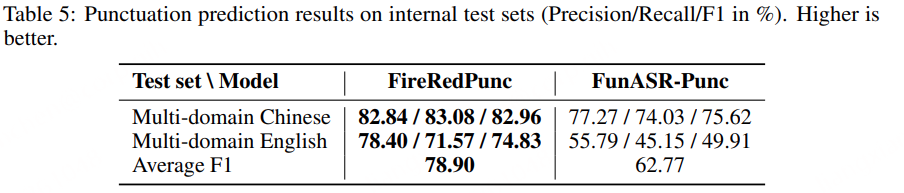
FireRedPunc:标点预测(Punc)支持中英文标点预测,平均 F1 值为 78.90%,优于 FunASR-Punc(62.77%)。适配日常对话、会议、文档等多场景,解决语音识别结果无标点、可读性差的问题,无需人工二次编辑。
- 基于经典的BERT预训练模型打造,针对语音识别的文本结果做了多领域微调,学习中英双语的标点使用规律,结合上下文语义实现智能标点预测,区别于传统的规则化标点方案,适配更复杂的语言场景。
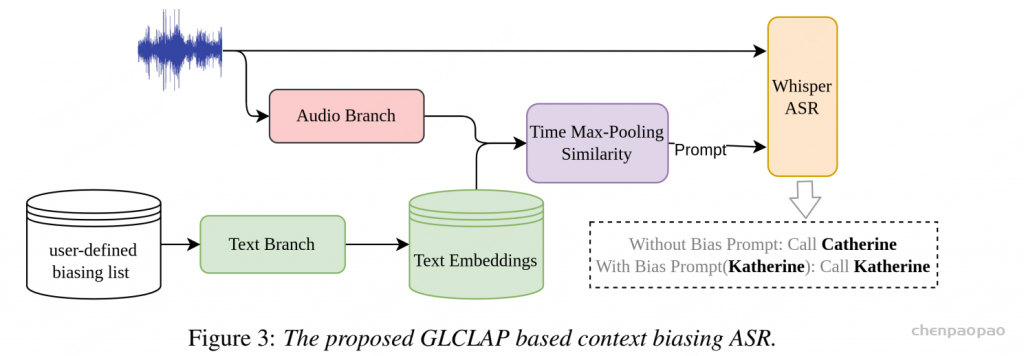
FireRedASR2S:系统概述
FireRedASR2S 是一套工业级一体化语音识别系统,将四大模块 —FireRedVAD、FireRedLID、FireRedASR2以及 FireRedPunc — 集成至统一处理流水线中。 该系统采用模块化设计:各组件可独立部署使用;默认配置则构成端到端转写流水线,能够适配各类声学场景(人声、歌声、背景音乐、非人声噪声),同时支持多语言及汉语方言场景,最终输出结构化结果,包含带标点文本、时间戳、置信度分数与语种标签。
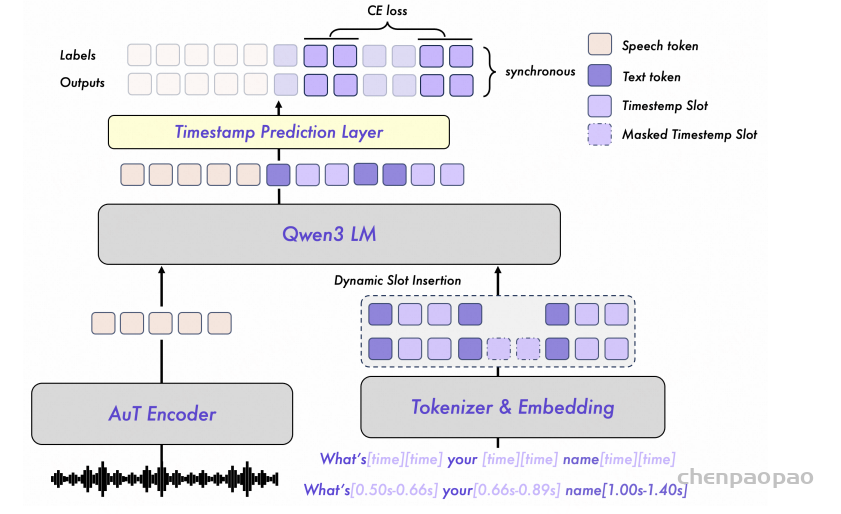
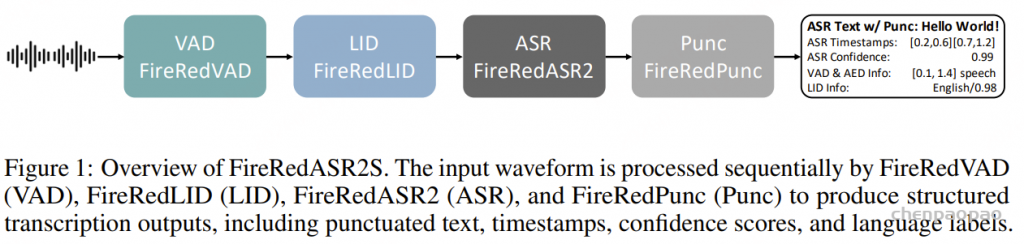
处理流水线:如图 1 所示,FireRedASR2S 对输入音频波形分四阶段处理:
- 第一阶段,FireRedVAD 在原始音频时间轴上检测人声片段,滤除非人声区域,提升长音频处理的鲁棒性;
- 第二阶段,FireRedLID 为每个检测到的片段输出语句级语种标签,必要时附加汉语方言标签;
- 第三阶段,FireRedASR2 将各片段转写为文本,并返回语音识别置信度;若使用 FireRedASR2-AED 版本,还可提供字符级与词语级时间戳;
- 最后阶段,FireRedPunc 为识别结果补充标点符号,提升文本可读性与下游任务适用性。
FireRedASR2:
FireRedASR2 包含两个版本:FireRedASR2-AED 与 FireRedASR2-LLM。
- FireRedASR2-AED 采用经典的 注意力编解码(AED)架构;
- FireRedASR2-LLM 基于编码器 – 适配器 – 大语言模型架构构建,借助大语言模型的能力提升语音识别效果。
两个模型的输入特征处理与声学编码方式相近,仅在词元序列建模方法上有所不同。此外,FireRedASR2-AED 支持输出词元级时间戳与整句置信度;词语级时间戳可通过对词元时间戳做后处理得到(例如将英文子词单元合并为完整单词)。
FireRedASR2-AED
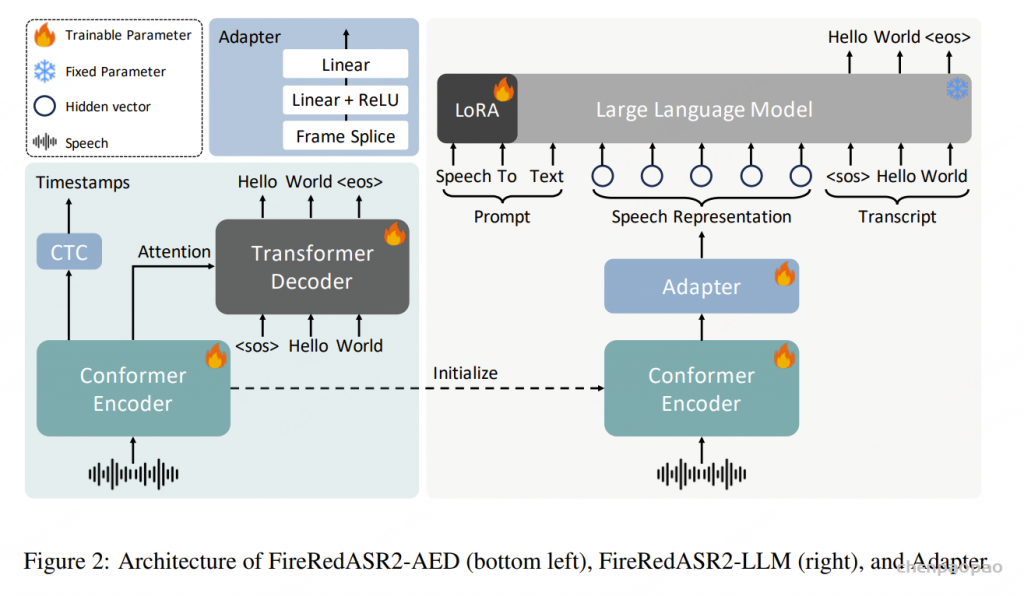
架构(Architecture):FireRedASR2-AED 采用端到端 ASR 架构,基于 Conformer 编码器 + Transformer 解码器 的设计。
- 编码器(Encoder):
- 以卷积下采样开始,用于降低帧率
- 后接多层堆叠的 Conformer block
- 解码器(Decoder):
- 标准 Transformer 解码器
- 通过注意力机制对编码器输出进行建模
- 使用交叉熵目标生成 token 序列
训练数据 相比 FireRedASR,FireRedASR2 的主要改进在于:
- 监督训练数据从 7 万小时扩展至约 20 万小时
- 数据覆盖范围更广,包括:
- 普通话
- 英语
- 中文方言
- 中英混合(code-switching)
- 语音与歌声
- 非语音音频
性能提升和泛化能力增强主要归因于这一更大规模且更多样化的数据集。
输入特征(Input Features)使用 80 维 log Mel 滤波器组(FBank)特征:
- 窗长:25 ms
- 帧移:10 ms
- 后处理:全局均值方差归一化(CMVN)
FireRedASR2-AED 采用混合分词策略:中文:按汉字(character)建模,英文:使用 BPE(Byte-Pair Encoding)子词单元。相较于 FireRedASR-AED:词表规模更新为 8667,更好支持多语言及方言场景。
基于解码器概率的置信度估计:FireRedASR2-AED 输出句子级(utterance-level)置信度分数,用于衡量识别结果的可靠性。具体方法:
- 从 beam search 得到的 1-best 路径
- 提取对应 token 的后验概率(softmax 输出)
- 排除特殊 token(如
<s>,<eos>等)
然后:将 token 级概率聚合为序列级分数常用方式:几何平均(geometric mean)。为了提升工程实用性,还可以进行进一步优化:
- 过滤异常值(outliers)
- 置信度截断(confidence clipping)
最终,该分数可用于:结果过滤、排序(reranking)、UI 展示
后置 CTC 分支用于时间戳预测
FireRedASR2-AED 的一个关键改进是:通过额外的 CTC 分支支持时间戳(timestamps)预测。在基础 AED 模型训练完成后:在编码器输出上增加一个轻量级 CTC 投影头(CTC head),冻结 Encoder 和 Decoder,仅训练 CTC 分支(使用标准 CTC loss)
实现细节:CTC head = 线性层(encoder hidden → logits);CTC 词表与 AED 词表完全一致便于后续对齐(forced alignment)
该设计的优点:不影响原 AED 模型识别精度,同时支持基于对齐的时间戳预测
推理流程(Inference)
- AED 解码:使用 beam search 得到 token 序列
- CTC 对齐:从 encoder 输出计算 frame-level CTC logits; 对 AED 输出序列执行 CTC 强制对齐(forced alignment);blank token id = 0
然后:将 frame-level 对齐结果转换为 token-level 起止时间,根据 encoder 的下采样率进行时间映射
- 英文:将多个 BPE token 合并为一个词,取:起始时间 = 最小 start,结束时间 = 最大 end
- 中文:每个汉字 token 直接作为一个词单元
FireRedASR2-LLM:基于 Encoder-Adapter-LLM 的 ASR 模型
FireRedASR2-LLM 同样是一个端到端 ASR 模型,遵循 FireRedASR-LLM [1] 提出的 Encoder-Adapter-LLM 框架。
该模型由三部分组成:
- 音频编码器(Encoder)
- 基于 Conformer
- 将声学特征转换为高层语义表示
- 适配器(Adapter)
- 轻量级模块
- 将编码器输出映射到预训练文本大语言模型(LLM)的 embedding 空间
- 自回归语言模型(LLM)
- 通过 next-token prediction(下一个 token 预测)生成转录文本(transcript)
FireRedASR2-LLM 与 FireRedASR2-AED 在以下方面保持一致:训练数据、输入特征、数据处理流程。此外:FireRedASR2-LLM 的 Encoder 使用 FireRedASR2-AED 的 Encoder 预训练权重进行初始化。
核心变化在于:使用了 20 万小时大规模监督训练数据,模型架构和训练策略保持不变
与 FireRedASR 的差异总结
总结了 FireRedASR2 与 FireRedASR 的主要差异。
总体来看:
- FireRedASR2 继承了 FireRedASR 中已验证有效的模型设计
- 通过以下方式进一步提升性能:
- 更大规模且更多样化的训练数据(20 万小时)
- 在 AED 模型中引入 后置 CTC 分支(post-hoc CTC branch),支持时间戳预测

从本质上讲:
- 结构创新不多(偏工程稳健)
- 性能提升主要来自数据规模 + 功能增强(timestamps)
FireRedVAD:
FireRedVAD 为下游 ASR 提供鲁棒的音频分段能力,适用于真实场景音频,其中语音可能与以下内容共存:
- 歌声(singing)
- 背景音乐(background music)
- 各类非语音声学事件
不同于许多工业级 VAD 方案(通常依赖 ASR 强制对齐信号,并主要基于 ASR 语料训练),FireRedVAD 基于高质量人工标注的声学事件数据进行训练,从而在复杂声学环境下具备更可靠的检测能力。
FireRedVAD 包含三类基于 DFSMN 的模型:
- 非流式 VAD(offline)用于离线音频分段
- 流式 VAD(streaming)用于低延迟在线分段
- 非流式多标签 VAD(mVAD)用于声学事件识别(speech / singing / music)
多标签 VAD(mVAD):mVAD 被建模为帧级多标签分类任务,预测三类事件的后验概率:
- speech(语音)
- singing(歌声)
- music(音乐)
特点:每一类事件输出独立概率,最终通过逐类别后处理得到对应的时间片段
语音活动检测(VAD):VAD 被建模为帧级二分类任务:
- voice(有声) = speech ∪ singing
- non-voice(无声) = music + silence + noise
该定义符合 UGC(用户生成内容)场景:歌声通常与语音采用类似处理方式
训练数据
人工标注的事件语料库:
FireRedVAD 使用数千小时的人工标注声学事件数据进行训练。每条语音都标注了 speech(语音)、singing(歌声)和 music(音乐) 的时间边界。不同于常见做法(例如通过 ASR 强制对齐或弱分割启发式方法生成 VAD 监督信号),FireRedVAD 直接采用高质量的人工标注数据进行训练。
mVAD 与 VAD 的监督方式:
mVAD 模型直接使用原始的三类标签进行训练。而 VAD 模型则基于同一标注体系构造二分类标签:将 speech 和 singing 映射为正类,将 music、silence 和 noise 映射为负类。
尽管两者共享相同的语义体系(ontology),mVAD 与 VAD 仍作为独立模型进行训练,并分别采用针对各自任务设计的优化目标与后处理策略。
模型结构
输入特征:
FireRedVAD 使用与 FireRedASR2相同的声学特征。
DFSMN 主干网络:
所有 FireRedVAD 模型均采用深度前馈序列记忆网络(DFSMN),该结构在帧级声学分类任务中具有高效且优良的表现。
我们通过depthwise 1-D convolution)来实现 FSMN的记忆模块,以建模时间上下文,并结合残差连接(residual connection)以提升训练稳定性。
网络配置:模型包含 8 个 DFSMN block,后接 1 个前馈层。
- 隐层维度(hidden size):256
- 投影维度(projection size):128
时间上下文设置如下:
- 回看(look-back):阶数 20,步长 1
- 非流式(offline)VAD 与 mVAD:
- 使用 look-ahead = 20,stride = 1(利用未来信息提升分割效果)
- 流式(streaming)VAD:
- look-ahead = 0(保证因果性推理)
同时,模型采用 dropout(0.05)进行正则化。
模型规模:得益于紧凑的设计,FireRedVAD 的三个模型均非常轻量,每个模型仅约 0.6M 参数(约 2.2MB,float32)。
这种超轻量特性使其:
- 非常适合云端高并发处理
- 也适用于资源受限的边缘设备部署
输出层 最终分类器为一个线性映射,将 DFSMN 的隐藏状态映射为 logits:
- VAD:输出维度为 1(语音 vs 非语音)
- mVAD:输出维度为 3(speech / singing / music)
随后使用 sigmoid 激活函数得到后验概率。
流式推理:
为支持在线 VAD,流式模型在每一层维护一个小型缓存(cache),用于保存 FSMN 所需的固定长度历史信息(look-back)。在推理过程中:
- 模型逐步更新缓存
- 仅对新输入帧进行计算
- 无需重复处理历史音频
从而实现:低延迟、有界内存占用
后处理与分段
DFSMN 模型输出的是帧级后验概率,需通过确定性的后处理流程转换为时间片段。
处理流程如下:
- 平滑(Smoothing)
对后验概率序列应用滑动平均滤波(moving-average) - 阈值判定(Thresholding)
基于概率阈值得到帧级分类结果 - 状态机约束(Finite-state postprocessing)
为抑制局部声学波动导致的频繁切换,引入有限状态机,约束:- 最小语音时长(min speech duration)
- 最小静音时长(min silence duration)提升离线与流式场景下的稳定性
分段还可以进行可选的优化,包括:合并短间隙、延长边界、拆分过长语音段,这能够增强长音频和下游 ASR 的鲁棒性。
对于 mVAD,同样的流程会独立应用于每个事件的后验流(speech、singing、music),使用事件特定的阈值,得到每个事件的时间戳段。
- 非流式 VAD 输出带有开始/结束时间戳的一组语音段;
- 流式 VAD 输出增量的帧级判决和语音开始/结束事件;
- mVAD 输出 speech、singing 和 music 的每个事件时间戳,从而支持事件感知的下游处理。
FireRedLID
FireRedLID 旨在在多样化声学条件下保持鲁棒,并支持多语言识别以及精细的中文方言识别。
模型与训练
架构:FireRedLID 采用 Encoder-Decoder 架构,使用 Conformer Encoder 和 Transformer Decoder,实现风格与 AED ASR 模型一致。给定输入语句,Encoder 生成声学表示,Decoder 输出表示 LID 结果的短 token 序列。
初始化:Conformer Encoder 从预训练的 FireRedASR2-AED Encoder 初始化,以利用其大规模 ASR 表征学习能力;LID Decoder 则随机初始化,从零开始训练。
输入特征:FireRedLID 使用与 FireRedASR2 相同的声学特征。
训练数据:FireRedLID 使用约 20 万小时多语言语音 训练,覆盖 100+ 种语言,包括普通话及 20+ 种中文方言。数据经过精心筛选,涵盖多样域和声学条件,以提升泛化能力。
训练目标:采用标准 序列到序列交叉熵(Seq2Seq CrossEntropy),使用 teacher forcing 进行训练。
分层标签空间与解码
两级标签:FireRedLID 将 LID 建模为 两级层次结构。
- 第一级预测语言(如 zh、en、ja、ko 等);
- 当预测语言为中文(zh)时,模型进一步预测中文方言标签(如 mandarin、yue、wu、min、xiang 等)。
此设计反映自然标签结构,并通过在粗粒度语言决策条件下预测方言,提高方言识别的稳定性。
短序列 token 预测:将分层 LID 任务表述为 短序列生成任务,最大解码长度为 2。
- 模型通常先输出语言 token;
- 对中文语句,Decoder 通常再输出第二个 token 表示方言,然后生成
<eos>; - 对非中文语句,Decoder 在预测语言 token 后通常直接输出
<eos>终止。
这种设计保持标签序列紧凑,相比平坦标签空间减少歧义。
解码与置信度:推理时,使用 beam search 解码 token 序列。由于输出长度最多 2 个 token,解码开销可忽略。模型输出最优假设,并将已解码 token(不含特殊 token,如 <sos> 和 <eos>)的平均后验概率作为语句级置信度。
支持语言与方言
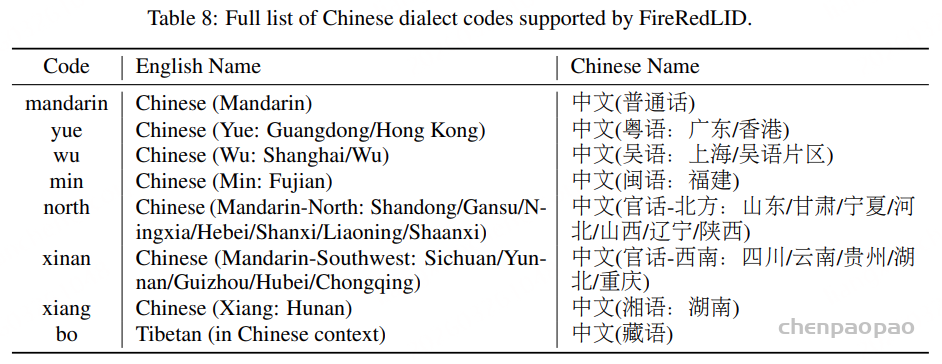
标签覆盖:FireRedLID 支持 100+ 种语言和 20+ 种中文方言。
- 语言用紧凑的代码表示(如 zh、en、ja、ko);
- 中文方言被分为 8 个地理或语言学方言簇(如 mandarin、yue、wu、min 等)。
FireRedPunc:
FireRedPunc 用于为 ASR 转写结果预测标点,从而提升可读性及下游可用性(如字幕显示和机器翻译)。它主要针对开域 ASR 输出的中英文标点预测。
架构:FireRedPunc 采用 BERT 风格的 Encoder,并在 token 级别添加分类头。
- 给定输入 token 序列,模型为每个 token 预测一个标点标签,表示该 token 后应插入的标点;
- Encoder 从预训练的 LERT 检查点初始化(LERT 是一个以语言学为动机的 BERT 变体),并对标点预测任务进行微调。
标点集合:使用紧凑的 5 类标点集合,包括:无标点、,、.、?、!。
- 对中文文本,使用全角中文标点;
- 设计覆盖 ASR 应用中最常用的标点,同时保持分类器简单且稳定。
训练数据:FireRedPunc 在大规模多领域文本语料上训练,带标点注释。
- 数据量约 185.7 亿中文字符 和 22 亿英文单词;
- 覆盖多样领域和写作风格,以增强对 ASR 风格输入的泛化能力。
训练目标:采用 标准 token 级交叉熵损失 进行训练。
推理:
- 推理时,使用与 LERT 预训练 Encoder 相同的 tokenizer 对 ASR 输出进行分词;
- 模型预测每个 token 的标点标签;
- 最终文本通过将预测标点插入原始文本生成。
Evaluation
FireRedASR2
- FireRedASR2-LLM(8B+ 参数)
- FireRedASR2-AED(1B+ 参数)
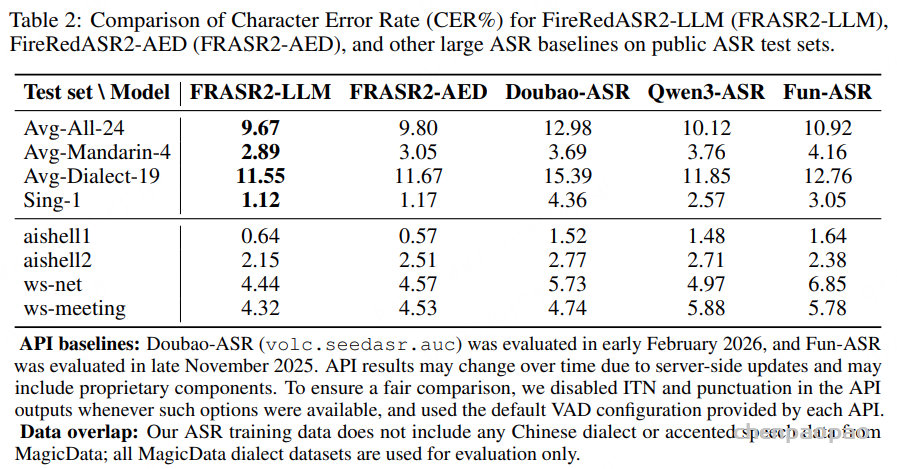
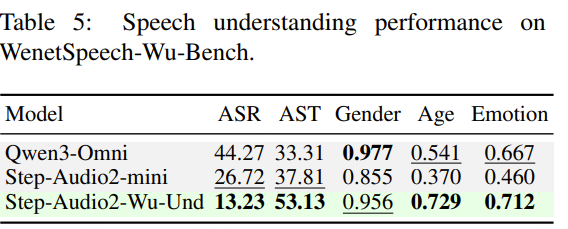
FireRedASR2-LLM 在所有汇总指标上表现最佳:
- 普通话(Avg-Mandarin-4)平均 CER 为 2.89%
- 中文方言(Avg-Dialect-19)平均 CER 为 11.55%
- 全部 24 个测试集(Avg-All-24)平均 CER 为 9.67%
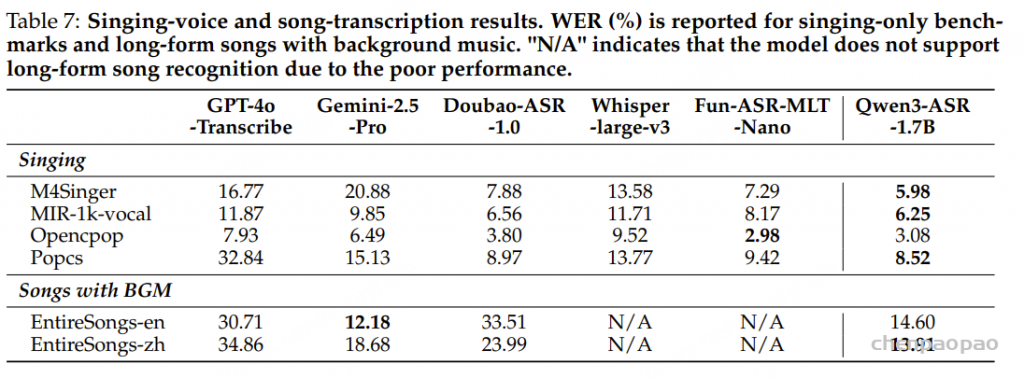
在歌曲歌词识别上也表现优异:在 opencpop 数据集上,FireRedASR2-LLM 的 CER 为 1.12%。 FireRedASR2-AED 尽管模型较小,但仍能达到有竞争力的准确率,为实际部署提供了更平衡的选择。
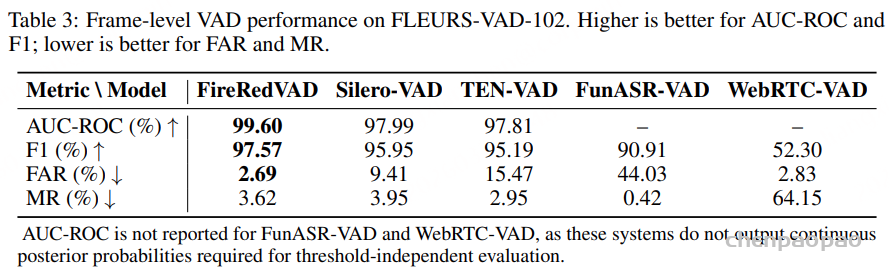
FireRedVAD
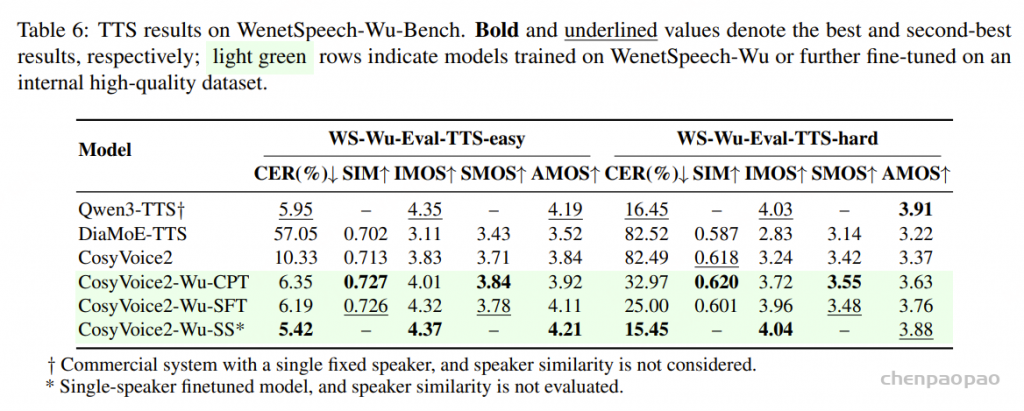
FireRedVAD 在多语言 VAD 任务上表现出色:
- AUC-ROC 达到 99.60%
- F1 分数 达到 97.57%
误报率(FAR) 仅 2.69%漏报率(MR) 仅 3.62%,说明 FireRedVAD 在下游语音分段任务中能保持平衡。相比之下,一些基线(如 FunASR-VAD)虽然漏报率非常低,但代价是误报率显著升高,这在实际部署中可能导致过度分段并增加不必要的下游 ASR 计算。
FLEURS-VAD-102,一个覆盖 102 种语言的多语言 VAD 基准集。
FireRedLID
多语言 LID:在 FLEURS 测试集(82 种语言)和 CommonVoice 测试集(74 种语言)上评估。 中文方言识别:合并 KeSpeech 和 MagicData 测试样本,覆盖 10 多种中文方言。
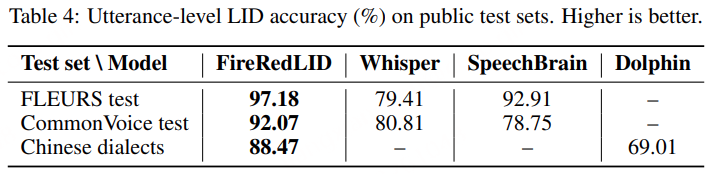
FLEURS 测试集:FireRedLID 达到 97.18% 准确率,显著优于 Whisper,并较 SpeechBrain 有明显提升。 CommonVoice 测试集:FireRedLID 取得比较系统中的最高准确率。 中文方言基准:FireRedLID 达到 88.47% 准确率,证明了分层标签建模在细粒度中文方言识别中的有效性。
FireRedPunc
与常用标点模型 FunASR-Punc (CT-Transformer) 对比