

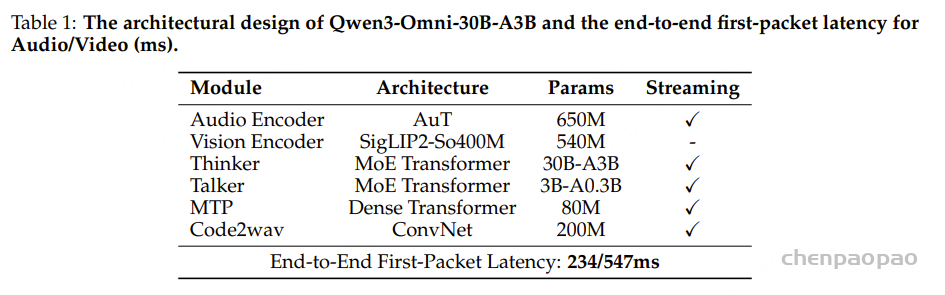
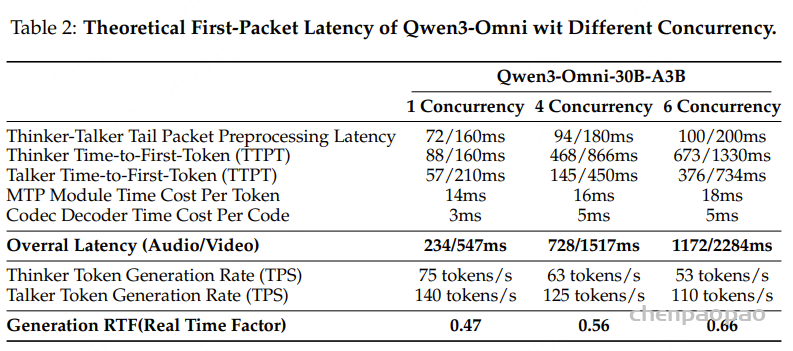
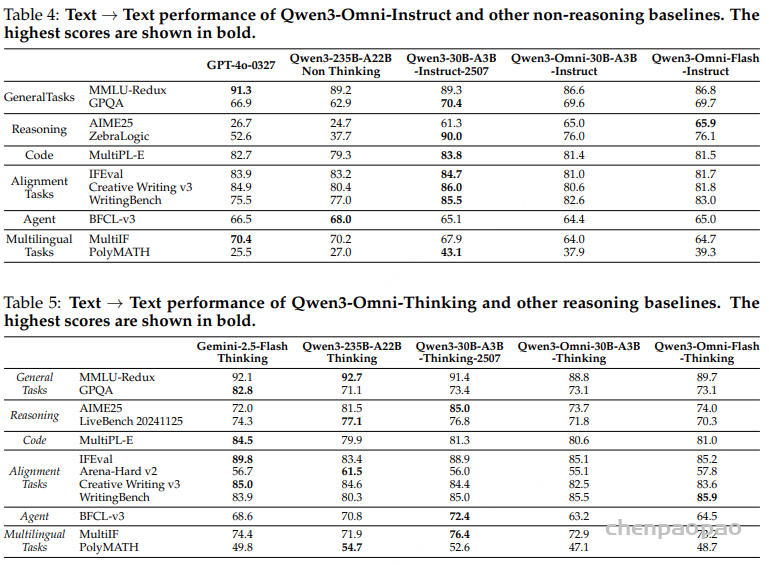
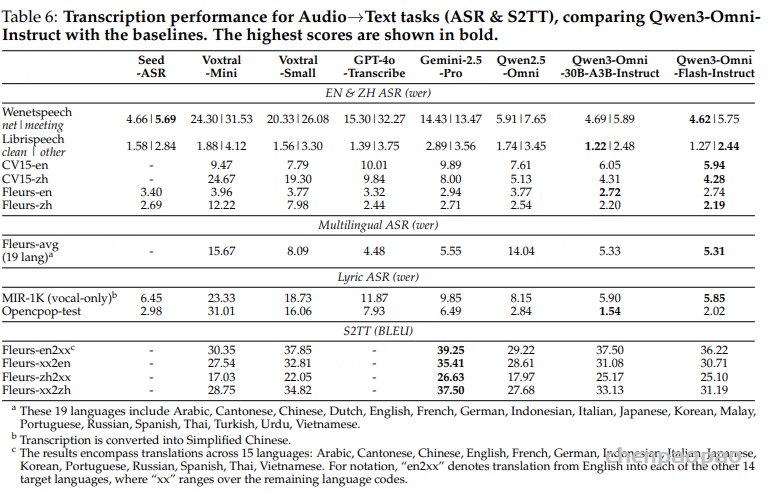
- 论文链接: https://arxiv.org/pdf/2601.11027
- Demo Page: https://hujingbin1.github.io/WenetSpeechWu-Demo-Page-Public/
- Github: https://github.com/ASLP-lab/WenetSpeech-Wu-Repo
- HuggingFace: https://huggingface.co/collections/ASLP-lab/wenetspeech-wu
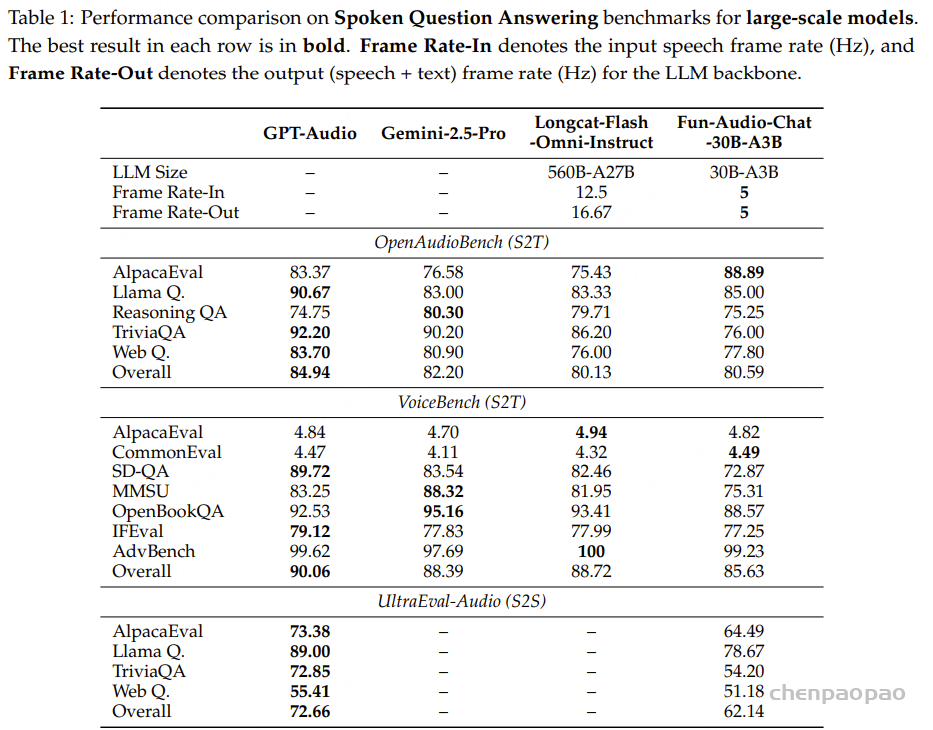
低资源方言的语音处理仍然是构建包容性强、鲁棒性高的语音技术过程中面临的一项基础性挑战。尽管中文吴语在语言学研究中具有重要地位,且使用人群规模庞大,但长期以来,其发展一直受限于大规模语音数据匮乏、缺乏统一的评测基准以及公开可用模型不足等问题。
本文提出 WenetSpeech-Wu,这是首个面向吴语的大规模、多维度标注的开源语音语料库,包含约 8000 小时来源多样的语音数据。

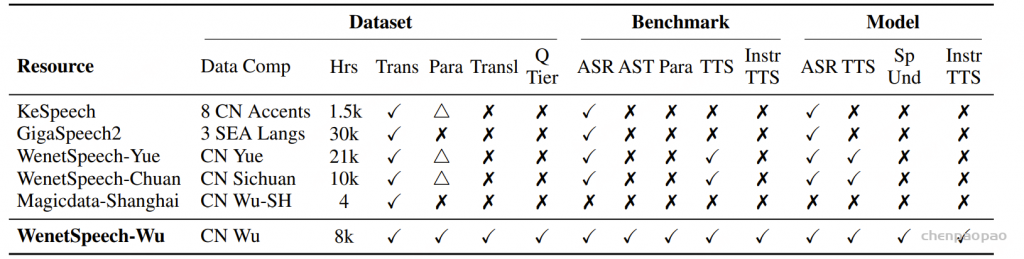
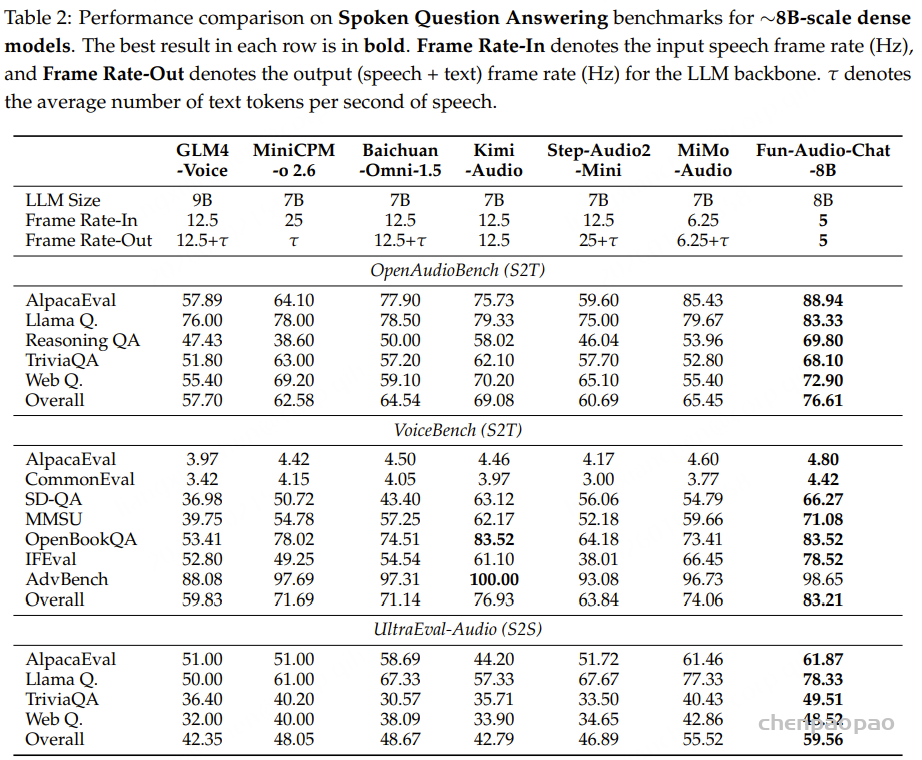
吴语语音处理面临三重关键困境:一是数据严重匮乏,现有公开数据集MagicData-Shanghai仅提供4.19小时的上海话标注语音,不仅规模极小,且未覆盖其他吴语子方言,更缺乏情感、说话人属性等支撑多类语音任务的关键标注;二是缺乏标准化评测基准,导致不同研究方法难以进行公平对比与系统评估;三是模型支撑不足,无论是开源还是商业语音处理模型,在吴语的自动语音识别(ASR)、文本到语音合成(TTS)等基础任务上均表现较差,无法满足实际应用需求。
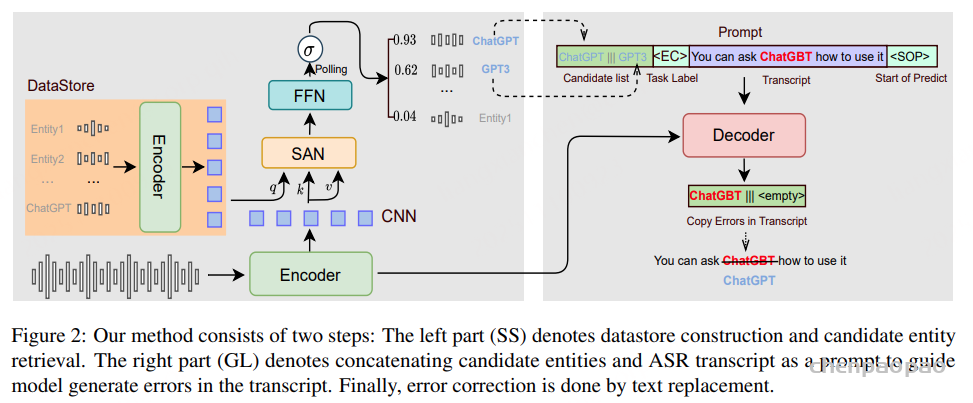
Datapipline Overview
本文提出了一种自动化且可扩展的流程,用于构建具有多维标注的大规模吴语语音数据集,如图1所示。该流程旨在实现高效的数据采集、稳健的自动转写以及多样化的下游标注任务支持

采集与过滤:我们从多种领域和不同子方言中收集大规模真实场景下的吴语语音数据。首先基于元数据进行筛选以去除非吴语内容,随后采用基于 WebRTC 的语音活动检测(VAD)进行分割处理。进一步结合 DNSMOS 和信噪比(SNR)进行质量过滤,最终获得高质量语音语料。
标注工具构建:为支持大规模自动转写,我们利用 880 小时人工标注的吴语语音数据对两个预训练 ASR 模型进行微调。
自动转写与结果融合:我们采用识别结果投票误差降低方法(ROVER)对多个 ASR 系统的转写结果进行融合。具体来说,我们结合了两个微调后的吴语 ASR 模型,以及 Dolphin 和 TeleASR 的输出,并通过网格搜索确定各模型权重。融合后的结果生成最终转写文本,并附带置信度分数。
多维标注:
- 说话人属性: 性别和年龄通过 VoxProfile 进行推断,多说话人检测则采用 Pyannote 实现。
- 吴语到普通话的翻译: 通过基于词典的映射生成,并进一步利用大语言模型 Qwen3-8B 进行优化,以获得更加流畅、标准的普通话表达。
- 情感标注: 通过多阶段、跨模态流程获得。首先使用 SenseVoice 和 Emo2Vec 对声学信号进行初步预测,并结合 Qwen3-8B 对文本内容进行情感分析。对于被联合判定为非中性的样本,进一步采用基于文本的 DeepSeek-R1 和基于声学信息的 Gemini-2.5-Pro 进行复核,最终标签由两者结果的交集确定。
- 韵律声学特征: 利用 Dataspeech 提取韵律声学特征,包括语速、响度、能量和音高,以支持语音生成相关任务。
数据集分布
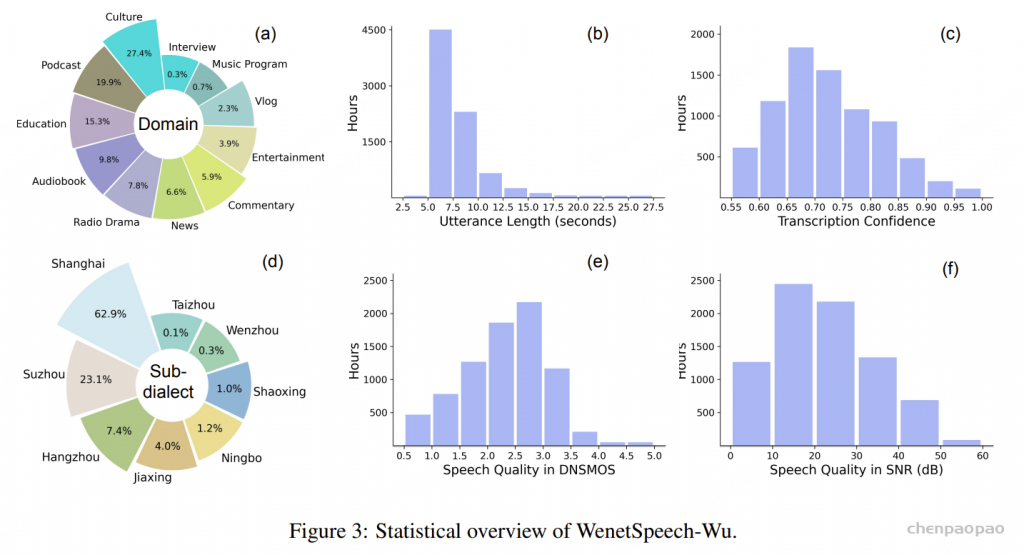
时长与置信度分布:WenetSpeech-Wu 包含 8,000 小时语音数据,共计 386 万条语句,单条语音时长最长可达 30 秒,平均时长为 7.45 秒。我们采用加权 ROVER 生成的转写置信度作为标注质量的衡量指标,并保留置信度高于 0.55 的语句。语句时长分布与转写置信度分布的详细情况分别如图2b和c所示。
领域与子方言覆盖:WenetSpeech-Wu 覆盖了广泛的语音领域和多种吴语子方言。语音领域包括 新闻、文化、Vlog、娱乐、教育、播客、评论、访谈、广播剧、音乐节目以及有声书,其分布情况如图2a和d所示。
在方言覆盖方面,约有 37% 的录音由于无法可靠地归属到某一具体吴语子方言,被标注为 Unknown。其余录音则覆盖了多种已识别的吴语子方言,包括 上海话、苏州话、绍兴话、宁波话、杭州话、嘉兴话、台州话和温州话,其分布如图2d 所示。
音频质量:如图2e 和图2f 所示,大多数语句的信噪比(SNR)分布在 10–40 dB 之间,并在 20–30 dB 区间达到峰值。主观听感质量(MOS)评分主要集中在 2.0–3.5 的范围内。
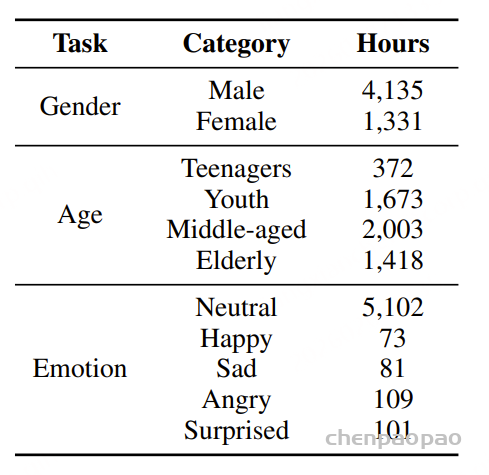
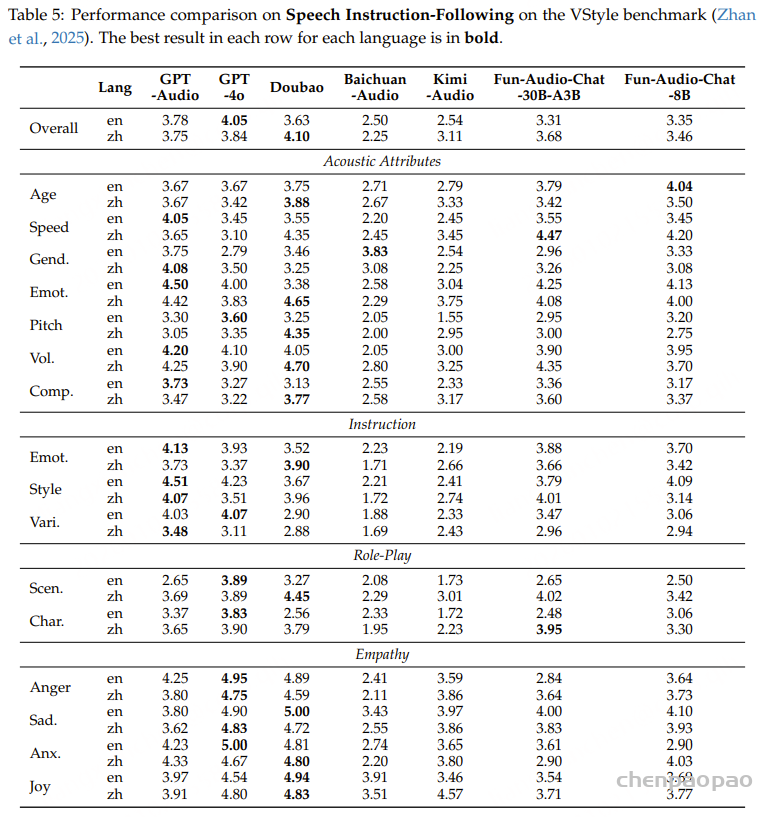
说话人属性与情感标注:我们针对单说话人语音片段标注了性别、年龄和情感信息。性别分为 男性和 女性;年龄划分为四个阶段:0–17 岁为 青少年,18–35 岁为 青年,36–59 岁为 中年,60 岁及以上为 老年;情感则分为五类:中性、快乐、悲伤、惊讶和 愤怒。各类别的具体分布情况如表2所示。
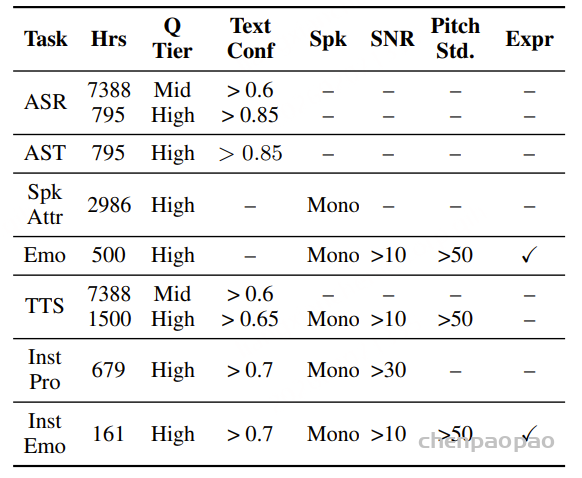
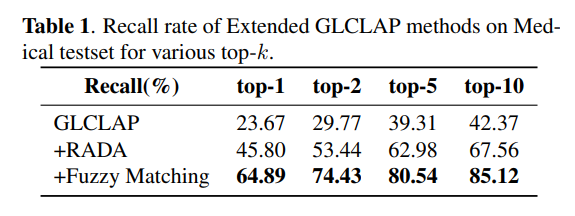
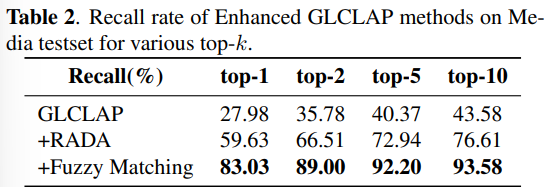
面向任务的数据质量分级:为支持多样化语音任务在实际训练中的不同需求,我们提出了一种与任务特定质量要求相匹配的数据质量分级策略。针对 ASR 和 TTS 任务,我们构建了两个质量等级的数据子集。其中,普通质量子集主要用于大规模预训练,更强调数据覆盖范围和多样性,仅要求中等水平的转写置信度;高质量子集则面向监督微调(SFT),采用更严格的筛选标准,包括更高的转写置信度、更干净的声学环境以及可靠的说话人分离,以提供更稳定、有效的监督信号。对于对标注噪声和语义歧义更为敏感的任务,例如吴语到普通话的自动语音翻译、说话人属性预测、语音情感识别、语音合成以及指令控制语音合成,我们采用了更为严格的数据筛选标准,包括单说话人录音、高 MOS 评分、较高信噪比、音高标准差约束,以及经过一致性验证的标注结果,具体标准如表3所示。
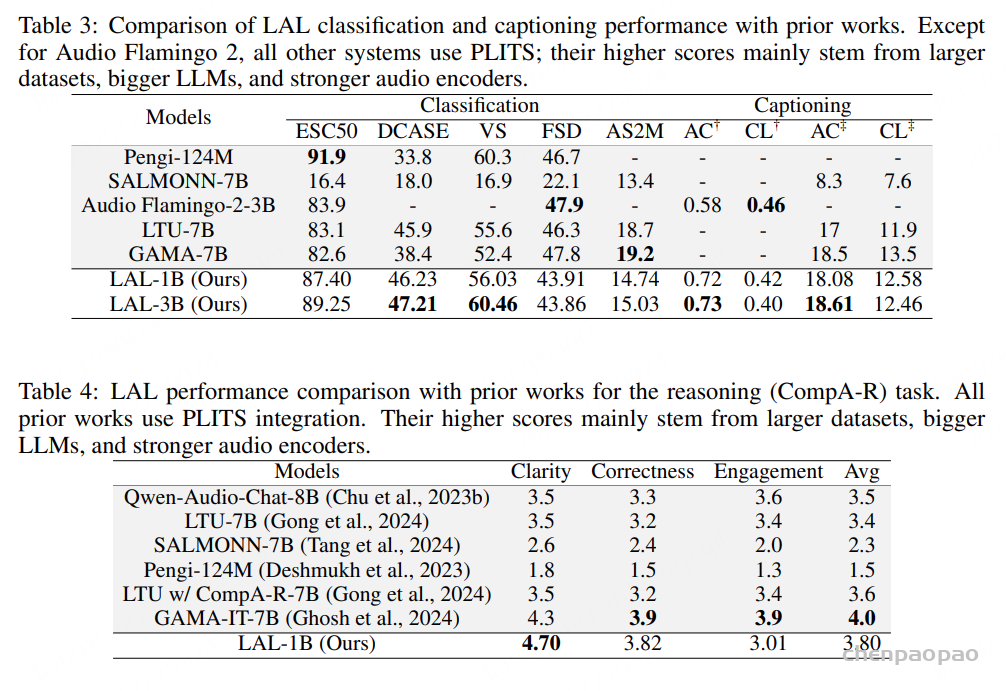
提出了 WenetSpeech-Wu-Bench,这是首个面向吴语语音处理的公开、人工精校评测基准,涵盖自动语音识别(ASR)、吴语到普通话自动语音翻译(AST)、说话人属性预测、情感识别、语音合成(TTS)以及指令控制语音合成(instruct TTS),为公平、统一的性能评估提供了标准化平台。
自动语音识别:WenetSpeech-Wu-Bench 的 ASR 测试集包含 9.75 小时的语音数据,涵盖上海话、苏州话以及普通话混合语码场景,同时包括单说话人和多说话人情形。
吴语到普通话语音翻译:吴语到普通话的 AST 测试集,共包含 3000 条吴语语句,总时长为 4.4 小时,配有经过人工校验的标准普通话译文,覆盖多个领域。
说话人属性预测与语音情感识别:该测试集用于评估吴语语音中的年龄、性别和情感预测能力。在说话人属性方面,性别分为男性和女性,每类各包含 1500 条样本;年龄划分为四组:17 岁及以下为青少年、18 至 35 岁为青年、36 至 59 岁为中年、60 岁及以上为老年,每组各 500 条样本。在情感分类方面,数据包括中性样本300 条,高兴、愤怒、惊讶样本各200条,难过样本100条,共计 1000 条。
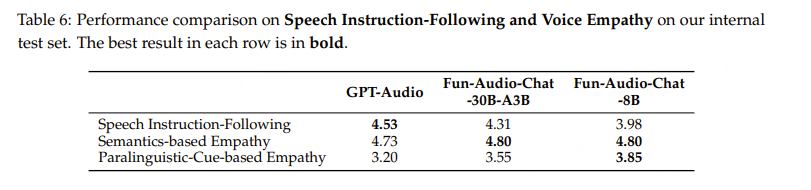
语音合成: TTS 测试集,包括 144 条简单句和 98 条复杂句,文本内容经专业吴语专家审校与优化。提示语音样本选自开源的 Magicdata-Shanghai 数据集,并通过严格筛选确定了 12 位吴语说话人。评估方面,说话人相似度通过 WeSpeaker 的说话人嵌入相似度计算,语音可懂度则使用我们提出的 Step-Audio2-Wu-ASR 模型计算 CER。此外,还开展了主观听测评估,包括可懂度 MOS(IMOS)、相似度 MOS(SMOS)和口音 MOS(AMOS)。主观测试由 23 名听众参与,每人评价 20 条样本。
指令控制语音合成:WenetSpeech-Wu-Bench包含两个用于评估指令控制语音合成的测试集。在韵律控制测试集中,选取了 5 条以中等语速和正常基频录制的语音提示,并基于这些提示合成了 20 条句子,通过控制语速和音高变化进行评估。评估包括两个实验条件:快速语速与高音高,以及慢速语速与低音高。所有样本通过 Dataspeech 自动标注。当语速和音高变化符合预期指令时,该样本记为 1 分,否则为 0 分,最终通过平均得分衡量模型对韵律指令的遵循能力。情感控制测试集用于评估模型对情感相关指令的响应能力。我们选取了 10 条不包含明显情感表达的参考提示语音,并基于每条提示为四种目标情感(愤怒、悲伤、快乐、惊讶)分别合成 50 条语句。样本通过 Step-Audio2-Wu-Und 模型进行评估,当预测情感与目标情感一致时记为正确,并以平均分类准确率作为指标。此外,还开展了主观听测实验,听众从韵律 MOS(PMOS)和情感 MOS(EMOS)两个维度对语音质量进行评分。该评测共有 23 名听众参与,每人评估 15 条样本,用于综合判断合成语音对指令的遵循程度。
实验
语音理解
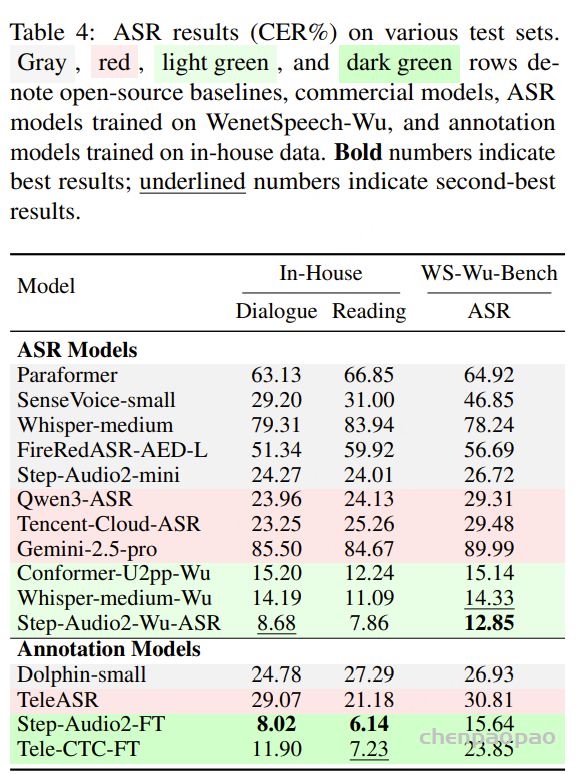
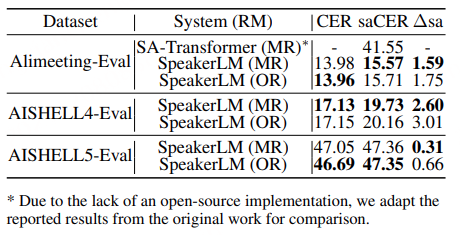
ASR 模型:评估工作在 WenetSpeech-Wu-Bench 的 ASR 测试集以及两个内部人工标注测试集上进行,后者涵盖对话与朗读场景,从而能够在多种说话条件下进行全面评估。
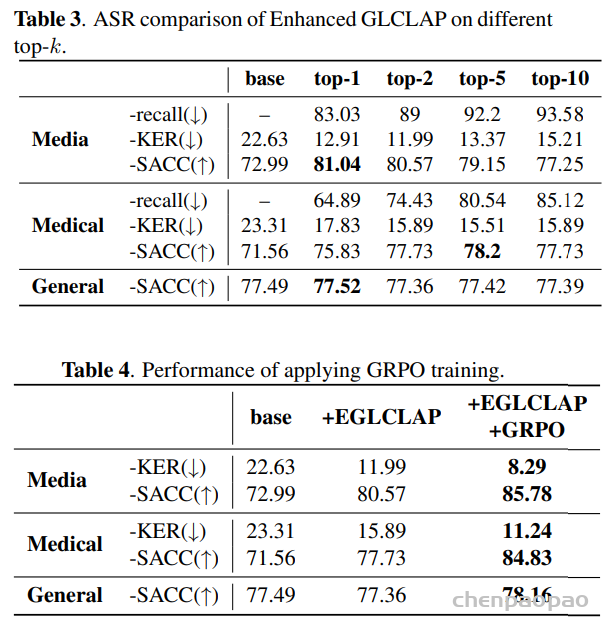
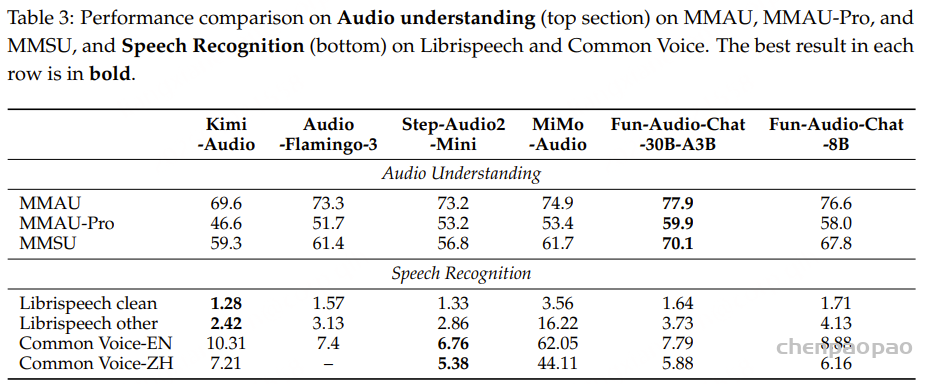
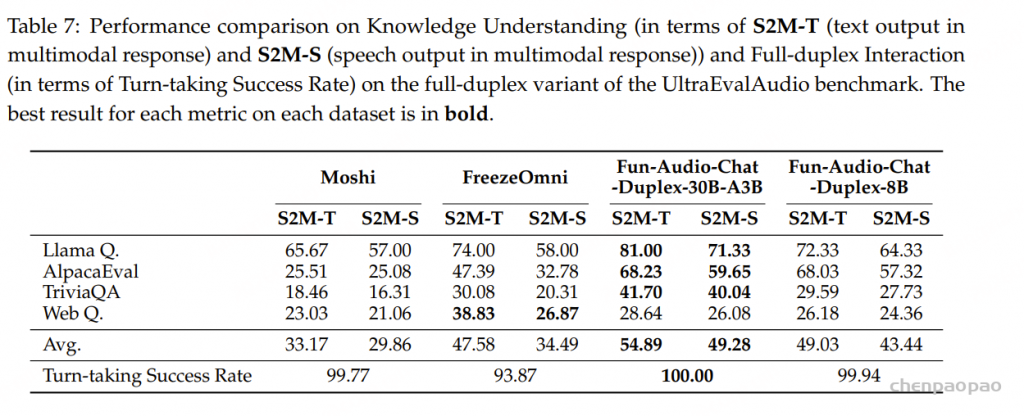
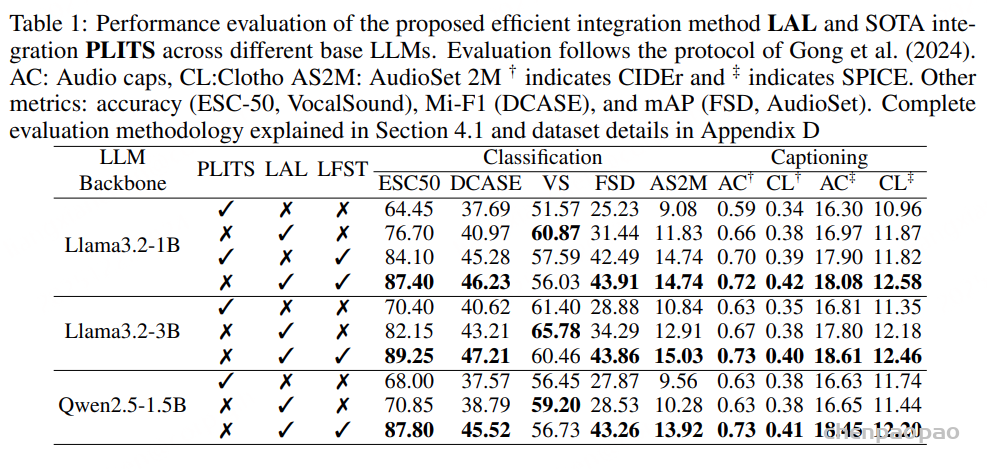
如表4所示,现有开源与商业 ASR 系统在三个测试集上的表现均较为有限,表明它们难以有效支持吴语识别任务。相比之下,基于 WenetSpeech-Wu 训练的模型( Conformer-U2pp-Wu、Whisper-medium-Wu、Step-Audio2-Wu-ASR)在各个规模下均取得了当前最优性能,即便是规模最小的 Conformer-U2pp-Wu,也显著优于以往所有系统。
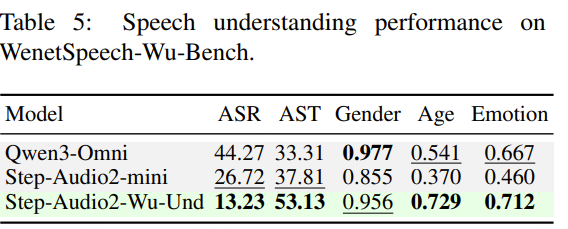
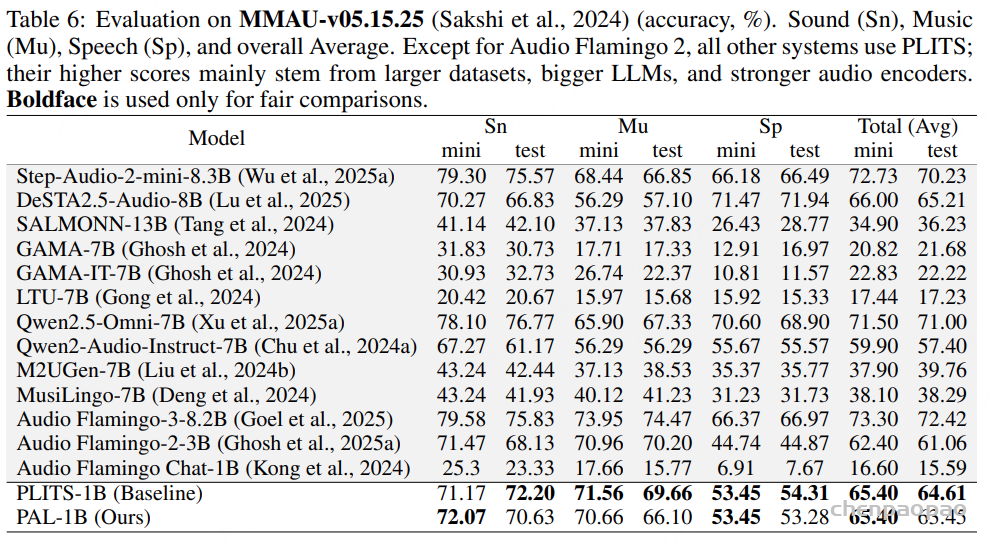
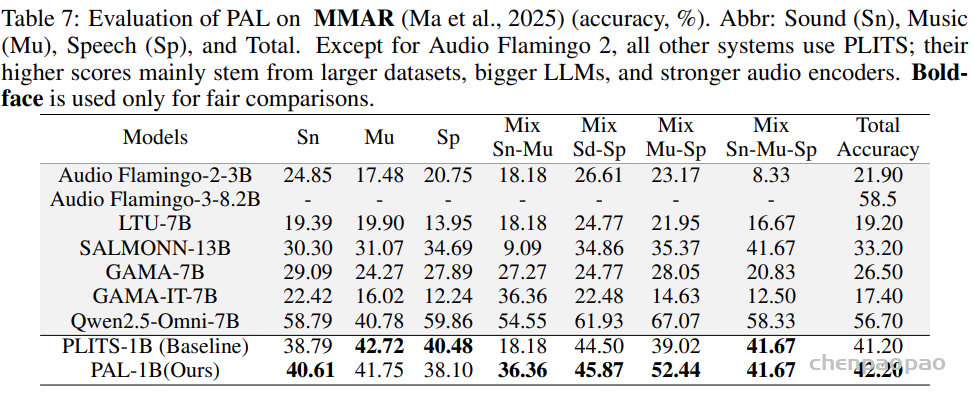
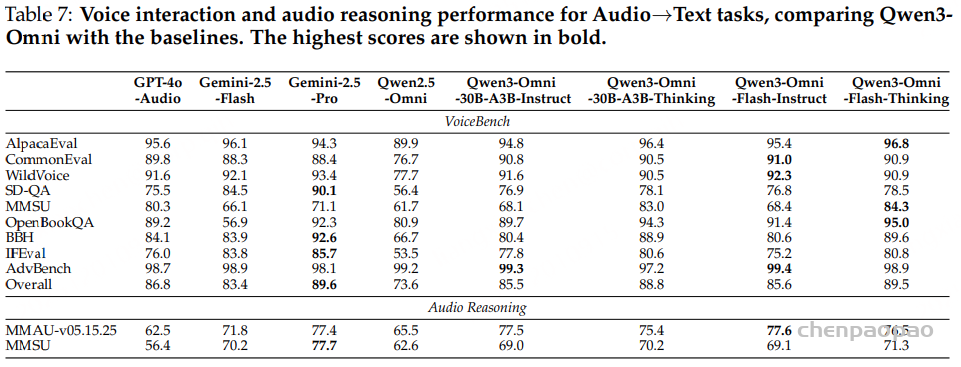
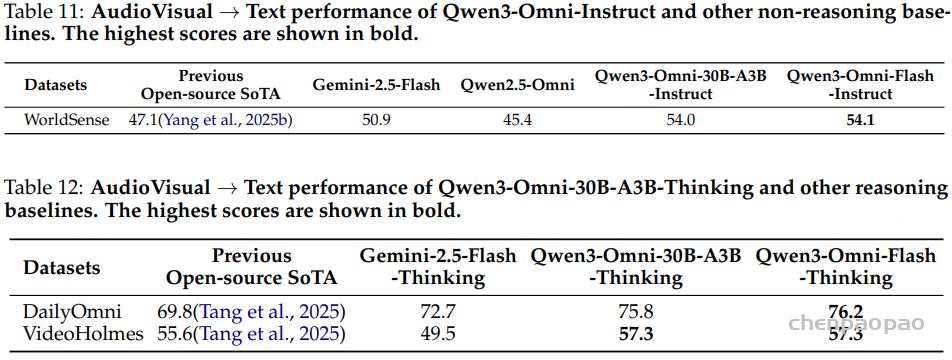
语音理解模型:结果表明,在多任务微调后,Step-Audio2-Wu-Und 的 ASR 性能较 Step-Audio2-Wu-ASR 略有下降,但仍位居第二。在吴语到普通话的 AST 任务上,该模型显著优于所有基线模型。与 Step-Audio2-mini 的对比进一步显示,普通话与吴语之间在性别、年龄和情感预测方面存在明显领域差异,而我们的数据有效缓解了这一问题。与 Qwen3-Omni 相比,我们的模型在年龄和情感预测任务上表现出显著提升,而在性别分类任务上略有下降。
语音生成
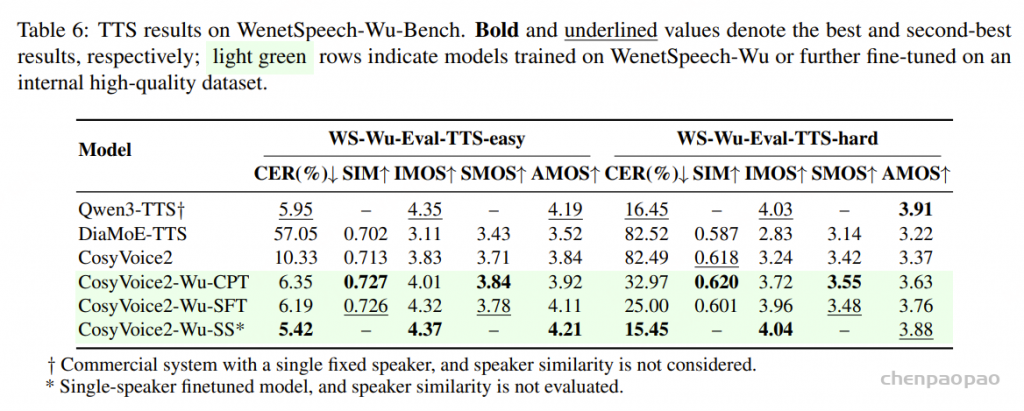
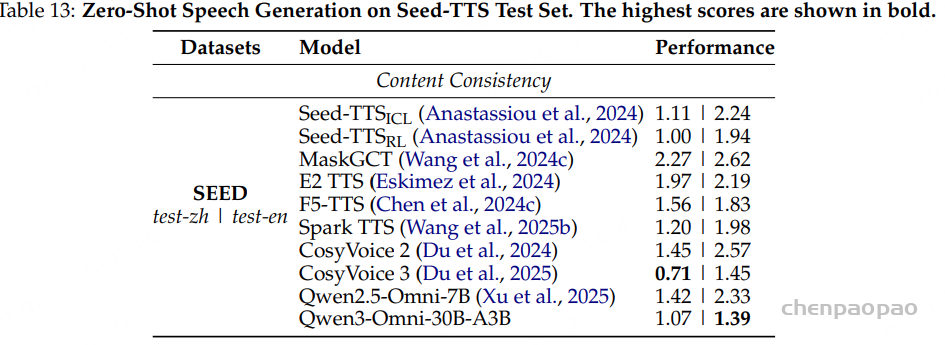
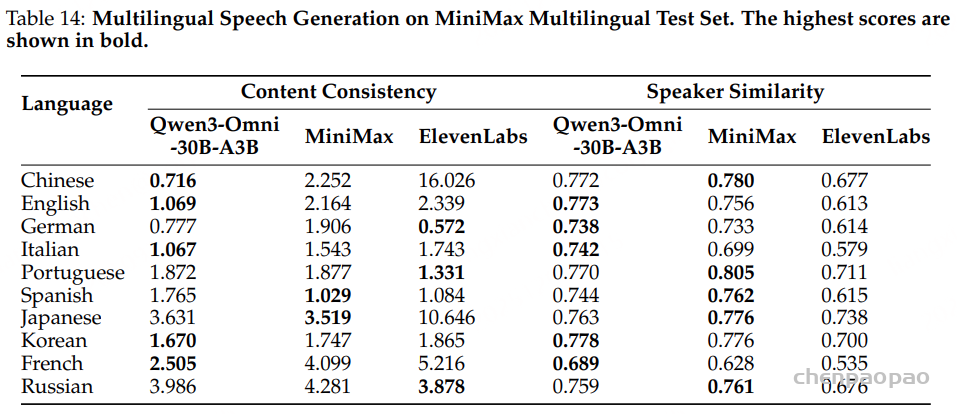
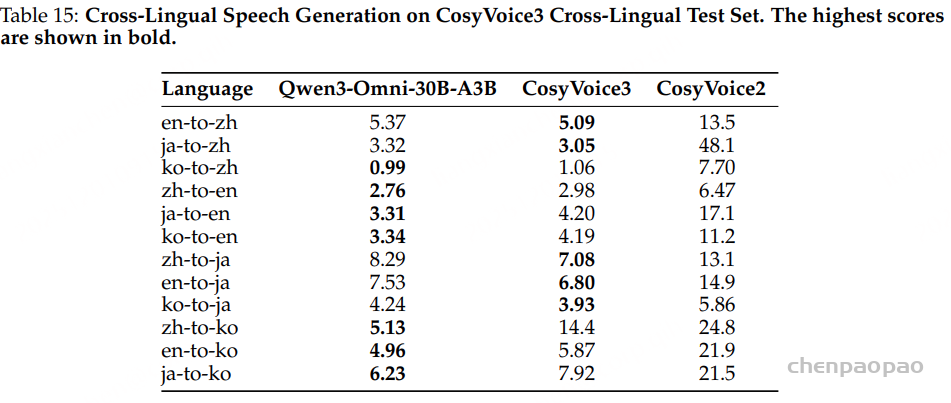
TTS 模型:如表6所示,实验结果表明,分阶段训练策略显著提升了 CosyVoice2 在吴语语音合成任务中的表现。CPT 阶段利用大规模数据,增强了模型的基础能力和鲁棒性,尤其在复杂样本上的表现提升明显。SFT 阶段进一步改善了语音的自然度与表现力。最终,在单说话人监督微调(SS-SFT)阶段,模型在 CER、IMOS 和 AMOS 等指标上均取得最佳结果。总体来看,CosyVoice2-Wu-SS 在多数评测指标上已接近或超过基线系统 Qwen3-TTS、DiaMoE-TTS 以及原始 CosyVoice2,尤其在高难度语音合成任务中优势更为明显。
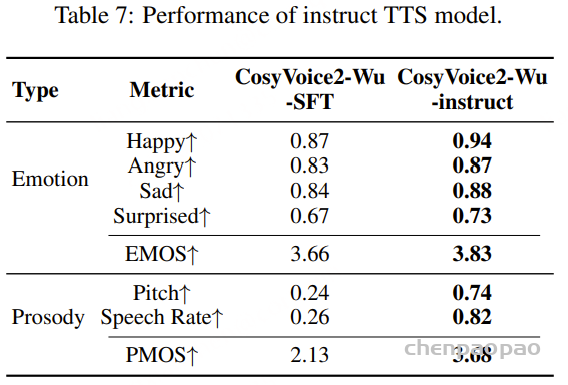
指令控制 TTS 模型:指令控制训练数据来源于表3中介绍的 Inst Pro 和 Inst Emo 数据集。微调后的模型在 WenetSpeech-Wu-Bench 上所有可控性指标均表现出明显提升,如表所示。主观听感测试同样验证了模型在韵律与情感控制方面具有良好的感知效果,进一步证明了所提出数据集与方法的有效性。















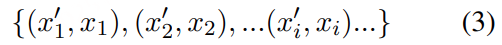
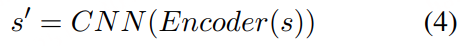
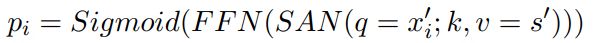
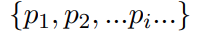


{kind=link}