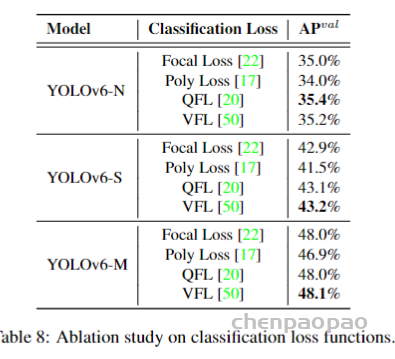
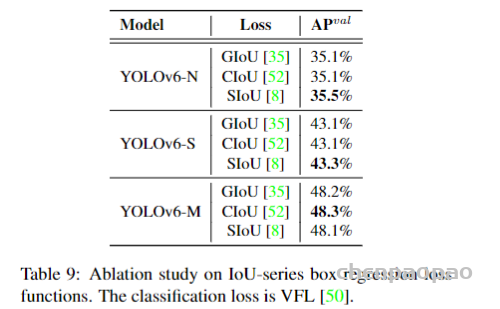
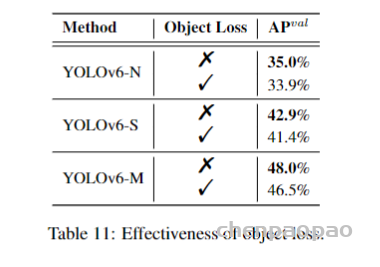
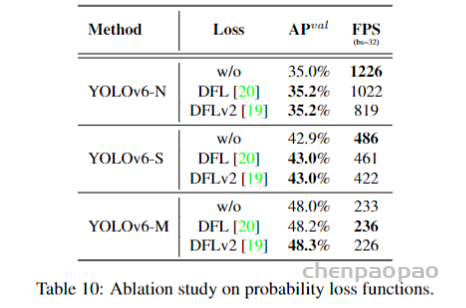
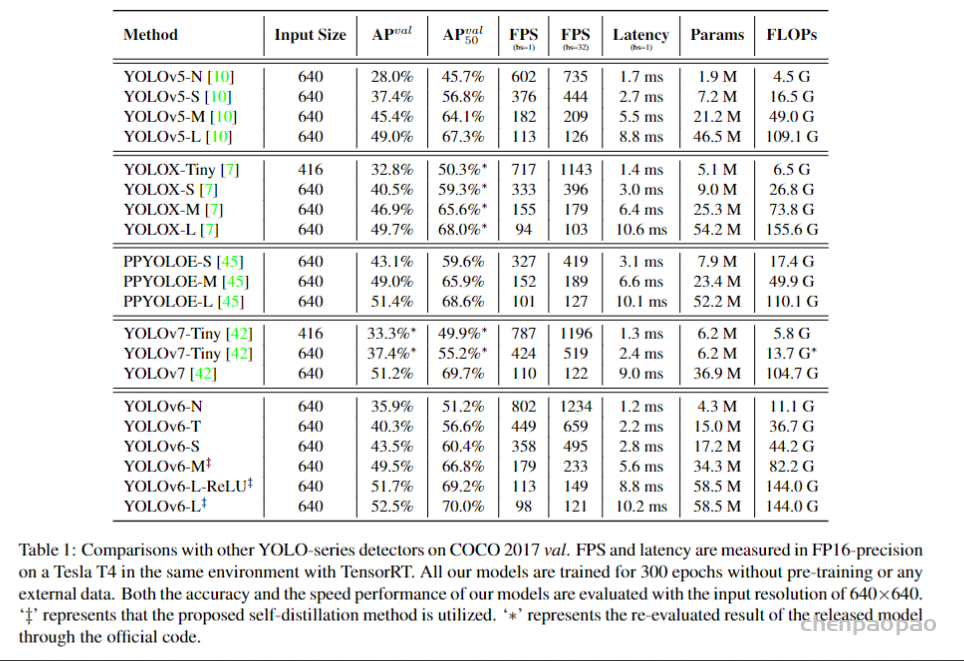
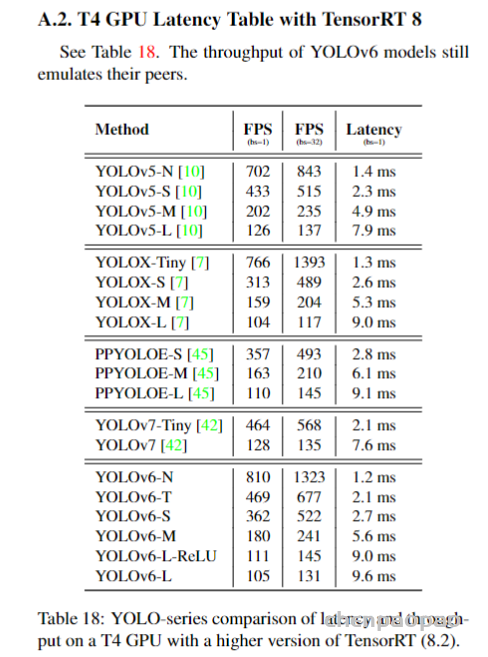
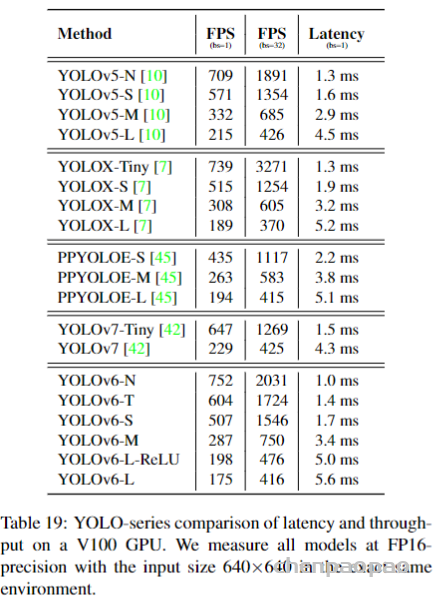
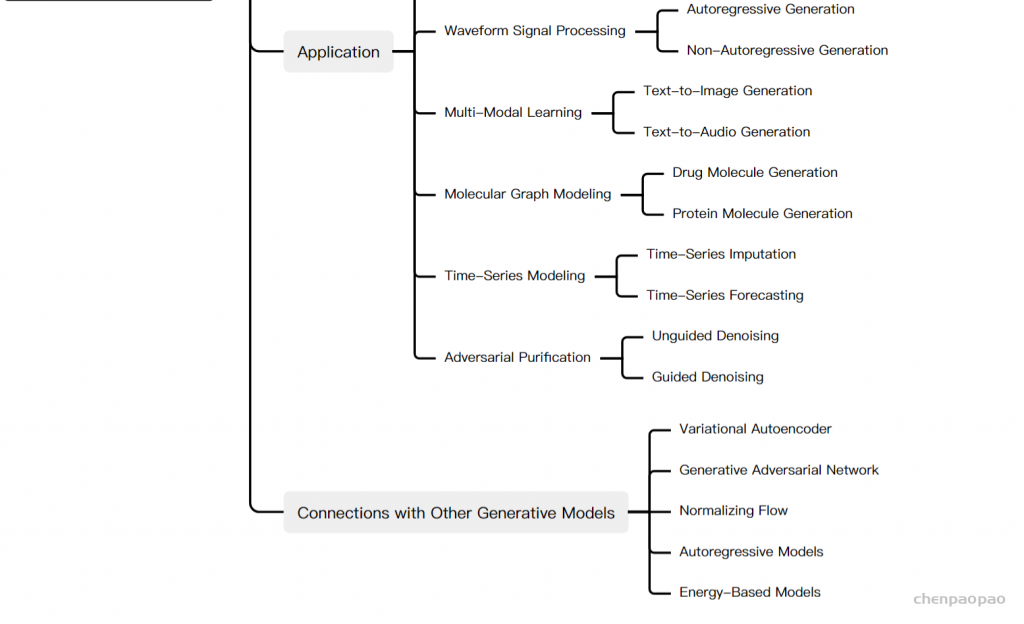
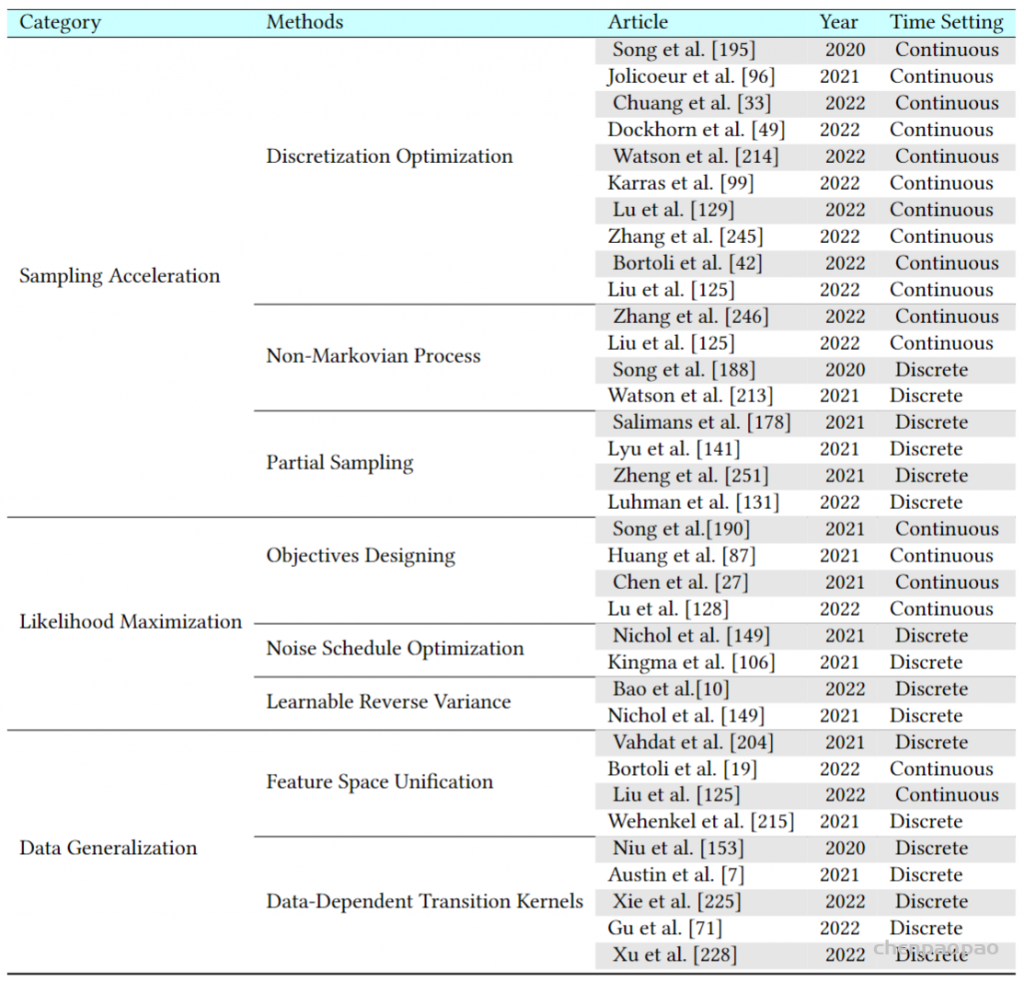
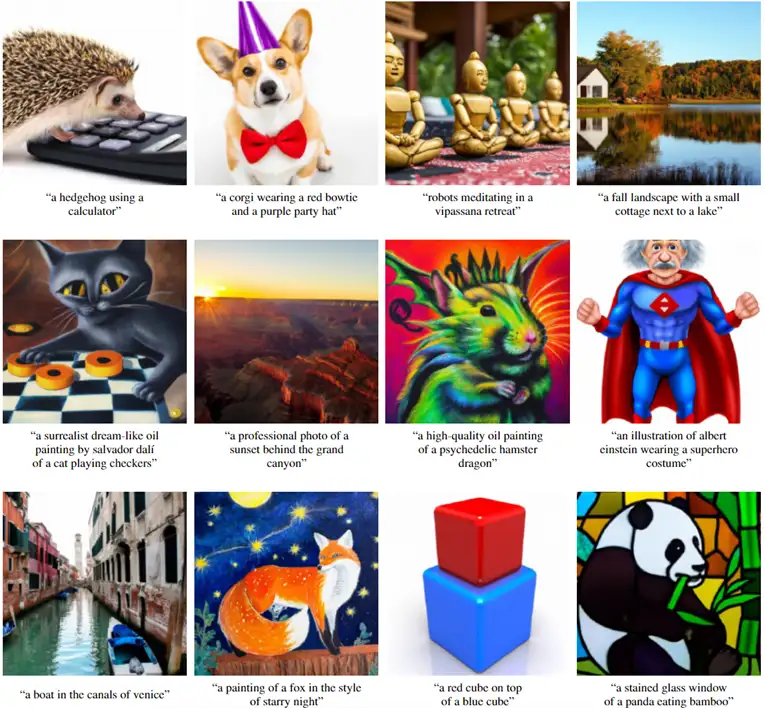
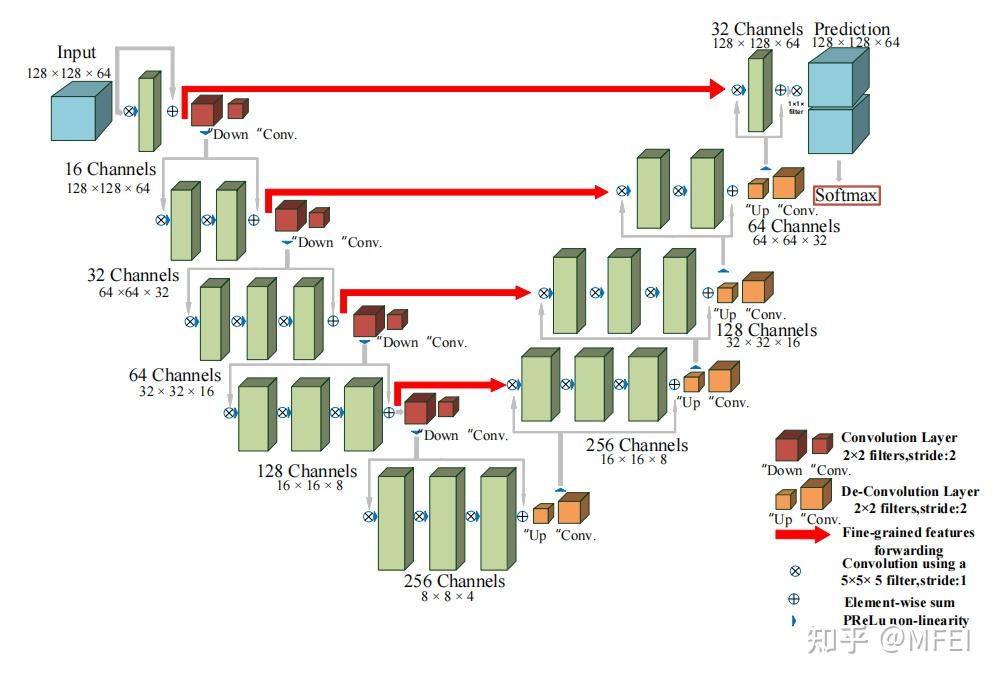
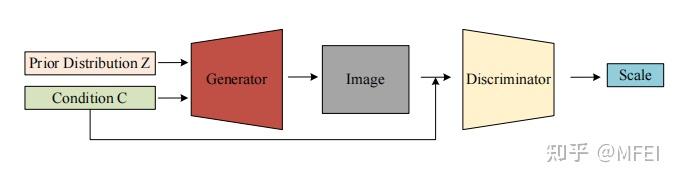
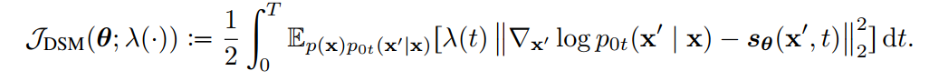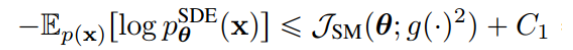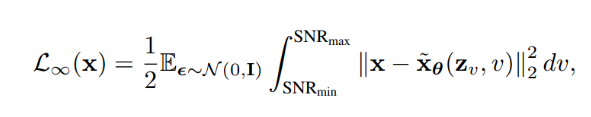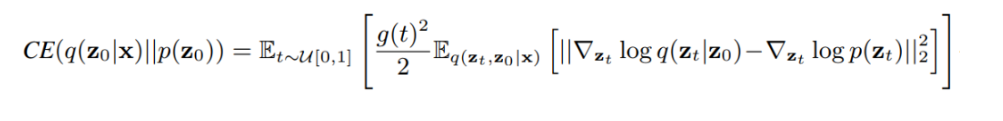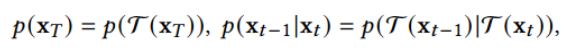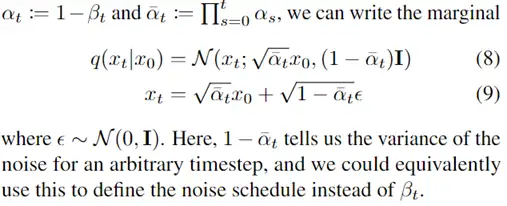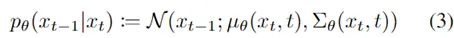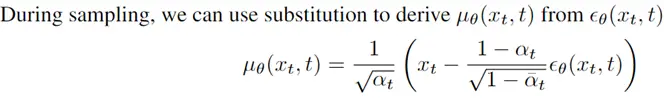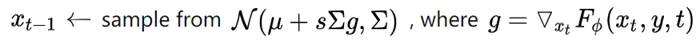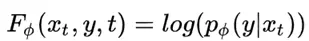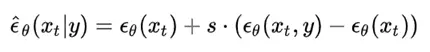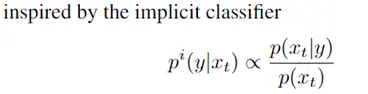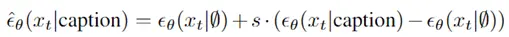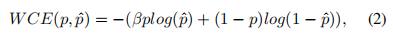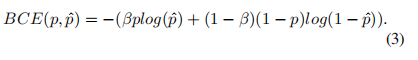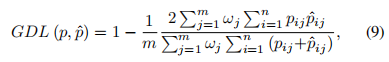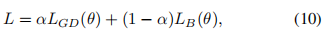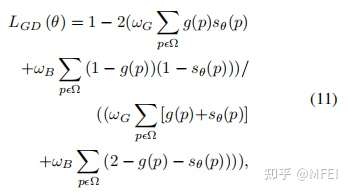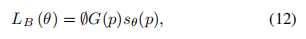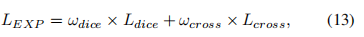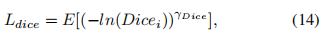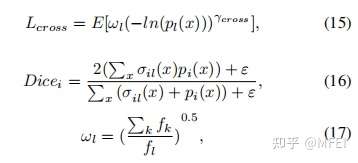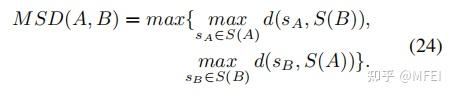论文地址: https://arxiv.org/abs/1912.08193
gitlab: https://github.com/zsef123/PointRend-PyTorch
存在的问题
在目前的语义分割网络中存在的问题主要有过采样和现采样。
1.过采样( oversample ):对于图片中低频区域( 属于同一个物体 ),没必要使用 太多的采样点,却使用太多采样点造成过采样;
2.欠采样( undersample ) :对于图片中高频区域( 靠近物体边界 ),如果这些区域的采样过于稀疏,导致分割出的边界过于平滑,不大真实
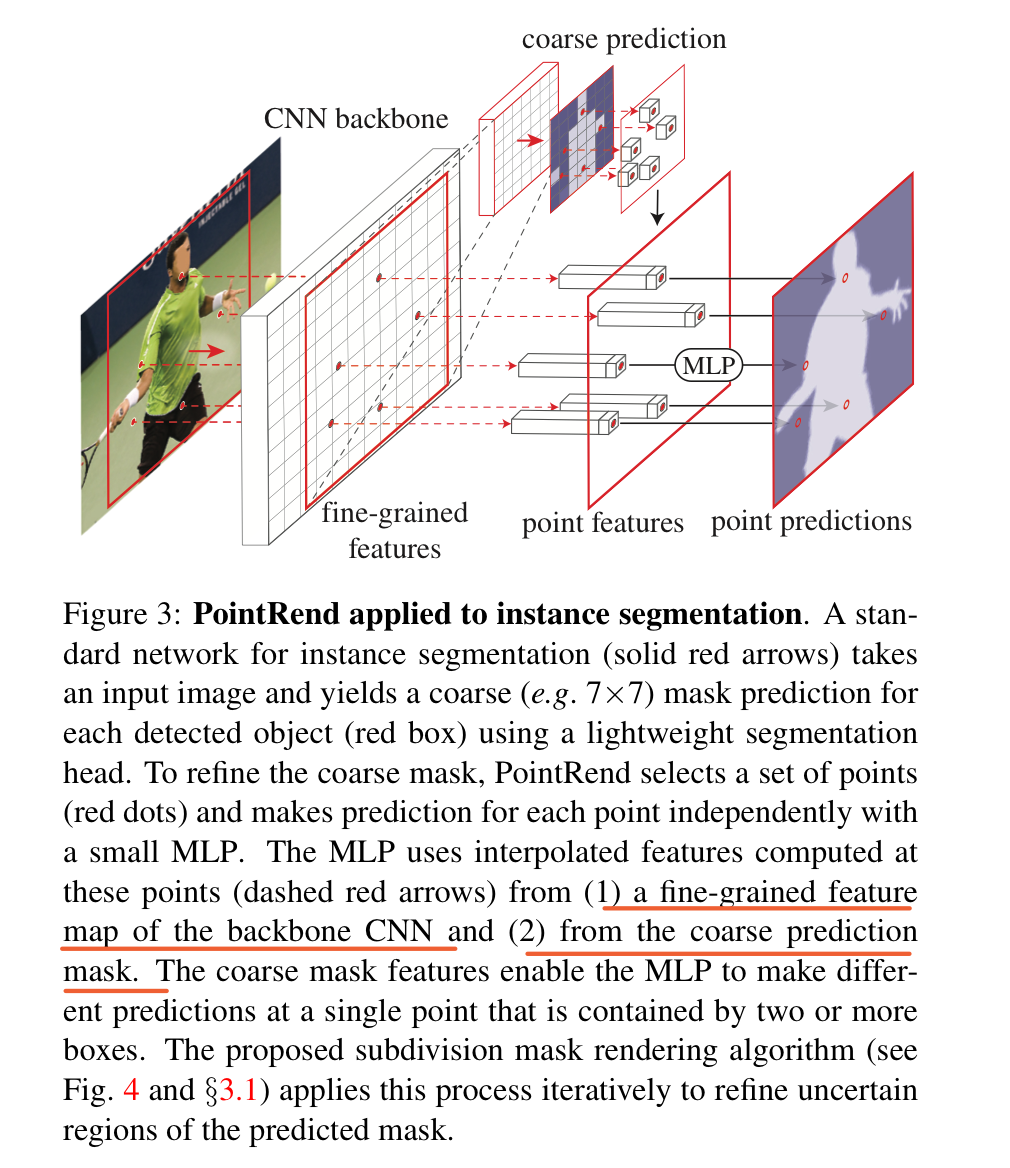
文章要解决的问题是在实例分割任务中边缘不够精细的问题。以MaskRCNN举例,由于计算量和显存的原因,对于每一个ROIAlign之后的proposal我们一般只会upsample到28*28的分辨率输出mask。这对于绝大多数物体显然是不够的。如果想得到像素级别的精度,我们不得不付出更大的计算和存储代价。那有什么办法可以在低代价下仍然得到精细的分割结果呢?其实很重要的一点是往往这些不准确的部分是在物体的边缘,这些边缘其实只占了整个物体中非常小的一部分。所以基于这样的一个想法,作者提出可以每次在预测出来的mask中只选择Top N最不确定的位置进行细分预测。每个细分点的特征可以通过Bilinear插值得到,每个位置上的classifier通过一个简单的MLP来实现。这其实是等价于用一个1*1的conv来预测,但是对于中心很确定的点并不计算。整体的示意图如下:
PointRend 解决了什么问题?
这篇论文讲了一个很好听的故事,即:把语义分割以及实例分割问题(统称图像分割问题)当做一个渲染问题来解决。故事虽然这么讲,但本质上这篇论文其实是一个新型上采样方法,针对物体边缘的图像分割进行优化,使其在难以分割的物体边缘部分有更好的表现。
作为一个小白,那么问题来了:
1、什么是渲染?
2、为什么要把图像分割问题当做渲染问题呢?
要想知道什么是渲染,可以参考:
简单来说,渲染就是“绘制”,把3D的物体在2D平面上绘制出来。
为什么要把图像分割问题和渲染问题扯在一起呢?因为讲故事好听啊,论文好写嘛….咳咳…不不,是因为二者有类似的问题要解决:即物体边缘难以处理。
具体来说,在图像渲染中,对于多个3D物体,在边缘要判断对于镜头而言谁先谁后,而且还得抗锯齿;而对于图像分割问题,边缘恢复也一直是个麻烦事儿,因为在典型的语义分割网络中(如FCN、DeepLab),在CNN内部一般都会相对输入图像降采样16倍,然后再想办法上采样回去。更细致地说,对于 DeepLabV3+,模型最后直接是一个4倍的双线性插值上采样,这显然对物体边缘的预测十分不利。虽然 DeepLabV3+当时在2017年就达到了秒天秒地的 89%mIoU on VOC2012 test (使用了300M JFT 数据集预训练),至今无人超越(因为JFT 数据集 Google没有公开 \手动滑稽),但显然这个上采样过程仍然存在较大的提升空间。
参考链接:Uno Whoiam:DeepLab 语义分割模型 v1、v2、v3、v3+ 概要(附 Pytorch 实现)
而在实例分割网络中,Mask R-CNN 这货生成的 Mask 才 28×28,要是把这样的 mask 拉伸到 不说多了比如 256×256,还指望它可以很好地预测边缘?我只能说这是在想Peach。
事实上,在图像分割任务上边缘预测不理想这个情况其实在许多前人的工作中都有提及,比如 Not All Pixels Are Equal: Difficulty-Aware Semantic Segmentation via Deep Layer Cascade 中就详细统计了语义分割中,模型最容易误判的 pixel基本上都在物体边缘(如下图右上红色部分标记) 。

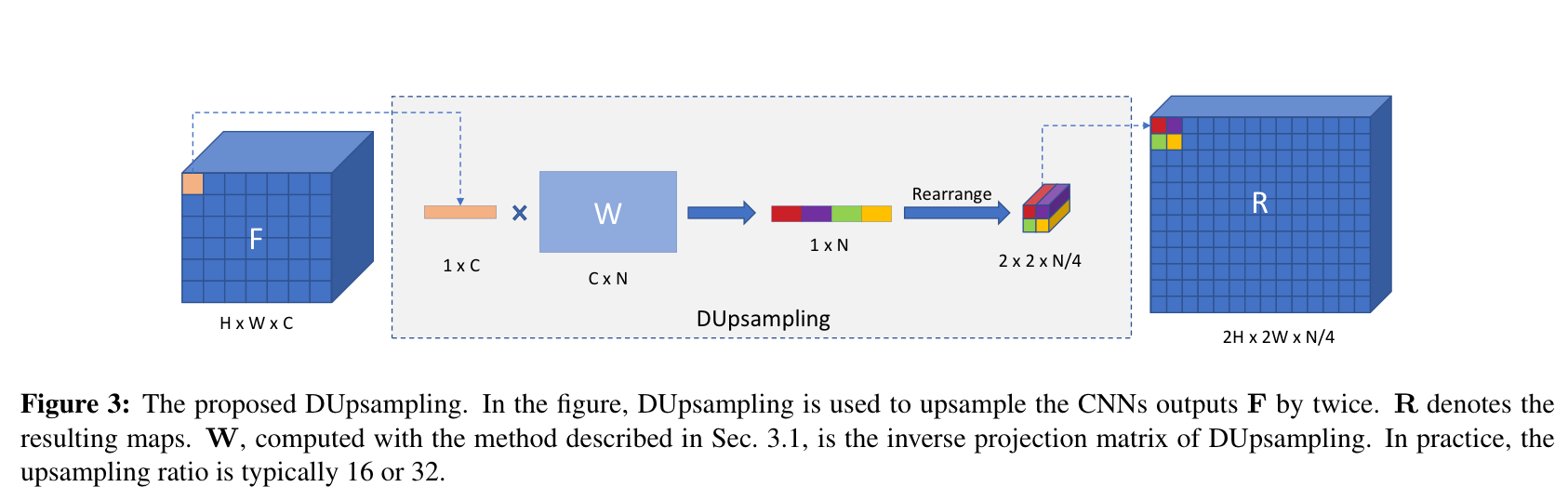
而关于上采样其实也有一些前人的工作,如 Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation,在实现上有点像超分辨率网络 ESPCN 里使用的 sub-pixel convolutional layer 的操作,不过多加了一个二阶范数约束:
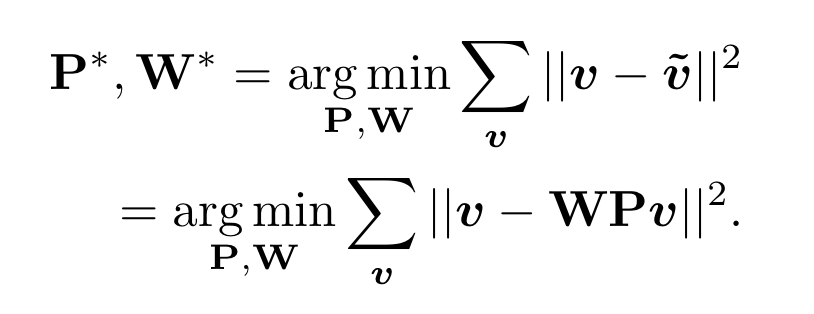
总的来说,图像分割边缘预测是一个未被很好解决的问题,而何恺明团队的 PointRend 是对此问题的一个新的思路和解法,接下来将介绍 PointRend 是如何 work 的。
文主要贡献
1.提出可嵌入主流网络的PointRend模块,提高了图像分割精度。
2.把图像分割问题看作渲染问题,本质上是一个新型上采样方法,为图像分割提供独特视角。
3.降低了训练所需的算力。输出224×224分辨率图像,PointRend只需0.9B FLOPs。
二、总体思路
PointRend 方法要点总结来说是一个迭代上采样的过程:
while 输出的分辨率 < 图片分辨率:
- 对输出结果进行2倍双线性插值上采样得到 coarse prediction_i。(粗分辨率预测)
- 挑选出 N 个“难点”,即结果很有可能和周围点不一样的点(例如物体边缘)。
- 对于每个难点,获取其“表征向量”,“表征向量”由两个部分组成,其一是低层特征(fine-grained features),通过使用点的坐标,在低层的特征图上进行双线性插值获得(类似 RoI Align),其二是高层特征(coarse prediction),由步骤 1 获得。
- 使用 MLP 对“表征向量”计算得到新的预测,更新 coarse prediction_i 得到 coarse prediction_i+1。这个 MLP 其实可以看做一个只对“难点”的“表征向量”进行运算的由多个 conv1x1 组成的小网络。
整个过程可以这么理解:
小明同学做题,现在有已知条件(coarse prediction_0,fine-grained features),想求解答案(coarse prediction_k),发现直接求(双线性插值or其它方法)不够准确,那就一步一步来吧(从coarse prediction_1,coarse prediction_2….求到coarse prediction_k)。好的,现在求coarse prediction_1,诶,发现有好多东西不知道,不能从 coarse prediction_0 直接得到怎么办?那就找出不知道的(“难点”),在 fine-grained features 里面找出对应的线索(ROIAlign-like 双线性插值),然后在结合 coarse prediction_0 得到整体线索(“特征向量”)求解(使用MLP计算),嗯,终于得到 coarse prediction_1了。再用同样的思路反复求解,直到 coarse prediction_k。
示意图如下:

另外,其PointRend 训练为了节省时间,没有使用上述的迭代过程,而是使用多种组合的采样方法,不赘述,详见paper。
- 从PointRend的应用思路中可以看到,这里包含了两个阶段的特征处理,分别是fine-grained features和coarse prediction部分,如果主干网络是ResNet,那么fine-grained features就是ResNet的stage2输出,也就是4倍下采样时的精细分割结果,而coarse prediction就是检测头的预测结果(还未上采样还原成原图的结果)。
- 从coarse prediction中挑选N个“难点”,也就是结果很有可能和周围点不一样的点(比如物体边缘的点)。对于每一个难点,获取他的“特征向量”,对于点特征向量(point features),主要由两部分组成,分别是fine-grained features的对应点和coarse prediction的对应点的特征向量,将这个两个特征向量拼接成一个向量。
- 接着,通过一个MLP网络对这个“特征向量”进行预测,更新coarse prediction。也就相当于对这个难点进行新的预测,对他进行分类。
看完这个,我们就可以这么理解,将预测难的点(边缘点)提取出来,再提取其特征向量,经过MLP网络,将这个点的归属进行分类,然后提升这些点的分类准确率。这就是PointRend的思想。
一个PointRend模块包括三部分。
1.point selection strategy:用于inference和traing的点选择
对于点采样过程,需要对模型的Train过程和Inference过程做区分
该方法的核心思想是灵活自适应地选择图像平面上的点来预测分割标签。直观地说,这些点应该更密集地位于高频区域附近,例如物体边界,类似于射线追踪中的反混叠问题。我们产生了推理和训练的想法。
- inference推理
通过仅在与其邻域有显着不同的位置进行计算,该方法可用于有效地渲染高分辨率图像(例如,通过光线跟踪)。对于所有其他位置,通过对已经计算的输出值(从粗网格开始)进行插值来获得值。
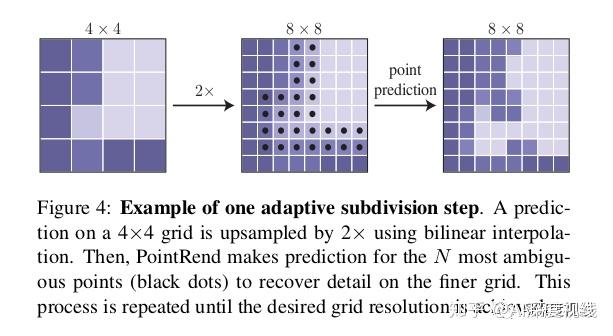
对于每个区域,我们以粗到精的方式迭代地“渲染”输出蒙版。在规则网格上的点上进行最粗糙级别的预测(例如,通过使用标准的粗糙分段预测头)。在每次迭代中,PointRend使用双线性插值对其先前预测的分段进行上采样,然后在此较密集的网格上选择N个最不确定的点(例如,对于二进制掩码,概率最接近0.5的那些)。然后,PointRend为这N个点中的每一个点计算特征,并预测它们的标签。重复该过程,直到将分段上采样到所需的分辨率为止。
- training
对于Train过程的点采样操作,同样可以遵循Inference中的操作。但是作者发现,这样子采样对于梯度的传播不太友好,于是只能被迫选择其他的点采样策略——干脆就用随机采样的方式来进行采样。
在训练过程中,PointRend还需要选择一些点,以在这些点上构建用于训练point head的逐点(point-wise)特征。原则上,点选择策略可以类似于推理inference中使用的细分策略。但是,细分引入了一系列步骤,这些步骤对于通过反向传播训练神经网络不太友好。取而代之的是,为了训练,我们使用基于随机采样的非迭代策略。
采样策略在特征图上选择N个点进行训练。它旨在使用三个原理将选择偏向不确定区域,同时还保留一定程度的均匀覆盖。对于训练和推理选择,N的值可以不同。
(i)过度生成:我们通过从均匀分布中随机采样kN个点(k> 1)来过度生成候选点。(ii)重要抽样:通过对所有kN个点的粗略预测值进行插值并计算任务特定的不确定性估计,我们将重点放在具有粗略预测的点上。从kN个候选中选择最不确定的βN个点(β∈[0,1])。(iii)覆盖范围:从均匀分布中采样剩余的(1-β)N点。我们用不同的设置来说明此过程,并将其与常规的网格选择进行比较,如下图所示。

在训练时,预测和损失函数仅在N个采样点上计算(除粗略分割外),这比通过细分步骤进行反向传播更简单,更有效。这种设计类似于在Faster R-CNN系统中对RPN + Fast R-CNN的并行训练,其推理是顺序的。
2. Point-wise Representation:逐点表示
PointRend通过组合(例如,级联)两种特征类型(细粒度和粗略预测特征)在选定点上构造逐点特征,如下所述。
- 细粒度特征
为了允许PointRend呈现精细的分割细节,我们从CNN特征图中提取每个采样点的特征向量。 因为一个点是“实值2D坐标”,所以我们按照标准做法对特征图执行双线性插值,以计算特征向量。 可以从单个特征图中提取特征(例如,ResNet中的res2);也可以按照Hypercolumn方法,从多个特征图(例如res2到res5)中提取并连接它们。
- 粗预测特征
细粒度的特征可以解析细节,但在两个方面也有不足:
首先,它们不包含特定区域的信息,因此,两个实例的边界框重叠的相同点将具有相同的细粒度特征。但是,该点只能位于一个实例之中。 因此,对于实例分割的任务,其中不同的区域可能针对同一点预测不同的标签,因此需要其他区域特定的信息。
其次,取决于用于细粒度特征的特征图,这些特征可能只包含相对较低级别的信息(例如,我们将对res2使用DeepLabV3)。 因此,需要有更多具有上下文和语义信息的特征。
基于这两点考虑,第二种特征类型是来自网络的粗分割预测,例如表示k类预测的区域(box)中每个点的k维向量。通过设计,粗分辨率能够提了更加全局的上下文信息,而通道则传递语义类别。这些粗略的预测与现有架构的输出相似,并且在训练过程中以与现有模型相同的方式进行监督。例如,在mask R-CNN中,粗预测可以是一个轻量级的7×7分辨率Mask头的输出。
点特征向量(point features),主要由两部分组成,分别是fine-grained features的对应点和coarse prediction的对应点的特征向量,将这个两个特征向量拼接成一个向量
3. point head
给定每个选定点的逐点特征表示,PointRend使用简单的多层感知器(MLP)进行逐点分割预测。这个MLP在所有点(和所有区域)上共享权重,类似于图卷积或PointNet。由于MLP会预测每个点的分割标签,因此可以通过特定任务的分割loss进行训练。
三、效果如何?
3实验结果
- 网络设计
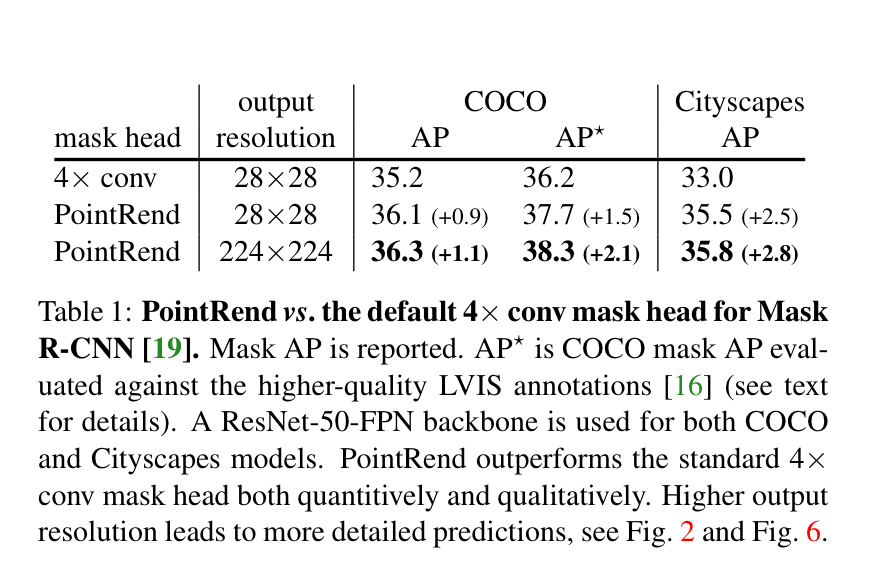
实验使用ResNet-50+ FPN 的Mask-Rcnn作backbone。 Mask-RCNN中的默认head是region-wise FCN,用“ 4×conv”表示,作为用来与本文网络进行比较的基准网络。
为了计算粗略预测,我们用重量更轻的设计替换4×conv Mask头,该设计类似于Mask R-CNN的box head产生7×7Mask预测。具体来说,对于每个边界框,我们使用双线性插值从FPN的P2层提取14×14特征图。这些特征是在边界框内的规则网格上计算的(此操作可以看作是RoIAlign的简单版本)。接下来,我们使用具有256个输出通道步幅为2的 2×2卷积层,后跟ReLU, 将空间大小减小到7×7。最后,类似于Mask R-CNN的box head,用两个带1024宽的隐藏层的MLP为K类分别产生7×7的Mask预测。ReLU用于MLP的隐藏层,并且Sigmoid激活函数应用于输出。
PointRend:在每个选定点上,使用双线性插值从粗预测头的输出中提取K维特征向量,PointRend还从FPN的P2级别插值256维特征向量,步长为4。这些粗预测和细粒度特征向量是串联在一起的,我们使用具有256个通道的3个隐藏层的MLP在选定点进行K类别预测。在MLP的每个层中,我们用K个粗预测特征补充到256个输出通道中,作为下一层输入向量。在MLP中使用ReLU,并将Sigmoid激活函数应用于输出。
不得不说这个针对物体边缘进行优化的上采样方法的确在感官上和数据上都有很不错的效果:

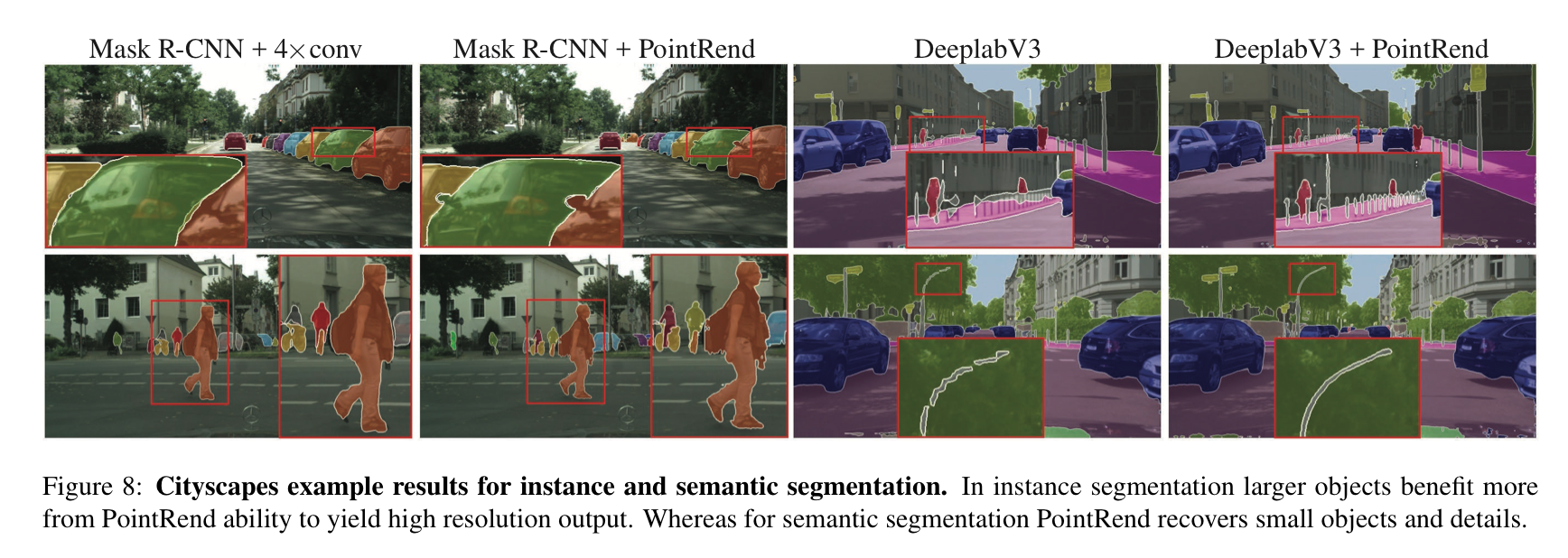
语义分割结果:

实例分割结果(基于MaskR-CNN):
PointRend的一些代码和实现
摘自: https://chowdera.com/2022/194/202207120607167479.html
代码详解: https://www.361shipin.com/blog/1536592971120508928
- 作者提出可以在预测出来的mask中只选择Top N最不确定的位置进行细分预测。
具体为先根据粗糙预测出来的mask,将mask按类别预测分数排序,选出分数高的前2 类别的mask,计算出在2个类别mask上均有较高得分的Top K个像素点作为K 个不确定点【1个像素点只能对应1个类别,如果它对应2个类别的分数都很高,说明它很可能是边界点,也是不确定的】
def sampling_points(mask, N, k=3, beta=0.75, training=True):
"""
主要思想:根据粗糙的预测结果,找出不确定的像素点
:param mask: 粗糙的预测结果(out) eg.[2, 19, 48, 48]
:param N: 不确定点个数(train:N = 图片的尺寸/16, test: N = 8096) eg. N=48
:param k: 超参
:param beta: 超参
:param training:
:return: 不确定点的位置坐标 eg.[2, 48, 2]
"""
assert mask.dim() == 4, "Dim must be N(Batch)CHW" #this mask is out(coarse)
device = mask.device
B, _, H, W = mask.shape #first: mask[1, 19, 48, 48]
mask, _ = mask.sort(1, descending=True) #_ : [1, 19, 48, 48],按照每一类的总体得分排序
if not training:
H_step, W_step = 1 / H, 1 / W
N = min(H * W, N)
uncertainty_map = -1 * (mask[:, 0] - mask[:, 1])
#mask[:, 0]表示每个像素最有可能的分类,mask[:, 1]表示每个像素次有可能的分类,当一个像素
#即是最有可能的又是次有可能的,则证明它不好预测,对应的uncertainty_map就相对较大
_, idx = uncertainty_map.view(B, -1).topk(N, dim=1) #id选出最不好预测的N个点
points = torch.zeros(B, N, 2, dtype=torch.float, device=device)
points[:, :, 0] = W_step / 2.0 + (idx % W).to(torch.float) * W_step #点的横坐标
points[:, :, 1] = H_step / 2.0 + (idx // W).to(torch.float) * H_step #点的纵坐标
return idx, points #idx:48 || points:[1, 48, 2]- 得到不确定点的位置以后,可以通过Bilinear插值得到对应的特征,对每个不确定点的使用一个MLP来进行单独进行细分预测【训练与预测有所区别】。
具体为:通过刚刚得到的不确定点所在图片的相对位置坐标来找到对应的特征点,将此点对应的特征向量与此点的粗糙预测结果合并,然后通过一个MLP进行细分预测。
##训练阶段
def forward(self, x, res2, out):
"""
主要思路:
通过 out(粗糙预测)计算出top N 个不稳定的像素点,针对每个不稳定像素点得到在res2(fine)
和out(coarse)中对应的特征,组合N个不稳定像素点对应的fine和coarse得到rend,
再通过mlp得到更准确的预测
:param x: 表示输入图片的特征 eg.[2, 3, 768, 768]
:param res2: 表示xception的第一层特征输出 eg.[2, 256, 192, 192]
:param out: 表示经过级联空洞卷积提取的特征的粗糙预测 eg.[2, 19, 48, 48]
:return: rend:更准确的预测,points:不确定像素点的位置
"""
"""
1. Fine-grained features are interpolated from res2 for DeeplabV3
2. During training we sample as many points as there are on a stride 16 feature map of the input
3. To measure prediction uncertainty
we use the same strategy during training and inference: the difference between the most
confident and second most confident class probabilities.
"""
if not self.training:
return self.inference(x, res2, out)
#获得不确定点的坐标
points = sampling_points(out, x.shape[-1] // 16, self.k, self.beta) #out:[2, 19, 48, 48] || x:[2, 3, 768, 768] || points:[2, 48, 2]
#根据不确定点的坐标,得到对应的粗糙预测
coarse = point_sample(out, points, align_corners=False) #[2, 19, 48]
#根据不确定点的坐标,得到对应的特征向量
fine = point_sample(res2, points, align_corners=False) #[2, 256, 48]
#将粗糙预测与对应的特征向量合并
feature_representation = torch.cat([coarse, fine], dim=1) #[2, 275, 48]
#使用MLP进行细分预测
rend = self.mlp(feature_representation) #[2, 19, 48]
return {"rend": rend, "points": points}
##推理阶段
@torch.no_grad()
def inference(self, x, res2, out):
"""
输入:
x:[1, 3, 768, 768],表示输入图片的特征
res2:[1, 256, 192, 192],表示xception的第一层特征输出
out:[1, 19, 48, 48],表示经过级联空洞卷积提取的特征的粗糙预测
输出:
out:[1,19,768,768],表示最终图片的预测
主要思路:
通过 out计算出top N = 8096 个不稳定的像素点,针对每个不稳定像素点得到在res2(fine)
和out(coarse)中对应的特征,组合8096个不稳定像素点对应的fine和coarse得到rend,
再通过mlp得到更准确的预测,迭代至rend的尺寸大小等于输入图片的尺寸大小
"""
"""
During inference, subdivision uses N=8096
(i.e., the number of points in the stride 16 map of a 1024×2048 image)
"""
num_points = 8096
while out.shape[-1] != x.shape[-1]: #out:[1, 19, 48, 48], x:[1, 3, 768, 768]
#每一次预测均会扩大2倍像素,直至与原图像素大小一致
out = F.interpolate(out, scale_factor=2, mode="bilinear", align_corners=True) #out[1, 19, 48, 48]
points_idx, points = sampling_points(out, num_points, training=self.training) #points_idx:8096 || points:[1, 8096, 2]
coarse = point_sample(out, points, align_corners=False) #coarse:[1, 19, 8096] 表示8096个不稳定像素点根据高级特征得出的对应的类别
fine = point_sample(res2, points, align_corners=False) #fine:[1, 256, 8096] 表示8096个不稳定像素点根据低级特征得出的对应类别
feature_representation = torch.cat([coarse, fine], dim=1) #[1, 275, 8096] 表示8096个不稳定像素点合并fine和coarse的特征
rend = self.mlp(feature_representation) #[1, 19, 8096]
B, C, H, W = out.shape #first:[1, 19, 128, 256]
points_idx = points_idx.unsqueeze(1).expand(-1, C, -1) #[1, 19, 8096]
out = (out.reshape(B, C, -1)