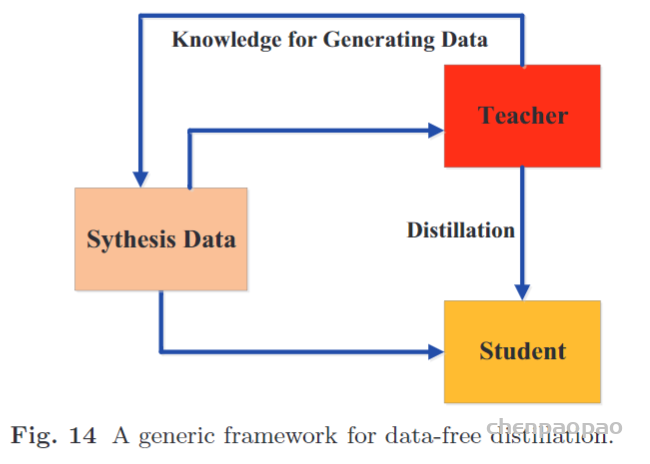
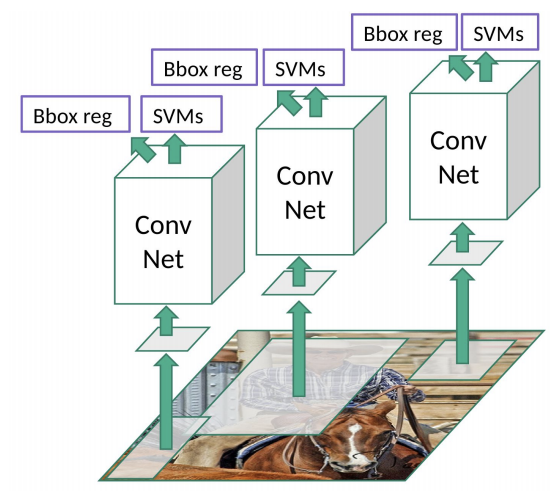
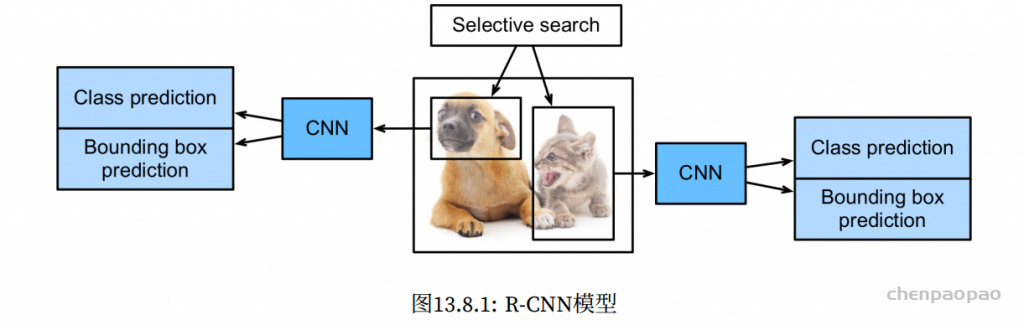
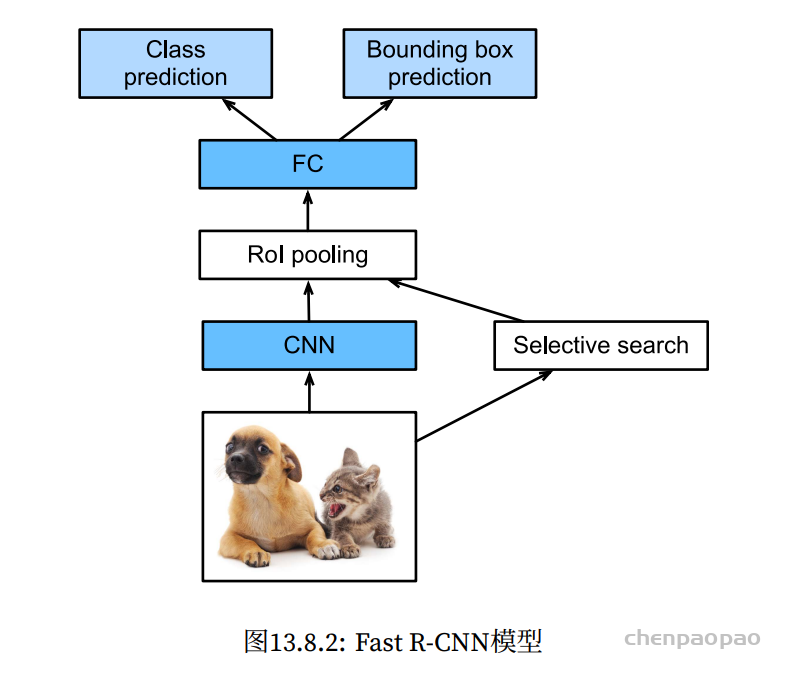
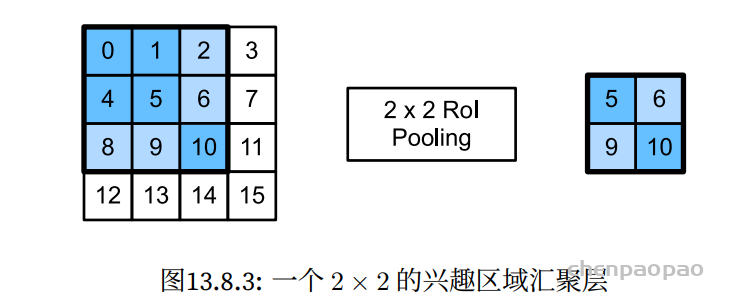
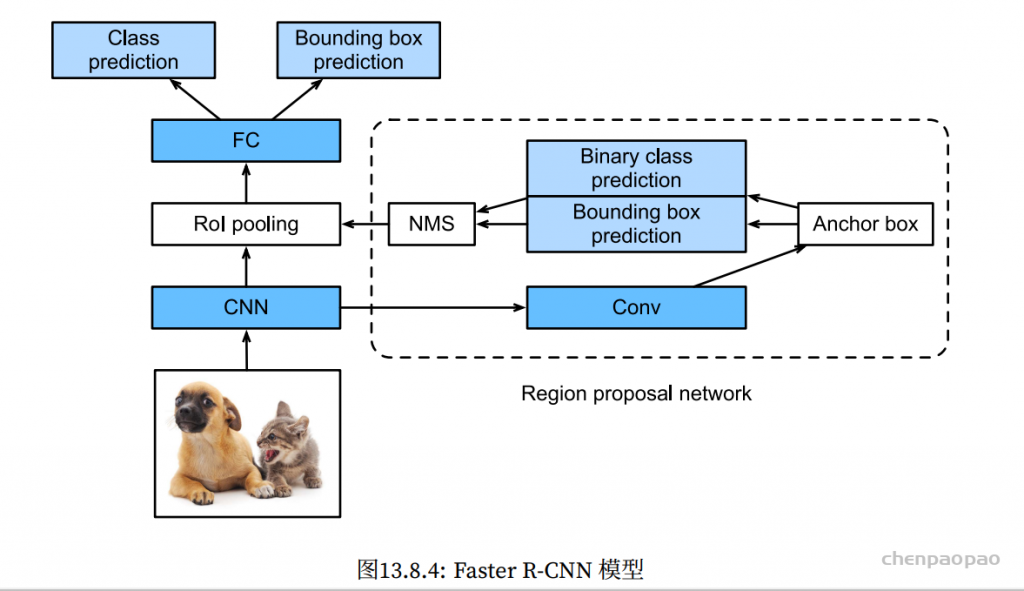
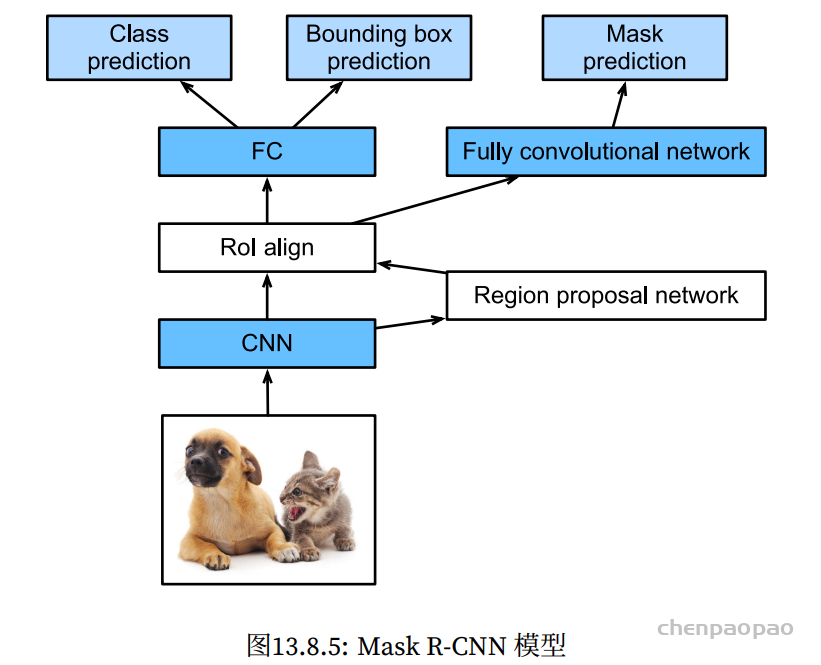
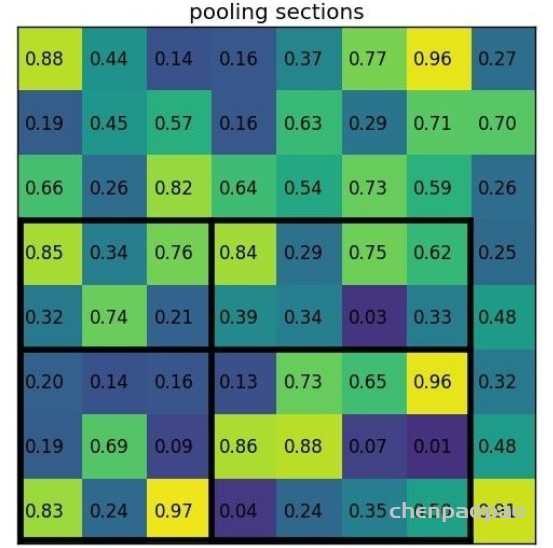
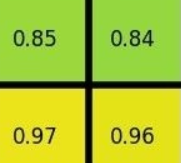
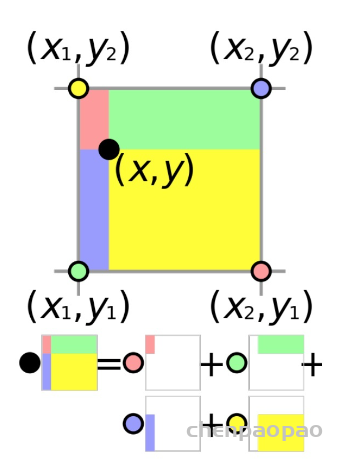
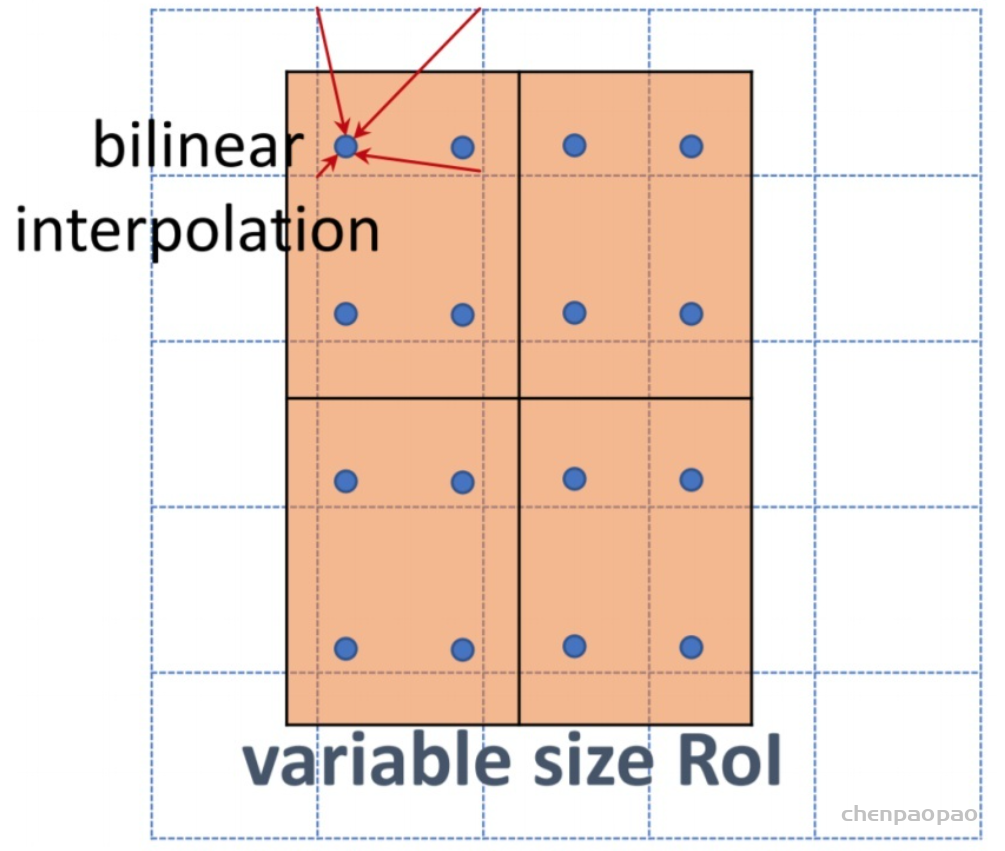
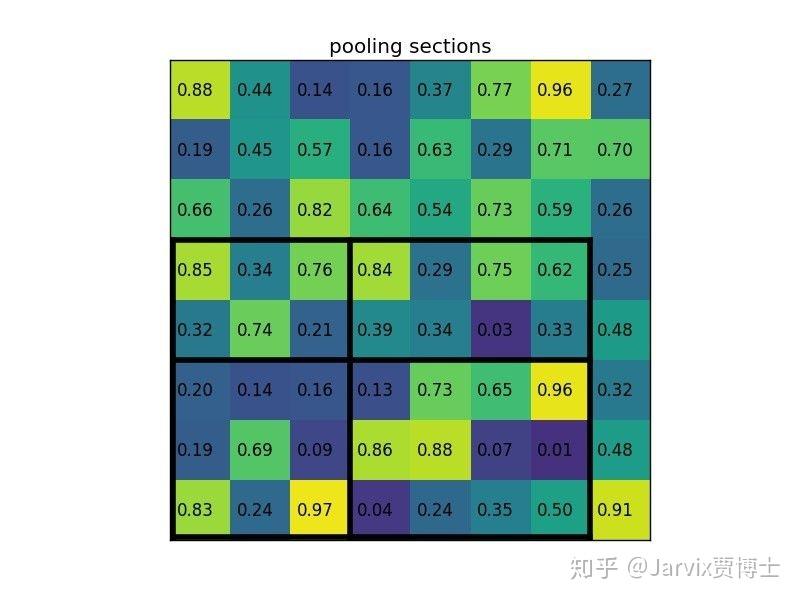
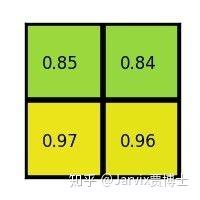
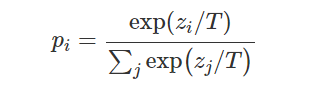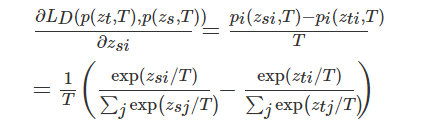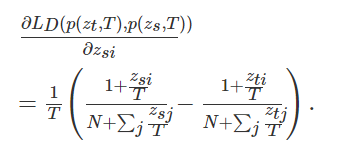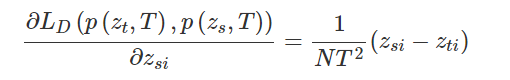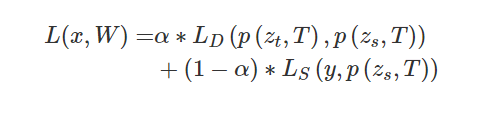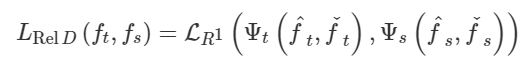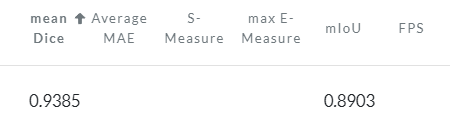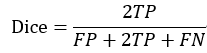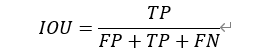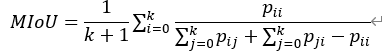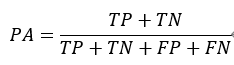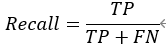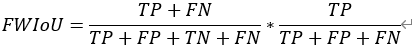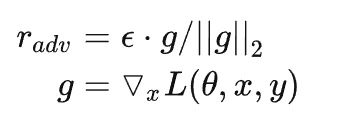Temporal ensembling 还对标签噪声具有鲁棒性,即使有标签数据的标签有误的话,无监督 loss 可以平滑这种错误标签的影响。
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results
Mean Teacher 这篇文章一上来就说“模型成功的关键在于 target 的质量”,一语道破天机啊。而提高 target 的质量的方法目前有两:1.精心选择样本噪声;2. 找到一个更好的 Teacher model。而论文采用了第二种方法。
Mean teacher 也是坚信“平均得就是最好的”(不知道是不是平均可以去噪的原因…orz),但是时序上的平均已经被 temporal ensembling 做了,因此 Mean teacher 提出了一个大胆的想法,我们对模型的参数进行移动平均(weight-averaged),使用这个移动平均模型参数的就是 teacher model 了,然后用 teacher model 来构造高质量 target。
一思索就觉得这想法好,对模型的参数进行平均,每次更新的网络的时候就能更新 teacher model,就能得到 target,不用像 temporal ensembling 那样等一个迭代期这么久,这对 online model 是致命的。
学生损失(student loss)定义为 ground truth 标签和学生模型的软对数之间的交叉熵:
代表交叉熵损失,y 是一个 ground truth 向量,其中只有一个元素为1,它表示转移训练样本的 ground truth 标签,其他元素为0。在蒸馏和学生损失中,两者均使用学生模型的相同 logit,但温度不同。温度在学生损失中为T = 1,在蒸馏损失中为T = t。最后,传统知识蒸馏的基准模型是蒸馏和学生损失的结合:
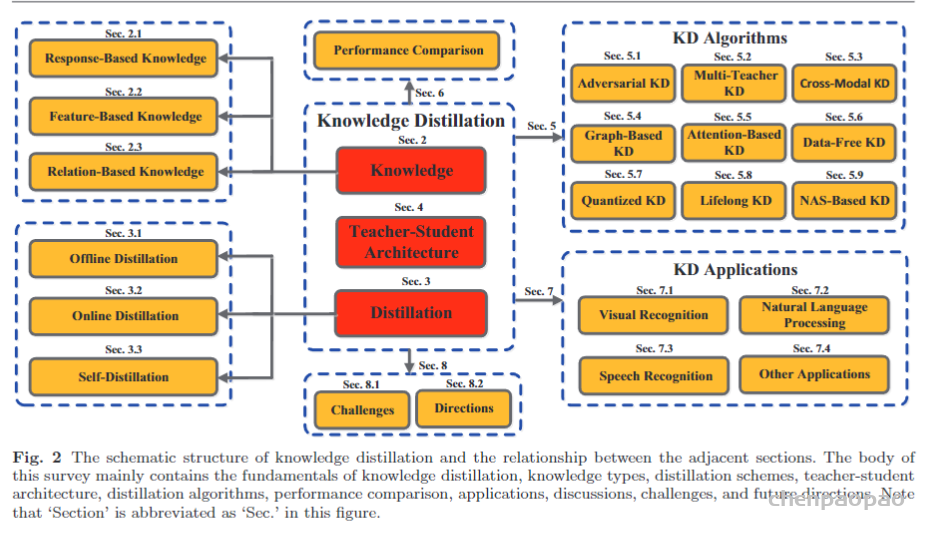
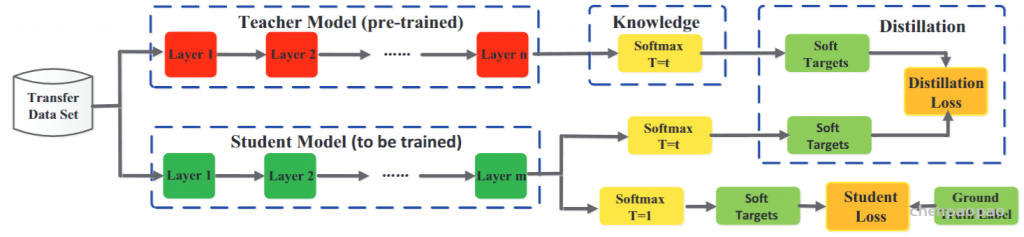
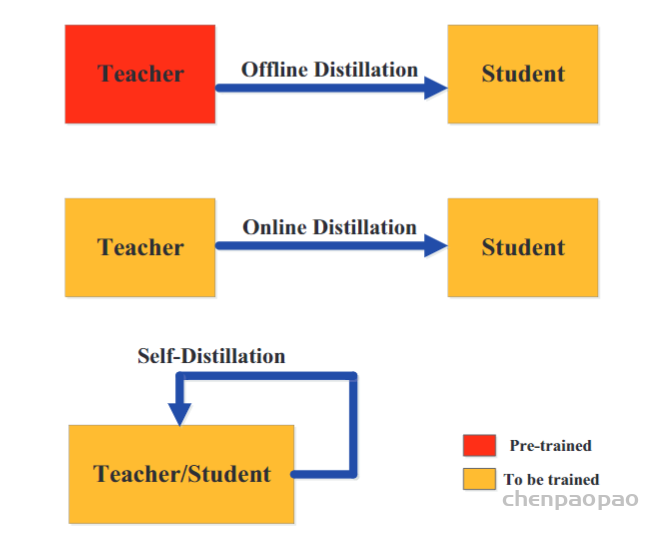
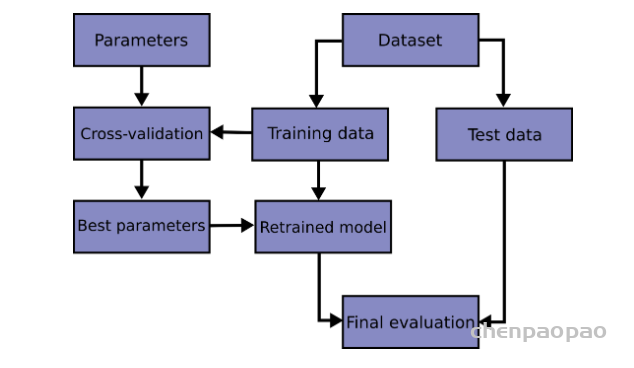
其中 x 是转移集上的训练输入,W是学生模型的参数,并且是调节参数。为了轻松理解知识蒸馏,下图显示了传统知识蒸馏与教师和学生模型联合的特定体系结构。在下图所示的知识蒸馏中,始终首先对教师模型进行预训练,然后再进行训练。仅使用来自预训练教师模型的软目标的知识来训练学生模型。实际上,这就是离线知识提炼与基于响应的知识。
he specific architecture of the benchmark knowledge distillation(Hinton et al., 2015)
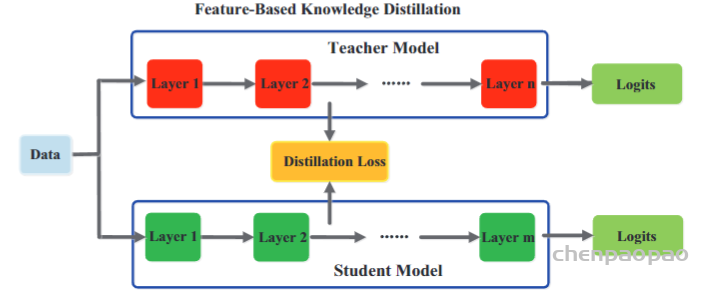
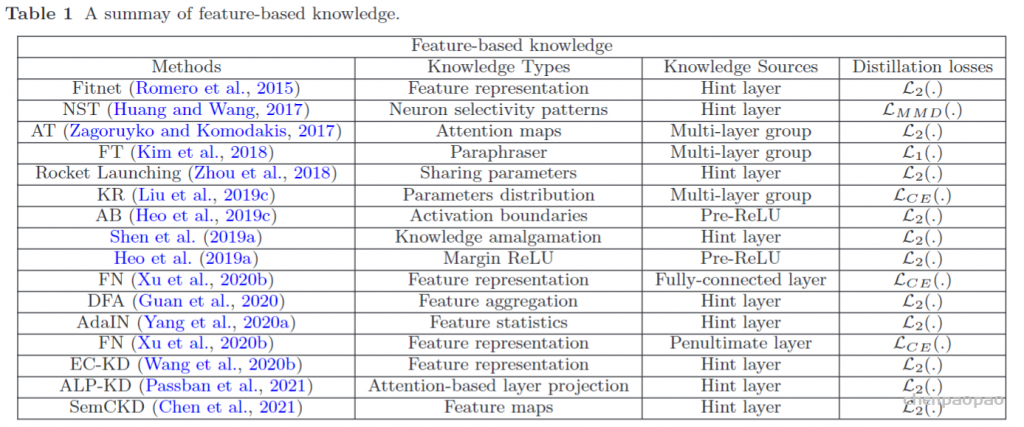
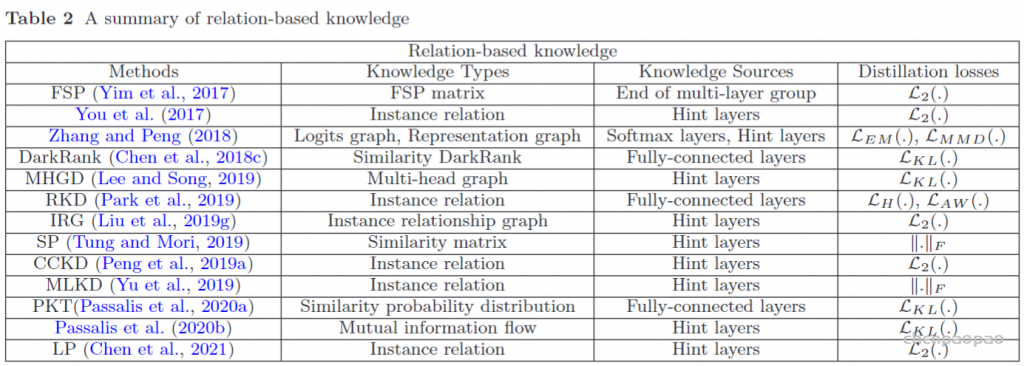
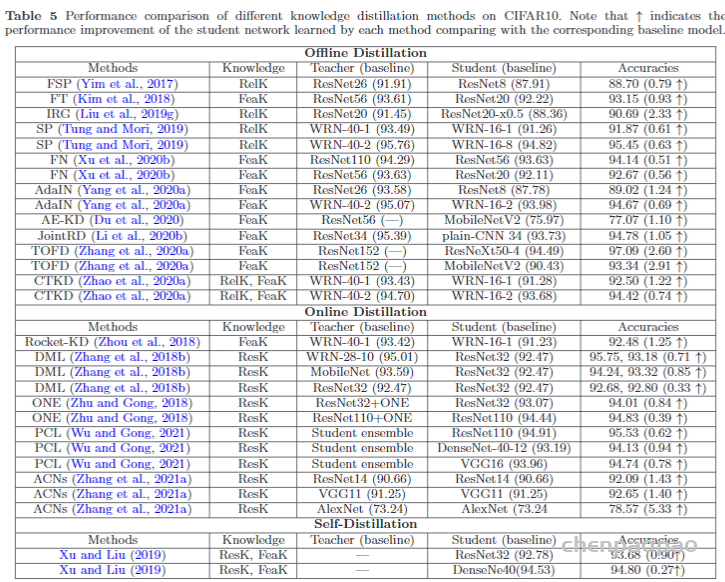
为了探索不同特征图之间的关系,Yim等人。(2017)提出了一种解决方案流程(FSP),该流程由两层之间的Gram矩阵定义。FSP 矩阵总结了特征图对之间的关系。它是使用两层要素之间的内积来计算的。利用特征图之间的相关性作为蒸馏的知识,(Lee et al。,2018)提出了通过奇异值分解的知识蒸馏来提取特征图中的关键信息。为了利用多位教师的知识,Zhang和Peng(2018)分别以每个教师模型的 logits 和特征为节点,形成了两个图。具体来说,在知识转移之前,不同的教师的重要性和关系通过 logits 和表示图进行建模(Zhang and Peng,2018)。Lee and Song(2019)提出了基于多头图的知识蒸馏。图知识是通过多头注意力网络在任意两个特征图之间的内部数据关系。为了探索成对的提示信息,学生模型还模拟了教师模型的成对的提示层之间的互信息(Passalis等,2020b)。通常,基于特征图的关系的知识的蒸馏损失可以表示为:
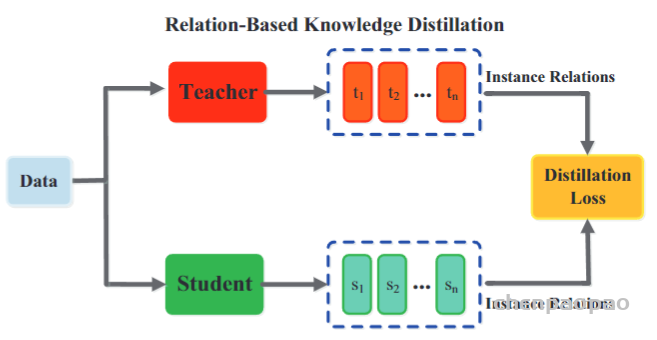
传统的知识转移方法通常涉及个人知识的提炼。老师的软目标直接提炼给学生。实际上,提炼的知识不仅包含特征信息,还包含数据样本的相互关系。具体来说,刘等。(2019g)通过实例关系图提出了一种鲁棒而有效的知识提炼方法。实例关系图中传递的知识包含实例特征,实例关系和特征空间转换跨层。Park等。(2019)提出了一种关系知识蒸馏,该知识蒸馏了实例关系中的知识。基于流形学习的思想,通过特征嵌入来学习学生网络,这保留了教师网络中间层中样本的特征相似性(Chen等人,2020b)。使用数据的特征表示将数据样本之间的关系建模为概率分布(Passalis和Tefas,2018; Passalis等,2020a)。师生的概率分布与知识转移相匹配。(Tung and Mori,2019)提出了一种保留相似性的知识提炼方法。尤其是,将教师网络中输入对的相似激活所产生的保持相似性的知识转移到学生网络中,并保持成对相似性。Peng等。(2019a)提出了一种基于相关一致性的知识蒸馏方法,其中蒸馏的知识既包含实例级信息,又包含实例之间的相关性。使用关联一致性进行蒸馏,学生网络可以了解实例之间的关联。
在自我蒸馏中,教师和学生模型采用相同的网络。这可以视为在线蒸馏的特殊情况。具体来说,Zhang等。(2019b)提出了一种新的自蒸馏方法,其中将来自网络较深部分的知识蒸馏为浅层部分。与(Zhang et al。,2019b)中的自蒸馏相似,有人提出了一种自注意蒸馏方法进行车道检测(Hou et al。,2019)。该网络利用其自身层的注意力图作为其较低层的蒸馏目标。快照蒸馏(Yang et al。,2019b)是自我蒸馏的一种特殊变体,其中网络早期(教师)的知识被转移到其后期(学生)以支持在同一时期内的监督训练过程网络。为了进一步减少通过提前退出的推理时间,Phuong和Lampert(2019b)提出了基于蒸馏的训练方案,其中提前退出层尝试在训练过程中模仿后续退出层的输出。
另外,最近提出了一些有趣的自蒸馏方法。具体来说,袁等。提出了一种基于标签平滑规则化(label smoothing regularization)分析的无教师知识蒸馏方法(Yuan et al。,2020)。Hahn和Choi提出了一种新颖的自我知识蒸馏方法,其中自我知识由预测概率而不是传统的软概率组成(Hahn和Choi,2019)。这些预测的概率由训练模型的特征表示来定义。它们反映了特征嵌入空间中数据的相似性。Yun等。提出了分类自知识蒸馏,以匹配同一模型中同一来源内的类内样本和扩充样本之间的训练模型的输出分布(Yun et al。,2020)。此外,采用Lee等人(2019a)提出的自蒸馏进行数据增强,并将增强的自知性蒸馏为模型本身。还采用自我蒸馏中以一对一地优化具有相同架构的深度模型(教师或学生网络)(Furlanello等,2018; Bagherinezhad等,2018)。每个网络都使用教师优化来蒸馏先前网络的知识。
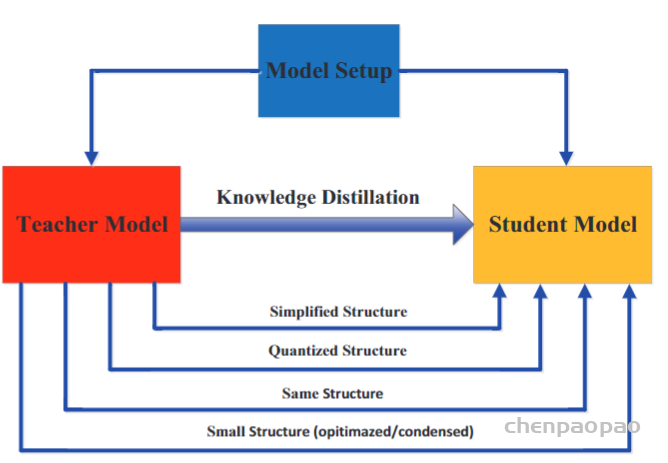
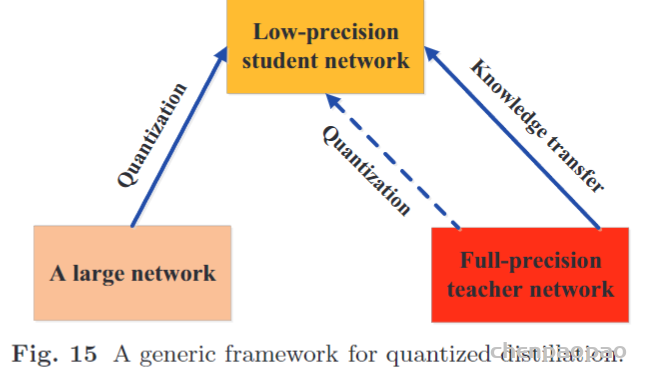
大型深层神经网络和小型学生神经网络之间的模型能力差距会降低知识转移的速度。为了有效地将知识转移到学生网络,已提出了多种方法来控制模型复杂度的可控降低。具体来说,Mirzadeh等。(2020)引入了助教来减轻教师模型和学生模型之间的训练差距。(Gao et al。,2020)通过残差学习进一步缩小了差距,即使用辅助结构来学习残差。另一方面,最近的几种方法也集中在最小化学生模型和教师模型的结构差异上。例如,Polino等。(2018)将网络量化与知识蒸馏相结合,即学生模型很小,是教师模型的量化版本。Nowak和Corso(2018)提出了一种结构压缩方法,该方法涉及将多层学习的知识转移到单层。Wang等。(2018a)逐步执行从教师网络到学生网络的块状知识转移,同时保留接受领域。在在线环境中,教师网络通常是学生网络的集合,其中学生模型彼此共享相似的结构(或相同的结构)。
此外,为了解决终身学习中的灾难性遗忘问题,全局蒸馏(Lee等人,2019b),基于知识蒸馏的终身GAN(Zhai等人,2019),多模型蒸馏(Zhou等人,2020) )和其他基于KD的方法(Li and Hoiem,2017; Shmelkov et al。,2017)已经开发出来,以提取学习到的知识并在新任务上教给学生网络。
NAS蒸馏(NAS-Based Distillation)
神经体系结构搜索(NAS)是最流行的自动机器学习(或AutoML)技术之一,旨在自动识别深度神经模型并自适应地学习适当的深度神经结构。在知识蒸馏中,知识转移的成功不仅取决于老师的知识,还取决于学生的架构。但是,大型教师模型和小型学生模型之间可能存在能力差距,从而使学生难以向老师学习。为了解决这个问题,已经有工作采用 NAS 来找到 oracle-based 和 architecture-aware 的合适的学生架构实现知识蒸馏。此外,知识蒸馏被用于提高神经架构搜索的效率,例如,具有蒸馏架构知识的 NAS(AdaNAS)以及教师指导的架构搜索(TGSA)。在TGSA中,指导每个体系结构搜索步骤以模仿教师网络的中间特征表示,通过有效搜索学生的可能结构,老师可以有效地监督特征转移。
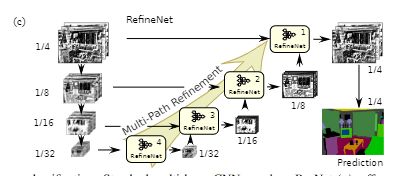
class RCUBlock(nn.Module):
def __init__(self, in_planes, out_planes, n_blocks, n_stages):
super(RCUBlock, self).__init__()
for i in range(n_blocks):
for j in range(n_stages):
setattr(self, '{}{}'.format(i + 1, stages_suffixes[j]),
conv3x3(in_planes if (i == 0) and (j == 0) else out_planes,
out_planes, stride=1,
bias=(j == 0)))
self.stride = 1
self.n_blocks = n_blocks
self.n_stages = n_stages
def forward(self, x):
for i in range(self.n_blocks):
residual = x
for j in range(self.n_stages):
x = F.relu(x)
x = getattr(self, '{}{}'.format(i + 1, stages_suffixes[j]))(x)
x += residual
return
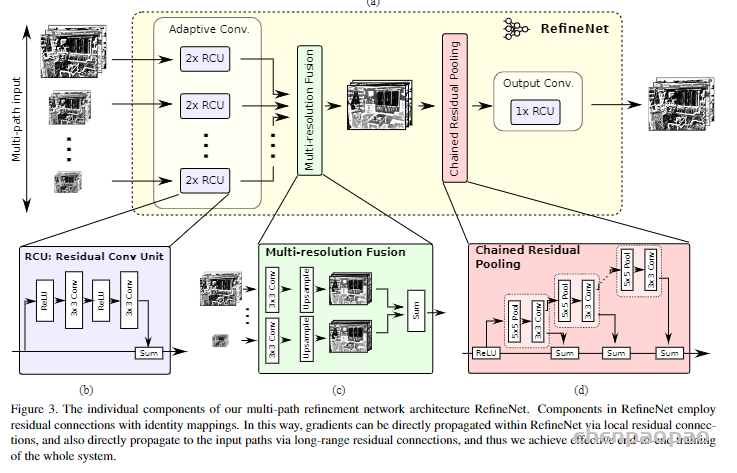
class CRPBlock(nn.Module):
def __init__(self, in_planes, out_planes, n_stages):
super(CRPBlock, self).__init__()
for i in range(n_stages):
setattr(self, '{}_{}'.format(i + 1, 'outvar_dimred'),
conv3x3(in_planes if (i == 0) else out_planes,
out_planes, stride=1,
bias=False))
self.stride = 1
self.n_stages = n_stages
self.maxpool = nn.MaxPool2d(kernel_size=5, stride=1, padding=2)
def forward(self, x):
top = x
for i in range(self.n_stages):
top = self.maxpool(top)
top = getattr(self, '{}_{}'.format(i + 1, 'outvar_dimred'))(top)
x = top + x
return x
实际上就是取消了符号函数,用二范式做了一个scale,需要注意的是:这里的norm计算的是,每个样本的输入序列中出现过的词组成的矩阵的梯度norm。原作者提供了一个TensorFlow的实现 [10],在他的实现中,公式里的 x 是embedding后的中间结果(batch_size, timesteps, hidden_dim),对其梯度 g 的后面两维计算norm,得到的是一个(batch_size, 1, 1)的向量 ||g||2 。为了实现插件式的调用,笔者将一个batch抽象成一个样本,一个batch统一用一个norm,由于本来norm也只是一个scale的作用,影响不大。实现如下:
import torch
class FGM():
def __init__(self, model):
self.model = model
self.backup = {}
def attack(self, epsilon=1., emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
self.backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = epsilon * param.grad / norm
param.data.add_(r_at)
def restore(self, emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}
import torch
class PGD():
def __init__(self, model):
self.model = model
self.emb_backup = {}
self.grad_backup = {}
def attack(self, epsilon=1., alpha=0.3, emb_name='emb.', is_first_attack=False):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
if is_first_attack:
self.emb_backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = alpha * param.grad / norm
param.data.add_(r_at)
param.data = self.project(name, param.data, epsilon)
def restore(self, emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.emb_backup
param.data = self.emb_backup[name]
self.emb_backup = {}
def project(self, param_name, param_data, epsilon):
r = param_data - self.emb_backup[param_name]
if torch.norm(r) > epsilon:
r = epsilon * r / torch.norm(r)
return self.emb_backup[param_name] + r
def backup_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
self.grad_backup[name] = param.grad.clone()
def restore_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
param.grad = self.grad_backup[name]
使用的时候,要麻烦一点:
pgd = PGD(model)
K = 3
for batch_input, batch_label in data:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
pgd.backup_grad()
# 对抗训练
for t in range(K):
pgd.attack(is_first_attack=(t==0)) # 在embedding上添加对抗扰动, first attack时备份param.data
if t != K-1:
model.zero_grad()
else:
pgd.restore_grad()
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
pgd.restore() # 恢复embedding参数# 梯度下降,更新参数
optimizer.step()
model.zero_grad()