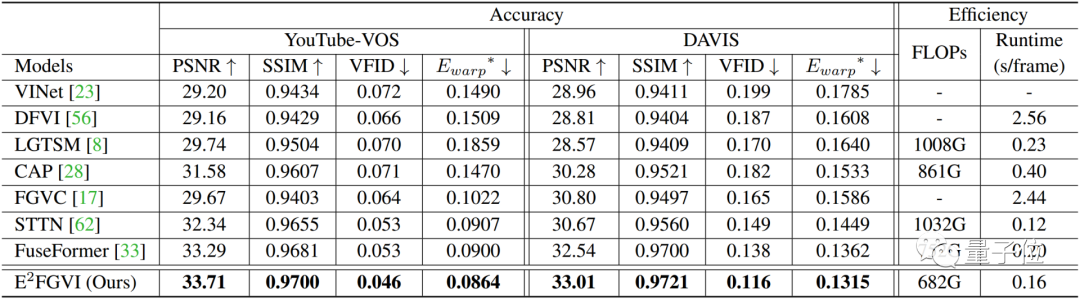
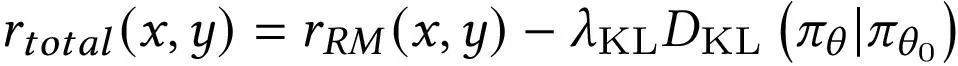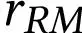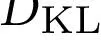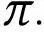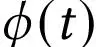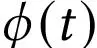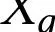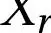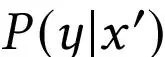摘自:https://zhuanlan.zhihu.com/p/615522634
最近AIGC发展的也太太太太太太快了,感觉完全follow不上了,我对text to image的认知还停留在stackgan上,汗颜。
这里总结了几篇比较新的survey,记录一下
A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT
ChatGPT is not all you need. A State of the Art Review of large Generative AI models
现有的一下GAI技术
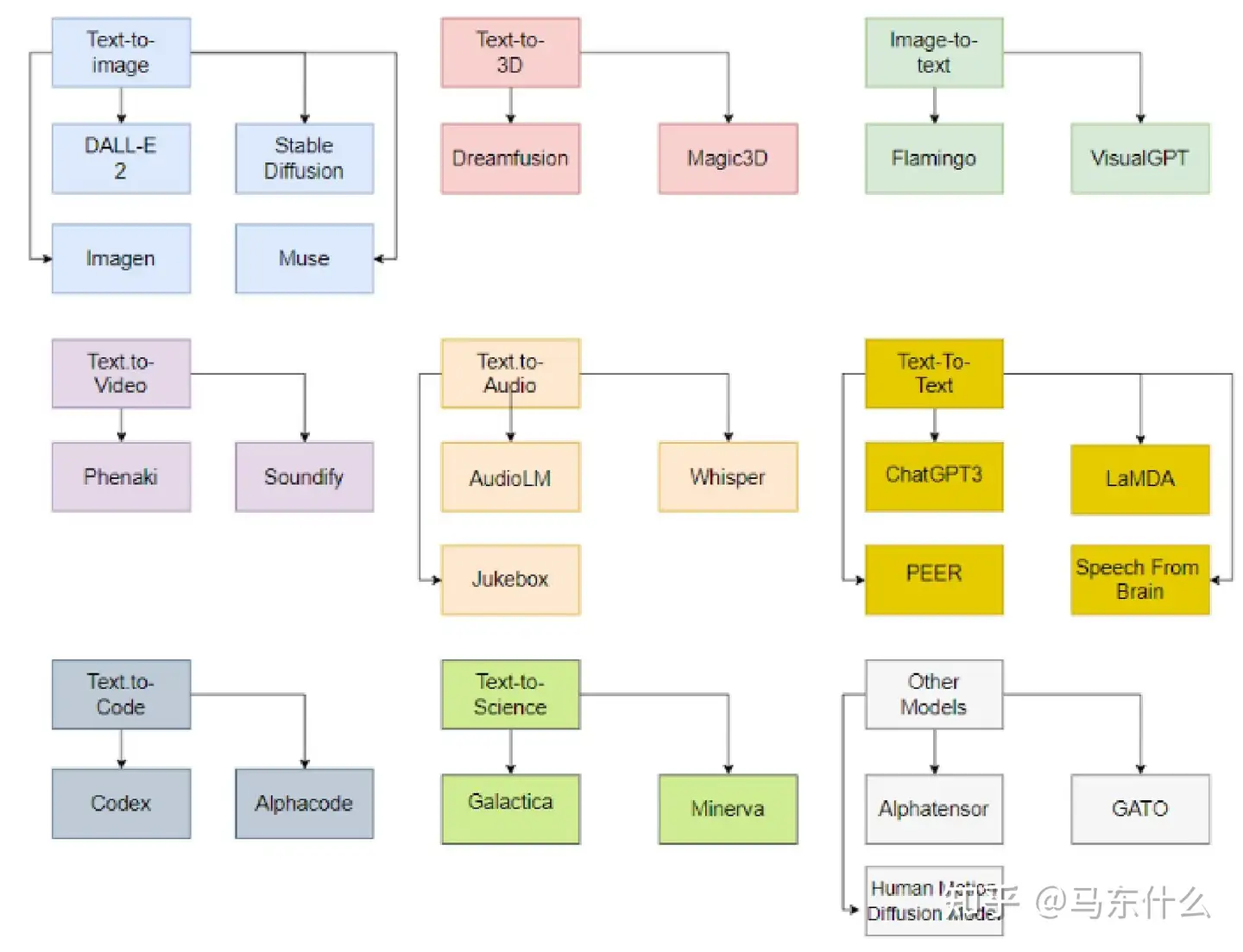
这几年的一些GAI技术的总结,包括了ChatGPT (文本到文本的对话模型)与 DALL-E-2(文本到图像的生成模型) , Codex(文本到代码的生成模型) ,Dreamfusion (文本到3D图像), Flamingo(图像到文本),Phenaki (文本到视频),AudioLM(文本到音频),Galactica(文本到科学文本),AlphaTensor(自动搜索高性能的矩阵运算逻辑)
实际上,ChatGPT 和其他生成式人工智能 (GAI) 技术属于人工智能生成内容 (AIGC) 的范畴,涉及通过人工智能模型创建数字内容,例如图像、音乐和自然语言。
AIGC 的目标是使内容创建过程更加高效和易于访问,从而能够以更快的速度制作高质量的内容 。
AIGC是通过从人类提供的指令中提取和理解意图信息,并根据其知识和意图信息生成内容来实现的 。近年来,大型模型在 AIGC 中变得越来越重要,因为它们提供了更好的意图提取,从而改进了生成结果。随着数据的增长和模型的规模,模型可以学习的分布变得更加全面和接近现实,从而导致更真实和高质量的内容生成。
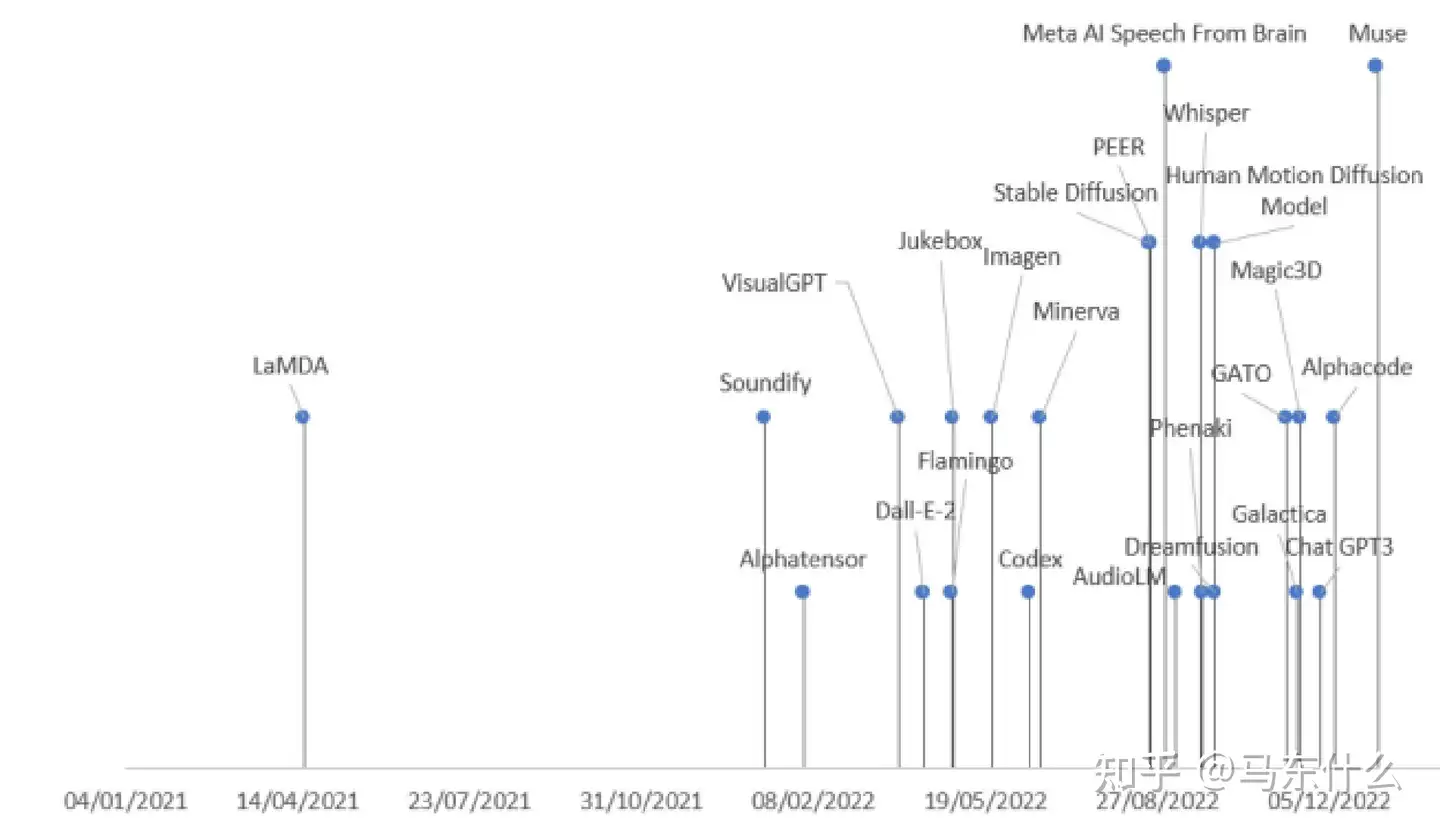
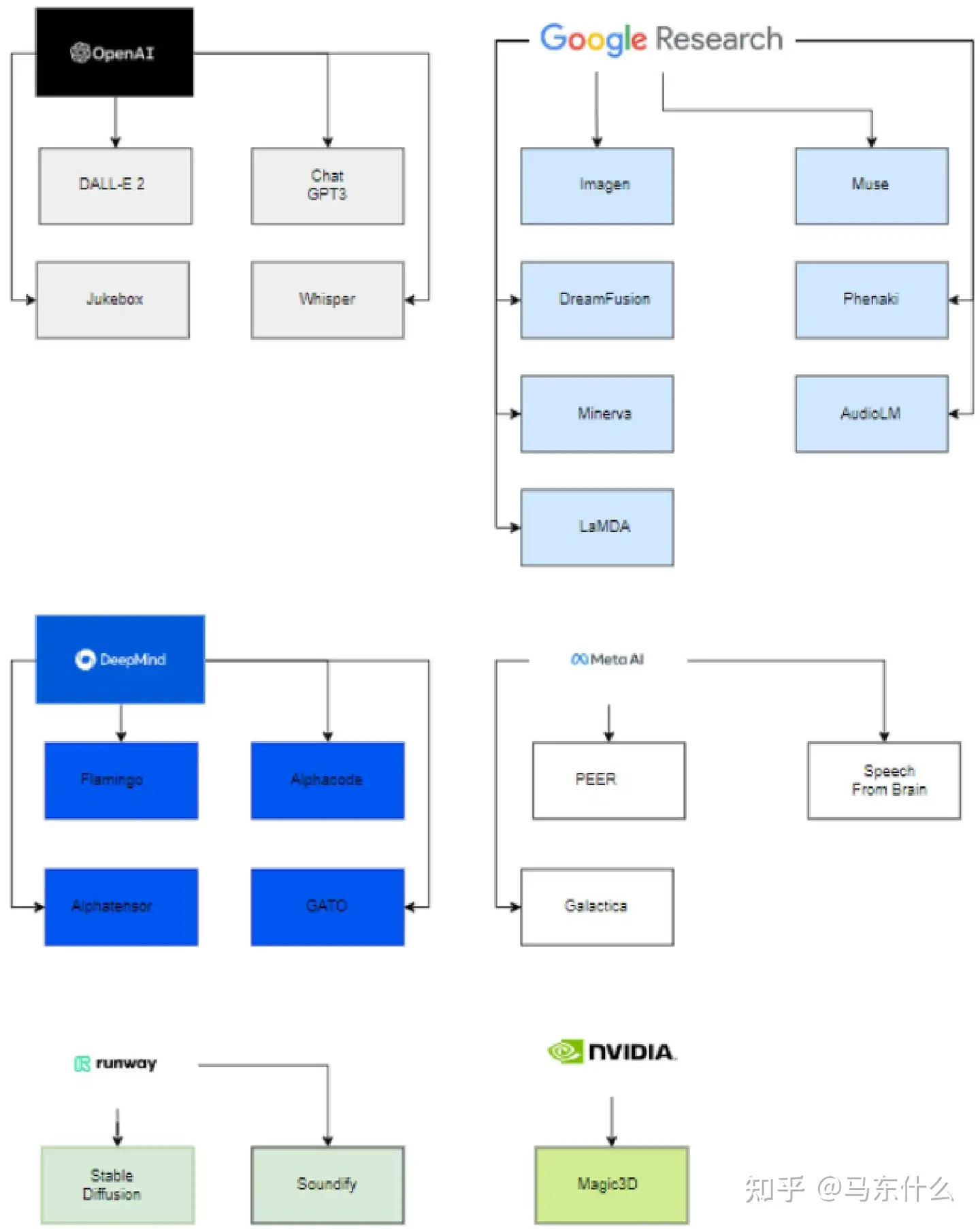
生成式 AI 模型的分类 按发布日期列出的涵盖模型。除了 2021 年发布的 LaMDA 和 2023 年发布的 Muse 之外,所有模型都在 2022 年发布。 为了能够训练这些巨大的模型,必须拥有强大的计算能力和一支技术精湛、经验丰富的数据科学和数据工程团队。因此,目前暂时只有下图中所示的公司,成功部署并将生成式人工智能模型投入商用。
在参与初创公司的主要公司方面,请注意微软向 OpenAI 投资了 10 亿美元,并帮助他们开发模型。
另外,请注意谷歌在 2014 年收购了 Deepmind。
在大学方面,请注意 VisualGPT 是由 KAUST、卡内基梅隆大学和南洋理工大学开发的
人体运动扩散模型是由以色列特拉维夫大学开发的。
同样,还有一些其他的项目是由公司与大学合作开发的。具体来说,Stable Diffsion(Runway、Stability AI 和 LMU MUNICH)、Soundify(Runway 和卡内基梅隆大学)和 DreamFusion(谷歌和加州大学伯克利分校)就是这种情况 。
INTRODUCTION
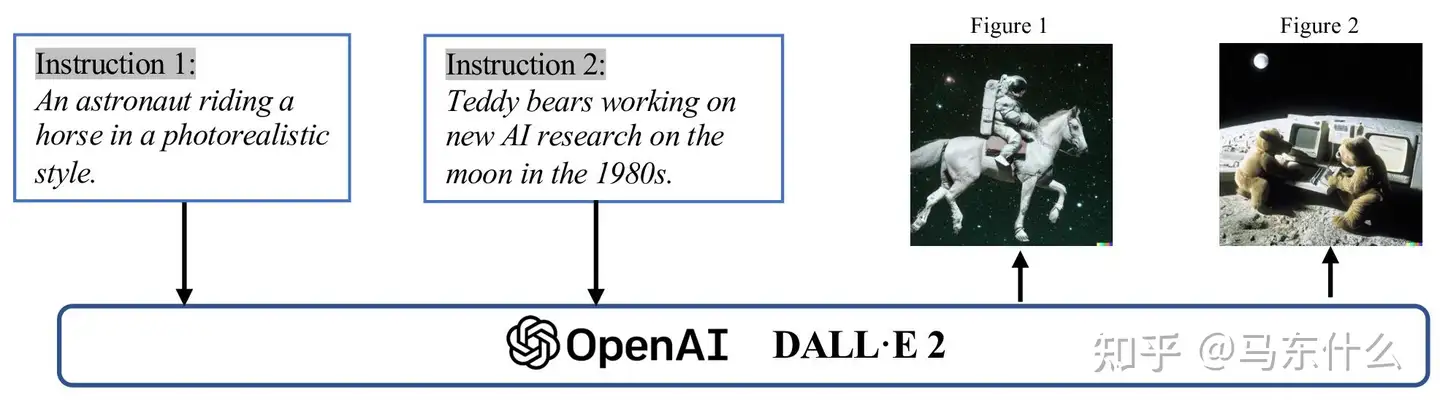
近年来,人工智能生成内容 (AIGC) 获得了计算机科学界以外的广泛关注,整个社会开始对大型科技公司构建的各种内容生成产品感兴趣 [3],例如 ChatGPT [4]和 DALL-E2 [5]。AIGC 是指使用先进的生成式 AI (GAI) 技术生成的内容,而不是由人类作者创建,它可以在短时间内自动创建大量内容。例如,ChatGPT 是 OpenAI 开发的用于构建对话式 AI 系统的语言模型,它可以有效地理解并以有意义的方式响应人类语言输入。此外,DALL-E-2 是另一个由 OpenAI 开发的最先进的 GAI 模型,它能够在几分钟内根据文本描述创建独特的高质量图像,例如“An astronaut riding a horse ina photorealistic style”,如下图所示。由于AIGC取得的骄人成绩,很多人认为这将是人工智能的新时代,对全世界产生重大影响。
从技术上讲,AIGC 是指在给定可以帮助教导和引导模型完成任务的人类指令后,利用 GAI 算法生成满足指令的内容。这个生成过程通常包括两个步骤:从人类指令中提取意图信息,并根据提取的意图生成内容 。然而,正如之前的研究 [6, 7] 所证明的那样,包含上述两个步骤的 GAI 模型范例并不完全新颖,实际上例如text to image的应用,早年的stackgan等就已经在做这类事情了。
与之前的工作相比,最近 AIGC 的核心进步主要体现在使用了更大的数据集上训练更复杂的生成模型、使用更大的基础模型架构以及能够访问的更加广泛的计算资源的结果 。
例如GPT-3的主框架与GPT-2保持一致,但预训练数据量从WebText[8](38GB)增长到CommonCrawl[9](过滤后570GB),基础模型大小从 1.5B 增长到 175B。因此,GPT-3 在各种任务上比 GPT-2 具有更好的泛化能力,例如人类意图提取(NLP中存在模型顿悟的现象,即当参数量超过某个大小之后,下游任务的performance会发生突飞猛进的情况 )。
除了数据量和计算能力提升带来的好处之外,研究人员也在探索将新技术与 GAI 算法相结合的方法。例如,ChatGPT 利用人类反馈 (RLHF) [10-12] 的强化学习来确定给定指令的最合适响应,从而随着时间的推移提高模型的可靠性和准确性。这种方法让 ChatGPT 能够更好地理解人类在长对话中的偏好。同时,在计算机视觉中,Stability.AI 于 2022 年提出的stable diffusion [13] 在图像生成方面也取得了巨大的成功。与以前的方法不同,生成扩散模型可以通过控制探索和利用之间的权衡来帮助生成高分辨率图像,从而使生成图像的多样性与训练数据的相似性和谐地结合在一起。
通过结合这些进步,模型在 AIGC 任务中取得了重大进展,并已被各个行业采用,包括艺术 [14]、广告 [15] 和教育 [16]。在不久的将来,AIGC 将继续成为机器学习研究的重要领域。因此,对过去的研究进行广泛审查并确定该领域的未解决问题至关重要。本次调研是首次聚焦AIGC领域的核心技术和应用。
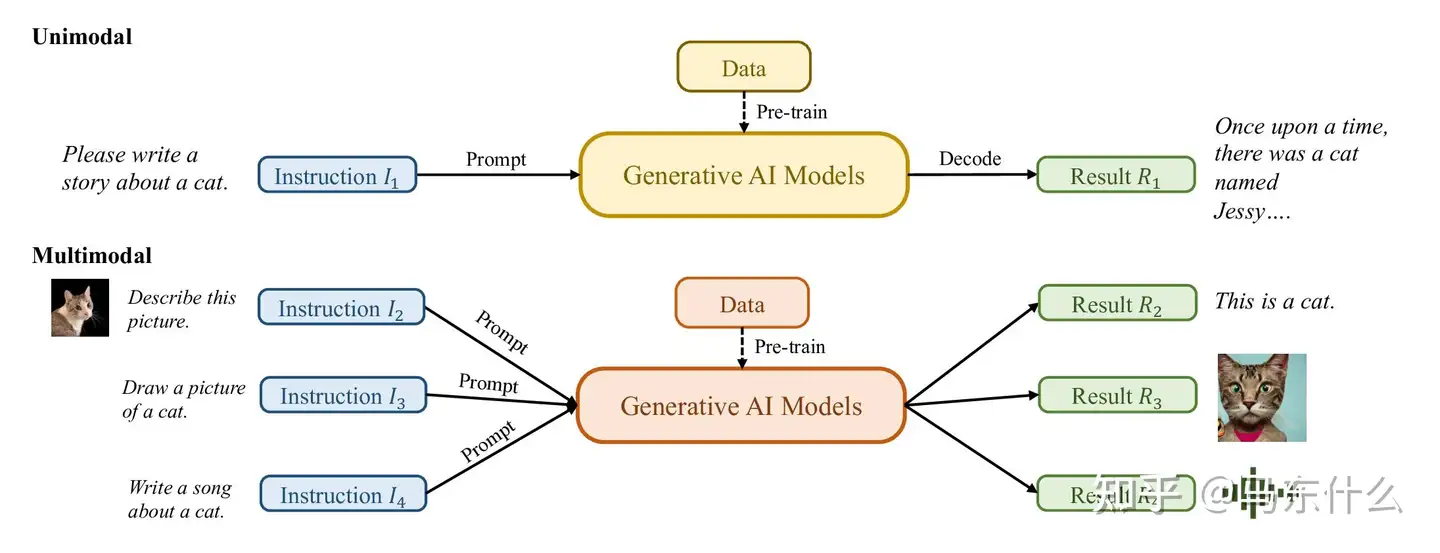
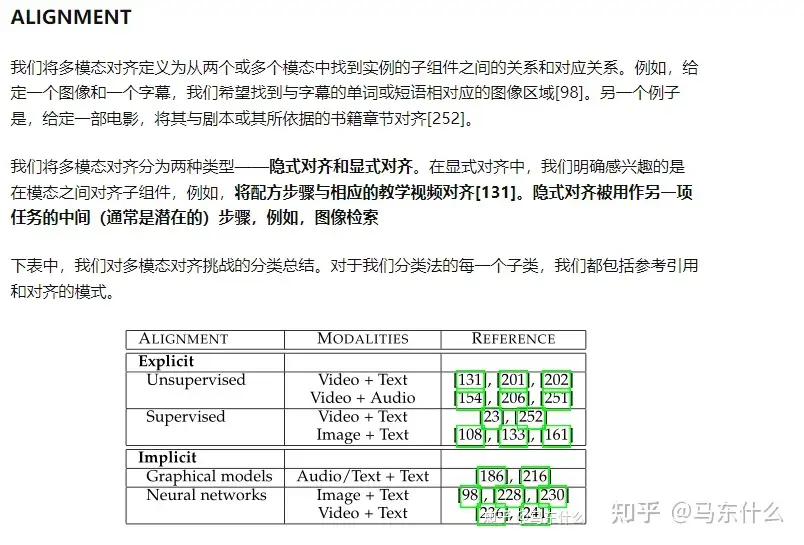
单模态和多模态的AIGC技术
图 2. AIGC 概览。一般来说,GAI模型可以分为两类:单模态模型和多模态模型。单模态模型从与生成的内容模态相同的模态接收指令,而多模态模型接受跨模态指令并产生不同模态的结果。 生成式人工智能(AIGC)的历史
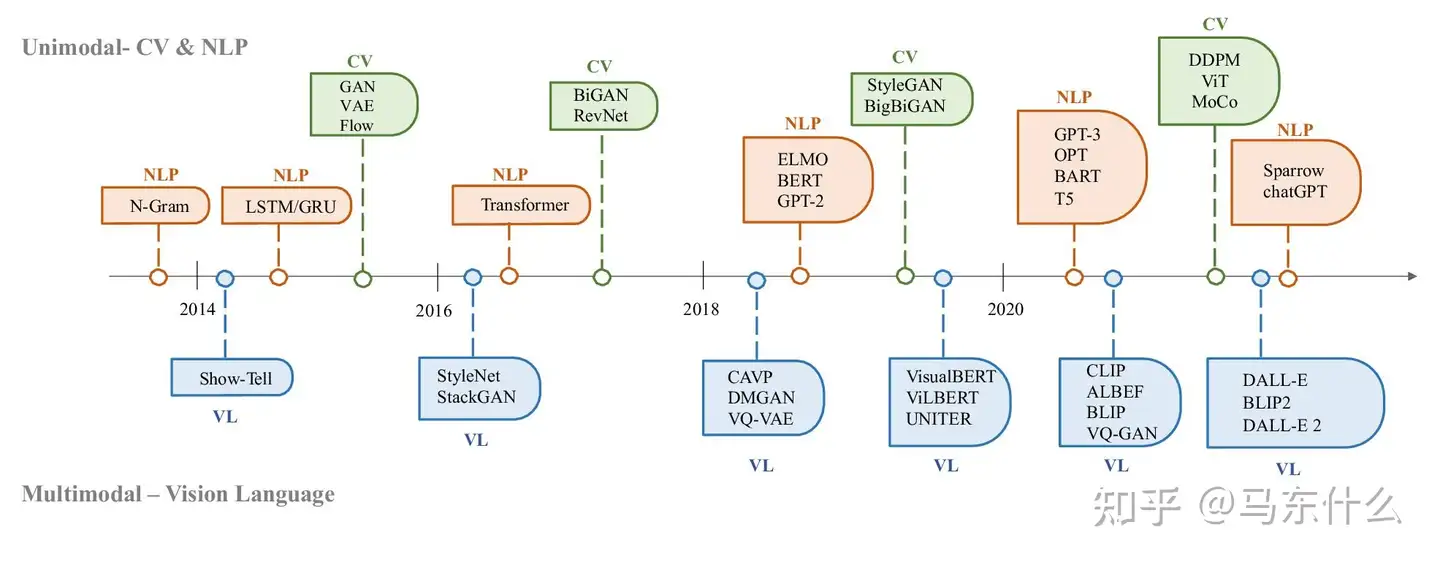
nlp的前transformer时代的AIGC
生成模型在人工智能领域有着悠久的历史,可以追溯到 1950 年代随着隐马尔可夫模型 (HMM) [20] 和高斯混合模型 (GMM) [21] 的发展。这些模型生成序列数据,例如语音和时间序列。然而,直到深度学习的出现,生成模型的性能才得到显着改善。在早期的深度生成模型中,不同领域总体上没有太多重叠 。在自然语言处理(NLP)中,传统的句子生成方法是使用 N-gram 语言建模 [22] 来学习单词分布,然后搜索最佳序列。但是,这种方法不能有效地适应长句子。为了解决这个问题,循环神经网络 (RNN) [23] 后来被引入用于语言建模任务,允许建模相对较长的依赖关系。随后开发了长短期记忆 (LSTM) [24] 和门控循环单元 (GRU) [25],它们利用门控机制在训练期间控制记忆。这些方法能够处理样本 [26] 中的大约 200 个标记,这标志着与 N-gram 语言模型相比有了显着的改进。
cv领域的前transformer时代的AIGC
同时,在计算机视觉(CV)中,在基于深度学习的方法出现之前,传统的图像生成算法使用纹理合成 [27] 和纹理映射 [28] 等技术。这些算法基于手工设计的特征,生成复杂多样图像的能力有限。2014 年,生成对抗网络 (GANs) [29] 首次被提出,这是该领域的一个重要里程碑,因为它在各种应用中取得了令人瞩目的成果。变分自动编码器 (VAE) [30] 和扩散生成模型 [31] 等其他方法也已被开发用于对图像生成过程进行更细粒度的控制以及生成高质量图像的能力 。
后transformer时代的发展
生成模型在各个领域的进步遵循了不同的路径,但最终出现了交叉点:transformer 架构 [32 ]。由 Vaswani 等人介绍。对于 2017 年的 NLP 任务,Transformer 后来被应用到 CV 中,然后成为各个领域许多生成模型的主导骨干 [9,33,34]。在 NLP 领域,许多著名的大型语言模型,例如 BERT 和 GPT ,都采用 transformer 架构作为它们的主要构建块,与以前的构建块(即 LSTM 和 GRU)相比具有优势。在 CV 中,Vision Transformer (ViT) [35] 和 Swin Transformer [36] 后来通过将 transformer 架构与视觉组件相结合 ,进一步采用了这一概念,使其能够应用于基于图像的下游。
除了 transformer 对单个模态的改进之外,这种交集还使来自不同领域的模型能够融合在一起以用于多模态任务。多模态模型的一个这样的例子是 CLIP [37 ]。CLIP 是一种联合视觉语言模型,将 transformer 架构与视觉组件相结合,使其能够在大量文本和图像数据上进行训练。由于它在预训练过程中结合了视觉和语言知识,因此它也可以用作多模态提示生成中的图像编码器。总而言之,基于 transformer 的模型的出现彻底改变了 AI 生成,并使大规模训练成为可能。
近年来,研究人员也开始引入基于这些模型的新技术。例如,在 NLP 中,人们有时更喜欢prompt learning[38],而不是微调(finetune) ,这是指在提示中包含从数据集中选择的几个示例,以帮助模型更好地理解任务要求。
图 3. 生成式人工智能在 CV、NLP 和 VL 中的历史(VL=cv+nlp) 自监督学习的提出(包括了cv中的各类花哨的对比学习方法,以及nlp中的pretrain task本身都可以归类为自监督学习)提供了更强大的原始输入的representations。
未来,随着AIGC变得越来越重要,将会引入越来越多的技术,为这一领域注入活力。
目前的一些知名工作
DALL·E 2
由 OpenAI 创建,能够根据包含文本描述的提示生成原始、真实和逼真的图像和艺术 [10]。幸运的是,可以使用 OPENAI API 访问此模型。特别是,DALL·E 2 设法结合了概念、属性和不同的风格。为此,它使用了 CLIP 。CLIP(对比语言-图像预训练)是一种在各种(图像、文本)对上训练的神经网络 [25]。使用 CLIP,可以用自然语言来指导预测最相关的文本片段,给定图像,该模型最近已合并为图像的成功表示学习器。具体而言,CLIP 嵌入具有几个理想的特性:它们对图像分布偏移具有鲁棒性,具有令人印象深刻的零样本能力,并且经过微调以实现最先进的结果。为了获得完整的图像生成模型,CLIP 图像嵌入解码器模块与先验模型相结合,从给定的文本标题生成可能的 CLIP 图像嵌入。我们在下图中说明了从提示生成的图像。从提示“A shiba inu wearing a beret and black turtleneck”生成的图像。
openai并未开放dalle2的源码,不过有一个不错的开源实现:https://github.com/lucidrains/DALLE2-pytorchgithub.com/lucidrains/DALLE2-pytorch
IMAGEN
Imagen 是一种文本到图像扩散模型 [17],由大型transformer语言模型组成。至关重要的是,使用该模型观察到的主要发现是,在纯文本语料库上预先训练的大型语言模型在编码文本以进行图像合成方面非常有效 [28]。 准确地说,使用 Imagen,已经发现增加语言模型的大小比增加图像扩散模型的大小更能提高样本保真度和图像-文本的语义一致性 。该模型由谷歌创建,API 可以在他们的网页上找到。为了评估他们的模型,谷歌创建了 Drawbench,这是一组 200 个提示,支持文本到图像模型的评估和比较。最具体地说,该模型基于预训练的文本编码器(如 BERT [12]),该编码器执行从文本到一系列词嵌入的映射,以及将这些嵌入映射到分辨率不断提高的图像的级联条件扩散模型。我们在下图 中显示了根据提示生成的图像。
提示“一只可爱的柯基犬住在寿司做的房子里”生成的图像。 同样,google并没有开放imagen的源码,不过同一个作者(这个人真的太屌了,算法开发怪兽)开放了自己的实现:https://github.com/lucidrains/imagen-pytorchgithub.com/lucidrains/imagen-pytorch
Stable diffusion
Stable diffusion是一种潜在扩散模型,它是开源的,由慕尼黑大学的 CompVis 小组开发。该模型与其他模型的主要区别在于使用了潜在扩散模型,并且它执行图像修改,因为它可以在其潜在空间中执行操作。对于 Stable Diffusion,我们可以通过他们的网站使用 API。更具体地说,Stable Diffusion 由两部分组成:文本编码器和图像生成器 [17]。图像信息创建者完全在潜在空间中工作。此属性使其比以前在像素空间中工作的扩散模型更快。我们在图 7 中展示了一个稳定扩散图像示例。
相对而言,Stable diffusion的开源代码就多多了,https://github.com/CompVis/stable-diffusiongithub.com/CompVis/stable-diffusion https://github.com/Stability-AI/stablediffusiongithub.com/Stability-AI/stablediffusion
除了官方放出的代码之外,keras-cv作为keras唯一官方的专门做cv的library也放出了基础版本stable diffusion的实现:https://github.com/keras-team/keras-cv/blob/master/keras_cv/models/stable_diffusion/stable_diffusion.pygithub.com/keras-team/keras-cv/blob/master/keras_cv/models/stable_diffusion/stable_diffusion.py
另外一个就是huggingface开放的diffuser了:https://github.com/huggingface/diffusersgithub.com/huggingface/diffusers
Muse
该模型是一种文本到图像转换器模型,可实现最先进的图像生成,同时比扩散或自回归模型更高效 [6]。具体来说,它是在离散标记空间中的掩码建模任务上进行训练的。因此,由于使用了离散令牌并且需要更少的采样迭代,它更有效。与自回归模型 Parti 相比,Muse 由于并行解码而更加高效。Muse 在推理时间上比 Imagen-3B 或 Parti-3B 快 10 倍,比 Stable Diffusion v 1.4 快 3 倍。Muse也比 Stable Diffusion 更快,尽管这两个模型都在 VQGAN 的潜在空间中工作 。
前面描述的模型处理文本提示到 2D 图像的映射。但是,对于游戏等行业,需要生成 3D 图像。下面简要介绍两种文本到 3D 模型:Dreamfusion 和 Magic3D。
同样,google并未开放muse的开源代码,仍旧是这个巨佬。。。我丢https://github.com/lucidrains/muse-maskgit-pytorchgithub.com/lucidrains/muse-maskgit-pytorch
Dreamfusion
DreamFusion 是由 Google Research 开发的文本到 3D 模型,它使用预训练的 2D 文本到图像扩散模型来执行文本到 3D 合成 [24]。特别是,Dreamfusion 将以前的 CLIP 技术替换为从 2D 扩散模型中提取的损失。具体来说,扩散模型可以用作一般连续优化问题中的损失来生成样本。至关重要的是,参数空间中的采样比像素中的采样要困难得多,因为我们想要创建从随机角度渲染时看起来像好的图像的 3D 模型。为了解决这个问题,这个模型使用了一个可微分的生成器。其他方法侧重于对像素进行采样,但是,该模型侧重于创建从随机角度渲染时看起来像好图像的 3D 模型。
Dreamfusion 从一个特定角度创建的图像以及可以从其他文本提示生成的所有变体。为了看到完整的动画图像,我们建议访问 Dreamfusion 的网页。
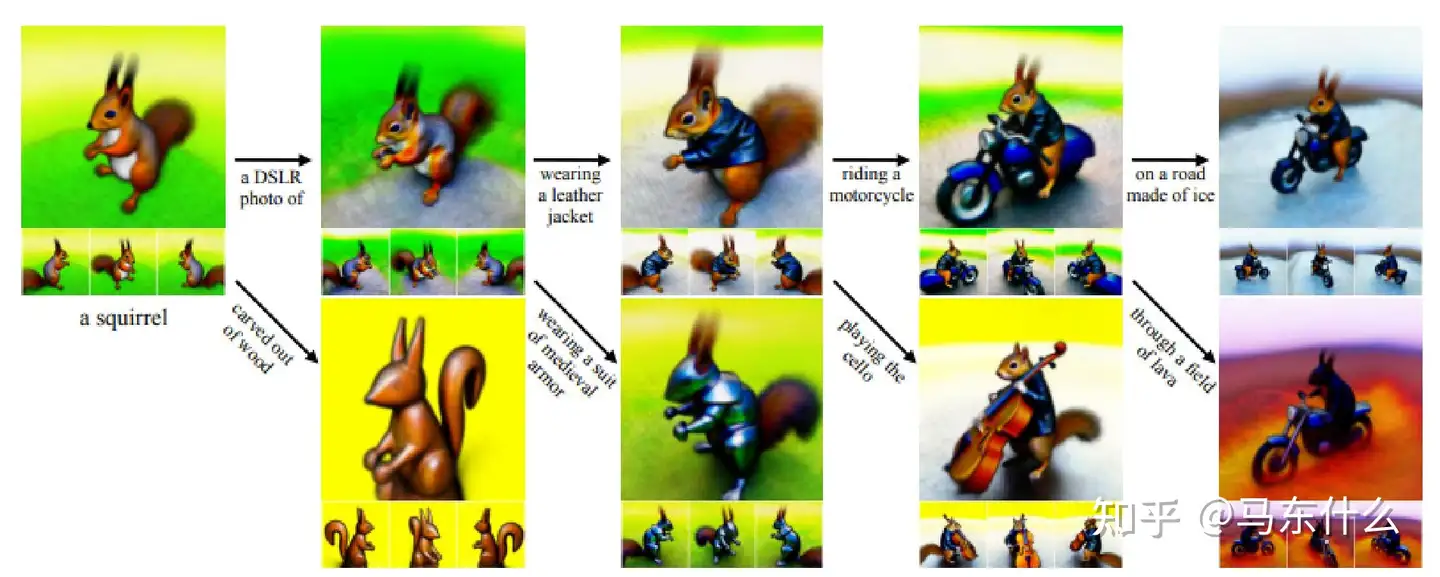
图 8. 左侧显示了 Dreamfusion 生成的 3D 松鼠。然后,其他图像包含对松鼠生成的修改,带有文本提示,如“穿夹克” Magic3D
该模型是NVIDIA公司制作的文本转3D模型。虽然 Dreamfusion 模型取得了显着的效果,但该方法存在两个问题:主要是处理时间长和生成的图像质量低。然而,Magic3D 使用两阶段优化框架 [20] 解决了这些问题。首先,Magic3D 先验构建低分辨率扩散,然后使用稀疏 3D 哈希网格结构进行加速。使用它,带纹理的 3D 网格模型通过高效的可区分渲染进一步优化。相比之下,在人类评估方面,该模型取得了更好的结果,因为 61.7% 的人更喜欢该模型而不是 DreamFusion。正如我们在图 9 中看到的,与 DreamFusion 相比,Magic3D 在几何和纹理方面实现了更高质量的 3D 形状。
图 9. 由 Magic3D 和 Dreamfusion 生成的 3D 图像,其中“我们的”指的是 Magic3D。我们可以看到总共 8 个文本提示以及两个模型从该提示生成的图像。 有时,获取描述图像的文本也很有用,这恰好是对前面分析的图像到文本的模型的逆映射。下面将简单分析执行此任务的两个模型以及其他模型:Flamingo 和 VisualGPT。
Flamingo
一种由 Deepmind 创建的视觉语言模型,它在广泛的开放式视觉和语言任务中使用少量学习,只需提示一些输入/输出示例 [1]。具体来说,Flamingo 的输入包含视觉条件自回归文本生成模型,能够摄取一系列与图像和/或视频交错的文本标记,并生成文本作为输出。对模型连同照片或视频进行查询,然后模型使用文本答案进行回答。可以在图 10 中观察到一些示例。Flamingo 模型利用两个互补模型:一个分析视觉场景的视觉模型和一个执行基本推理形式的大型语言模型。语言模型是在大量文本数据上训练的。
图 10. 包含图像和文本的输入提示以及来自 Flamingo 的输出生成的文本响应。每列都包含一个示例,我们可以在其中看到 Flamingo 如何使用文本中的图像回答问题。 VisualGPT
VisualGPT 是 OpenAI [7] 制作的图像字幕模型。具体来说,VisualGPT 利用预训练语言模型 GPT-2 [5] 中的知识。为了弥合不同模态之间的语义鸿沟,一种新颖的编码器-解码器注意机制[33]被设计为具有不饱和整流门函数。至关重要的是,该模型的最大优势在于它不需要像其他图像到文本模型那样多的数据。特别是,提高图像字幕网络中的数据效率将使快速数据管理、稀有物体的描述以及专业领域的应用成为可能。最有趣的是,这个模型的 API 可以在 GitHub 上找到。我们在图 11 中包含了模型针对提供给模型的三幅图像生成的文本提示的三个示例。
正如我们在前面的内容中看到的,现在可以从文本生成图像。因此,下一个合乎逻辑的步骤是生成视频
Phenaki
该模型由 Google Research 开发,能够在给定一系列文本提示的情况下执行逼真的视频合成 [34]。最有趣的是,我们可以从 GitHub 访问模型的 API。特别是,Phenaki 是第一个可以从开放域时间变量提示生成视频的模型。为了解决数据问题,它对大型图像-文本对数据集以及较少数量的视频-文本示例进行联合训练,可以产生超出视频数据集可用范围的泛化。这主要是由于图像文本数据集有数十亿个输入,而文本视频数据集要小得多。同样,限制来自可变长度视频的计算能力。
该模型由三部分组成:C-ViT 编码器、训练转换器和视频生成器。编码器获得视频的压缩表示。第一个标记被转换为嵌入。接下来是时间变换器,然后是空间变换器。在空间变换器的输出之后,他们在没有激活的情况下应用单个线性投影将标记映射回像素空间。因此,即使提示是新的概念组合,该模型也会根据开放域提示生成时间上连贯且多样化的视频。视频可能长达几分钟,而模型是在 1.4 秒的视频上训练的。下面我们在图 12 和图 13 中显示了通过一系列文本提示以及从一系列文本提示和图像创建视频的一些示例。
图 12. Phenaki 模型在给出四种不同提示时创建的图像序列。 图 13. Phenaki 模型在给定图像和提示的情况下创建的图像序列。我们可以看到模型如何根据文本提示操作给定的图像。 Soundify
在视频编辑中,声音占故事的一半。但是,对于专业的视频编辑,问题来自于寻找合适的声音、对齐声音、视频和调整参数 [21]。为了解决这个问题,Soundify 是 Runway 开发的一个将音效与视频相匹配的系统。该系统使用优质音效库和 CLIP(一种具有前面提到的零镜头图像分类功能的神经网络)。具体来说,该系统分为三部分:分类、同步和混合。通过对视频中的发声器进行分类,分类将效果与视频相匹配。为了减少不同的声音发射器,视频根据绝对颜色直方图距离进行分割。在同步部分,确定间隔,将效果标签与每个帧进行比较,并精确定位高于阈值的连续匹配。在混音部分,效果被分成大约一秒的块。至关重要的是,块是通过淡入淡出拼接的。
图像并不是唯一重要的非结构化数据格式。对于视频、音乐和许多上下文,音频可能至关重要。因此,我们在本小节中分析输入信息为文本且输出信息为音频的三个模型。
AudioLM
此模型由 Google 开发,用于生成具有长期一致性的高质量音频。特别是,AudioLM 将输入音频映射到一系列离散标记中,并将音频生成作为该表示空间中的语言建模任务 [4]。通过对大量原始音频波形进行训练,AudioLM 学会在给出简短提示的情况下生成自然且连贯的连续音。尽管在没有任何音乐符号表示的情况下接受训练,但该方法可以通过生成连贯的钢琴音乐延续来扩展到语音之外。与其他模型一样,可以通过 GitHub 找到 API。音频信号涉及多个抽象尺度。在音频合成方面,多个音阶使得在显示一致性的同时实现高音频质量非常具有挑战性。该模型通过结合神经音频压缩、自监督表示学习和语言建模方面的最新进展来实现这一目标。
在主观评价方面,评分者被要求听一段 10 秒的样本,并判断它是人类语音还是合成延续。基于收集到的 1000 个评分,该率为 51.2%,这与随机分配标签相比没有统计学意义。这告诉我们,人类无法区分合成样本和真实样本。
Jukebox
这是一个由 OpenAI 开发的模型,可以在原始音频域 [13] 中通过唱歌生成音乐。同样,它的 API 可以在 GitHub 中找到。以前,文本到音乐类型中的早期模型以指定时间、音高和速度的钢琴卷轴的形式象征性地生成音乐。具有挑战性的方面是尝试将音乐直接制作为一段音频的非符号方法。事实上,原始音频的空间维度非常高,这使得问题非常具有挑战性。因此,关键问题是对原始音频进行建模会产生远程依赖性,这使得学习音乐的高级语义在计算上具有挑战性。
为了解决这个问题,该模型试图通过分层 VQ-VAE 架构来解决它,将音频压缩到离散空间 [14],损失函数旨在保留最多的信息量。该模型可制作摇滚、嘻哈和爵士等不同流派的歌曲。但是,该模型仅限于英文歌曲。具体来说,它的训练数据集来自 LyricWiki 的 120 万首歌曲。VQ-VAE 有 50 亿个参数,并在 9 秒的音频片段上训练了 3 天。
Whisper
该模型是由 OpenAI 开发的音频到文本转换器。它完成了该领域的几项任务:多语言语音识别、翻译和语言识别[26]。与之前的案例一样,它的 API 可以在 GitHub 网站上找到。语音识别系统的目标应该是开箱即用地在广泛的环境中可靠地工作,而不需要为每个部署分布对解码器进行有监督的微调。这很难,因为缺乏高质量的预训练解码器。
具体来说,这个模型是在 680,000 小时的标记音频数据上训练的。这些数据是从互联网上收集的,这导致了一个非常多样化的数据集,涵盖了来自许多不同环境、录音设置、说话者和语言的广泛分布的音频。该模型确保数据集仅来自人声,因为机器学习语音会损害模型。文件在 30 秒的片段中被破坏,与该时间片段内出现的转录子集配对。该模型有一个编码器-解码器转换器,因为该架构已被验证可以可靠地扩展。我们可以通过下图观察模型的架构特征。我们可以看到不同类型的数据和学习顺序。
以前的模型都是将一种非结构化数据类型转换为另一种数据类型。但是,对于文本,将文本转换为另一种文本以满足一般问答等任务非常有用。以下四种模型处理文本,也输出文本,以满足不同的需求。
ChatGPT
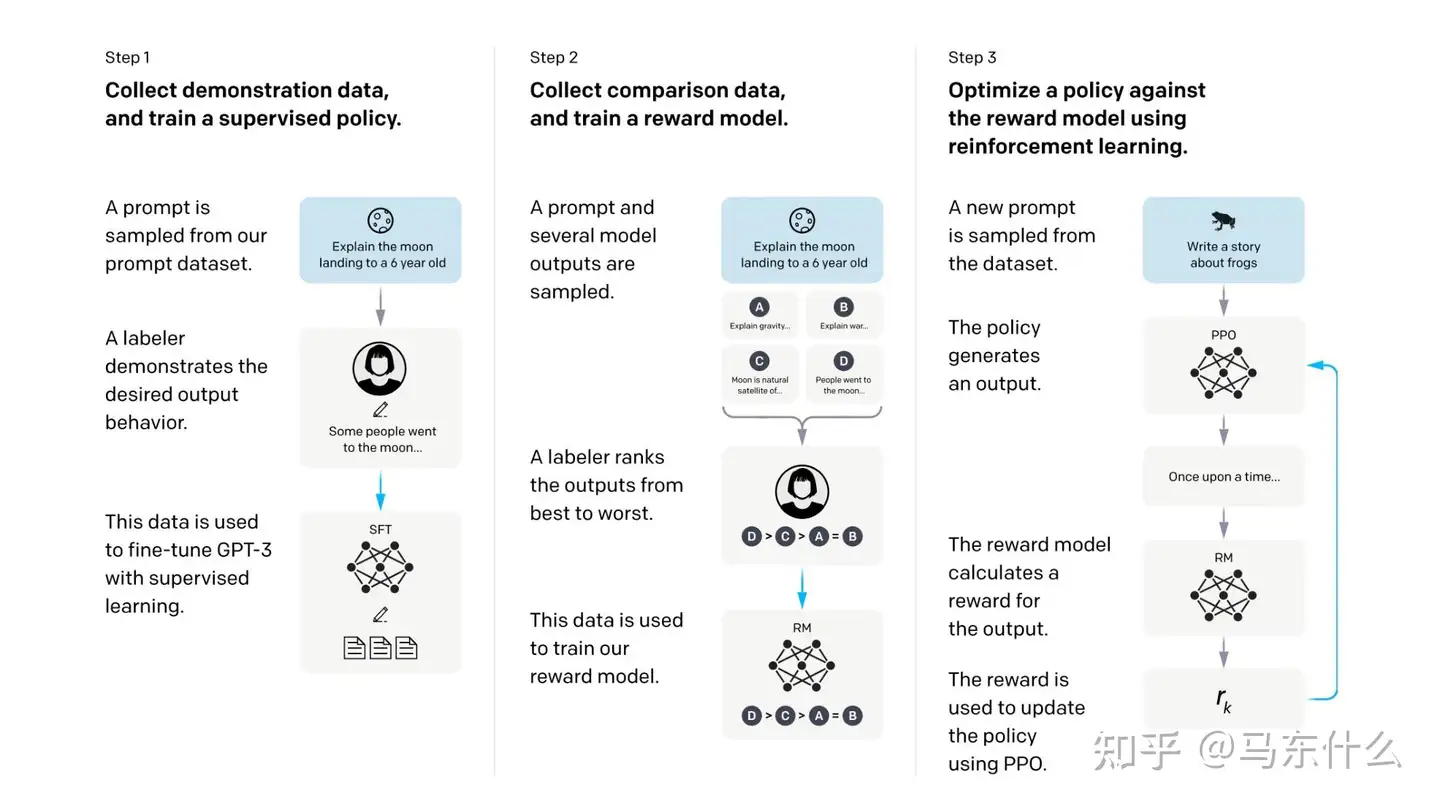
流行的 ChatGPT 是 OpenAI 的一种模型,它以对话方式进行交互。众所周知,该模型会回答后续问题、挑战不正确的前提并拒绝不适当的请求。更具体地说,ChatGPT 背后的算法基于转换器。然而,训练是通过人类反馈的强化学习进行的。特别是,初始模型是使用有监督的微调进行训练的:人类 AI 训练员将提供他们扮演双方的对话,即用户和 AI 助手。然后,这些人将获得模型编写的回复,以帮助他们撰写回复。该数据集与 InstructGPT [3] 的数据集混合,后者被转换为对话格式。可以在他们的网站上找到演示,也可以在 OpenAI 的网站上找到 API。我们在图 14 中总结了 ChatGPT 训练的主要步骤,可在 ChatGPT 演示网站上找到。最后,ChatGPT 还能够生成代码和简单的数学运算。
LaMDA
LaMDA 是对话应用程序的语言模型 [32]。与大多数其他语言模型不同,LaMDA 接受了对话训练。它是一系列专门用于对话的基于 Transformer 的神经语言模型,具有多达 137B 个参数,并在 1.56T 公共对话数据和网络文本的单词上进行了预训练。微调可以确保模型的安全性和事实基础。只有 0.001% 的训练数据用于微调,这是该模型的一大成就。特别是,对话模式利用了 Transformer 在文本中呈现长期依赖关系的能力。具体来说,它们通常非常适合模型缩放。因此,LaMDA 使用单个模型来执行多项任务:它生成多个响应,这些响应经过安全过滤,基于外部知识源并重新排序以找到最高质量的响应。我们在图 15 中说明了与模型的对话示例。
PEER
由 Meta AI 研究开发的协作语言模型,在编辑历史上进行训练以涵盖整个写作过程 [29]。它基于四个图 14. ChatGPT 的训练步骤,将监督学习与强化学习相结合。步骤:计划、编辑、解释和重复。重复这些步骤,直到文本处于不需要进一步更新的令人满意的状态。该模型允许将撰写论文的任务分解为多个更容易的子任务。此外,该模型还允许人类随时进行干预并将模型引导至任何方向。
它主要接受维基百科编辑历史的训练。该方法是一种自我训练,使用模型来填充缺失的数据,然后在该合成数据上训练其他模型。这样做的缺点来自评论非常嘈杂和缺乏引用,这试图通过并不总是有效的检索系统来弥补。该框架基于迭代过程。制定计划、收集文件、执行编辑和解释它的整个过程可以重复多次,直到得出一个文本序列。对于训练,使用了 DeepSpeed transformer。
Meta AI Speech from Brain
Meta AI 开发的模型,用于帮助无法通过语音、打字或手势进行交流的人们 [11]。以前的技术依赖于需要神经外科干预的侵入性大脑记录技术。该模型试图直接从非侵入性大脑记录中解码语言。这将提供更安全、更具可扩展性的解决方案,使更多人受益。这种提出的方法的挑战来自每个人大脑中的噪声和差异以及传感器的放置位置。深度学习模型通过对比学习进行训练,并用于最大限度地对齐非侵入性大脑记录和语音。一种称为 wave2vec 2.0 的自监督学习模型。用于识别听有声读物的志愿者大脑中语音的复杂表征。用于测量神经元活动的两种非侵入性技术是脑电图和脑磁图。
训练数据来自四个开源数据集,代表 169 名志愿者收听有声读物的 150 小时录音。EEG 和 MEG 记录被插入大脑模型,该模型由具有残留连接的标准深度卷积网络组成。这些录音来自个人的大脑。然后,该模型同时具有声音的语音模型和 MEG 数据的大脑模型。结果表明,该算法的几个组成部分有利于解码性能。同样,分析表明该算法随着 EEG 和 MEG 记录的增加而改进。这项研究表明,尽管数据存在噪声和可变性,但经过自我监督训练的 AI 可以解码感知语音。这项研究的最大局限在于它侧重于语音感知,但最终目标是将这项工作扩展到语音生成。
虽然我们已经介绍了文本到文本模型,但并非所有文本都遵循相同的语法。一种特殊类型的文本是代码。在编程中,知道如何将想法转化为代码是必不可少的。为此,Codex 和 Alphacode 模型会有所帮助。
Codex
由 OpenAI 创建的 AI 系统,可将文本翻译成代码。它是一种通用编程模型,因为它基本上可以应用于任何编程任务 [8]。编程可以分为两部分:将问题分解为更简单的问题,并将这些问题映射到已经存在的现有代码(库、API 或函数)中。第二部分是程序员时间限制最多的部分,也是Codex最擅长的地方。为训练收集的数据是 2020 年 5 月从托管在 GitHub 上的公共软件存储库收集的,其中包含 179GB 的 1 MB 以下的唯一 Python 文件。该模型是根据 GPT-3 进行微调的,GPT-3 已经包含强大的自然语言表示。演示和 API 可以在 Open AI 的网站上找到。
Alphacode
其他语言模型已经展示了令人印象深刻的代码生成能力,但这些系统在评估更复杂、未见过的问题时仍然表现不佳。然而,Alphacode 是一个用于为需要更深入推理的问题生成代码的系统 [19]。三个组成部分是实现这一成就的关键:拥有用于训练和评估的广泛数据集、大型且高效的基于 Transformer 的架构以及大规模模型采样。在训练方面,该模型首先通过总计 715.1 GB 代码的 GitHub 存储库进行预训练。这是一个比 Codex 的预训练数据集更广泛的数据集。为了更好地训练,从 Codeforces 平台引入了微调数据集。通过这个平台,代码竞赛在验证阶段进行,我们在这个阶段提高了模型的性能。关于基于转换器的架构,他们使用编码器-解码器转换器架构。与常用的解码器架构相比,这种架构允许双向描述和额外的灵活性。同样,他们使用浅层编码器和深度编码器来提高模型的效率。为了降低采样成本,使用了多查询注意力。
即使是科学文本也正在成为生成式人工智能的目标。尽管要在该领域取得成功还有很长的路要走,但研究自动科学文本生成的首次尝试至关重要。
Galactica
Galactica 是 Meta AI 和 Papers with Code 开发的自动组织科学的新型大型模型。该模型的主要优点是能够对其进行多个时期的训练而不会过度拟合,其中上游和下游性能通过使用重复标记得到改善。数据集设计对该方法至关重要,因为所有数据均以通用降价格式处理,以混合不同来源的知识。引文通过特定的标记进行处理,该标记允许研究人员在给定任何输入上下文的情况下预测引文。模型预测引用的能力随着规模的扩大而提高,并且模型在引用分布方面变得更好。此外,该模型可以执行涉及 SMILES 化学公式和蛋白质序列的多模态任务。具体而言,Galactica 在仅解码器设置中使用 Transformer 架构,并为所有模型尺寸激活 GeLU。
Minerva
能够使用逐步推理解决数学和科学问题的语言模型。Minerva 非常明确地专注于为此目的收集训练数据。它解决定量推理问题,大规模制作模型并采用一流的推理技术。具体来说,Minerva 通过逐步生成解决方案来解决这些问题,这意味着包括计算和符号操作,而不需要计算器等外部工具。
Alphatensor
由研究公司 Deepmind 创建的 Alphatensor 因其发现新算法的能力而成为业界完全革命性的模型 [15]。在已发布的示例中,Alpha Tensor 创建了一种更高效的矩阵乘法算法,这非常重要,因为提高算法的效率会影响很多计算,从神经网络到科学计算例程。
该方法基于深度强化学习方法,其中训练代理 AlphaTensor 玩单人游戏,目标是在有限因子空间内找到张量分解。在 TensorGame 的每一步,玩家选择如何组合矩阵的不同条目以进行相乘。根据达到正确乘法结果所需的选定运算次数分配分数。为了解决代理 TensorGame,开发了 AlphaTensor。AlphaTensor 使用专门的神经网络架构来利用合成训练游戏的对称性。
GATO
GATO是Deepmind做的一个单一的通才智能体。它作为一种多模式、多任务、多实施的通才政策 [27]。具有相同权重的相同网络可以承载与播放 Atari、字幕图像、聊天、堆叠积木等截然不同的功能。在所有任务中使用单一神经序列模型有很多好处。它减少了对具有归纳偏差的手工制定政策模型的需求。它增加了训练数据的数量和多样性。这个通用代理在许多任务上都取得了成功,并且可以用很少的额外数据进行调整以在更多任务上取得成功。 r 在模型规模的操作点进行训练,允许实时控制现实世界的机器人,目前在 GATO 的情况下约为 1.2B 参数。
AIGC 的基础
基础模型 Transformer
Transformer 是许多最先进模型的骨干架构,例如 GPT-3 [9]、DALL-E-2 [5]、Codex [2] 和 Gopher [39]。它最初被提出是为了解决传统模型(如 RNN)在处理可变长度序列和上下文感知方面的局限性。Transformer 架构主要基于一种自注意力机制,该机制允许模型关注输入序列中的不同部分。 Transformer 由编码器和解码器组成。编码器接收输入序列并生成隐藏表示,而解码器接收隐藏表示并生成输出序列。编码器和解码器的每一层都由多头注意力和前馈神经网络组成。多头注意力是 Transformer 的核心组件,它学习根据令牌的相关性为令牌分配不同的权重。这种信息路由方法使模型能够更好地处理长期依赖性,从而提高各种 NLP 任务的性能。Transformer 的另一个优点是其架构使其高度可并行化,并允许数据战胜归纳偏差 [40]。此属性使 transformer 非常适合大规模预训练,使基于 transformer 的模型能够适应不同的下游任务。
Pre-trained Language Models(PLM)
自从引入 Transformer 架构以来,由于其并行性和学习能力,它已成为自然语言处理中的主导选择。通常,这些基于 transformer 的预训练语言模型通常可以根据其训练任务分为两类:autoregressive language modeling和masked language modeling [41]。给定一个由多个标记组成的句子,掩码语言建模的目标,例如 BERT [42] 和 RoBERTa [43],是指在给定上下文信息的情况下预测掩码标记的概率。掩蔽语言建模最著名的例子是 BERT [42],它包括掩蔽语言建模和下一句预测任务。
RoBERTa [43] 使用与 BERT 相同的架构,通过增加预训练数据量和纳入更具挑战性的预训练目标来提高其性能。同样基于 BERT 的 XL-Net [44] 结合了置换操作来更改每次训练迭代的预测顺序,从而使模型能够跨令牌学习更多信息。自回归语言建模,例如 GPT-3 [9] 和 OPT [45],是在给定先前标记的情况下对下一个标记的概率进行建模,因此是从左到右的语言建模。与掩码语言模型不同,自回归模型更适合生成任务。
Reinforcement Learning from Human Feedback
尽管接受了大规模数据的训练,AIGC 可能并不总是产生符合用户意图的输出,其中包括对有用性和真实性的考虑。为了更好地使 AIGC 输出与人类偏好保持一致,人类反馈强化学习 (RLHF) 已应用于各种应用程序中的模型微调,例如 Sparrow、InstructGPT 和 ChatGPT [10、46] 。
通常,RLHF 的整个流程包括以下三个步骤:预训练、奖励学习和强化学习微调 。首先,语言模型 �0
作为初始语言模型在大规模数据集上进行了预训练 。由于 �0 对于人类给定的input x给出的答案可能不符合人类的目的,因此
在第二步中,我们训练奖励模型来编码多样化和复杂的人类偏好。具体来说,给定相同的 ,不同的生成答案
由人类以人肉的方式进行评估(这成本我擦) 。
随后使用 ELO [47] 等算法转移到逐点奖励标量
在最后一步中,语言模型 被微调以使用强化学习最大化学习到的奖励函数。为了稳定 RL 训练,Proximal Policy Optimization (PPO) 通常用作 RL 算法。在 RL 训练的每一集中,都会考虑一个经验估计的 KL 惩罚项,以防止模型输出一些特殊的东西来欺骗奖励模型。具体来说,每一步的总奖励
由
给出,其中
是学习的奖励模型,
是 KL 惩罚项,
是经过训练的策略。有关 RLHF 的更多详细信息,请参阅 [48]。
(RLHF的部分可以参考这篇文章的精彩描述Akiko:从零实现ChatGPT——RLHF技术笔记734 赞同 · 44 评论文章
)
尽管 RLHF 通过结合流利性显示出可喜的结果,但由于缺乏公开可用的基准和实施资源,这一领域的进展受到阻碍,导致人们认为 RL 是 NLP 的一种具有挑战性的方法。为了解决这个问题,最近引入了一个名为 RL4LMs [49] 的开源库,它包含用于在基于 LM 的生成上微调和评估 RL 算法的构建块。
除了人类反馈之外,最新的对话代理 Claude 支持宪法 AI [50],其中奖励模型是通过 RL 从 AI 反馈 (RLAIF) 中学习的。批评和 AI 反馈都以从“宪法”中得出的一小组原则为指导,这是人类唯一提供给Claude的东西。AI 反馈侧重于通过解释其对危险查询的反对意见来控制输出以降低危害。此外,最近对 RLAIF [51] 的初步理论分析证明了 RLHF 的经验成功,并为语言模型的专门 RLHF 算法设计提供了新的见解。
Computing
硬件
近年来,硬件的显着进步促进了大规模模型的训练。过去,使用 CPU 训练大型神经网络可能需要几天甚至几周的时间。但是,随着更强大的计算资源的出现,这个过程被加速了几个数量级。例如,NVIDIA A100 GPU 在 BERT-large 推理期间的速度是 V100 的 7 倍,是 T42 的 11 倍。此外,谷歌的张量处理单元 (TPU) 专为深度学习而设计,与当前一代的 A100 GPU3 相比,可提供更高的计算性能。这种计算能力的快速进步显着提高了 AI 模型训练的效率,并为开发大型复杂模型开辟了新的可能性。
分布式训练
另一个重大改进是分布式训练。在传统的机器学习中,训练通常在使用单个处理器的单个机器上执行。这种方法适用于小型数据集和模型,但在处理大型数据集和复杂模型时,这种方法显然不切实际。在分布式训练中,训练工作负载分配给多个处理器或机器,从而可以更快地训练模型。一些公司还发布了简化深度学习堆栈分布式训练过程的框架 [53-55]。这些框架提供的工具和 API 允许开发人员轻松地将他们的训练工作负载分布在多个处理器或机器上,而无需管理底层基础设施。
云计算
云计算在训练大规模模型方面也发挥了至关重要的作用。以前,模型通常在本地进行训练。现在,随着 AWS 和 Azure 等云计算服务提供对强大计算资源的访问,深度学习研究人员和从业者可以根据需要启动大型 GPU 或 TPU 集群来训练大型模型。总的来说,这些进步使得能够开发出更复杂、更准确的模型,为 AI 研究和应用的各个领域开辟了新的可能性。
生成式人工智能
单模态模型
在本节中,我们将介绍最先进的单模态生成模型。这些模型旨在接受特定的原始数据模态作为输入,例如文本或图像,然后以与输入相同的模态生成预测。我们将讨论这些模型中使用的一些最有前途的方法和技术,包括生成语言模型,例如 GPT3 [9]、BART [34]、T5 [56],以及生成视觉模型,例如 GAN [29]、 VAE [30] 和normalizng flow [57]。
生成式语言模型
生成语言模型 (GLM) 是一种 NLP 模型,经过训练可以根据输入数据中的模式和结构生成可读的人类语言。这些模型可用于广泛的 NLP 任务,例如对话系统 [58]、翻译 [59] 和问答 [60]。
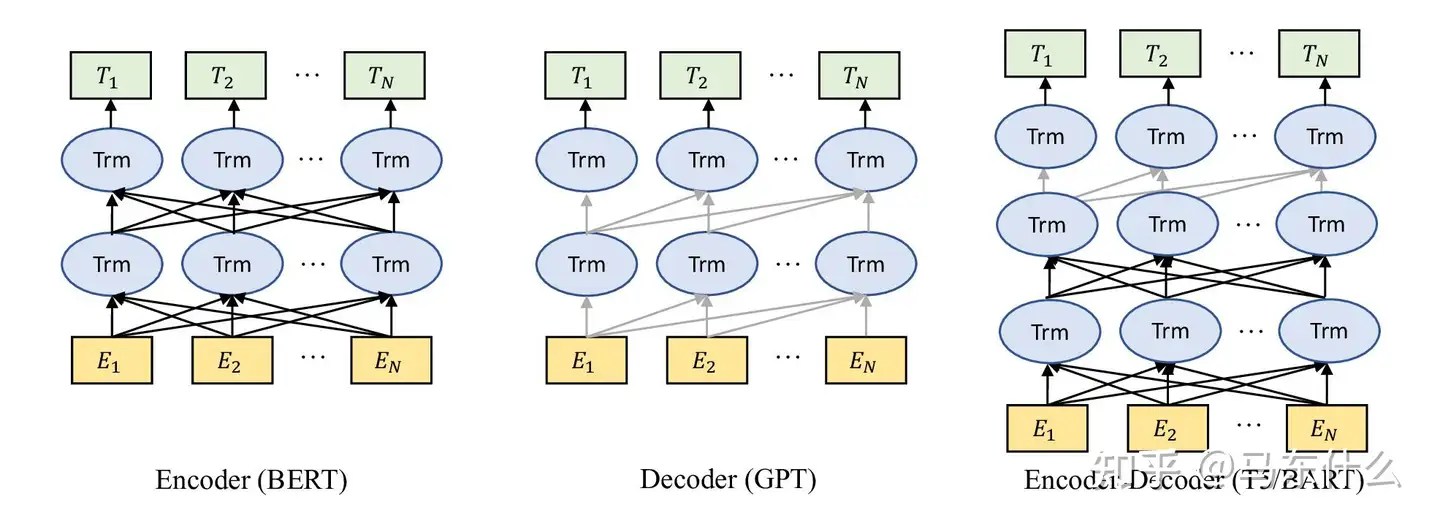
最近,预训练语言模型的使用已成为 NLP 领域的主流技术。通常,当前最先进的预训练语言模型可分为屏蔽语言模型(编码器)、自回归语言模型(解码器)和编码器-解码器语言模型,如图 4 所示
解码器模型广泛用于文本生成,而编码器模型主要应用于分类任务。通过结合这两种结构的优势,编码器-解码器模型可以利用上下文信息和自回归属性来提高各种任务的性能。本次调查的主要重点是生成模型。在以下部分中,我们将深入研究解码器和编码器-解码器架构的最新进展。
解码器模型
基于自回归解码器的语言模型最突出的例子之一是 GPT [61],它是一种基于transformer的模型,它利用自我注意机制同时处理序列中的所有单词。GPT 接受了基于先前单词的下一个单词预测任务的训练,使其能够生成连贯的文本。随后,GPT-2 [62] 和 GPT-3 [9] 保持自回归从左到右的训练方法,同时扩大模型参数并利用基本网络文本以外的多样化数据集。
Gopher [39] 使用类似 GPT 的结构,但将 LayerNorm [63] 替换为 RSNorm,其中在原始 layernorm 结构中添加了residual connection以维护信息。除了增强了norm function外,其他几项研究也集中在优化注意力机制上。BLOOM [64] 与 GPT-3 具有相同的结构,但 BLOOM 没有使用稀疏注意力,而是使用全注意力网络,更适合建模长依赖关系。 [65] 提出了 Megatron,它扩展了常用的架构。
在此之上,后续的比较突破性的发展的典型例子为instructgpt,
下图为InstructGPT [10] 的架构。
首先,演示数据由人工标记器收集,并用于微调 GPT-3。然后从语言模型中抽取提示和相应的答案,人工贴标签者将从最好到最差的答案进行排序。此数据用于训练奖励模型。最后,使用经过训练的奖励模型,可以根据人类标注者的偏好优化语言模型。
GPT-3、BERT 和 T5 具有分布式训练目标以处理大量数据。这种方法后来也被 MT-NLG [66] 和 OPT [45] 采用。除了模型架构和预训练任务方面的进步外,在改进语言模型的微调过程方面也付出了巨大的努力。例如,InstructGPT [10] 利用预训练的 GPT-3 并使用 RLHF 进行微调,允许模型根据人类标记的排名反馈来学习偏好。
编码器-解码器模型
一种主要的编码器-解码器方法是文本到文本传输转换器 (T5) [56],它将基于transformer的编码器和解码器组合在一起进行预训练。T5 采用“文本到文本”方法,这意味着它将输入和输出数据转换为标准化的文本格式。这使得 T5 可以使用相同的模型架构在广泛的 NLP 任务上进行训练,例如机器翻译、问答、摘要等。正如其名称所述,Switch Transformer [67] 利用“切换”(指简化的 MoE 路由算法)在 T5 上进行并行训练 。与基本模型相比,该模型在相同的计算资源下成功地获得了更大的规模和更好的性能。另一种广泛使用的改进 T5 的方法是 ExT5 [68],它由 Google 于 2021 年提出,扩展了之前 T5 模型的规模。与 T5 相比,ExT5 继续在 C4 和 ExMix 上进行预训练,ExMix 是跨不同领域的 107 个受监督 NLP 任务的组合。另一种广泛使用的编码器-解码器方法是 BART [34],它融合了 BERT 的双向编码器和 GPT 的自回归解码器 ,使其能够利用编码器的双向建模能力,同时保留生成任务的自回归属性。HTLM [69] 利用 BART 去噪目标对超文本语言进行建模 ,其中包含有关文档级结构的有价值信息。该模型还在各种生成任务的零样本学习上实现了最先进的性能。
相反,DQ-BART [70] 旨在使用蒸馏和量化将 BART 压缩成更小的模型,从而在各种下游任务上实现 BART 的原始性能。
生成式视觉模型
生成对抗网络 (GAN) 在图像生成研究领域的基于深度学习的比较早的成功的工作了。GAN 由两部分组成,生成器和鉴别器。生成器尝试学习真实示例的分布以生成新数据,而鉴别器则确定输入是否来自真实数据空间。
生成器和鉴别器的结构极大地影响了 GAN 的训练稳定性和性能 。LAPGAN [71] 使用拉普拉斯金字塔框架 [72] 中的级联卷积网络以从粗到精的方式生成高质量图像。 A. Radford 等人。 [73] 提出 DCGANs 结构,一类具有架构约束的 CNN,作为无监督学习的强大解决方案。Progressive GAN [74] 逐渐增加生成器和鉴别器,从低分辨率开始并添加层以对更精细的细节进行建模,从而实现更快、更稳定的训练并生成高质量的图像。由于传统的卷积 GAN 仅基于低分辨率特征图中的空间局部点生成高分辨率细节,SAGAN [75] 引入了注意力驱动的远程依赖建模和光谱归一化,以改善训练动态。此外,从复杂的数据集中生成高分辨率和多样化的样本仍然是一个挑战。为了解决这个问题,BigGAN [76] 被提议作为 GAN 的大规模 TPU 实现。StyleGAN [77] 通过分离高级属性和变体来改进 GAN,允许在质量指标、插值和分离方面进行直观控制和更好的性能。 [78, 79] 专注于逆映射——将数据投影回潜在空间,从而为辅助辨别任务提供有用的特征表示。为了解决模式崩溃和改进生成模型,D2GAN [80] 和 GMAN [81] 方法都通过结合额外的鉴别器扩展了传统的 GAN。MGAN [82] 和 MAD-GAN [83] 通过合并多个生成器和一个鉴别器来解决模式崩溃问题。CoGAN [84] 由一对具有权重共享约束的 GAN 组成,允许从单独的边缘分布中学习联合分布,而不需要训练集中的相应图像。
代表性变种: 由于生成器的潜在向量 是高度非结构化的,InfoGAN [85] 提出了另一种潜在代码 来提取实际数据空间的重要结构化特征。在 CGANs [86-88] 中,生成器和鉴别器以附加信息为条件,例如类标签或来自其他模态的数据,以生成以特定属性为条件的样本。 f-GAN [89] 允许使用任何 f-divergence 作为训练生成模型的目标函数。f-divergence 的选择为控制生成样本的质量和训练模型的难度之间的权衡提供了一个灵活的框架。
目标函数 :生成模型的目标是匹配真实的数据分布。WGAN [90] 和 LS-GAN [91, 92] 旨在使用真实数据密度的 Lipschitz 正则性条件对损失函数进行正则化,以便更好地泛化和生成真实的新数据。 [93] 是一种权重归一化技术,旨在稳定 GAN 中鉴别器的训练。车等。 [94] 正则化目标,可以稳定 GAN 模型的训练。UGAN [95] 通过定义关于鉴别器展开优化的生成器目标来稳定 GAN 的训练。 [96] 通过从真实/生成的数据对中采样来提高鉴别器的相对性,以提高生成器生成的数据分布的稳定性和覆盖率。
VAE: 在变分贝叶斯推理 [97] 之后,变分自动编码器 (VAE) 是一种生成模型,它试图将数据反映到概率分布中,并学习接近其原始输入的重建。
复杂的先验 :重写变分自动编码器的变分证据下限目标 (ELBO) 有助于改善变分界限 [98]。由于真正的聚合后验是难以处理的,VampPrior [99] 引入了以可学习的伪输入为条件的后验先验的变分混合。 [100–102] 提出围绕随机抽样过程跳过连接以捕获数据分布的不同方面。
正则化自动编码器 : [1, 103, 104] 将正则化引入编码器的潜在空间,并在不符合任意选择的先验条件的情况下产生平滑且具有代表性的潜在空间。 [105] 提出了一种多尺度分层组织来对较大的图像进行建模。
flow :归一化流是通过一系列可逆和可微映射从简单到复杂的分布转换。
Coupling and autoregressive flows: 通过[57]中的耦合方法学习数据的非线性确定性变换,使变换后的数据符合因式分布。丁等人。 [106] 提出多尺度流在生成方向上逐渐向分布引入维度。耦合层更灵活的推广是自回归流 [107–109],它允许将并行密度估计作为通用逼近器。
Convolutional and Residual Flows :郑等。 [110] 使用一维卷积 (ConvFlow) 和 Hoogeboom 等人。 [111] 为建模 d×d 卷积提供了更通用的解决方案。他们利用三角形结构来改善输入之间的相互作用并有效地计算行列式。RevNets [112] 和 iRevNets [113] 率先构建了基于残差连接的可逆网络架构,缓解了梯度消失问题。此外,残差连接可以看作是一阶常微分方程 (ODE) [114] 的离散化,以提高参数效率。
Diffusion :生成扩散模型 (GDM) 是一类前沿的基于概率的生成模型,展示了计算机视觉领域的最新成果。它的工作原理是通过多级噪声扰动逐步破坏数据,然后学习反转此过程以生成样本。
Model Formulations :扩散模型主要分为三类。DDPM [115]分别应用两个马尔可夫链来逐步破坏具有高斯噪声的数据,并通过学习马尔可夫转移核来逆转前向扩散过程。基于分数的生成模型 (SGM) 直接作用于数据对数密度的梯度,也就是分数函数。NCSN[31] 用多尺度增强噪声扰动数据,并通过以所有噪声水平为条件的神经网络联合估计所有此类噪声数据分布的得分函数。由于完全分离的训练和推理步骤,它享有灵活的采样。Score SDE [116] 将前两个公式概括为连续设置,其中噪声扰动和去噪过程是随机微分方程的解。事实证明,概率流 ODE 也可以用来模拟逆向过程。
Training Enhancement :训练增强旨在通过引入来自另一个预训练模型或额外可训练超参数的先验知识来改进采样。受知识蒸馏思想的启发,Salimans 等人。 [117] 建议逐步将知识从预训练的复杂教师模型提取到更快的学生模型,这可以将采样步骤减半。TDPM [118] 和 ES-DDPM [119] 通过提前停止截断扩散过程来提高采样速度。为了从非高斯分布初始化的逆向过程生成样本,引入了另一种预训练的生成模型,如 VAE 或 GAN 来近似这种分布。法兰赛斯等。 [120] 将训练步骤的数量制定为变量以实现最佳权衡。改进的 DDPM [121] 首先通过将噪声尺度项添加到损失函数中来引入噪声尺度调整。同时,San Romans 等人 [122] 引入了噪声预测网络以逐步调整噪声调度。这种噪声调度学习通过在训练和推理期间有效地引导噪声的随机游走来改进重建。
Efficient Training-free Sampling :无需额外训练,免训练采样直接减少离散化时间步长的数量,同时最大限度地减少离散化误差。在相同的训练目标下,DDIM [123] 将 DDPM 推广到一类非马尔可夫扩散过程并引入跳跃加速。这可以提供更短的生成马尔可夫链。AnalyticDPM [124] 通过估计最优模型逆向方差的解析形式和 KL-divergence w.r.t 其得分函数来提供更有效的推理。还有一些作品 [125, 126] 通过动态规划直接计算出最佳采样轨迹。
Noise Distribution :噪声扰动的分布是扩散模型的重要组成部分,其中大部分是高斯分布。同时,以更多的自由度拟合这种分布可以提高性能。Nachmani 等人。 [127] 证明 Gamma 分布可以改善图像和语音的生成,高斯分布的混合也优于单一分布。此外,冷扩散 [128] 提出了一个更普遍的结论,即噪声可以设置为任何分布作为生成行为扩散模型并不强烈依赖于噪声分布的选择。除了噪声扰动,CCDF [129] 表明没有必要从高斯分布进行初始化,它可以通过简单的前向扩散减少采样步骤,但噪声初始化更好。
Mixed Modeling: 混合建模旨在将扩散模型与另一类生成模型相结合,以充分利用它们的所有优点,从而提供更强的表现力或更高的采样速度。DiffuseVAE [130] 通过使用 VAE 生成的模糊图像重建调节扩散采样过程,将标准 VAE 合并到 DDPM 管道中。LSGM [131] 在 VAE 的潜在空间中训练 SGM,将 SGM 泛化为非连续数据,并使 SGM 在小空间内学习更流畅。去噪扩散 GAN [132] 将条件 GAN 引入 DDPM 管道,以使用更具表现力的多模态分布参数化去噪过程,从而提供大的去噪步骤。DiffFlow [133] 将流函数集成到图 8 中。
生成视觉语言的一般结构。我们将生成过程分为编码器部分和解码器部分。编码器模型会将输入编码为潜在表示,然后解码器会将此表示解码为生成的输出。 基于 SDE 的扩散模型的轨迹,这使得向前的步骤也可以训练。从噪声扰动中引入的随机性赋予归一化流更强的表达能力,而可训练的正向过程大大减少了扩散轨迹长度。因此,DiffFlow 能够以更好的采样效率学习边界更清晰的分布。
单模态本身相对多模态简单一些,因为不需要额外的跨模态的一些特殊设计,单模态模型。。。额,话说去掉了多模态模型之后其它的vit,resnet,bert,tabnet,tft这些不都是传统的单模态模型么。。
多模态模型
多模态生成是当今 AIGC 的重要组成部分。多模态生成的目标是通过学习数据中的多模态连接和交互来学习生成原始模态的模型 [7]。模态之间的这种联系和相互作用有时可能非常复杂,这使得与单模态表示空间相比,多模态表示空间难以学习。然而,随着前面章节中提到的强大的特定于模式的基础架构的出现,越来越多的方法被提出来应对这一挑战。在本节中,我们介绍了视觉语言生成、文本音频生成、文本图生成和文本代码生成方面最先进的多模态模型。由于大多数多模态生成模型总是与实际应用高度相关,因此本节将主要从下游任务的角度进行介绍。
视觉语言生成
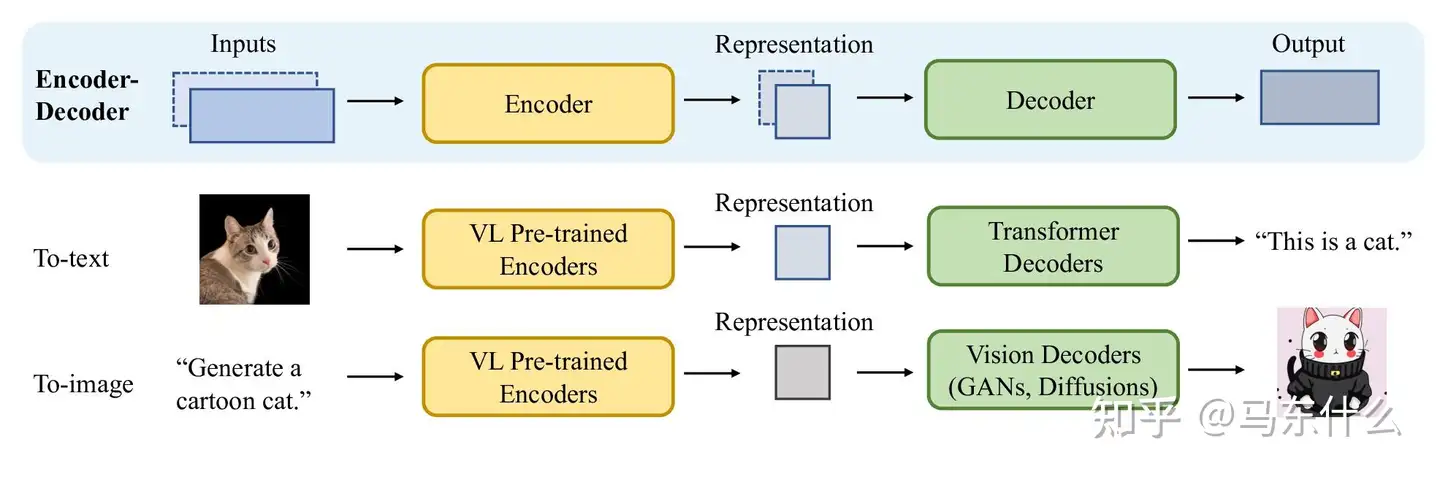
编码器-解码器架构是一种广泛使用的框架,用于解决计算机视觉和自然语言处理中的单峰生成问题。在多模态生成中,特别是在视觉语言生成中,这种方法经常被用作基础架构 。编码器负责学习输入数据的上下文表示,而解码器用于生成反映跨模态交互、结构和表示中连贯性的原始模态 。在下文中,我们对最先进的视觉语言编码器进行了全面调查,然后对解码器组件进行了阐述。
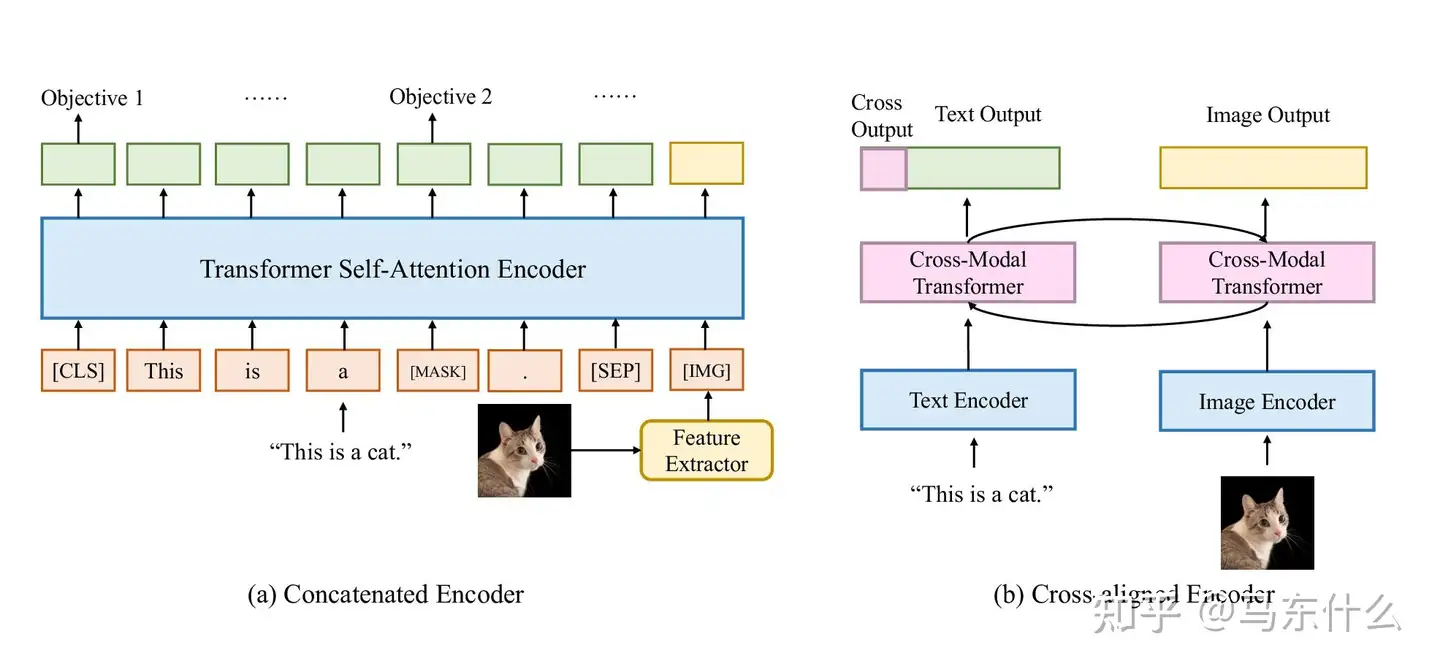
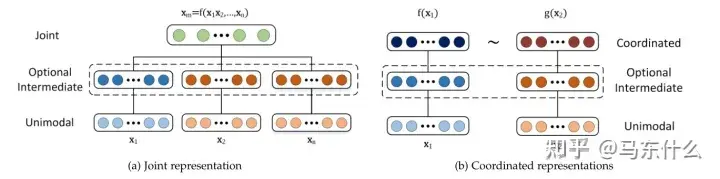
视觉语言编码器。最近,用于单一模态的编码器的开发取得了显着进步,引发了如何从多种模态中学习上下文表示的问题。一种常见的方法是使用融合函数组合特定于模态的编码器,然后利用多个预训练任务来对齐表示空间 [37、134、135]。一般来说。这些编码器模型可以分为两类,级联编码器和交叉对齐编码器 [7](说白了就是单塔和双塔)。
两种类型的视觉语言编码器:级联编码器和交叉对齐编码器。前者直接单塔内直接交互,后者在双塔之间存在约束(例如clip中的dual encoder)。 级联编码器(单塔) 多模态之间的交互的最直接的思路是连接来自单个编码器的嵌入。马东什么:多模态206 赞同 · 3 评论文章
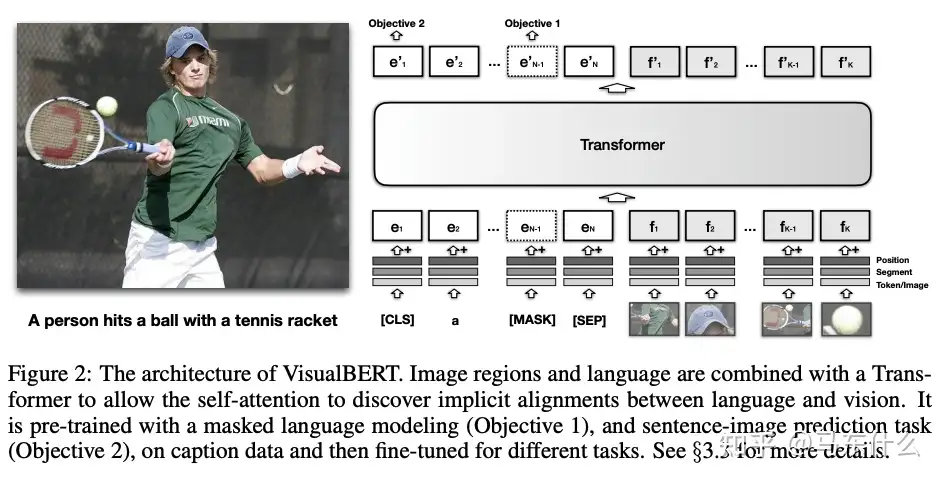
一个早期的例子是 VisualBERT [134],它利用了 BERT的结构(如下图)。马东什么:多模态 一个早期的例子是 VisualBERT [134],它利用了 BERT的结构(如下图)。
其中,bert作为文本编码器,CNN 作为图像编码器。来自图像编码器的嵌入将直接合并到 BERT 的token嵌入中,用的是joint representation
允许模型隐式学习对齐的联合表示空间
使用了隐式对齐
所谓隐式就是放到一个layer组件中做自由的交互,显式则是同一个样本的不同模态视角之间做一些距离计算之类的进行约束 VisualBERT 还利用了与 BERT 一样的多任务预训练范式,使用两个基于视觉的语言模型目标:使用图像和句子图像预测进行掩码语言建模。此外,VisualBERT 还结合了一些特定于模态的pretrain task。
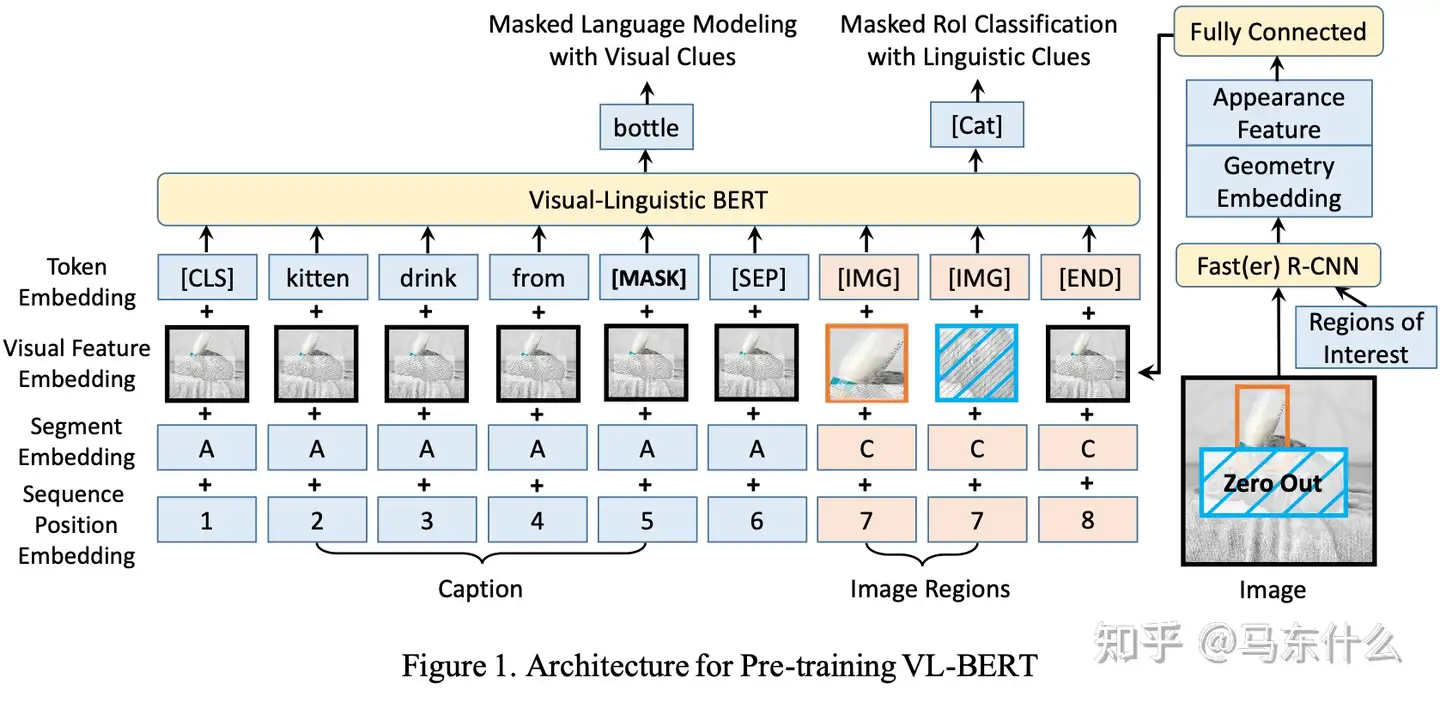
另一个例子是 VL-BERT [136],它与 VisualBERT 具有相似的架构。
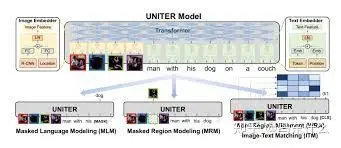
与 VisualBERT 不同,VL-BERT 使用 Faster R-CNN [137] 作为感兴趣区域 (ROI) 提取器,并利用提取的 ROI 信息作为图像区域嵌入。VL-BERT 还包括一个额外的预训练任务,即带有语言线索的mask ROI 分类,以更好地结合视觉信息。后来,基于与 VisualBERT 相同的架构,提出了 UNITER [ 138],
uniter具有不同的训练目标。UNITER使用掩码语言建模、掩码区域建模、图像文本匹配预测和词区域对齐预测作为其预训练任务 。通过这种方式,UNITER 可以学习信息丰富的上下文嵌入。为此,我们看到级联编码器通常基于相同的 BERT 架构,并使用类似 BERT 的任务进行预训练。然而,这些模型总是涉及非常复杂的预训练过程、数据收集和损失设计。为了解决这个问题,[135] 提出了 SimVLM,它通过将 PrefixLM 设置为训练目标并直接使用 ViT 作为文本编码器和图像编码器来简化视觉语言模型的预训练过程。 与以前的方法相比,SimVLM 在多种视觉语言任务上实现了最先进的性能,并且架构大大简化。
交叉对齐编码器(双塔or多塔)
另一种学习上下文表示的方法是查看模态之间的成对交互 [7]。与单塔结构不同,交叉对齐编码器始终使用双塔结构,其中每个模态一个塔,然后使用交叉模态编码器学习联合表示空间 。
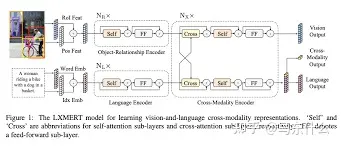
LXMERT [139] 使用 Transformers 提取图像特征和文本特征,
然后添加多模态交叉注意力模块进行协调学习。生成的输出嵌入将是视觉嵌入、语言嵌入和多模态嵌入。该模型还使用多个多模态任务进行了预训练。
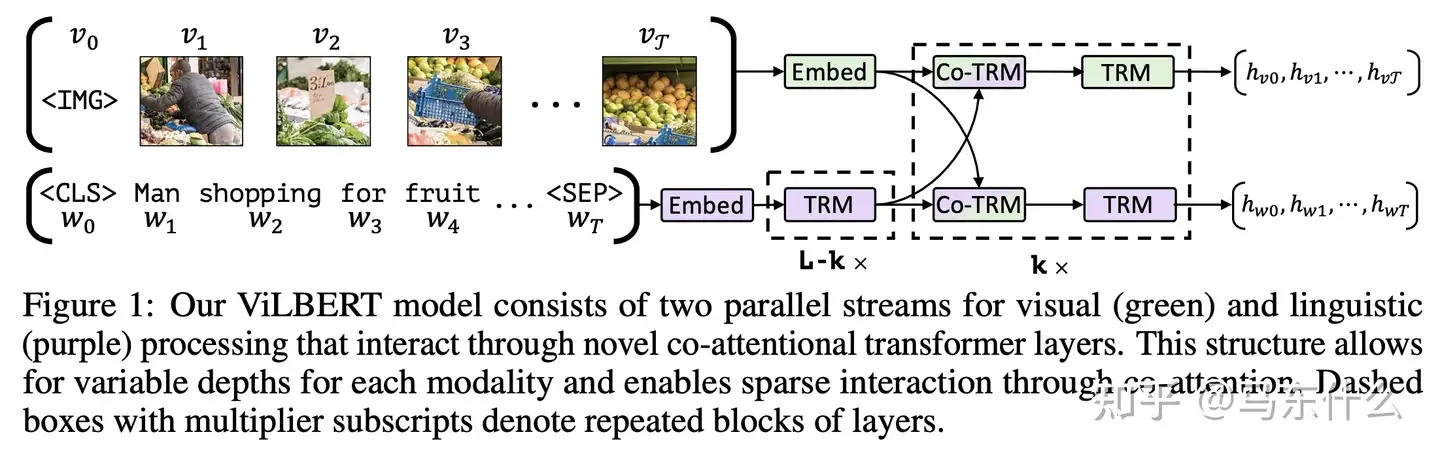
同样,ViLBERT [140] 利用cross transformer模块来对齐两种模式。
给定视觉和语言嵌入,一种特定模态的key和value将被输入到另一种模态的注意力模块中,以生成包含这两种信息的集合注意力嵌入。通常,这些模型都利用跨层将信息融合到联合表示空间中。然而,由于其大量参数,在这种情况下使用transformer架构将是低效的。为了简化训练过程和计算,CLIP [37] 使用点积作为交叉层,比 使用cross Transformer 做多个模态之间的交互更高效,能够实现高效的大规模下游训练。此外,CLIP 在大量成对数据上进行了训练,这已被证明优于许多其他模型 。
文本解码器
给定某种模态的表示,视觉语言解码器的主要目的是将其转换为任务指定的某种原始模态(不同模态之间的translation )。这里主要关注文本到图像解码器(例如以文生图)和图像到文本的解码器(例如图片注释)。
图像到文本解码器 ,通常从编码器获取上下文表示,并将该表示解码为句子。随着大型语言模型的出现和有效性的验证,许多架构现在选择性地冻结语言解码器组件 。因此,文本解码器可以大致分为两类:联合训练模型和冻结编码器 。
联合训练的解码器
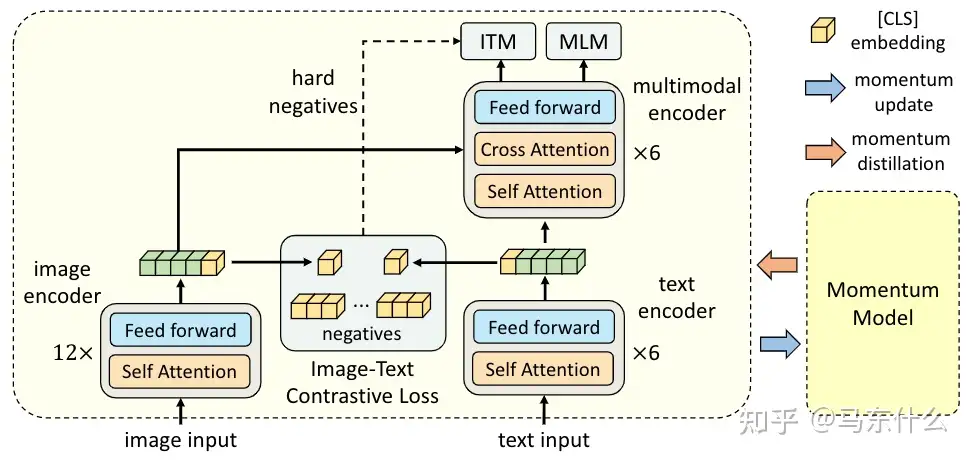
联合训练的解码器是指在解码表示时需要完整的交叉模式训练的解码器。图像本到文本生成的挑战通常在于在预训练期间如何对齐两种模式 。因此,这类模型需要更强大的编码器而不是解码器 。为了应对这一挑战,许多模型优先构建强大的编码器,然后将其与相对轻量级的解码器模型相结合 。例如,VLP [138] 和 ALBEF [141] 利用一个简单的转换器解码器来解码信息:
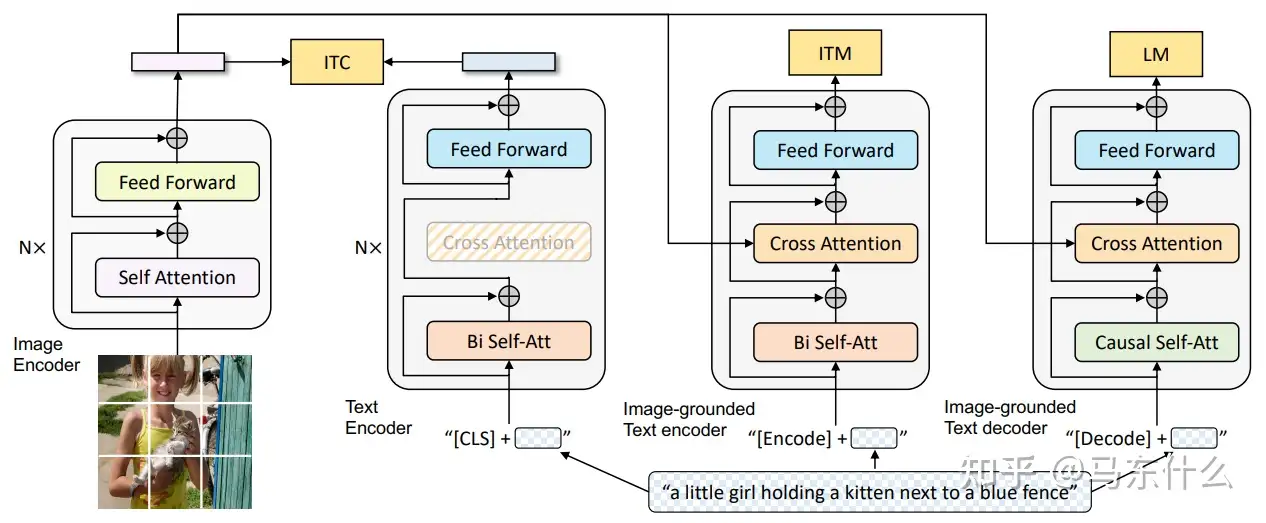
ALBEF BLIP [142] 在预训练期间将编码器和解码器结合在一起,允许多模式空间对齐以实现理解和生成目标。
BLIP 由三部分组成,一个用于提取图像和文本特征的单模态编码器,一个接受图像和文本特征作为输入的图像文本编码器,以及一个接受图像特征并输出文本的图像接地文本解码器。除了对齐的编码器和解码器结构,作者还设计了几个相应的预训练任务来帮助模型更好地学习多模态依赖。
冻结编码器
另一种有效执行图像到文本生成任务的方法是冻结大型语言模型并仅训练图像编码器 ,这也可以看作是执行多模态prompt的一种方法。由于 NLP 中prompt和in context learning的成功,人们越来越关注这种性质的方法。这让人们质疑这种方法在多模式环境中是否也有效。Frozen [143] 首先将in context learning引入视觉语言任务。它冻结了语言模型,只训练图像编码器。生成的图像表示将嵌入到语言模型的输入嵌入中。该方法在各种零样本和少样本视觉语言任务中实现了最先进的性能 。
后来,Alayrac 等人提出了 Flamingo [144],它进一步探索了多模态的in context learning。Flamingo 涉及冻结视觉编码器和冻结语言编码器以获得视觉语言表示,并利用门控交叉注意力密集层将图像表示融合为文本表示 。最近,[145] 提出了一种用冻结语言模型实现 Visual和nlp 交互的方法,使模型能够生成交错的多模态数据。该方法还冻结输入编码器并训练文本到图像和图像到文本的线性映射,以进一步编码和解码生成的嵌入。然而,为什么这种基于prompt的方法在多模态生成中起作用仍然是一个问题。此外还提出了一些作品来回答这个问题。梅鲁洛等。提出了一种在冻结图像编码器和文本编码器之间注入线性投影的方法[146]。在训练期间,只调整线性投影。实验结果表明,具有相似大小的冻结语言模型通常在将视觉信息转换为语言方面表现同样出色,但经过语言监督预训练的图像编码器(如 CLIP 文本编码器)可以对额外信息进行编码,从而在视觉语言任务上表现得更好。
图像解码器 text to image generation是指给定一个指令,生成一个与该指令对应的图像。同样,图像生成中常用的模型也遵循编码器-解码器架构,其中编码器更侧重于学习语言信息,解码器更侧重于利用学习到的信息来限制图像合成。一般来说,最近的工作可以分为两类,基于 GAN 的方法和基于扩散的方法(btw在扩散模型之前基本都是走的gan,vae,gan的工作多的一笔) 。
基于 GAN 的解码器
给定文本编码器
,基于 GAN 的方法结合了鉴别器 和生成器 ,其中生成器 接受由
生成的文本嵌入和噪声向量 以生成输出
,这些输出与真实样本一起输入到鉴别器 分布
[147]。该领域的一个著名模型是 StackGAN [148] 。 StackGAN 架构由两个阶段组成:调节阶段和细化阶段。
在调节阶段,模型将文本描述作为输入并生成低分辨率图像。然后将该图像送入细化阶段,在该阶段进一步细化以生成与文本描述相匹配的高分辨率图像。
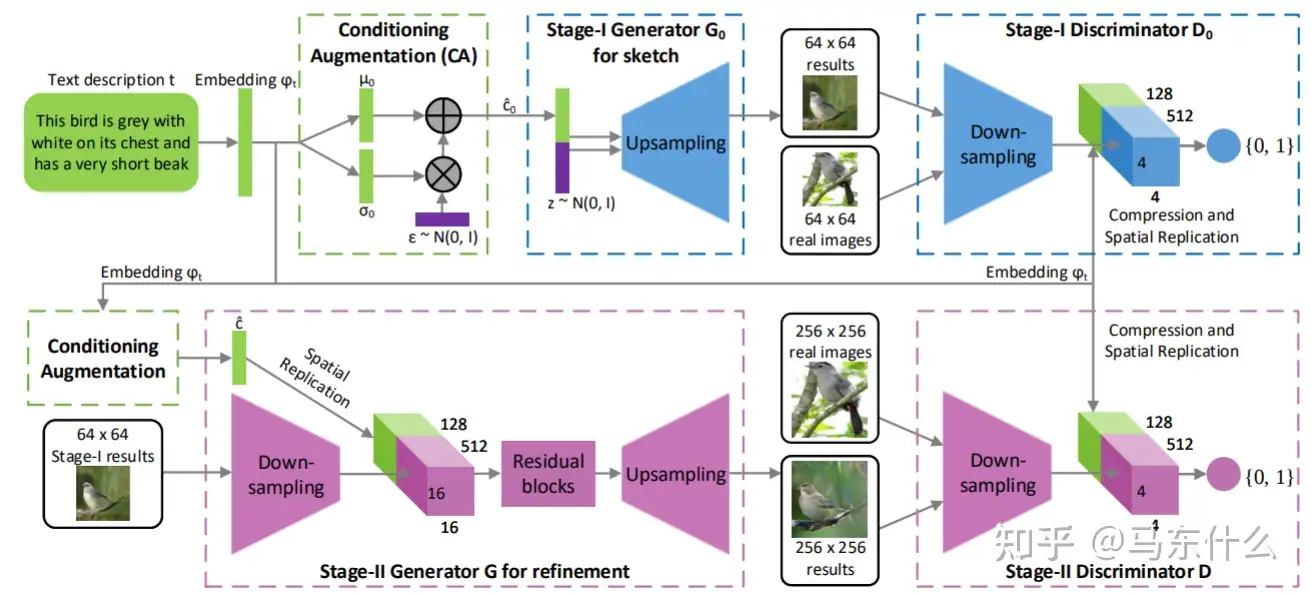
AttnGAN [149] 是另一种基于 StackGAN 架构的文本到图像合成模型。Attngan 在 StackGAN 架构中加入了注意力机制,以进一步提高生成图像的质量。然而,这些模型在指令学习过程中主要使用相对简单的文本编码器,这可能会导致一定的信息丢失。
StyleCLIP [150] 是一种最新的文本到图像合成模型,它使用对比学习来对齐文本和图像特征。它基于 StyleGAN [77] 架构,产生了对以前的文本到图像合成模型(如 StackGAN)的重大进步。StyleCLIP 还遵循编码器-解码器结构,使用文本编码器对指令进行编码,使用图像解码器合成新图像。StyleCLIP 的一项关键创新是它使用对比学习来对齐文本和图像特征。通过训练模型以最大化文本和图像特征之间的相似性,同时最小化不同文本和图像对之间的相似性,StyleCLIP 能够学习文本和图像特征之间更有效的映射,从而产生更高质量的图像合成(这种translation之间的对齐一般都是显式的,sample中image和text是一一对应的)。
基于扩散的解码器
生成图像建模最近在使用扩散模型方面取得了巨大成功。这些模型也已应用于文本到图像的生成。例如,GLIDE [151] 将消融扩散模型 (ADM) 引入到文本到图像的生成中。与之前基于扩散的方法相比,GLIDE 使用具有 3.5B 参数的更大模型和更大的成对数据集,在许多基准测试中取得了更好的结果。与 GLIDE 不同,Imagen [152] 将冻结的 T5 语言模型与超分辨率扩散模型相结合。
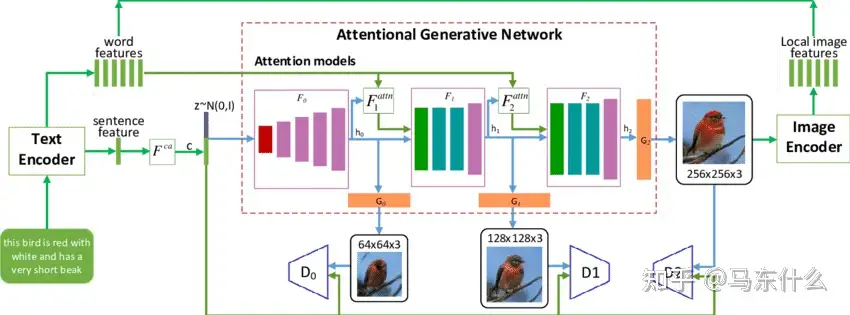
图 11. DALL-E-2 的模型结构。虚线上方是CLIP预训练过程,旨在对齐视觉和语言模态。虚线下方是图像生成过程。文本编码器接受指令并将其编码为表示,然后先验网络和扩散模型解码该表示以生成最终输出。 冻结编码器将对文本指令进行编码并生成嵌入,然后第一个扩散模型将相应地生成低分辨率图像。第二个扩散模型接受带有文本嵌入的图像并输出高分辨率图像。DALL-E-2 [5] 将 CLIP 编码器与扩散解码器相结合,用于图像生成和编辑任务。与 Imagen 相比,DALL-E-2 利用先验网络在文本嵌入和图像嵌入之间进行转换。除了模型设计方面的进步外,这些基于扩散的模型与以前的生成方法之间的另一个主要区别是,这些基于扩散的模型通常在具有更多参数的更大数据集上进行训练,这使得它们有可能学习比其他模型更好的表示。
除了前面提到的方法,还有使用 VAE 作为解码器的作品。例如,Ramesh 等人。提出了 DALL-E [33],这是一种零镜头图像生成器,它利用 dVAE 作为图像编码器和解码器,BPE 作为文本编码器,并在推理过程中使用预训练的 CLIP。
其它
文本音频生成:
近年来,文本-音频多模式处理领域取得了显着增长。该领域的大多数模型要么专注于合成任务,例如语音合成,要么专注于识别任务,例如自动语音识别。它们指的是将书面文本转换为口头语音或将人类语音准确转录为机器可读文本的过程。然而,文本音频生成是一项不同的任务,涉及使用多模式模型创建新颖的音频或文本。虽然相关,但文本音频生成、合成和识别任务在其目标和用于实现这些目标的技术方面有所不同。在这项工作中,我们专注于文本音频生成而不是合成或识别任务。
AdaSpeech [153] 被提议通过在梅尔谱解码器中利用两个声学编码器和条件层归一化,使用有限的语音数据有效地定制高质量的新语音。由于之前的研究在风格转换方面存在局限性,Lombard [154] 利用频谱整形和动态范围压缩 [155] 在存在噪声的情况下生成高度清晰的语音。Cross-lingual generation 是另一项有影响力的跨语言语音传输工作。 [156] 可以产生多种语言的高质量语音,并通过使用音素输入表示和对抗性损失项来跨语言传输语音,从而将说话者身份与语音内容区分开来。
文本音乐生成
[157] 提出了一种针对音频和歌词的深度跨模态相关学习架构,其中模态间典型相关分析用于计算音频和歌词之间时间结构的相似性。为了更好地学习社交媒体内容,JTAV [158] 使用跨模态融合和专注池技术融合了文本、听觉和视觉信息。与 JTAV 不同,[159] 结合了与音乐更相关的多种类型的信息,例如播放列表-曲目交互和流派元数据,并将它们的潜在表示对齐以模拟独特的音乐作品。此外,还有一些工作专注于在给定音频作为输入的情况下生成文本信息,例如描述和字幕。 [160] 提出通过结合音频内容分析和自然语言处理来利用每个曲目的信息来生成音乐播放列表的描述。MusCaps [161] 是一种音乐音频字幕模型,它通过多模式编码器处理音频文本输入并利用音频数据预训练来生成音乐音频内容的描述,以获得有效的音乐特征表示。对于音乐和语言预训练,Manco 等人。 [162] 提出了一种多模式架构,它使用弱对齐文本作为唯一的监督信号来学习通用音乐音频表示。CLAP [163] 是另一种从自然语言监督中学习音频概念的方法,它利用两个编码器和对比学习将音频和文本描述带入联合多模态空间。
文本到graph生成
文本图生成是一个重要的多模态主题,可以在很大程度上释放 NLP 系统的潜力。自然语言文本本质上是模糊的,因为它携带了各种冗余信息,而且逻辑组织也很弱。同时,有利于机器处理结构化、组织良好和压缩形式的内容。知识图谱(KG)是语言处理系统中将语义内部状态之间的关系反映为图结构的结构化意义表示。并且越来越多的作品从文本中提取 KG 以辅助文本生成,这些文本包含跨多个句子的复杂思想。语义解析也可以表述为文本到图形生成的问题。它旨在将自然语言文本转换为逻辑形式,主要是抽象意义表示(AMR)[164],这是一种广泛覆盖的句子级语义表示。与 text-to-KG generation 相比,它强调提供机器可解释的表示而不是构建语义网络。相反,KG-to-text generation 旨在基于已构建的 KG 生成流畅且逻辑连贯的文本。除了 NLP 领域,文本图形生成也可以推动计算机辅助药物设计的发展。有新兴的工作将高度结构化的分子图与语言描述联系起来,这有助于人类理解深刻的分子知识和新分子探索。下面,我们简要概述这四个主题中的一些代表作品。
文本到knowledge graph的生成
李等。 [165] 将文本到 KG 的构建视为知识图谱完成(KGC)的过程,其中缺失的术语逐渐被推理覆盖。采用双线性模型和另一个基于 DNN 的模型来嵌入项并计算任意元组的分数以进行加法运算。KG-BERT [166] 利用预训练语言模型的力量在 KGC 期间捕获更多上下文信息。这个想法是通过微调的 BERT 模型将三元组表示为文本序列,并将图补全模型表示为序列分类问题。马拉维亚等。 [167] 提出了一种结合图卷积网络(GCN)的方法来提取更多的结构和语义上下文。它还通过引入图形扩充和渐进屏蔽策略来解决图形稀疏性和可扩展性问题。或者,另一行作品 [168-170] 直接查询预训练的语言模型以获得语义知识网络。具体来说,语言模型被反复提示以预测完形填空句中的掩码项,以获取相关知识。CycleGT [171] 是一种无监督方法,允许 text-KG 双向翻译。采用无监督循环训练策略提供自我监督,使整个训练过程可以使用非平行文本和图形数据。利用类似的策略,DualTKB [172] 进一步证明,即使在弱监督环境下,模型性能也可以大大提高。卢等人。[173] 提出了一个统一的文本到图形框架,它包含了大多数信息提取任务。同时,预定义模式的使用可能会限制其对节点和边的不同文本形式的泛化。Grapher [174] 通过在两个独立的阶段生成节点和边来有效地执行端到端文本到 KG 的构建。具体来说,预训练的语言模型首先使用实体提取任务进行微调以生成节点。随后,引入焦点损失和稀疏邻接矩阵来解决边缘构建过程中的偏斜边缘分布问题。
知识图到文本生成
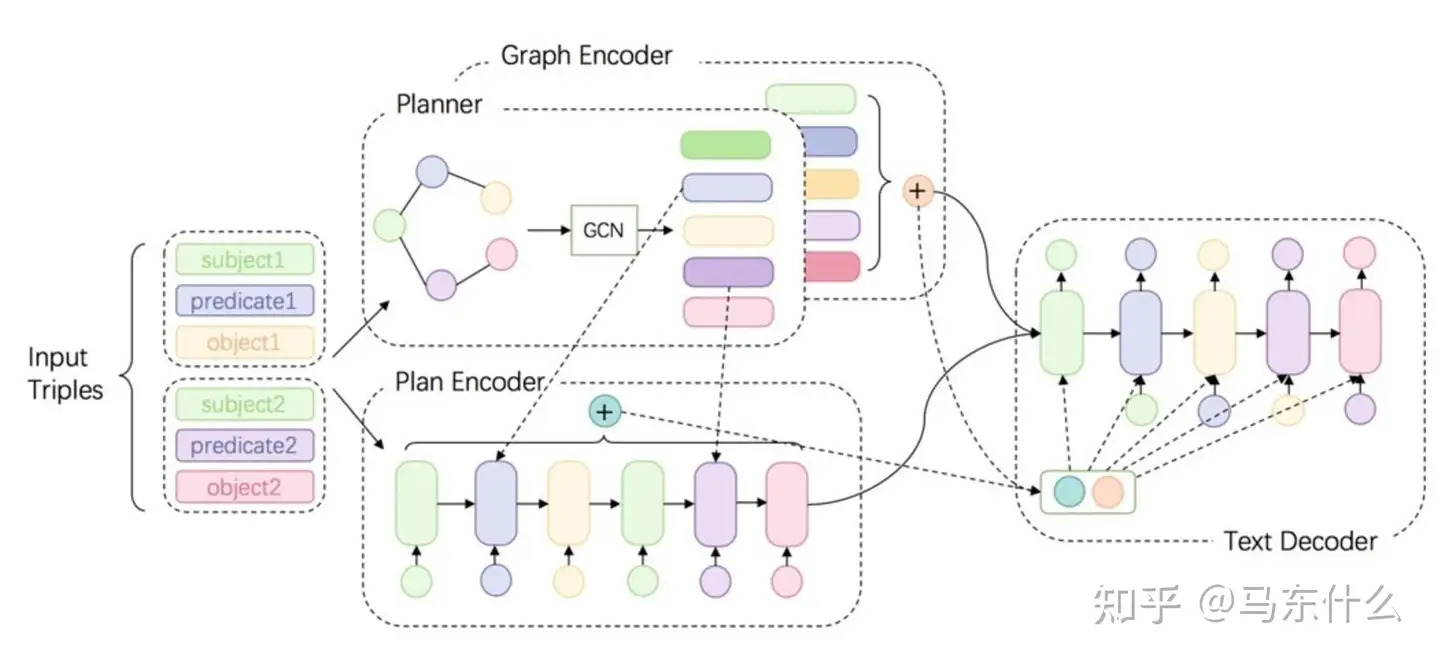
GTR-LSTM [176] 是一个序列到序列的编码器解码器框架,它从线性化的 KG 三元组生成文本。它可以处理 KG 中的循环以捕获全局信息。同时,其线性化图的性质仍然会导致相当大的结构信息丢失,尤其是对于大型图。为了解决这个问题,Song 等人。 [177] 使用图状态 LSTM 对图语义进行编码,该图状态 LSTM 可以在一系列状态转换期间在节点之间传播信息。它被证明能够对节点之间的非本地交互进行建模,同时由于高度并行化也很高效。赵等。[175] 提出 DUALENC,一种双编码模型,以弥合输入图和输出文本之间的结构差异。具体来说,它利用基于 GCN 的图形编码器来提取结构信息,同时还采用神经规划器来创建图形的顺序内容计划,以生成线性输出文本。或者,Koncel-Kedziorski 等人。 [178] 使用从图形注意力网络 (GAT) [179] 扩展而来的基于转换器的架构对文本生成的图形结构进行编码。这个想法是通过使用自我注意机制遍历其局部邻域来计算 KG 的节点表示。相反,Ribeiro 等人。 [180] 专注于联合利用局部和全局节点编码策略从图形上下文中捕获补充信息。HetGT [181] 改编自 transformer,旨在独立地对图中的不同关系进行建模,以避免通过简单地混合它们来避免信息丢失。输入图首先被转化为异构Levi图,然后根据每个部分的异构性拆分成子图,用于未来的信息聚合。
语义解析
早期作品 [182、183] 将语义解析表述为序列到序列生成问题。然而,AMR 本质上是一个结构化对象。序列到序列问题设置只能捕获浅层词序列信息,同时可能忽略丰富的句法和语义信息。吕等。 [184] 通过将 AMR 表示为根标记的有向无环图 (DAG),将语义解析建模为图预测问题。这将需要图中的节点与句子中的单词之间的对齐。提出了一种将对齐视为联合概率模型中的潜在变量的神经解析器,用于 AMR 解析期间的节点对齐和边缘预测。陈等。 [185] 通过神经序列到动作 RNN 模型构建具有动作集的语义图。通过在解码过程中整合结构和语义约束来加强解析过程。张等。 [186] 通过基于无对准器注意力的模型解决 AMR 解析中的重入属性出现的问题,该模型将问题表述为序列到图的转换。利用指针生成器网络,证明可以使用有限的标记 AMR 数据有效地训练模型。Fancellu 等人。 [187] 提出了一种图感知顺序模型来构建用于 AMR 图预测的线性化图。在没有潜在变量的情况下,它可以确保每个格式正确的字符串仅与一种新颖的图形感知字符串重写策略的一个派生配对。
文本分子生成
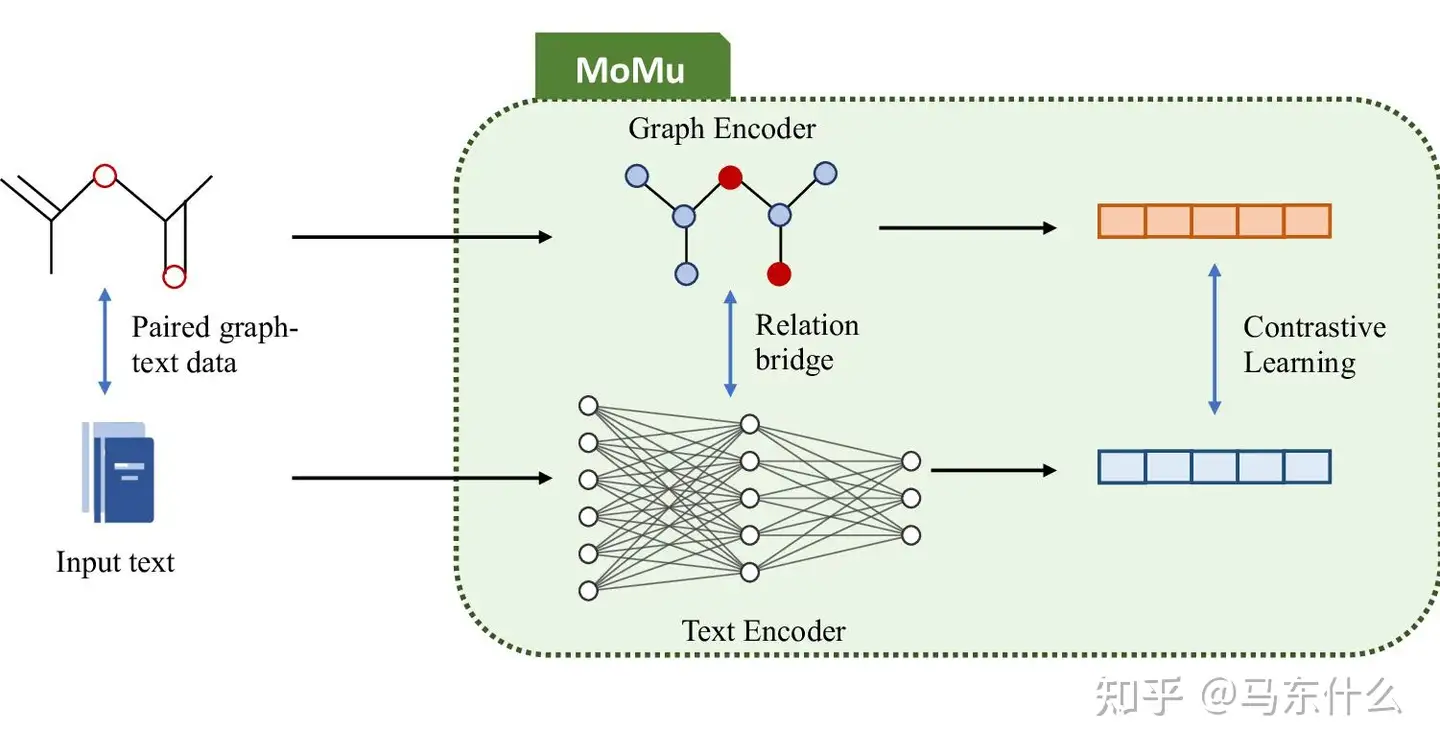
Text2Mol [189] 是一种跨模态信息检索系统,用于检索基于语言描述的分子图。基于 BERT 的文本编码器和 MLP-GCN 组合分子编码器用于在语义空间中创建多模态嵌入,通过对比学习与配对数据对齐。MolT5 [190] 没有从现有分子中检索,而是提出了一个自我监督的学习框架,用于文本条件从头分子生成和分子字幕。它通过预训练和微调策略解决了跨模态数据对的稀缺性。具体来说,它使用去噪目标在未配对的文本和分子字符串上预训练模型,然后使用有限的配对数据进行微调。然而,受其线性化图形性质的限制,分子的基于字符串的表示不是唯一的并且可能导致结构信息丢失。为了解决这个问题,MoMu [188] 引入了一个基于图的多模态框架,该框架通过对比学习联合训练两个独立的编码器,以与弱配对的跨模态数据进行语义空间对齐。除了从头分子图生成之外,它还可以适应各种下游任务。
文本代码生成
文本代码生成旨在从自然语言描述中自动生成有效的程序代码或提供编码辅助。LLM 最近在从自然语言 (NL) 描述生成编程语言 (PL) 代码方面展现出巨大潜力。早期的作品直接将文本代码生成制定为纯语言生成任务。然而,NL 和 PL 是具有固有不同模态的数据类型,在语义空间对齐期间,额外的策略对于捕获 NL 和 PL 之间的相互依赖性至关重要。与 NL 数据相比,PL 数据还封装了丰富的结构信息和不同的语法,这使得从 PL 上下文中理解语义信息更具挑战性。此外,文本代码模型也应该是多语言的,因为它们可以提供更好的泛化能力。下面主要介绍以自然语言描述为条件的代码生成模型。我们还审查了其他基于语言的编码辅助模型。
文本条件编程代码生成
CodeBERT [191] 是一种基于双峰 Transformer 的预训练文本代码模型,可以捕获 NL 和 PL 之间的语义联系。它采用混合目标函数,利用二项式 NL-PL 配对数据进行模型训练,单峰 PL 代码数据分别用于学习更好的生成器,以在语义空间中对齐 NL 和 PL。该模型进一步在六种多语言 PL 上进行了预训练,以实现更好的泛化。CuBERT [192] 与 CodeBERT 具有相似的模型架构,同时它不需要在函数的自然语言描述与其主体之间执行句子分离以进行句子对表示。CodeT5 [193] 提出了一种预训练的编码器-解码器 Transformer 模型,它可以更好地从代码中捕获上下文语义信息。具体来说,它引入了新颖的标识符感知预训练任务,通过从代码令牌中区分标识符并在屏蔽时恢复它们来保留关键令牌类型信息。PLBART [194] 将双峰文本代码模型从生成任务扩展到更广泛的判别任务类别,例如统一框架下的克隆和漏洞代码检测。另一行作品 [195、196] 引入了程序图的概念 [197] 以显式建模 PL 代码底层的结构以协助生成。程序图被构造为抽象语法树 (AST),以封装来自程序特定语义和语法的知识。
交互式编程系统
由于 NL 的内在歧义,文本代码生成受到编程代码生成的棘手搜索空间和用户意图的不当规范的共同挑战。CODEGEN [198] 提出了一种多轮程序合成方法,该方法将以单个复杂的 NL 规范为条件的程序合成分解为由一系列用户意图控制的渐进生成。它以自回归变换器的形式构建,学习给定先前标记的下一个标记的条件分布,并在 PL 和 NL 数据上进行训练。TDUIF [199] 通过形式化用户意图和提供更易于理解的用户反馈来扩展交互式编程框架。它进一步实现了可扩展的自动算法评估,不需要用户在循环中,具有高保真用户交互建模。
AIGC的应用
聊天机器人
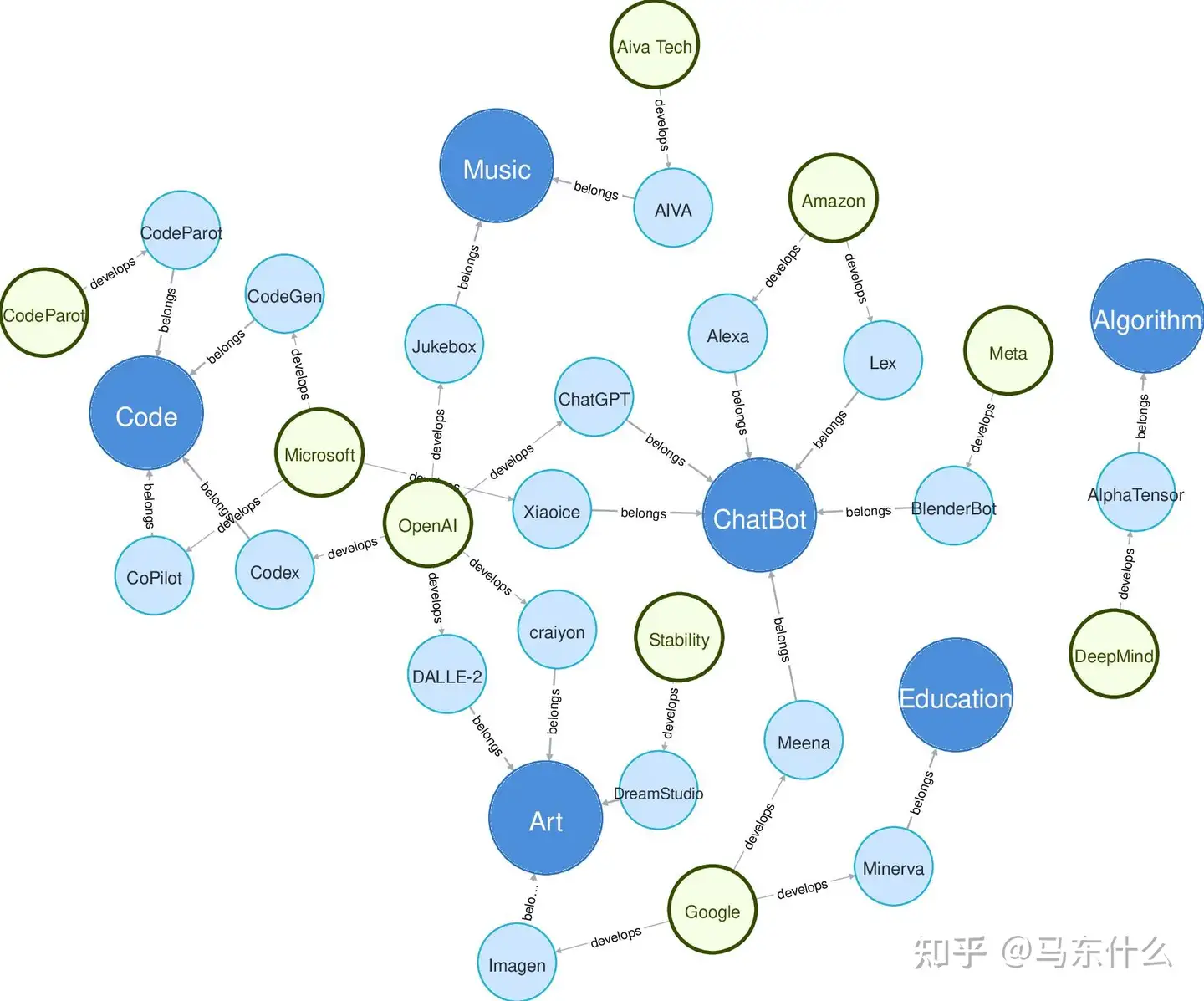
聊天机器人是一种计算机程序,旨在通过基于文本的界面模拟与人类用户的对话。聊天机器人通常使用语言模型以对话方式理解和响应用户查询和输入。它们可以被编程来执行范围广泛的任务,例如,提供客户支持和回答常见问题。图14.当前研究领域、应用与相关公司的关系图,其中深蓝色圆圈代表研究领域,浅蓝色圆圈代表应用,绿色圆圈代表公司。
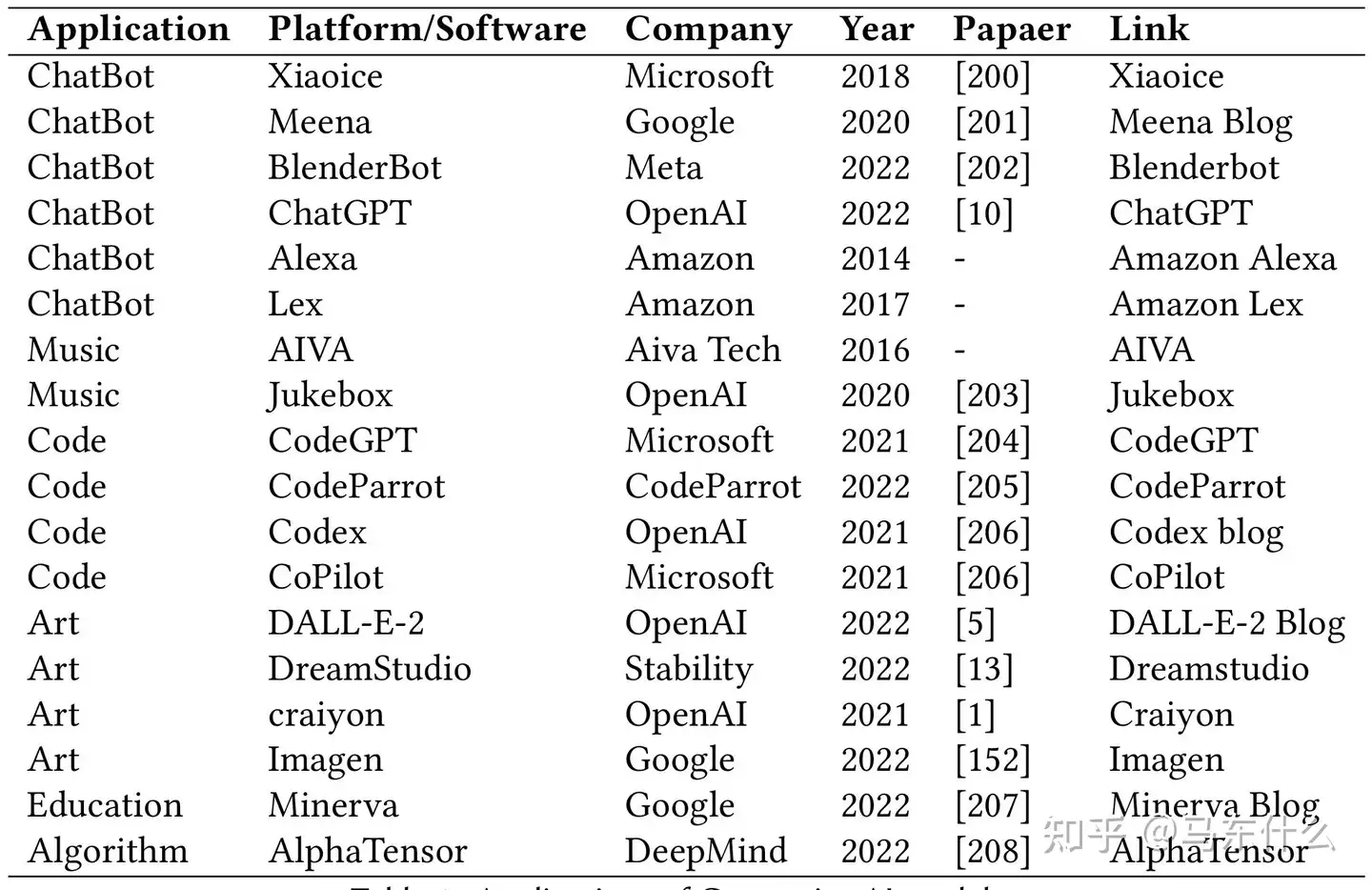
最突出的例子是Xiaoice[200]。 XiaoIce 由 Microsoft 的一组研究人员和工程师开发,使用了自然语言处理、机器学习和知识表示方面的最先进技术。Xiaoice的一个重要特征是它能够表达同理心,这是通过使用情感分析方法实现的,让小冰像人一样表现。2020 年,谷歌提出了 Meena [201],这是一个在社交媒体对话上训练的多轮开放域聊天机器人,它实现了最先进的交互式 SSA 分数和困惑度。最近,微软发布了他们最新版本的 Bing,其中包含 ChatGPT,使用户能够提出开放域或条件问题并通过对话获得结果。这为未来聊天机器人的发展提供了新的可能性。
艺术画
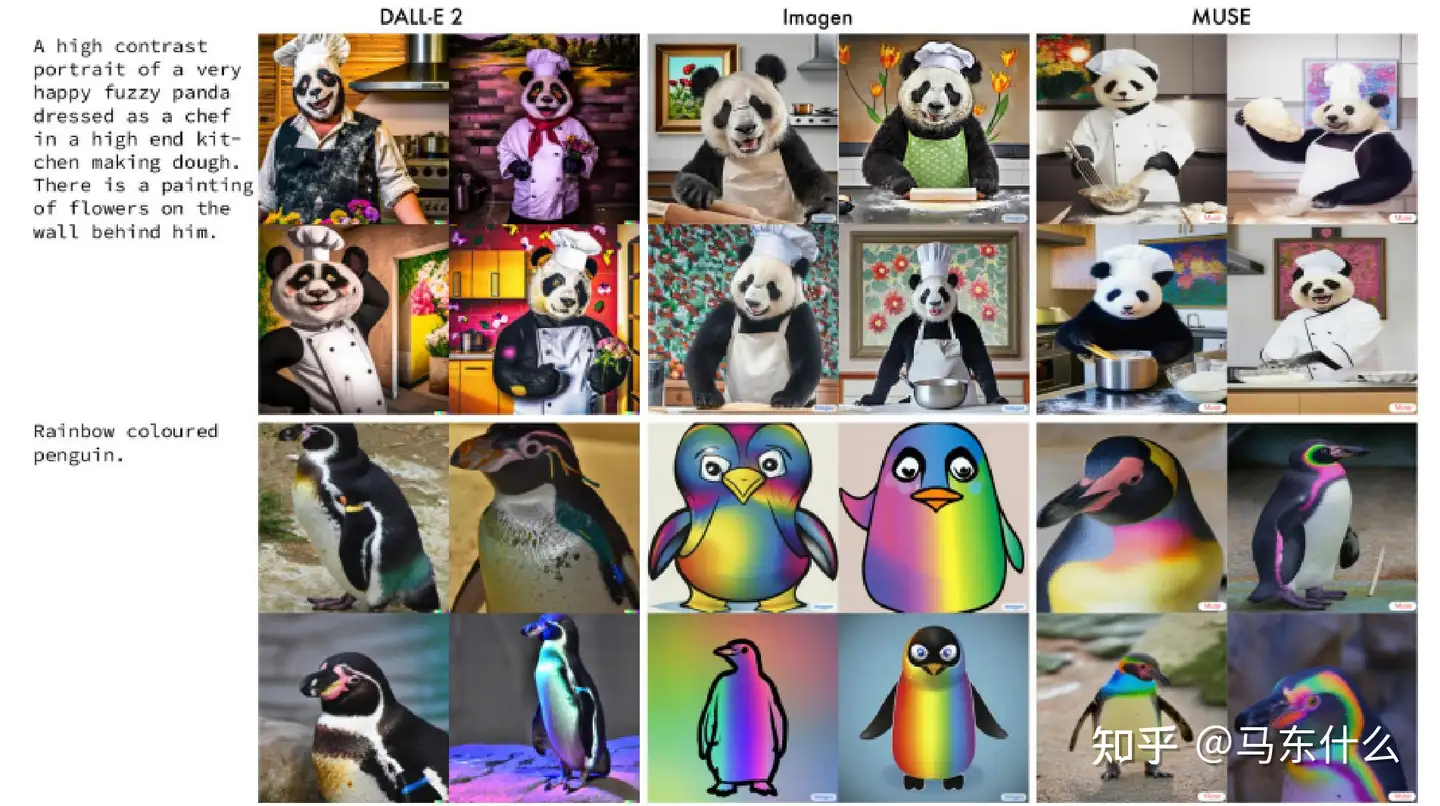
人工智能艺术生成是指使用计算机算法来创作原创艺术作品。这些算法在现有艺术品的大型数据集上进行训练,并使用机器学习技术生成模仿著名艺术家的风格和技巧或探索新艺术风格的新作品。随着基于扩散的模型的快速发展,越来越多的公司推出了他们的艺术生成产品。该领域最显着的进步之一是由 OpenAI 推出的 DALL-E 系列。DALL-E [1],即现在的 Craiyon,最初是在 VQ-VAE 和 CLIP 上构建的,然后diffusion也应用到这个产品上,成为 DALL-E2 [5]。DreamStudio [13] 由 Stability.ai 创建 ,是一种文本到图像生成服务,它利用stable diffusion根据给定的短语或句子生成图像。该技术提供与 DALL-E-2 相当的性能,但处理速度更快,使其成为许多用户的热门选择。由 Google 开发的 Imagen [152] 在其图像编辑和生成服务中使用diffusion。在一篇博客文章中,谷歌报告说他们与人类评分者进行了一项研究,以评估人工智能生成的图像的质量。结果表明,Imagen 在并排比较中优于其他模型,人类评分者更喜欢样本质量和图像文本对齐方面的评分更高。
音乐
深度音乐生成是指利用深度学习技术和人工智能算法生成新颖原创的音乐作品。一个突出的方法是以钢琴卷的形式产生音乐的象征性表示。这种方法需要为每个要演奏的音符指定时间、音高、速度和乐器。AIVA 4 是最著名的例子之一,由 Aiva Technologies 于 2016 年开发。它可以生成多种风格的音乐片段,包括电子、流行、爵士等,并且可以在各种环境中使用。作为全球首位被交响乐组织认可的人工智能作曲家,AIVA获得了SACEM音乐学会作曲家的全球地位。 OpenAI 在 2020 年开发了 Jukebox [203]。它在原始音频领域以不同的流派和艺术风格生成带有歌声的音乐。Jukebox 在音乐质量、连贯性、音频样本持续时间以及受艺术家、流派和歌词影响的能力方面被认为是一个飞跃。
代码
基于人工智能的编程系统通常旨在完成代码完成、源代码到伪代码映射、程序修复、API 序列预测、用户反馈和自然语言到代码生成等任务。最近,强大的 LLM 的出现将基于 AI 的编程的边界向前推进了一大步。CodeGPT [204] 是由 OpenAI 开发的开源代码生成模型,它与 GPT 系列中的许多其他模型一样遵循 transformer 架构。它可以针对各种代码生成任务进行微调,例如代码补全、摘要或基于大量源代码数据的翻译。CodeParrot [205] 是一个编程学习平台,在编码过程中为用户提供个性化的反馈和帮助。以渐进式人机交互的方式设计了各种交互练习和编程挑战。一个独特的功能是脚手架策略,它将复杂的任务拆分为更小且易于管理的步骤,以帮助学生逐渐建立他们的编码技能。与大多数以前的模型相比,Codex [206] 在更大、更多样化的数据集上进行了训练,这是向前迈出的重要一步。具体来说,它旨在从头开始生成完整的编码程序,而 CodeGPT 只能生成完成给定提示的代码片段。它还享有适应多种编程语言的好处,可以提供更好的灵活性和通用性。
教育
AIGC 有可能通过利用多模态数据(例如教程视频、学术论文和其他高质量信息)在教育方面取得重大进展,从而改善个性化教育体验。在学术方面,Google Research 引入了 Minerva [207],它建立在 PaLM 通用语言模型 [209] 和一个额外的以科学和数学为中心的数据集之上,以解决大学水平的多步定量任务,涵盖代数,概率论、物理学、数论、初等微积分、几何学、生物学、电气工程、化学、天文学和机器学习。例如,它可以给出证明任何
不等式
的分步细节,它还可以在其他三种选择(包括钠、铬和铝)中正确识别镅作为放射性元素。正如博客 5 中所述,Minerva 通过组合技术在推理任务上实现了最先进的性能,包括少量提示、思维链或便签本提示以及多数表决。虽然 Minerva 的表现仍然低于人类表现,但随着不断改进和未来的进步,AIGC 可以提供负担得起的个性化数学导师。商用方面,巧匠教育科技宣布将开发一款基于AIGC的自动课程、AI导师、在线教育自适应学习的班级机器人产品,预计2023年第四季度出货。
AIGC 的效率
在过去的十年中,具有神经网络的深度生成 AI 模型一直主导着机器学习领域,其兴起归功于 2012 年的 ImageNet 竞赛 [210],这导致了一场创建更深、更复杂模型的竞赛。在自然语言理解中也可以看到这种趋势,其中开发了具有大量参数的模型,例如 BERT 和 GPT-3。然而,不断增加的模型占用空间和复杂性,以及训练和部署所需的成本和资源,对现实世界中的实际部署提出了挑战。核心挑战是效率,可以分解如下:
(1)推断的效率:这涉及到在实际应用中部署模型进行推理的问题,即计算模型在给定输入下的输出。推理效率主要与模型的大小、速度和资源消耗(例如,磁盘和内存使用)有关。
(2)训练的效率:这包括影响模型训练速度和资源需求的因素,例如训练时间、内存占用以及在多个设备上的可扩展性。它还可能包括关于在特定任务上实现最佳性能所需数据量的考虑。
Prompt Learning(提示学习)
Prompt learning 是近年来在预训练大型语言模型的背景下提出的一个相对较新的概念。以前,要对给定的输入 进行预测 ,传统监督学习的目标是找到一个预测概率
的语言模型。通过快速学习,目标变成了找到一个模板
直接预测概率
[211]。因此,使用语言模型的目标变成了通过提供指定要完成的任务的提示来鼓励预训练模型进行预测。通常,prompt learning会冻结语言模型,直接对其进行few-shot或zeroshot学习。这使得语言模型能够在大量原始文本数据上进行预训练,并适应新的领域而无需再次调整。因此, Prompt Learning可以帮助节省大量时间和精力 。
Traditional Prompt Learning
利用语言模型进行提示学习的过程可以分为两个主要阶段:prompt engineering和answer engineering。
Prompt engineering :一般来说,常用的提示工程有两种形式:离散提示和连续提示。离散提示通常由人类为特定任务手动设计,而连续提示被添加到输入嵌入中以传达特定于任务的信息。
Answer engineering :重新制定任务后,语言模型根据提供的提示生成的答案需要映射到ground truth空间。Answer engineering有不同的范式,包括离散搜索空间和连续搜索空间。由于该主题与分类任务更密切相关,我们建议感兴趣的读者自己去看相关的综述了解更多信息。
除了单提示学习法外,还有多提示法。这些方法主要侧重于在推理过程中将多个提示组合在一起作为输入以提高预测的鲁棒性,这比依赖单个提示更有效。多提示学习的另一种方法是提示增强,旨在通过提供已经回答的额外提示来帮助模型回答问题。
In-context Learning
最近,In-context Learning作为提高语言模型性能的有效方法受到了广泛关注。这种方法是提示学习的一个子集,涉及使用预训练的语言模型作为主干,以及向提示添加一些输入标签演示对和说明。上下文学习已被证明在指导语言模型产生更好的答案方面非常有效,这些答案更符合给定的提示 。最近的一些研究还表明,上下文学习可以被视为一种隐式微调形式,因为它使模型能够学习如何根据输入提示更准确地生成答案。
预训练基础模型的效率
在 AIGC 框架的背景下,每个提议方法的基本组成部分都涉及利用大型预训练基础模型 (PFM) [212]。PFM,如 BERT [42]、GPT2 [62] 和 RoBERTa [43],通过在广泛的 NLP 任务上取得最先进的结果,彻底改变了自然语言处理领域。然而,这些模型非常大且计算量大,可能导致效率问题。当使用有限的计算资源工作时尤其如此,例如在个人计算机上或在处理能力有限的云环境中。为了解决这些效率问题,最近的许多工作都致力于探索更具成本效益的预训练方法来预训练大规模 PFM。学习算法的有效性取决于训练方法和模型架构效率。例如,ELECTRA [213] 引入了一个 RTD 任务来预测每个输入标记是否被其他标记替换,从而使 ELECTRA 能够针对所有输入标记进行训练。除了有效的训练方法外,模型架构效率也有助于提高 PFM 效率。通过降低 Transformer 算法的复杂性,大多数基于 Transformer 算法的 PFM 可能会受益于更高效的模型架构。
Model Compression
模型压缩是减小模型尺寸和提高计算效率的有效途径。它需要更少的计算资源和内存,比原始模型更能满足各种应用的需求,其策略可分为两类:参数压缩和结构压缩。参数压缩方法包括参数剪枝、参数量化、低秩分解和参数共享。参数剪枝基于相当大的 PFM 删除冗余参数,而参数量化将模型参数减少到低阶数,而不会对模型性能产生显着影响。低秩分解降低了高维参数向量的维数,参数共享映射模型参数以减少它们的数量。结构压缩是指设计新的紧凑网络结构并采用知识蒸馏,其中通过软标签等技术将从较大的教师模型中学到的知识转移到较小的学生模型中。例如,DistilBERT [214] 使用知识蒸馏来压缩 BERT,将其大小减小 40%,同时保持其 97% 的语言理解能力。ALBERT 使用分解嵌入参数化和跨层参数共享来减少模型参数的数量。
虽然 AIGC 有可能在许多不同的应用程序中非常有用,但它也引发了对安全和隐私的重大担忧。在本节中,我们将讨论揭示 AIGC“黑暗”面的研究以及为确保 AIGC 能够以安全和负责任的方式使用而提出的对策。
安全/隐私
pass 不感兴趣
未解决的问题和未来的方向
高风险应用程序。尽管社区见证了 AIGC 在图像、文本和音频生成方面的巨大成功,但这些领域可以说具有更高的容错性。相反,用于高风险应用的 AIGC,包括医疗保健 [248]、金融服务 [249]、自动驾驶汽车 [250] 和科学发现 [251],仍然具有挑战性。在这些领域中,任务是关键任务,需要高度的准确性、可靠性、透明度以及更少或接近零的容错能力。例如,用于自动组织科学的大型语言模型 Galactica [252] 可以执行知识密集型科学任务,并且在多个基准任务上具有良好的性能。由于以权威的口吻对其产生的有偏见和不正确的结果进行了强烈批评,其公开演示在首次发布后仅三天就被从该服务中删除。对于这些高风险应用程序中的生成模型来说,提供置信度分数、推理和源信息以及生成的结果至关重要。只有当专业人员了解这些结果的来源和来源时,他们才能自信地在他们的任务中使用这些工具。
专业化和泛化。 AIGC 依赖于基础模型的选择,这些模型在不同的数据集上进行训练,包括基于爬网的 [37] 和精心策划的 [252]。[230] 中指出,“在更多样化的数据集上进行训练并不总是比更专业的基础模型对下游性能更好。”然而,高度专业化的数据集的管理可能既耗时又不划算。更好地理解跨域表示以及它们如何适应测试时间分布变化可能会指导设计训练数据集以平衡专业化和泛化。
Continual Learning and Retraining 人类知识库不断扩大,新任务不断涌现。要生成具有最新信息的内容,不仅需要模型“记住”所学知识,还需要能够从新获取的信息中进行学习和推理。对于某些场景[253],在保持预训练基础模型不变的情况下,对下游任务进行持续学习就足够了。必要时 [254],可以对基础模型进行持续学习。然而,也有人观察到,持续学习可能并不总是优于重新训练的模型 [255]。这就需要了解何时应该选择持续学习策略以及何时选择再培训策略。此外,从头开始训练基础模型可能会让人望而却步,因此 AIGC 下一代基础模型的模块化设计可能会阐明模型的哪些部分应该重新训练。
Reasoning 推理是人类智能的重要组成部分,它使我们能够得出推论、做出决定和解决复杂问题。然而,即使使用大规模数据集进行训练,有时 GAI 模型在常识推理任务中仍然会失败 [256、257]。最近,越来越多的研究人员开始关注这个问题。思想链 (CoT) 提示 [256] 是一种很有前途的解决方案,可以应对生成式 AI 模型中的推理挑战。它旨在增强大型语言模型在问答上下文中学习逻辑推理的能力。通过解释人类用来得出模型答案的逻辑推理过程,他们可以遵循与人类处理推理相同的道路。通过采用这种方法,大型语言模型可以在需要逻辑推理的任务中实现更高的准确性和更好的性能。CoT 还应用于其他领域,如视觉语言问答 [257] 和代码生成 [258]。然而,如何根据特定任务构建这些CoT提示仍然是一个问题。
Scaling up 放大一直是大规模预训练中的一个常见问题。模型训练总是受到计算预算、可用数据集和模型大小的限制。随着预训练模型规模的增加,训练所需的时间和资源也显着增加。这对寻求利用大规模预训练来完成自然语言理解、计算机视觉和语音识别等各种任务的研究人员和组织提出了挑战。
另一个问题与使用大规模数据集进行预训练的效果有关,如果模型大小和数据量等实验超参数设计不当,可能无法产生最佳结果。因此,次优的超参数可能会导致浪费资源消耗,并且无法通过进一步的训练获得预期的结果。已经提出了几项工作来解决这些问题。霍夫曼等人。 [259] 引入了一个正式的比例定律来根据参数的数量和数据集的大小来预测模型的性能。这项工作为了解扩大规模时这些关键因素之间的关系提供了一个有用的框架。Aghajanyan 等人。 [260] 进行实证分析以验证霍夫曼比例定律,并提出一个额外的公式来探索多模态模型训练设置中不同训练任务之间的关系。这些发现为大规模模型训练的复杂性以及跨不同训练领域优化性能的细微差别提供了宝贵的见解。