
CVPR 2020 | 3D Photography:一张照片也能动起来
https://arxiv.org/abs/2004.04727
3D 相片是这两年比较热门的研究方向,Facebook App 已经支持分享 3D 相片,相信在不久的未来大家便可以在朋友圈、微博上分享炫酷的 3D 相片。

本文作者来自弗吉尼亚理工学院、国立清华大学和 Facebook,作者提出了一种从 单张 RGB-D 图像生成 3D 照相 的方法,效果炫酷、惊艳,目前代码已开源。
下面先展示一下本文的一些结果,镜头晃动、zoom-in 效果,毫无违和感。
人物、动物各种场景全都不在话下,一张照片也能立刻动起来!
3D相片的生成主要基于重建和渲染技术,传统的方法需要基线较长的精密的多视角图片捕捉设备或者其他特殊装置,如 Lytro Immerge 和 Facebook Manifold camera。最近有更多的工作尝试从智能相机来生成3D相片,如 Facebook 3D Photos 只需用双摄智能手机拍摄图片,生成RGB-D图像 (彩色图+深度图) 来制作3D相片。
本文同样考虑如何从输入的 RGB-D 图像来合成新的视角以生成3D照片。文章方法对深度图的质量要求并不高,只需要深度不连续处在彩色图和深度图中是合理对齐的即可。深度图可以从 双摄相机通过立体视觉的方式计算 得到,也可以借助 深度学习的方法从单张图片估计 得到,因此应用到智能手机完全没有问题,作者也对这两种来源的深度图进行了测试。
Method
Layered Depth Image
文章方法输入一张 RGB-D 图像,输出分层的深度图像 (Layered Depth Image, LDI),在原始图像中被遮挡的部位填补了颜色和深度。
LDI 类似普通的图像,区别在于每个像素点可以容纳零个或多个像素值,每个 LDI 像素存储一个颜色和一个深度值。与原始论文介绍的 LDI 不同,本文作者显式地表示了像素的局部连通性:每个像素在左右上下四个方向上都存储了零个或最多一个直接相邻的像素指针。LDI 像素与普通图像一样在光滑区域内是四连通的,但是在深度不连续处没有邻接像素。
LDI 是一种对3D相片非常有用的表达,主要在三个方面
- 其可以处理任意数量的深度层,可以根据需要适应深度复杂的情况;
- 其表达是稀疏的,具有更高的内存和存储效率;
- 其可以转换为轻量级的纹理网格表示,直接用于快速渲染。
Method Overview
给定输入的 RGB-D 图像,首先初始化一个单层的四连通的简单 LDI。然后进入预处理阶段,检测深度不连续像素点,并将其分组成简单的相连的深度边。文章算法反复选择深度边来进行修复,先断开边缘上的 LDI 像素,仅考虑边缘处的背景像素进行修复,从边缘的 “已知” 侧提取局部语境区域 (context region),并在 “未知” 侧生成一个合成区域 (synthesis region),合成的区域是一个包含新像素的连续2D区域。作者使用基于学习的方法根据给定的上下文生成其颜色和深度值。修复完成后再将合成的像素合并回 LDI。整个方法以这种方式反复进行,直到所有的深度边缘都经过处理。
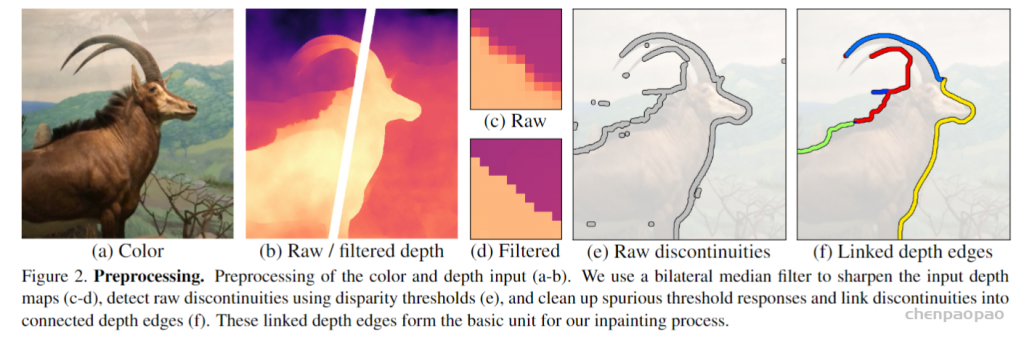
Image Preprocessing
初始化阶段首先将输入的 RGB-D 图的深度通道归一化到 0-1 之间,并对深度图进行双边中值滤波,以使得边缘更加明显,再基于此图片生成初始 LDI。然后再根据给定阈值判断相邻像素的视差,找到深度不连续像素,并经过一些简化、处理得到最终的深度不连续边。
Context and Synthesis Regions
接下来每次选择一条深度边借助填补算法来修复背景,首先在深度不连续处断开 LDI 像素连接,得到 (前景、背景) 轮廓像素,然后生成一个合成区域,使用洪水漫淹算法初始化颜色和深度值,再使用深度学习的方法填补该合成区域。

Context-aware Color and Depth Inpainting
给定语境区域和合成区域,这里的目标是合成颜色值和深度值。作者的网络与 EdgeConnect[2] 方法类似,将整个修复任务分解成三个子网络:
- 边修复网络 (edge inpainting network)
- 颜色修复网络 (color inpainting network)
- 深度修复网络 (depth inpainting network)

首先将语境区域的边作为输入,使用边修复网络预测合成区域中的深度边,先预测边信息能够推断 (基于边的) 结构 信息,有助于约束 (颜色和深度的) 内容 预测。然后使用修复的边和语境区域的颜色作为输入,使用颜色修复网络预测颜色。最后再使用同样的方法预测深度信息。
下图展示了边指导的深度修复能够准确地延拓深度结构,并能减轻预测的彩色 / 深度不对齐的问题。

Converting to 3D Textured Mesh
通过将所有修复好的颜色和深度值重新集成到原始 LDI 中,形成最终的 3D 纹理网格。使用网格表示可以快速渲染新的视图,而无需对每个视角进行推理,因此文章算法得到的3D表示可以在边缘设备上通过标准图形引擎轻松渲染。
Experimental Results
Visual Comparisons
下图展示了文章方法与其他基于 MPI (Multi-Plane Representation) 方法的对比,文章方法能够合成较为合理的边缘结构,StereoMag 和 PB-MPI 方法在深度不连续处存在缺陷,LLFF 在生成新视角时会有鬼影现象。

作者将文章方法与 Facebook 3D Photos 进行了比较。通过 iPhone X 采集的彩色图和估计的深度图作为两种方法的输入,下图是部分对比结果展示,文章方法能够合成更为合理的内容和结构信息。

代码测试
参考官方GitHub仓库,步骤如下
# 创建pytorch虚拟环境
# 下载代码
git clone https://github.com/vt-vl-lab/3d-photo-inpainting.git
cd 3d-photo-inpainting
./download.sh # 下载预训练模型
(pytorch) $ python main.py --config argument.yml # 运行代码参考
- 3D Photography using Context-aware Layered Depth Inpainting. Meng-Li Shih, Shih-Yang Su, Johannes Kopf, Jia-Bin Huang. CVPR, 2020.
- EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning. Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi. ICCV, 2019.