https://github.com/KaiiZhang/DDP-Tutorial/blob/main/DDP-Tutorial.md
数据并行和分布式数据并行方案:
第一: 数据并行 , 开一个进程(process),该进程下每个线程(threading)负责一部分数据,分别跑在不同卡上,前向传播,devices各玩各的,计算loss时候需要所有devices的输出输送到主GPU【默认device0】上计算梯度均值,并更新device0上的参数,然后将参数广播到其他device上。总结:单机-多线程,通过torch.nn.DataParallel 实现。
第二: 分布式数据并行,开多个进程,一个进程运行在一张卡上,每个进程负责一部分数据。在各进程梯度计算完成之后,各进程需要将梯度进行汇总平均,然后再由 rank=0 的进程,将其 broadcast 到所有进程。各进程用该梯度来更新参数。由于各进程中的模型,初始参数一致 (初始时刻进行一次 broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。
总结:单机/多机-多进程,通过torch.nn.parallel.DistributedDataParallel 实现。
毫无疑问,第一种简单,第二种复杂,毕竟 进程间 通信比较复杂。
torch.nn.DataParallel 和 torch.nn.parallel.DistributedDataParallel,下面简称为DP和DDP。
总结: 两个函数主要用于在多张显卡上训练模型,也就是所谓的分布式训练。
数据并行 torch.nn.DataParallel :
原理:
- 网络前向传播前,输入数据被分成几份送到不同显卡上,网络模型每个显卡上拷贝一份。
- 前向传播时,devices各玩各的。
- 前向传播完成后,每张显卡上的网络输出会送到主device上(默认第一张卡),在主device上计算loss。然后,loss送给每个device,每个device计算得到梯度,再把梯度送到主device上,主device对汇总得到的梯度求均值后,更新主device上的网络参数。最后,将更新后的网络权重广播(broadcast)到其它device上,实现所有device网络权重同步。
- torch.nn.DataParallel是把每张卡的输出聚合到GPU0上,然后在GPU0上与label计算loss,根据计算图反向传播,让每张卡上获得自己的梯度。优化器则对梯度进行聚合,在主GPU更新模型参数,再把新的参数分发到每个GPU。
从上面介绍可知,DataParallel 对主device依赖较高,会造成负载不均衡,限制模型训练速度。
DP使用教程:
主程序DP_main.py中,下面这行代码实现数据并行化分布式训练。
相比单卡单机代码:只需要修改以下代码:
model_train = torch.nn.DataParallel(model)
通过终端运行命令,
CUDA_VISIBLE_DEVICES=0,1 python3 DP_main.py
DP_main.py代码:
import torch
import torchvision
import torch.nn as nn
import torch.backends.cudnn as cudnn
import torchvision.transforms as transforms
from net import ToyModel
import torch.optim as optim
#---------------------------#
# 获得学习率
#---------------------------#
def get_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
#---------------------------#
# 获得数据集
#---------------------------#
def get_dataset():
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
CIFAR10_trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform_train)
# ----------------------------------------------------------#
# num_workers:加载数据集使用的线程数
# pin_memory=True:锁页内存, 可以加速数据读取. (可能会导致Bug)
# ----------------------------------------------------------#
trainloader = torch.utils.data.DataLoader(CIFAR10_trainset,
batch_size=16, num_workers=2, pin_memory=True)
return trainloader
#---------------------------#
# 训练
#---------------------------#
def train(model, device, trainloader, optimizer, loss_func, print_frequence, epoch):
train_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(trainloader):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_func(outputs, targets)
loss.backward()
optimizer.step()
# loss.item()把其中的梯度信息去掉,没.item()可能会导致程序所占内存一直增长,然后被计算机killed
train_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
if batch_idx % print_frequence == print_frequence - 1 or print_frequence == trainloader.__len__() - 1:
print('epoch: %d | Loss: %.3f | Acc: %.3f%% (%d/%d)' % (
epoch, train_loss / (batch_idx + 1), 100. * correct / total, correct, total))
torch.save(model.state_dict(), "%d.ckpt" % epoch)
# torch.save(model.module.state_dict(), "%d.ckpt" % epoch) 用双卡训练保存权重,重新加载时,也需要这样保存,否则,权重前面会多module
# -------------------------------------#
# 只是想看看lr有没有衰减
# -------------------------------------#
lr = get_lr(optimizer)
print("lr:", lr)
lr_scheduler.step()
if __name__ == '__main__':
trainloader = get_dataset()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = ToyModel()
print(model)
model_train = model.train()
if torch.cuda.is_available():
model_train = torch.nn.DataParallel(model) # 单GPU跑套DP的话,指标可能会降
cudnn.benchmark = True
model_train = model_train.cuda() # 等效于model_train = model_train.to(device)
loss_func = nn.CrossEntropyLoss()
optimizer = optim.SGD(model_train.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
# -------------------------------------#
# step_size控制多少个epoch衰减一次学习率
# -------------------------------------#
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.1)
print_frequence = 500
epochs = 100
for epoch in range(0, epochs):
train(model_train, device, trainloader, optimizer, loss_func, print_frequence, epoch)
分布式并行DistributedDataParallel
- 更快的训练速度
- 多进程的运行方式
- 支持单机多卡和多机多卡
- 平衡的GPU使用
DDP原理:
先说分布式几个名词:
一个world里进程个数为world_size,全局看,每个进程都有一个序号rank;分开看,一个进程在每台机器里面也有序号local_rank。
- group:进程组,默认一个组,即一个world
- world_size:全局进程个数
- rank:进程序号,用于进程间通信。rank=0为GPU主卡,主要用于多机多卡。本文中仅涉及到一台机器内多张卡。
- locak_rank:进程(一台机器)内的GPU编号,通过指令
torch.distributed.run自动指定,不需要用户输入该参数。
DDP 在每次迭代中,操作系统会为每个GPU创建一个进程,每个进程具有自己的 optimizer ,并独立完成所有的优化步骤,进程内与一般的训练无异。在各进程梯度计算完成之后,各进程需要将梯度进行汇总平均,然后再由 rank=0 的进程,将其 broadcast 到所有进程。各进程用该梯度来更新参数。由于各进程中的模型,初始参数一致 (初始时刻进行一次 broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。
而在 DataParallel 中,全程维护一个 optimizer,对各 GPU 上梯度进行求和,在主 GPU 进行参数更新,之后再将模型参数 broadcast 到其他 GPU。相较于 DP,DDP传输的数据量更少,速度更快,效率更高。
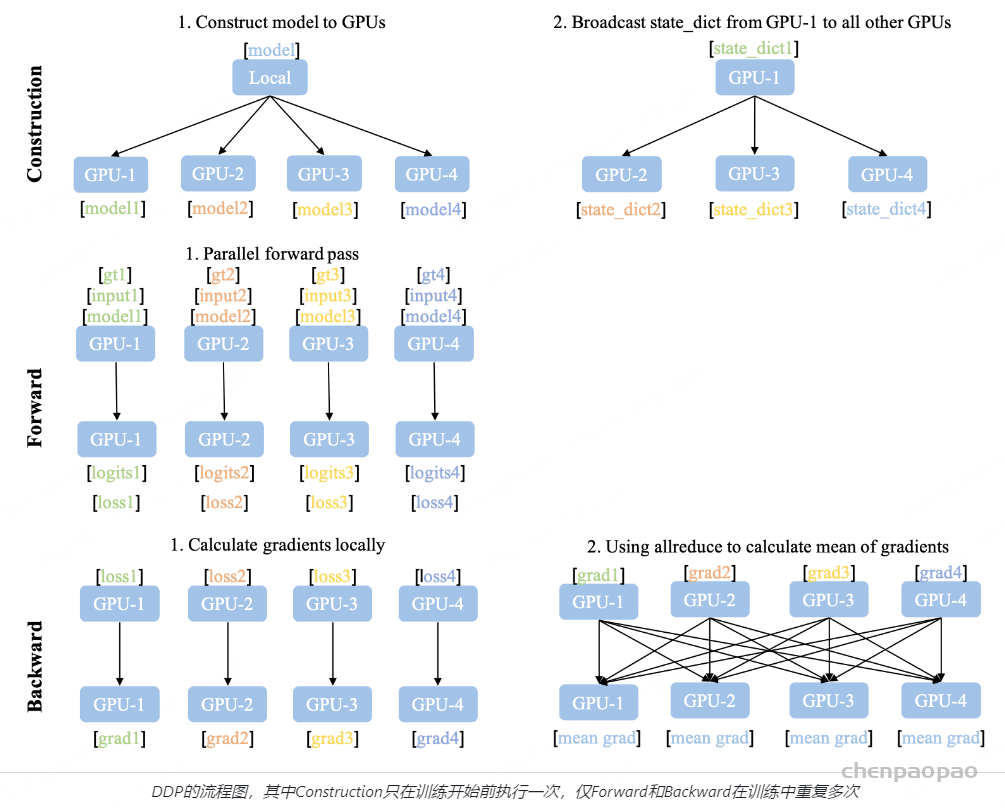
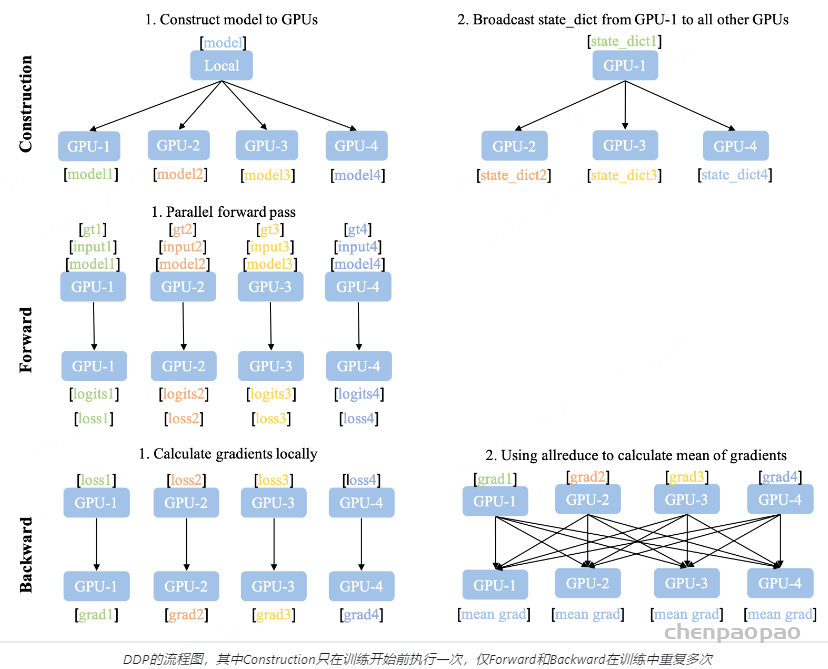
DDP的流程示意图如上图所示,DDP需要额外的建立进程组阶段(Construction)。在Construction阶段需要首先明确通信协议和总进程数。通信协议是实现DDP的底层基础,我们在之后单独介绍。总进程数就是指有多少个独立的并行进程,被称为worldsize。根据需求每个进程可以占用一个或多个GPU,但并不推荐多个进程共享一个GPU,这会造成潜在的性能损失。为了便于理解,在本文的所有示例中我们假定每个进程只占用1个GPU,占用多个GPU的情况只需要简单的调整GPU映射关系就好。
并行组建立之后,每个GPU上会独立的构建模型,然后GPU-1中模型的状态会被广播到其它所有进程中以保证所有模型都具有相同的初始状态。值得注意的是Construction只在训练开始前执行,在训练中只会不断迭代前向和后向过程,因此不会带来额外的延迟。
相比于DataParallel,DDP的前向后向过程更加简洁。推理、损失函数计算,梯度计算都是并行独立完成的。DDP实现并行训练的核心在于梯度同步。梯度在模型间的同步使用的是allreduce通信操作,每个GPU会得到完全相同的梯度。如图中后向过程的步骤2,GPU间的通信在梯度计算完成后被触发(hook函数)。图中没有画出的是,通常每个GPU也会建立独立的优化器。由于模型具有同样的初始状态和后续相同的梯度,因此每轮迭代后不同进程间的模型是完全相同的,这保证了DDP的数理一致性。
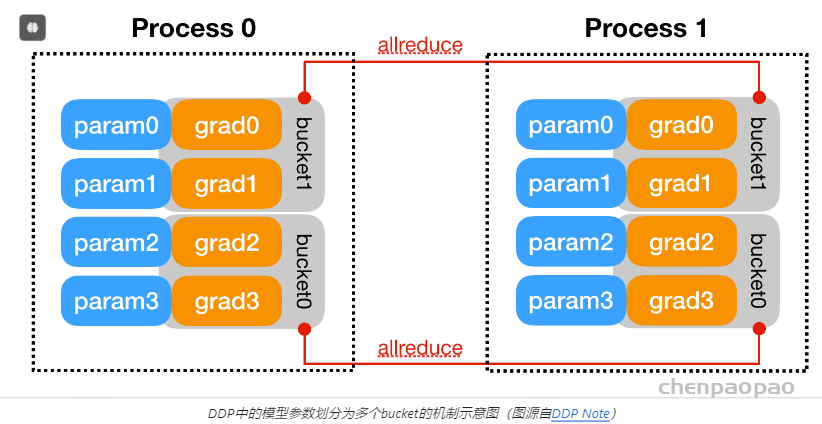
为了优化性能,DDP中针对allreduce操作进行了更深入的设计。梯度的计算过程和进程间的通信过程分别需要消耗一定量的时间。等待模型所有的参数都计算完梯度再进行通信显然不是最优的。如下图所示,DDP中的设计是通过将全部模型参数划分为无数个小的bucket,在bucket级别建立allreduce。当所有进程中bucket0的梯度计算完成后就立刻开始通信,此时bucket1中梯度还在计算。这样可以实现计算和通信过程的时间重叠。这种设计能够使得DDP的训练更高效。
在最后我们对DDP的通信部分进行介绍。DDP后端的通信由多种CPP编写的协议支持,不同协议具有不同的通信算子的支持,在开发中可以根据需求选择。
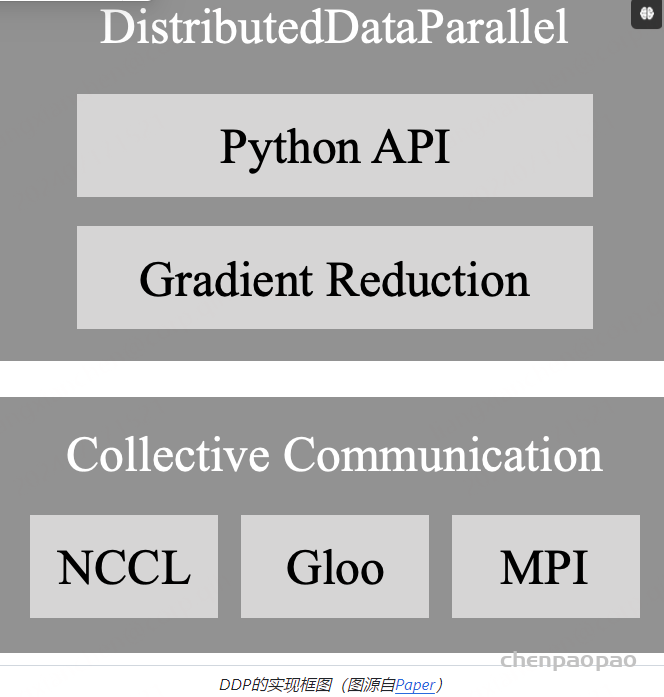
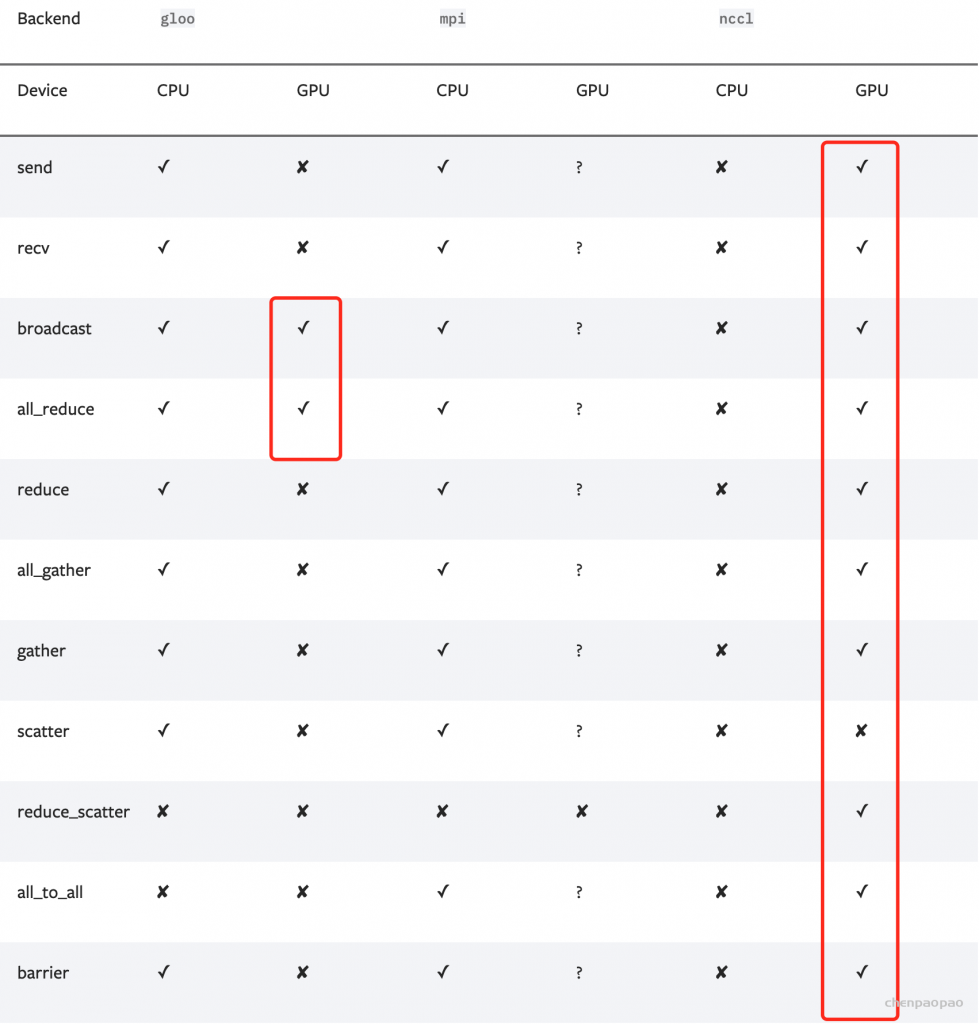
对于CV和NLP常用GPU训练的任务而言,选择Gloo或NCCL协议即可。一个决定因素是你使用的计算机集群的网络环境:
- 当使用的是Ethernet(以太网,大部分机器都是这个环境):那么优先选择NCCL,具有更好的性能;如果在使用中遇到了NCCL通信的问题,那么就选择Gloo作为备用。(经验:单机多卡直接NCCL;多机多卡先尝试NCCL,如果通信有问题,而且自己解决不了,那就Gloo。)
- 当使用的是InfiniBand:只支持NCCL。
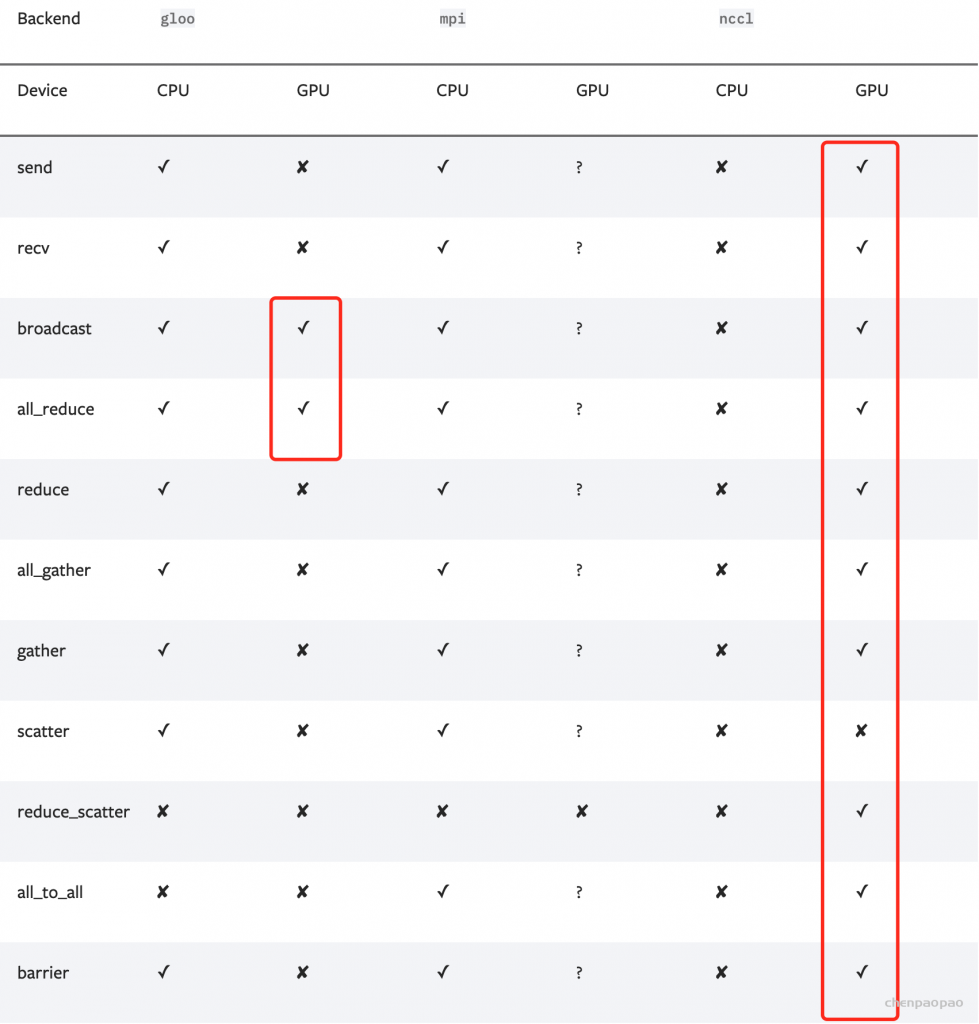
另一个决定性因素是二者支持的算子范围不同,因此在使用时还需要结合代码里的功能来确定。下图记录了每种通信协议能够支持的算子,Gloo能够实现GPU中最基本的DDP训练,而NCCL能够支持更加多样的算子.
DDP使用:
- 设备间通信
为了保证不同卡上的模型参数同步,设备间需要通讯。
设备间通讯通过后端backend实现,GPU上用nccl,CPU上用gloo。
torch.distributed.init_process_group('nccl')
- 指定GPU
指定使用哪些GPU,作用相当于CUDA_VISIBLE_DEVICES命令。
torch.cuda.set_device(args.local_rank)
- 构造模型
构造DDP model,[args.local_rank]是一个list
model = DistributedDataParallel(model, device_ids=[args.local_rank],
output_device=args.local_rank)
- 构建数据集
构建数据集中需要用到train_sampler来shuffle数据,继而实现把trainset中的样本随机分配到不同的GPU上,
train_sampler = torch.utils.data.distributed.DistributedSampler(trainset)
# ---------------------------------------------------------------#
# sampler参数和shuffle参数是互斥的,两个传一个就好,都用于数据打乱。
# ----------------------------------------------------------------#
trainloader = torch.utils.data.DataLoader(trainset,
batch_size=16, num_workers=2, sampler=train_sampler)
- 数据放到多卡上
模型、损失函数、输入数据要放到多卡上,代码例如:
data = data.to(args.local_rank) # 等效于data.cuda(args.local_rank)
通过终端运行命令,
# CUDA_VISIBLE_DEVICES="gpu_0, gpu1,..." python -m torch.distributed.launch --nproc_per_node n_gpus DDP_main.py
CUDA_VISIBLE_DEVICES="0,1" python -m torch.distributed.launch --nproc_per_node=2 DDP_main.py # 因为是单机多卡,所以只需要指定nproc_per_node【GPU数量】即可。local_rank不需要设置。
DDP_main.py中内容如下:
import argparse # 从命令行接受参数
from tqdm import tqdm # 用于进度条
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
from net import ToyModel
import torchvision.transforms as transforms
# ---------------------------#
# 下面两个包用于分布式训练
# ---------------------------#
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
# ---------------------------#
# 获得数据集
# ---------------------------#
def get_dataset():
transform = torchvision.transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
# -----------------------------------------------#
# train_sampler主要用于DataLoader中shuffle数据
# 把trainset中的样本随机分配到不同的GPU上
# -----------------------------------------------#
train_sampler = torch.utils.data.distributed.DistributedSampler(trainset)
# ---------------------------------------------------------------#
# batch_size:每个进程(GPU/卡)下的batch_size。
# 总batch_size = 这里的batch_size * 进程并行数
# 全局进程个数world_size = 节点数量 * 每个节点上process数量
# 总卡数 = 电脑数 * 每台电脑上有多少张卡
# sampler参数和shuffle参数是互斥的,两个传一个就好,都用于数据打乱。
# 在DDP中,用sampler参数
# ----------------------------------------------------------------#
trainloader = torch.utils.data.DataLoader(trainset,
batch_size=16, num_workers=2, sampler=train_sampler)
return trainloader
#---------------------------#
# 训练
#---------------------------#
def train(model, trainloader, optimizer, loss_func, lr_scheduler, epoch):
model.train()
iterator = tqdm(range(epoch)) # 为了进度条显示而已
for epoch in iterator:
# ------------------------------------------------------------------#
# 设置sampler的epoch,DistributedSampler需要这个来指定shuffle方式,
# 通过维持各个进程之间的相同随机数种子使不同进程能获得同样的shuffle效果。
# 这一步是必须的,让数据充分打乱,训练效果更好
# ------------------------------------------------------------------#
trainloader.sampler.set_epoch(epoch)
for data, label in trainloader:
data, label = data.to(args.local_rank), label.to(args.local_rank)
optimizer.zero_grad()
prediction = model(data)
loss = loss_func(prediction, label)
loss.backward()
iterator.desc = "loss = %0.3f" % loss
optimizer.step()
# ------------------------------------------------------------------#
# save模型的时候:保存的是model.module而不是model,
# 因为model其实是DDP model,参数是被`model=DDP(model)`包起来的。
# 只需要在进程0(local_rank=0)上保存一次就行了,避免多次重复保存。
# ------------------------------------------------------------------#
if dist.get_rank() == 0: # 等效于 if local_rank == 0:
torch.save(model.module.state_dict(), "%d.ckpt" % epoch)
lr_scheduler.step()
# -----------------------------------------------#
# 初始化配置local_rank配置
# -----------------------------------------------#
parser = argparse.ArgumentParser()
# local_rank:当前这个节点上的第几张卡,从外部传入
# 该步骤必须有,launch会自动传入这个参数
parser.add_argument("--local_rank",help="local device id on current node", type=int)
args = parser.parse_args()
local_rank = args.local_rank # 纯属想写代码时用local_rank还是args.local_rank都行
print('local_rank:', args.local_rank)
"""
local_rank: 0
local_rank: 1
"""
if __name__ == "__main__":
# DDP 初始化
torch.cuda.set_device(args.local_rank) # 作用相当于CUDA_VISIBLE_DEVICES命令,修改环境变量
dist.init_process_group(backend='nccl') # 设备间通讯通过后端backend实现,GPU上用nccl,CPU上用gloo
# 准备数据,要在DDP初始化之后进行
trainloader = get_dataset()
# 初始化model
model = ToyModel().to(args.local_rank) # 等效于model = ToyModel().cuda(args.local_rank)
# Load模型参数要在构造DDP model之前,且只需要在 master卡 上加载即可
ckpt_path = None
if dist.get_rank() == 0 and ckpt_path is not None:
model.load_state_dict(torch.load(ckpt_path))
# 构造DDP model
model = DDP(model, device_ids=[args.local_rank], output_device=args.local_rank)
# 初始化optimizer,要在构造DDP model之后
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
# 学习率衰减方式
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.1)
# 初始化loss
loss_func = nn.CrossEntropyLoss().to(args.local_rank)
# 模型训练
train(model, trainloader, optimizer, loss_func, lr_scheduler, epoch=100)
# ----------------------------------------------------------------------------------#
# CUDA_VISIBLE_DEVICES:来决定使用哪些GPU,个数和后面n_gpus相同
# torch.distributed.launch:启动DDP模式,构建多个进程,也会向代码中传入local_rank参数,
# 没有CUDA_VISIBLE_DEVICES限制的话,传入为从 0 到 n_gpus-1 的索引
# --nproc_per_node=n_gpus:单机多卡,用几个gpu
# -----------------------------------------------------------------------------------#
# 用 2 张卡跑
CUDA_VISIBLE_DEVICES="0,1" python -m torch.distributed.launch --nproc_per_node 2 DDP_main.py
# 用 3 张卡跑
CUDA_VISIBLE_DEVICES="1,2,3" python -m torch.distributed.launch --nproc_per_node 3 DDP_main.py